-
MySQL内外连接、索引特性
目录
MySQL内外连接是一种用于联接两个或多个表的操作。内连接只返回满足连接条件的行,外连接返回满足条件和不满足条件的行。
内连接
SQL如下:
SELECT ... FROM t1 INNER JOIN t2 ON 连接条件 [INNER JOIN t3 ON 连接条件] ... AND 其他条件;案例一:显示SMITH的名字和部门名字
多表查询:

多表查询本质就是内连接,用内连接方法:

外连接
分为左外连接和右外连接。
左外连接(LEFT JOIN)是指将左边的表(左表)的所有记录和右边的表(右表)的匹配记录进行连接,如果右表中没有匹配的记录,则右表的字段值为NULL。
右外连接(RIGHT JOIN)是指将右边的表(右表)的所有记录和左边的表(左表)的匹配记录进行连接,如果左表中没有匹配的记录,则左表的字段值为NULL。
简单来说,左外连接返回左表的所有记录和右表的匹配记录,右外连接返回右表的所有记录和左表的匹配记录。
左外连接
左外连接SQL如下:
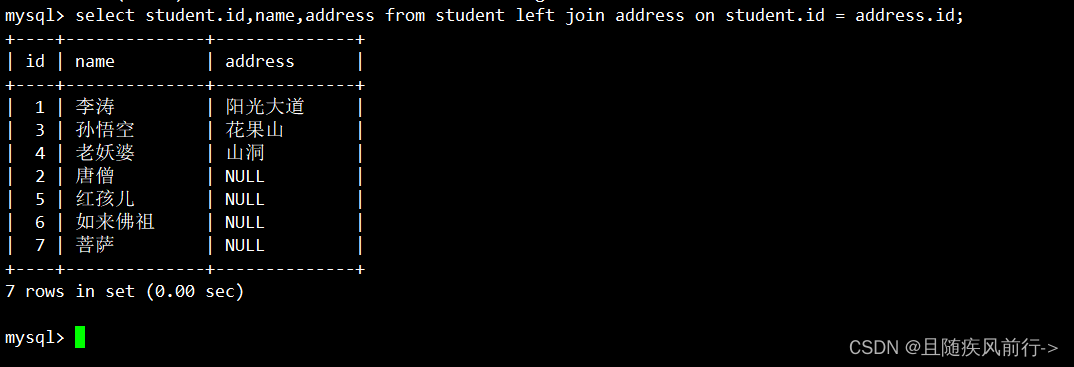
SELECT ... FROM t1 LEFT JOIN t2 on 连接条件 [LEFT JOIN t3 on 连接条件] ... AND 其他条件案例一:给定一个学生表和地址表,查询学生的地址,就算学生无地址也要显示
给定表如下:

使用左外连接:
右连接
右外连接SQL如下:
SELECT ... FROM t1 RIGHT JOIN t2 on 连接条件 [RIGHT JOIN t3 on 连接条件] ... AND 其他条件案例一:给定一个员工表和部门表,列出部门名称和这些部门的员工信息,同时列出没有员工的部门
给定表:

使用右外连接:

索引特性
理解索引
为什么需要索引?
当查询数据直接遍历时,查询时间复杂度为O(N),建立索引的价值在于提高海量数据的检索速度,只要执行了正确的创建索引的操作,数据库底层就会为表中的数据记录构建特定的数据结构,后续在查询表中的数据就能通过查询该数据结构快速查询到数据。但是一定程度也降低了增删改的效率,因为在增删改操作之外,可能需要对底层建立的数据结构进行调整维护。
常见的索引:
主键索引,唯一索引,普通索引,全文索引
验证索引
使用下面SQL创建一个海量数据的表,这段SQL将创建一个名为
bit_index的数据库,一个名为EMP的表,并向表中插入了8000000条记录的数据。- drop database if exists `bit_index`;
- create database if not exists `bit_index` default character set utf8;
- use `bit_index`;
- -- 构建一个8000000条记录的数据
- -- 构建的海量表数据需要有差异性,所以使用存储过程来创建, 拷贝下面代码就可以了,暂时不用理解
- -- 产生随机字符串
- delimiter $$
- create function rand_string(n INT)
- returns varchar(255)
- begin
- declare chars_str varchar(100) default
- 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
- declare return_str varchar(255) default '';
- declare i int default 0;
- while i < n do
- set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
- set i = i + 1;
- end while;
- return return_str;
- end $$
- delimiter ;
- -- 产生随机数字
- delimiter $$
- create function rand_num( )
- returns int(5)
- begin
- declare i int default 0;
- set i = floor(10+rand()*500);
- return i;
- end $$
- delimiter ;
- -- 创建存储过程,向雇员表添加海量数据
- delimiter $$
- create procedure insert_emp(in start int(10),in max_num int(10))
- begin
- declare i int default 0;
- set autocommit = 0;
- repeat
- set i = i + 1;
- insert into EMP values ((start+i)
- ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
- until i = max_num
- end repeat;
- commit;
- end $$
- delimiter ;
- -- 雇员表
- CREATE TABLE `EMP` (
- `empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
- `ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
- `job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
- `mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
- `hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
- `sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
- `comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
- `deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
- );
- -- 执行存储过程,添加8000000条记录
- call insert_emp(100001, 8000000);
倘若在执行call insert_emp出现错误:
ERROR 1728 (HY000): Cannot load from mysql.proc. The table is probably corrupted
可以尝试使用下面命令去修复myproc表,然后再重新执行SQL。
- USE mysql;
- REPAIR TABLE proc;
记录数较多,执行SQL较耗时:

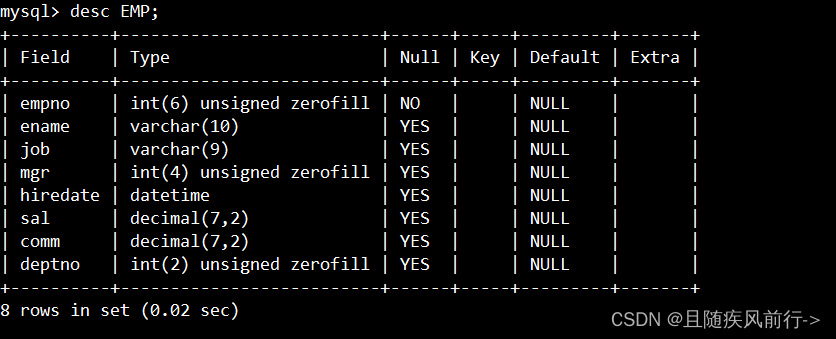
通过desc命令查看表,表中没有索引:
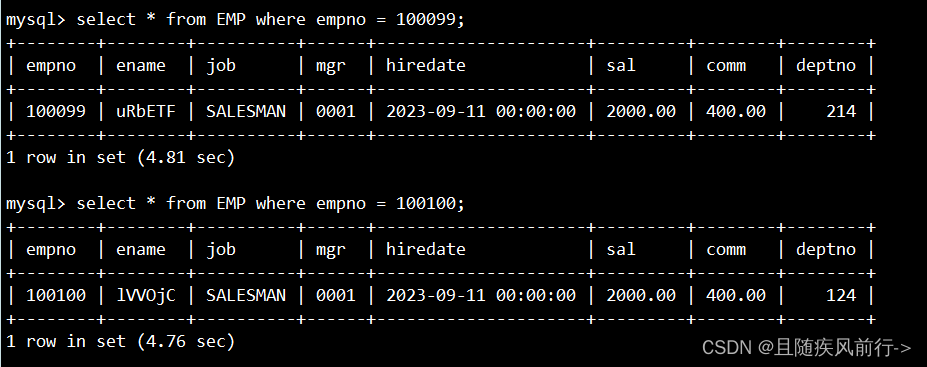
查询EMP中指定员工信息花费4秒以上:
以员工工号建立索引:

建立索引后查询,飞速:
注:索引创建原则
频繁查询、唯一性、更新不频繁、能作为查询条件

使用explain加在SQL前面,可见使用了索引:

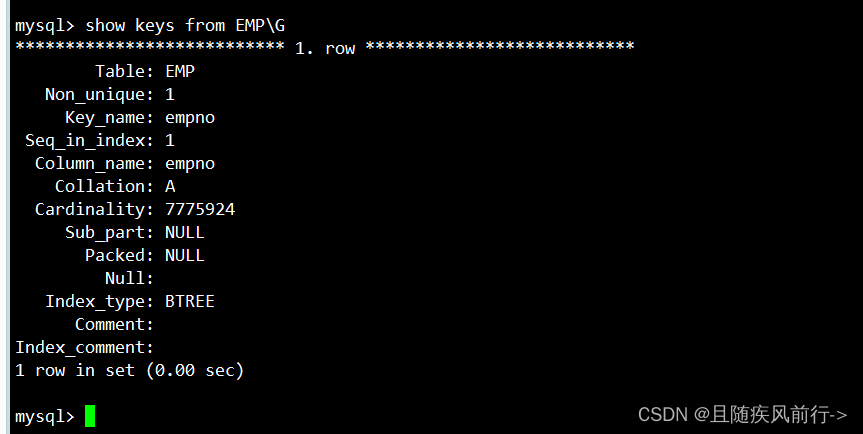
使用select keys from 表名 SQL查询表的索引信息:
说明:
Table: 表名
Non_unique: 是否是唯一键索引
Key_name: 索引名
Seq_in_index: 该列在索引中的位置,当索引为单列时,值为1,复合索引时,该值为每列在索引定义中的顺序。
Column_name: 定义索引的列字段
Collation: 表示列以何种顺序存储在索引中,“A”表示升序,NULL表无分类
Cardinality: 索引中唯一值的估计值。
Sub_part: 列中被编入索引的字符的数量,若列只是部分被编入索引,则该列的值为被编入的索引的字符的数目,若整列被编入,该列值为NULL
Packed: 指示关键字如何被压缩,没有则为NULL
Null: 索引列中是否包含NULL,有则为YES,不包含则为NO
Index_type: 索引类型,有BTREE、FULLTEXT(全文索引)、HASH、RTREE(B树的高维形式)
Comment: 注释
Index_comment: 索引注释也可以使用 show index from 表名 来查询索引,还可以用前面的desc查看索引

删除索引
方法一:删除主键索引
alter table 表名 drop primary key因为一个表只有一个主键索引,所以删除主键索引时不用指明索引名。
方法二:删除非主键索引
- alter table 表名 drop index 索引名
- drop index 索引名 on 表名

-
相关阅读:
Redis Lua Java 随机编号 用户编号
STM32:串口发送/接收HEX数据包代码篇(内含:实物图接线图+代码部分+个人笔记)
vue3学习——封装菜单栏
3.前端开发就业前景
@ConditionalOnProperty注解作用
利尔达蓝牙空调接收器方案助力打造更舒适的公路生活
springboot本地启动多个模块报错:Address already in use: JVM_Bind
第20集丨生活处处皆修行
LeetCode刷题(python版)——Topic58最后一个单词的长度
【MySQL】索引的作用及知识储备
- 原文地址:https://blog.csdn.net/u014801954/article/details/132800008
