-
基于Pandas+余弦相似度+大数据智能护肤品推荐系统——机器学习算法应用(含Python工程源码)+数据集

前言
本项目结合了Pandas数据处理工具和机器学习技术,旨在构建一个智能的护肤品推荐系统。该系统不仅会考虑用户的肤质特征,还会考虑过敏反应等因素,并筛选出相互禁忌的产品,以便为不确定如何选择护肤品的用户提供个性化的推荐。
首先,项目会收集用户的肤质信息,包括肤质类型(如干性、油性、混合性等)以及特殊过敏或敏感反应(例如对某些成分的过敏)。这些信息将作为推荐系统的输入。
接下来,项目会利用Pandas进行数据处理和分析,以便理解不同护肤产品的成分、特性和功效。这包括产品的成分列表、适用肤质类型、适用场景等信息。
然后,项目会应用机器学习与余弦相似度算法,基于用户的肤质和过敏特征,以及不同护肤产品的属性,来建立一个推荐模型。这个模型将考虑用户的需求和限制条件,例如对某些成分的过敏反应,从而为用户推荐适合他们的护肤产品。
在推荐产品时,系统还会考虑相互禁忌的产品组合。这意味着系统将避免推荐那些在使用时可能引发不良反应或效果相互抵消的产品。
最终,用户将获得一套适合他们肤质和需求的护肤产品建议。这些建议可能包括洁面产品、护肤霜、面膜等,以满足用户的整体护肤需求。
总的来说,项目旨在帮助用户更好地选择护肤产品,考虑了他们的肤质特征、过敏反应和产品相互作用等因素。这种护肤品推荐系统可以提高用户的护肤体验,确保他们选择的产品是安全有效的。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
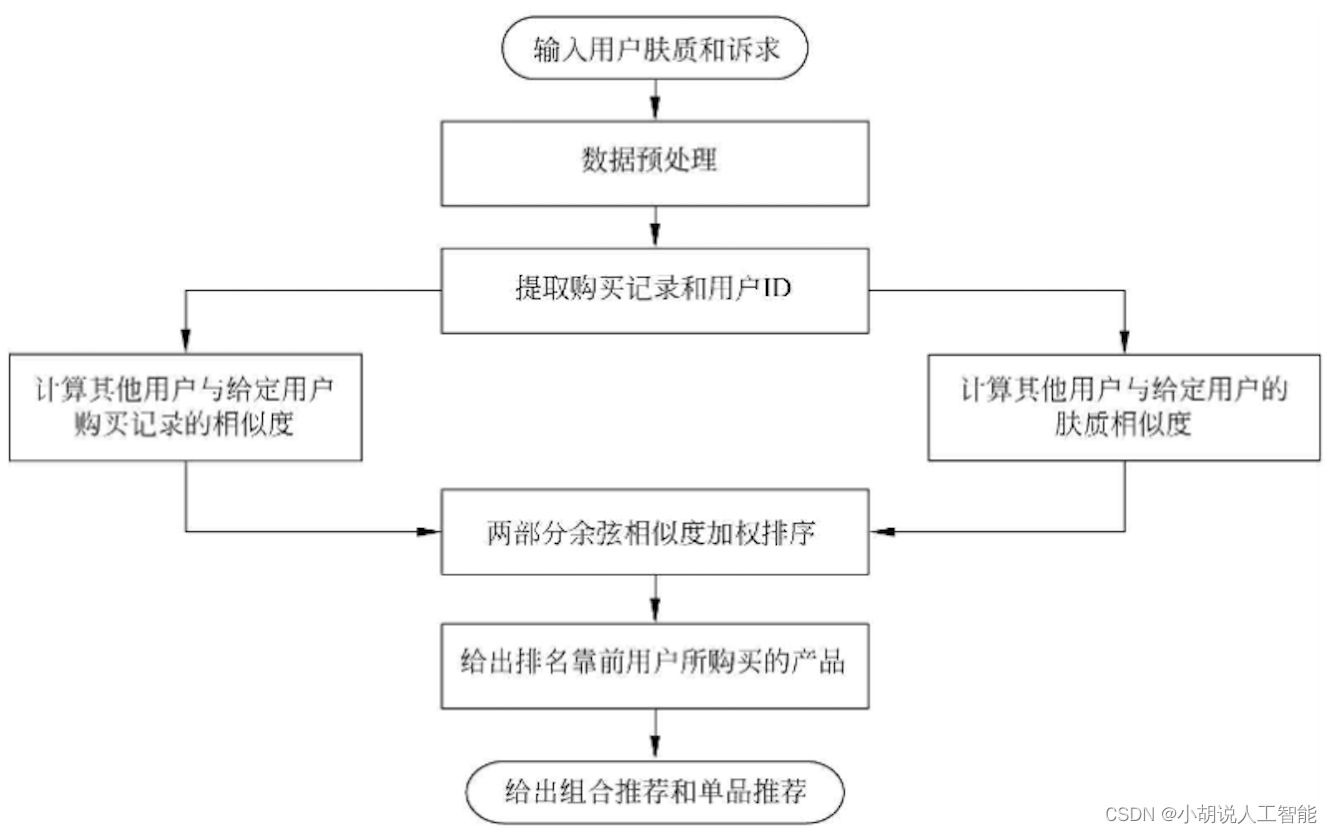
系统流程图
系统流程如图所示。
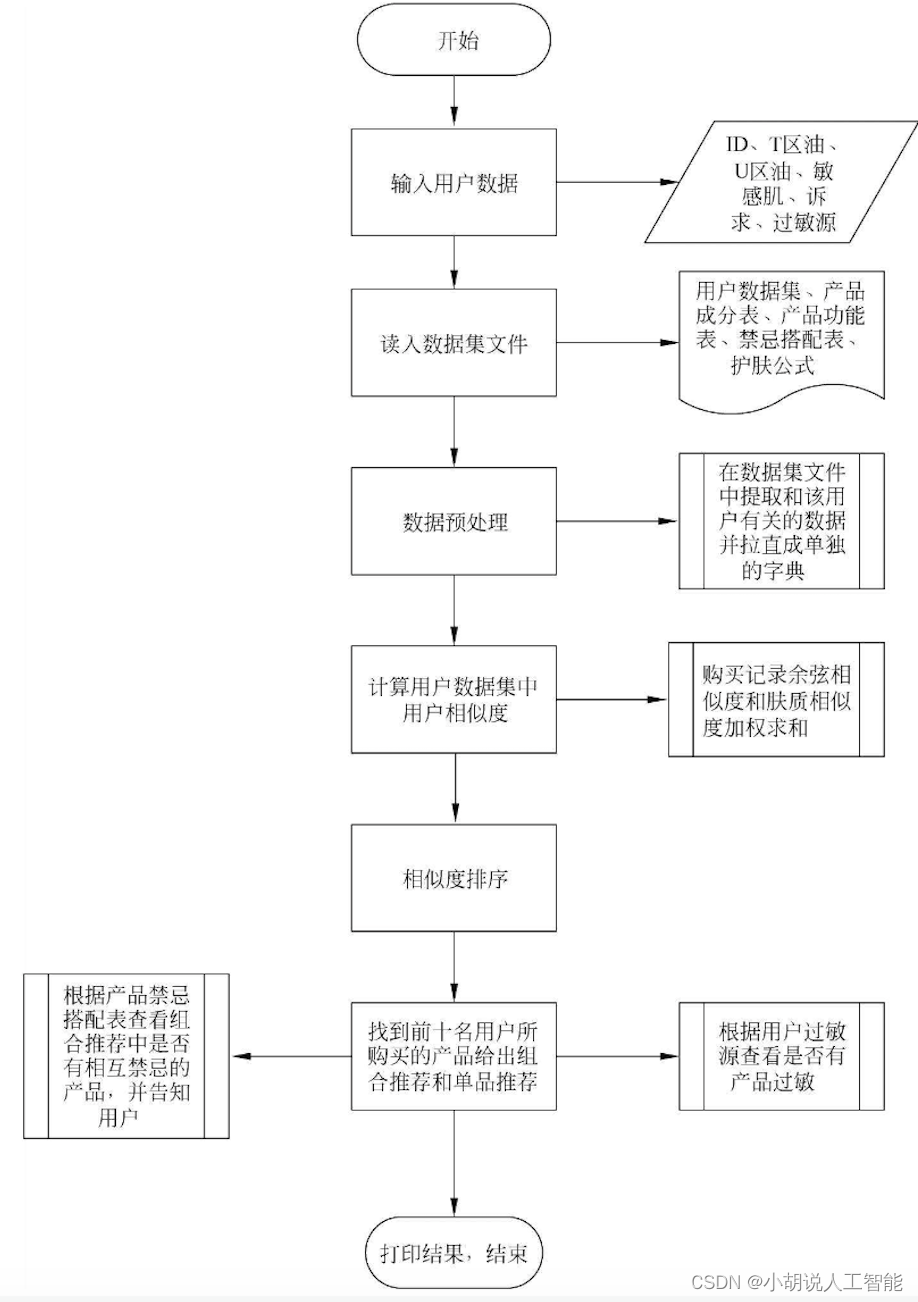
运行环境
本部分包括 Python 环境和Pycharm 环境。
Python环境
需要Python 3.6及以上配置,在Windows环境下推荐下载Anaconda完成Python所需环境的配置,下载地址为https://www.anaconda.com/,也可下载虚拟机在Linux环境下运行代码。
各数据包环境如下:
import pandas import numpy import math import itertools- 1
- 2
- 3
- 4
Pycharm 环境
PyCharm下载地址为http://www.jetbrains.com/pycharm/download/#section=windows,进入网站后单击Comminity版本下的DOWNLOAD下载安装包,下载完成后安装。单击Create New Project创建新的项目文件,Location为存放工程的路径,单击project附近的三角符号,可以看到PyCharm已经自动获取Python 3.6,单击create完成。
模块实现
本项目包括4个模块:文件读入、推荐算法、应用模块和测试调用函数,下面分别给出各模块的功能介绍及相关代码。
1. 文件读入
本部分主要是读取用户的肤质特征、诉求以及过敏成分,同时导入5个数据集文件,分别是用户数据集、产品主要成分表、功能表、禁忌搭配成分表、护肤公式。
相关代码如下:
#文件读入部分 user = pd.Series({'wxid':'o_2phwQNVY9WYG1p0B1z0E_d-lHM', 'T区油': 1, 'U区油': 1, '敏感肌': 1, '诉求': '祛痘', '过敏成分': '烟酰胺'}) pro = pd.read_csv(r'df_product1046.csv', encoding='ANSI') df_component = pd.read_csv("df_component.csv",encoding='gb18030') df_fake = pd.read_csv("df_fake.csv",encoding="gb18030") fformula = pd.read_csv("Formula_formatting.csv",encoding="gb18030") ingredient_banned = pd.read_excel('ingredient_banned_to_number.xlsx', encoding="gb18030")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2. 推荐算法
导入数据后,进行推荐算法计算相似度。
1)数据预处理
提取有用的数据加工成合适的格式方便调用。
相关代码如下:
def __init__(self, df_fake, sub2_product): self.frame = df_fake #调用文件 self.product = sub2_product #产品表 #self.screened_product_path = r'D:\work\dataclinic\fake\df_product1046.csv' #读取预筛选后的产品集 #self._init_data() #def _init_data(self): #self.frame = pd.read_csv(self.frame_path) #self.product = pd.read_csv(self.product_path,encoding='GB18030') #self.screened_product_path = pd.read_csv(self.product_path,encoding='GB18030') def screen(self, need): #数据预处理 self.frame = self.frame[(self.frame['诉求'].isin([need]))] def vec_purchase(self): #提取购买记录并拉直 g = self.frame['购买记录'] g2 = self.frame['购买记录2'] g3 = self.frame['购买记录3'] wxid = list(self.frame['wechatid']) s = pd.Series(wxid, index=g) s2 = pd.Series(wxid, index=g2) s3 = pd.Series(wxid, index=g3) pin = pd.concat([s, s2, s3], axis=0) #数据合并 dict_pin = {'wechatid': pin.values, '购买记录': pin.index, } df2 = pd.DataFrame(dict_pin) #拉直后的dataframe(wechat id :购买记录) self.frame_p = df2[~(df2['购买记录'].isin([-1]))]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2)计算相似度
处理数据格式后计算相似度。相似度由用户购买记录和肤质相似度组成,最后加权求和。
相关代码如下:
#计算肤质向量(T区油、U区油、敏感肌、痘痘肌)的余弦相似度 def cosine_skin(self, target_user_id, other_user_id): #数据预处理 target_skin = [] other_skin = [] cols = ['T区油', 'U区油', '敏感肌', '痘痘肌'] for col in cols: target_skin.append((self.frame[self.frame['wechatid'] == target_user_id][col].values[0]) * 2 - 1) #标准化可能 for col in cols: other_skin.append((self.frame[self.frame['wechatid'] == other_user_id][col].values[0]) * 2 - 1) #计算余弦相似度 nume=sum(np.multiply(np.array(target_skin),np.array(other_skin)))#分子 deno=sum(np.array(target_skin)** 2)*sum(np.array(other_skin)** 2)#分母 cosine = nume / math.sqrt(deno) #值为1 return cosine #计算购买记录余弦相似度 def cosine_purchase(self, target_user_id, other_user_id): target_items = self.frame_p[self.frame_p['wechatid'] == target_user_id]['购买记录'] items = self.frame_p[self.frame_p['wechatid'] == other_user_id]['购买记录'] union_len = len(set(target_items) & set(items)) if union_len == 0: return 0.0 product = len(target_items) * len(items) cosine = union_len / math.sqrt(product) return cosine #计算加权平均相似度并排序 def get_top_n_users(self, target_user_id, top_n): #提取其他所有用户 other_users_id = [i for i in set(self.frame_p['wechatid']) if i != target_user_id] #计算与其他用户的购买相似度 sim_purchase_list = [self.cosine_purchase(target_user_id, other_user_id) for other_user_id in other_users_id] #计算与其他用户的肤质相似度 sim_skin_list = [self.cosine_skin(target_user_id, other_user_id) for other_user_id in other_users_id] #加权平均(各占50%) sim_list = list((np.array(sim_purchase_list) + np.array(sim_skin_list)) / 2) sim_list = sorted(zip(other_users_id, sim_list), key=lambda x: x[1], reverse=True) return sim_list[:top_n]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
3)排序并提取产品
相关代码如下:
#提取候选产品表 def get_candidates_items(self, target_user_id): target_user_item = set(self.frame_p[self.frame_p['wechatid'] == target_user_id]['购买记录']) other_user_item = set(self.frame_p[self.frame_p['wechatid'] != target_user_id]['购买记录']) candidates_item = other_user_item - target_user_item #寻找候选推荐品标准:目标用户没有使用过的(必要性存疑) candidates_item = list(candidates_item & set(self.product['ind'].values)) #候选推荐品必须属于上一步筛选出的项目(目前使用全产品表代替筛选后产品表) return candidates_item #计算用户兴趣程度 def get_top_n_items(self, top_n_users, candidates_items, top_n): top_n_user_data = [self.frame_p[self.frame_p['wechatid'] == k] for k, _ in top_n_users] interest_list = [] for ind in candidates_items: tmp = [] for user_data in top_n_user_data: if ind in user_data['购买记录'].values: tmp.append(1) else: tmp.append(0) interest = sum([top_n_users[i][1] * tmp[i] for i in range(len(top_n_users))]) interest_list.append((ind, interest)) interest_list = sorted(interest_list, key=lambda x: x[1], reverse=True) return interest_list[:top_n] #输入wxid,需求默认推荐产品数为10 输出有序推荐产品 def calculate(self, target_user): top_n = self.product.shape[0] target_user_id = target_user.wxid need = target_user.诉求 self.screen(need) self.vec_purchase() top_n_users=self.get_top_n_users(target_user_id, top_n) candidates_items = self.get_candidates_items(target_user_id) top_n_items = self.get_top_n_items(top_n_users, candidates_items, top_n) #重构数据格式返回完整推荐产品信息 productlist = [top_n_items[i][0] for i in range(len(top_n_items))] product_rec = self.product[(self.product['ind'].isin(productlist))] product_rec['InterestRate'] = [top_n_items[i][1] for i in range(len(top_n_items))] return product_rec- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
4)组合推荐算法
相关代码如下:
#组合推荐算法 class CombRating(): def __init__(self,user, pro_withrate, fformula): self.user = user self.product = pro_withrate self.fformula=fformula #第一个for 找到用户的诉求是哪一种,要求四个属性全部对上 #第二个for 找到组合中应当有的产品类型,水、乳、霜、祛痘凝胶、洁面 def find_kind(self): #print(self.fformula) n_formula = self.fformula.shape[0] for i in range(n_formula): if (self.user.诉求 == self.fformula.诉求[i]) \ and (self.user.T区油 == self.fformula.T区油[i]) \ and (self.user.U区油 == self.fformula.U区油[i]) \ and (self.user.敏感肌 == self.fformula.敏感肌[i]): i_formula = i break #此处使用总共的产品种类解决数字问题 #寻找第一个是产品类型的列并记录此前经过的列数 form_list = [] total_pro_type = ['水', '乳', '霜', '祛痘凝胶', '洁面'] type_number = 0 for j in range(len(self.fformula.columns)): if self.fformula.columns[j] in total_pro_type: break else: type_number = type_number + 1 #再找到所有需要的产品种类 for j in range(type_number, len(self.fformula.columns)): if (self.fformula.loc[i_formula][j] == 1): form_list.append(self.fformula.columns[j]) return form_list def outer_multiple(self, form_list): ddict={} for i in range(len(form_list)): ddict[form_list[i]] = list(self.product[self.product.剂型 == form_list[i]].ind) #print(ddict) dd = [] for i in itertools.product(*ddict.values()): dd.append(i) comb_pd = pd.DataFrame(dd) #为DF的每一列添加名称 column_name = [] for i in range(len(comb_pd.columns)): column_name.append('产品'+str(i+1)) comb_pd.columns = column_name #返回的是产品编号ind一列的值 return comb_pd- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
3. 应用模块
根据已经计算并排序的用户,找到产品并加工好合适的数据格式,按照护肤公式中的种类进行排列组合,同时考虑单品过敏和组合推荐的相互禁忌情况。若有相互禁忌和过敏情况在最后输出让用户知情。
1)得到最终产品
相关代码如下:
#整合 class Recommendation(): def __init__(self, user, pro, df_component, df_fake, fformula, ingredient_banned): self.user = user self.pro = pro self.df_component = df_component self.df_fake = df_fake self.fformula = fformula self.ingredient_banned = ingredient_banned #诉求筛选得到sub1 def sub1_product(self): #通过用户筛选需求成分,返回筛选后的产品列表sub1 pro = self.pro user = self.user #T区条件筛选 if user['T区油'] == 1: for index in pro.index: if pro.loc[index, 'typeT区:油'] != 1: pro = pro.drop(index=index) elif user['T区油'] == 0: for index in pro.index: if pro.loc[index, 'typeT区:干'] != 1: pro = pro.drop(index=index) #U区条件筛选 if user['U区油'] == 1: for index in pro.index: if pro.loc[index, 'typeU区:油'] != 1: pro = pro.drop(index=index) elif user['U区油'] == 0: for index in pro.index: if pro.loc[index, 'typeU区:干'] != 1: pro = pro.drop(index=index) #敏感肌筛选 if user['敏感肌'] == 1: for index in pro.index: if pro.loc[index, '敏感'] != 1: pro = pro.drop(index=index) #诉求筛选美白/祛痘 if user['诉求'] == '祛痘': for index in pro.index: if pro.loc[index, '诉求'] != '祛痘': pro = pro.drop(index=index) elif user['诉求'] == '美白': for index in pro.index: if pro.loc[index, '诉求'] != '美白': pro = pro.drop(index=index) pro = pro.reset_index(drop=True) sub1 = pro return sub1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
2)筛选过敏物质
得到产品后筛选产品中与用户过敏的物质成分。
相关代码如下:
#过敏物质筛选,得到sub2 def sub2_product(self): #通过用户过敏成分筛选产品,得到sub2 user = self.user product = self.sub1_product() #1从user信息中提取过敏成分 allergic_cpnt = user['过敏成分'] #2选出含有过敏成分的产品 product_allergic = [] for i in range(0, len(df_component.成分)): if df_component.成分[i] == allergic_cpnt: product_allergic.append(df_component.ind[i]) #3-1 生成sub2产品表,筛除含有过敏成分的产品,返回sub2产品表 sub2_product = pd.DataFrame() sub2_product = product[:] for i in range(0, len(product.ind)): if i in product_allergic: sub2_product.drop(index=[i], inplace=True) sub2 = sub2_product return sub2 #输入两个产品的ind 返回过敏信息用于后面函数的调用 def is_pro_component_banned(self, pro1_ind, pro2_ind): #输入两个产品的ind 产品成分表、成分禁忌表、总产品表 #根据产品ind判断是否过敏,并且返回禁忌成分的字符串 df_component = self.df_component ingredient_banned = self.ingredient_banned pro = self.pro- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
3)筛选相互禁忌的产品
组合推荐一套可能出现两种产品之间有成分相互禁忌,所以要告知用户,让他们自已决断。
相关代码如下:
#对禁忌表进行预处理 ingredient_name = ingredient_banned.columns ingredient_banned= ingredient_banned.drop(ingredient_banned.columns[0], axis=1) #删除第一列 ingredient_banned.index = ingredient_name #重置横标签为产品名 #找出两个产品中所有的成分存入两个列表 pro1_component = [] pro2_component = [] for index in range(len(df_component.index)): if df_component.loc[index, 'ind'] == pro1_ind: pro1_component.append(df_component.loc[index, '成分']) elif df_component.loc[index, 'ind'] == pro2_ind: pro2_component.append(df_component.loc[index, '成分']) #print(pro1_component, pro2_component) #寻找是否冲突,并且记录成分、产品这一版先用字符串作为返回值 banned_record = '' for com1 in pro1_component: for com2 in pro2_component: if (com1 in ingredient_banned.index) and (com2 in ingredient_banned.index): if ingredient_banned.loc[com1, com2] == 2: li1 = list(pro[pro.ind == pro1_ind].typenickname) li1 = ''.join(li1) li2 = list(pro[pro.ind == pro2_ind].typenickname) li2 = ''.join(li2) banned_record = banned_record + '产品' + li1 + '与产品' + li2 + '相互禁忌' + '禁忌成分为' + com1 + '与' + com2 elif ingredient_banned.loc[com1, com2] == 1: li1 = list(pro[pro.ind == pro1_ind].typenickname) li1 = ''.join(li1) li2 = list(pro[pro.ind == pro2_ind].typenickname) li2 = ''.join(li2) banned_record = banned_record + '产品' + li1 + '与产品' + li2 + '相互禁忌' + '禁忌成分为' + com1 + '与' + com2 return banned_record #输入推荐组合 调用前方函数返回最后有备注的组合推荐 def is_comb_banned(self, comb_pd): #传入信息为 is_pro_component_banned 的参数加上推荐组合的df #增加df一列,用以存贮禁忌信息,数据形式为str #对每个组合进行循环,创建banned_info列表 #对每两个产品调用 is_pro_component_banned #若存在禁忌信息加入上述str,将banned_info加入df的新列 df_component = self.df_component ingredient_banned = self.ingredient_banned self.pro = self.pro comb_pd['禁忌搭配情况'] = None #对每个组合 for index in range(len(comb_pd.index)): total_banned = '' #对每两个产品 for pro1 in range(len(comb_pd.columns)): for pro2 in range(pro1, len(comb_pd.columns)): banned = self.is_pro_component_banned(comb_pd.ix[index, pro1], comb_pd.ix[index, pro2]) if banned != '': total_banned = total_banned + banned #将得到此列的禁忌信息加入整个pd并返回 comb_pd.loc[index, '禁忌搭配情况'] = total_banned #comb_pd.to_csv('result') return comb_pd- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
4)输出单品推荐与组合推荐
根据之前计算的产品信息,输出单品推荐和组合推荐,并告知过敏与禁忌成分。
相关代码如下:
#单品推荐 def single_rec(self): user = self.user #调用User类进行推荐 sub2 = self.sub2_product() U1 = UserCF(self.df_fake, sub2) items = U1.calculate(self.user) return items #复合推荐缺少护肤公式 def combine_rec(self): user = self.user #调用User类先进行单品推荐 sub2 = self.sub2_product() U1 = UserCF(self.df_fake, sub2) items = U1.calculate(self.user) #再调用Comb类进行复合推荐 C1 = CombRating(user, items, self.fformula) ddd = C1.outer_multiple(C1.find_kind()) #再调用禁忌类对此进行处理 return self.is_comb_banned(ddd)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4. 测试调用函数
调用之前的所有模块,并且输出单品推荐和组合推荐。
相关代码如下:
#测试代码1 R1 = Recommendation(user, pro, df_component, df_fake, fformula, ingredient_banned) #print(R1.combine_rec(), R1.single_rec()) a = R1.combine_rec() b = R1.single_rec() a.to_csv("file1_1") b.to_csv("file2_1")- 1
- 2
- 3
- 4
- 5
- 6
- 7
系统测试
将数据代入模型进行测试,得到如图1和图2所示的测试效果。
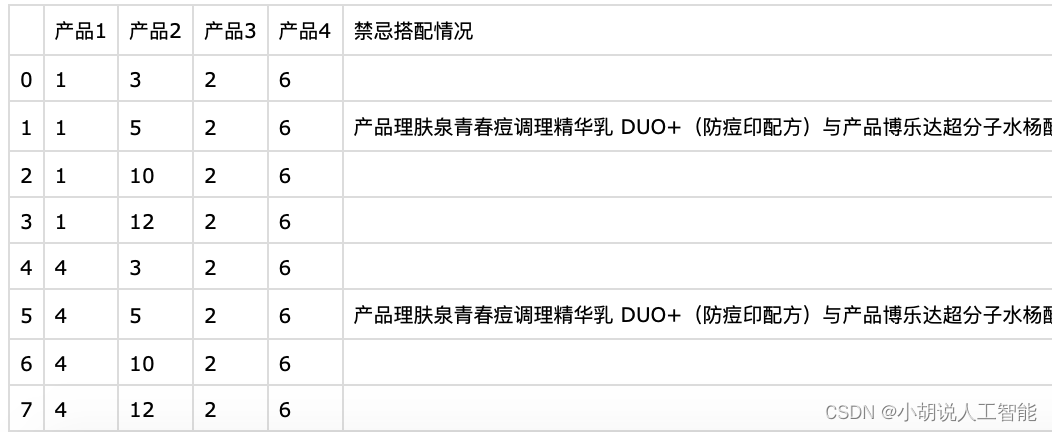
图1 组合推荐结果 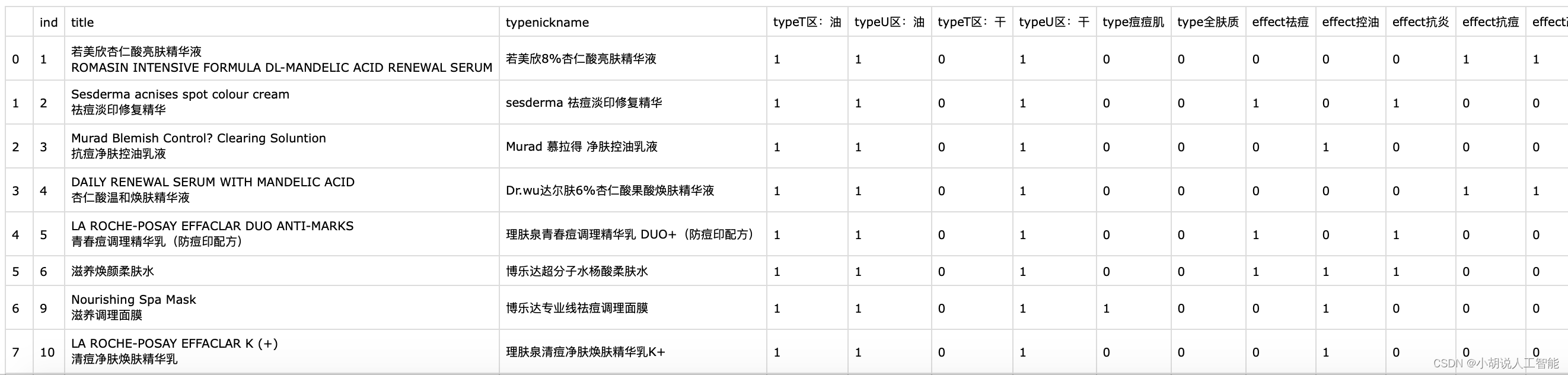 图2 单品推荐结果 工程源代码下载
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。 -
相关阅读:
c#装饰器模式详解
Js逆向教程-06js逆向断点的种类及介绍
python面向对象的编程---类
第一章:Class文件结构
【uniapp】小程序中input输入框的placeholder-class不生效以及解决办法
ECC(SM2) 简介及 C# 和 js 实现【加密知多少系列】
【均值漂移】mean-shift算法详解
CocosCreator3.8研究笔记(十三)CocosCreator 音频资源理解
第13集丨忠于内心是强大内心的第一步
前端研习录(08)——文档流
- 原文地址:https://blog.csdn.net/qq_31136513/article/details/132872128
