-
(二十五)大数据实战——kafka集群及Kafka-Eagle控制台安装与部署
前言
本节内容我们主要介绍一下搭建kafka集群以及kafka集群的一个web客户端组件Kafka-Eagle的部署安装,使用的kafka版本是kafka_2.12-3.0.0。在搭建kafka集群之前,我们要预先搭建好zookeeper集群,这里作者默认zookeeper的集群环境已经搭建完成,可参考作者往期博客内容。新版本的kafka集群分为俩种搭建方式,一种依赖zookeeper,一种使用Kraft模式,本节内容我们主要介绍zookeeper模式的kafka集群搭建部署。
正文
①kafka高可用集群部署规划
kafka高可用集群部署规划 hadoop101 hadoop102 hadoop103 zookeeper zookeeper zookeeper kafka kafka kafka Kafka-Eagle ②上传kafka安装包到hadoop101服务器/opt/software目录

③解压kafka安装包到/opt/module目录
- 命令:tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module

④在/opt/module/kafka_2.12-3.0.0/config目录下修改kafka配置文件server.properties
- server.properties 配置文件位置

- 配置brokerid
broker.id=0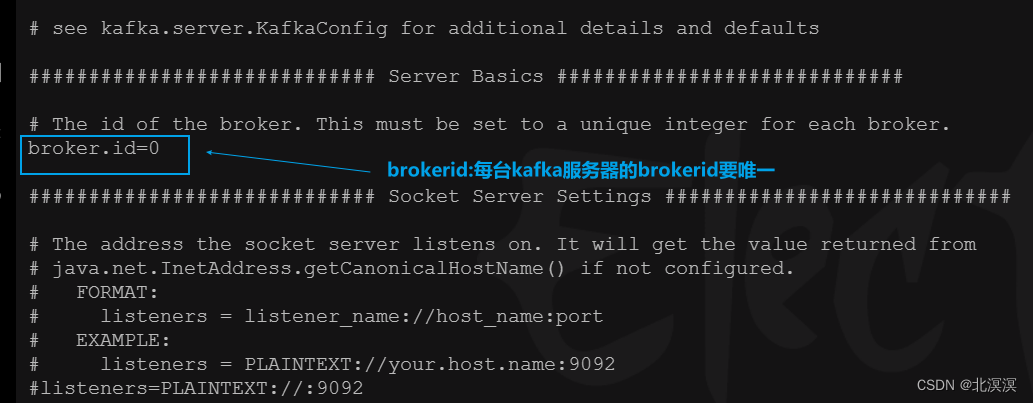
- 配置kafka数据存储目录,这里存储到kafka安装目录/opt/module/kafka_2.12-3.0.0/data下
log.dirs=/opt/module/kafka_2.12-3.0.0/data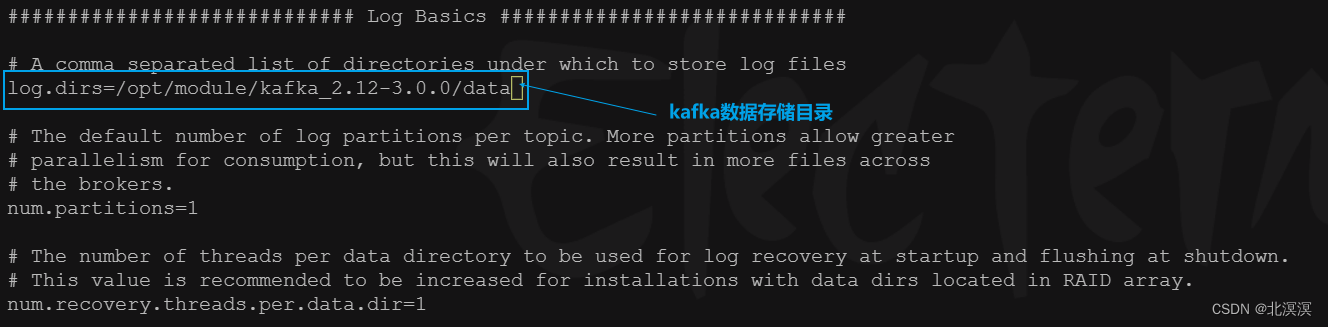
- 配置zookeeper访问路径
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka
⑤分发kafka安装包到hadoop102和hadoop103服务器,并修改其brokerid配置
- 分发kafka安装包

- 修改hadoop102的server.properties 配置文件的brokerid

- 修改hadoop103的server.properties 配置文件的brokerid

⑥配置kafka环境变量
- 在hadoop101服务器/etc/profile.d/my_env.sh 文件中增加 kafka环境变量配置

- 分发环境变量配置到hadoop102和hadoop103服务器

- 使环境变量生效



⑦将kafak安装包授权给hadoop用户,使用root用户启动kafka可以跳过此步骤
- 命令:
sudo chown -R hadoop:hadoop /opt/module/kafka_2.12-3.0.0/


⑦使用hadoop用户启动zookeeper集群服务和kafak集群服务
- 启动zookeeper集群

- 启动kafka集群
bin/kafka-server-start.sh -daemon config/server.properties


- 查看日志,验证kafka集群是否已经启动成功

⑧使用脚本启停kafka集群
- mykafka.sh集群启停脚本
- #! /bin/bash
- case $1 in
- "start"){
- for i in hadoop101 hadoop102 hadoop103
- do
- echo " --------启动 $i Kafka-------"
- ssh $i "/opt/module/kafka_2.12-3.0.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.12-3.0.0/config/server.properties"
- done
- };;
- "status"){
- for i in hadoop101 hadoop102 hadoop103
- do
- echo =============== $i ===============
- ssh $i jps
- done
- };;
- "stop"){
- for i in hadoop101 hadoop102 hadoop103
- do
- echo " --------停止 $i Kafka-------"
- ssh $i "/opt/module/kafka_2.12-3.0.0/bin/kafka-server-stop.sh "
- done
- };;
- esac
- 在kafka的bin目录下创建mykafka.sh启停脚本

- 测试脚本

⑨安装kafka客户端工具Kafka-Eagle监控
- 上传Kafka-Eagle安装包到hadoop101服务器

- 解压Kafka-Eagle安装包到/opt/module目录


- 进入Kafka-Eagle安装目录,修改system-config.properties配置文件

- 修改zookeeper连接地址
- efak.zk.cluster.alias=cluster1
- cluster1.zk.list=hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka

- 修改kafka offset storage的存储目录
cluster1.efak.offset.storage=kafka
- 修改数据库连接配置
- efak.driver=com.mysql.cj.jdbc.Driver
- efak.url=jdbc:mysql://hadoop101:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
- efak.username=root
- efak.password=root

- 添加Kafka-Eagle监控环境变量配置

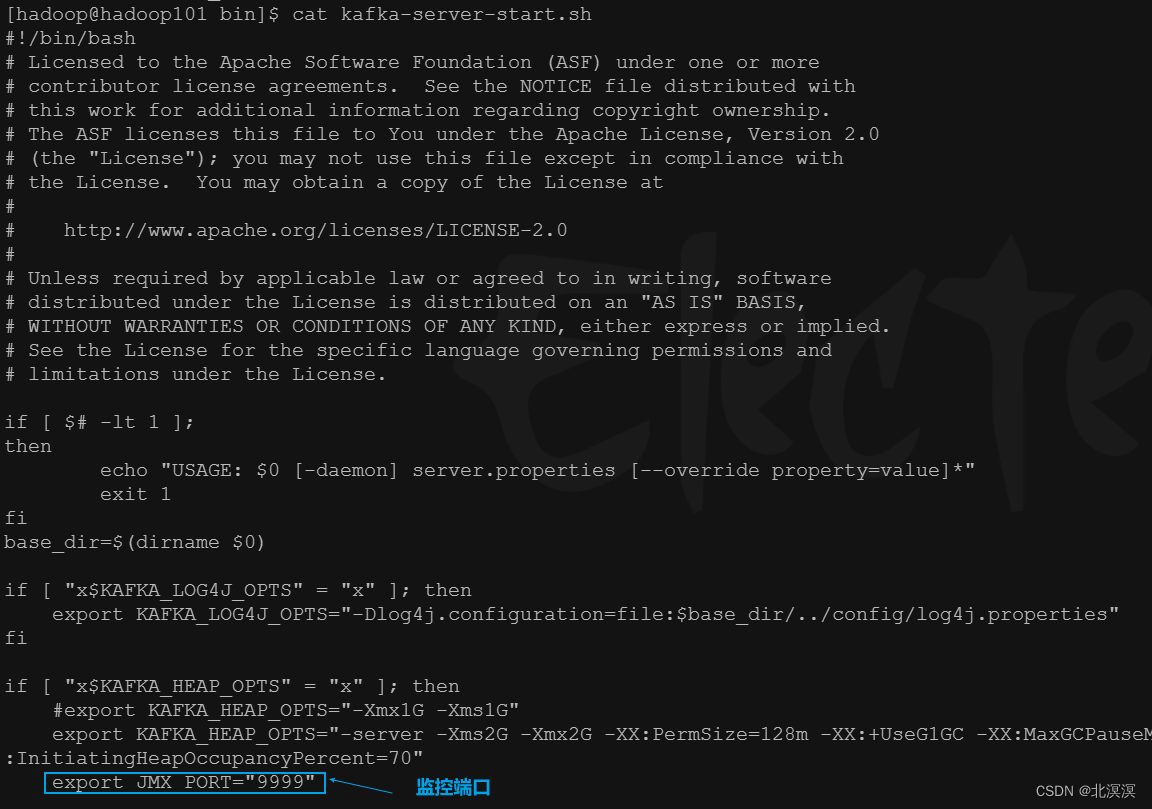
- 修改kafka服务器启动参数

- export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
- export JMX_PORT="9999"
- 分发kafka-server-start.sh启动脚本

- 重启kafka

- 启动Kafka-Eagle

- 访问Kafka-Eagle



结语
至此,关于kafka集群及Kafka-Eagle控制台安装与部署到这里就结束了,我们下期见。。。。。。
-
相关阅读:
在有序数组中插入一个数
Servlet生命周期
【中秋国庆不断更】OpenHarmony组件内状态变量使用:@State装饰器
Rockland丨Rockland重组 VhH 抗体解决方案
【JVM】类加载器 Bootstrap、Extension、Application、User Define 以及 双亲委派
二级指针 杂记
【主题课】9.10教师节电子贺卡制作
【论文阅读】Optimal Auctions Through Deep Learning
分布式计算实验1 负载均衡
Pandas数据分析:快速图表可视化各类操作详解+实例代码(三)
- 原文地址:https://blog.csdn.net/yprufeng/article/details/132729403
