-
LeetCode 138. Copy List with Random Pointer【链表,DFS,迭代,哈希表】中等
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章中,我不仅会讲解多种解题思路及其优化,还会用多种编程语言实现题解,涉及到通用解法时更将归纳总结出相应的算法模板。
为了方便在PC上运行调试、分享代码文件,我还建立了相关的仓库:https://github.com/memcpy0/LeetCode-Conquest。在这一仓库中,你不仅可以看到LeetCode原题链接、题解代码、题解文章链接、同类题目归纳、通用解法总结等,还可以看到原题出现频率和相关企业等重要信息。如果有其他优选题解,还可以一同分享给他人。
由于本系列文章的内容随时可能发生更新变动,欢迎关注和收藏征服LeetCode系列文章目录一文以作备忘。
给你一个长度为
n的链表,每个节点包含一个额外增加的随机指针random,该指针可以指向链表中的任何节点或空节点。构造这个链表的 深拷贝。 深拷贝应该正好由
n个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的next指针和random指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。例如,如果原链表中有
X和Y两个节点,其中X.random --> Y。那么在复制链表中对应的两个节点x和y,同样有x.random --> y。返回复制链表的头节点。
用一个由
n个节点组成的链表来表示输入/输出中的链表。每个节点用一个[val, random_index]表示:val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点
head作为传入参数。示例 1:
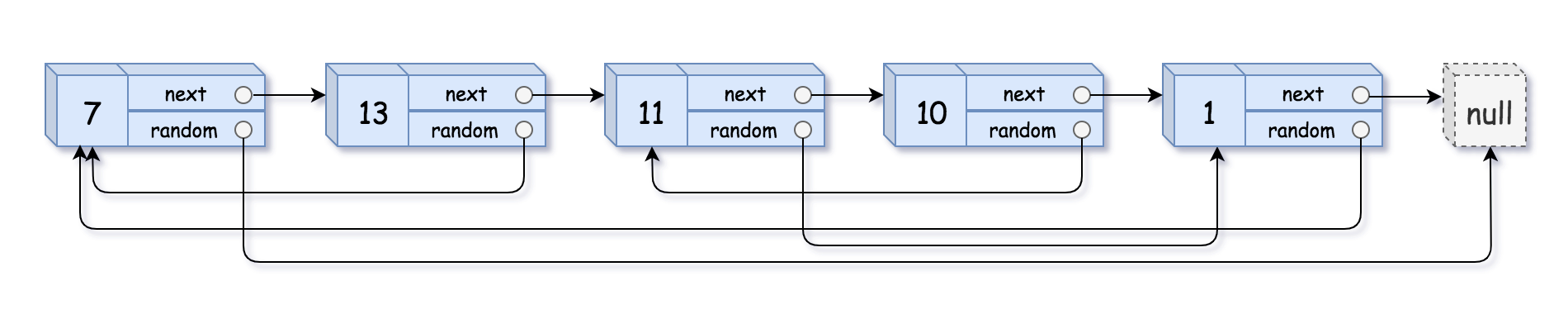
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]- 1
- 2
示例 2:

输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]- 1
- 2
示例 3:

输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]- 1
- 2
提示:
0 <= n <= 1000-104 <= Node.val <= 10^4Node.random为null或指向链表中的节点。
类似题目:
本题要求我们对一个特殊的链表进行深拷贝。如果是普通链表,我们可以直接按照遍历的顺序创建链表节点。而本题中因为随机指针的存在,当我们拷贝节点时,「当前节点的随机指针指向的节点」可能还没创建,因此我们需要变换思路。
解法1 递归+哈希表
一个可行方案是,我们利用回溯的方式,让每个节点的拷贝操作相互独立。对于当前节点,我们首先要进行拷贝,然后我们进行「当前节点的后继节点」和「当前节点的随机指针指向的节点」拷贝,拷贝完成后将创建的新节点的指针返回,即可完成当前节点的两指针的赋值。
具体地,我们用哈希表记录每一个节点对应新节点的创建情况。遍历该链表的过程中,我们检查「当前节点的后继节点」和「当前节点的随机指针指向的节点」的创建情况。如果这两个节点中的任何一个节点的新节点没有被创建,我们都立刻递归地进行创建。当我们拷贝完成,回溯到当前层时,我们即可完成当前节点的指针赋值。
注意一个节点可能被多个其他节点指向,因此我们可能递归地多次尝试拷贝某个节点,为了防止重复拷贝,我们需要首先检查当前节点是否被拷贝过,如果已经拷贝过,我们可以直接从哈希表中取出拷贝后的节点的指针并返回即可。
在实际代码中,我们需要特别判断给定节点为空节点的情况。
class Solution { public: unordered_map<Node*, Node*> cachedNode; Node* copyRandomList(Node* head) { if (head == nullptr) return nullptr; if (!cachedNode.count(head)) { Node* headNew = new Node(head->val); cachedNode[head] = headNew; headNew->next = copyRandomList(head->next); headNew->random = copyRandomList(head->random); } return cachedNode[head]; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
复杂度分析:
- 时间复杂度: O ( n ) O(n) O(n) ,其中 n n n 是链表的长度。对于每个节点,我们至多访问其「后继节点」和「随机指针指向的节点」各一次,均摊每个点至多被访问两次。
- 空间复杂度: O ( n ) O(n) O(n) ,其中 n n n 是链表的长度。为哈希表的空间开销。
解法2 迭代+哈希表
先用一个循环把新旧链表对应的两个结点捆绑在一个二元组里,然后再用一个循环完成对新链表每个结点的 n e x t next next 域和 r a n d o m random random 域的赋值:
class Solution { public: Node* copyRandomList(Node* head) { if (head == nullptr) return nullptr; unordered_map<Node*, Node*> cachedNode; Node* cur = head; while (cur) { cachedNode[cur] = new Node(cur->val); cur = cur->next; } cur = head; while (cur) { cachedNode[cur]->next = cachedNode[cur->next]; cachedNode[cur]->random = cachedNode[cur->random]; cur = cur->next; } return cachedNode[head]; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
复杂度分析:
- 时间复杂度: O ( n ) O(n) O(n) ,其中 n n n 是链表的长度。
- 空间复杂度: O ( n ) O(n) O(n) ,其中 n n n 是链表的长度。为哈希表的空间开销。
解法3 迭代 + 节点拆分
注意到方法一、二需要使用哈希表记录每一个节点对应新节点的创建情况,而我们可以使用一个小技巧来省去哈希表的空间。
- 首先将该链表中每一个节点拆分为两个相连的节点,例如对于链表 A → B → C A \rightarrow B \rightarrow C A→B→C ,我们可以将其拆分为 A → A ′ → B → B ′ → C → C ′ A \rightarrow A' \rightarrow B \rightarrow B' \rightarrow C \rightarrow C' A→A′→B→B′→C→C′ 。对于任意一个原节点 S S S ,其拷贝节点 S ′ S' S′ 即为其后继节点。
- 这样,我们可以直接找到「每一个拷贝节点 S ′ S' S′ 的随机指针」应当指向的节点,即为其「原节点 S S S 的随机指针指向的节点 T T T 」的后继节点 T ′ T' T′ 。需要注意原节点的随机指针可能为空,我们需要特别判断这种情况。
- 当完成了拷贝节点的随机指针的赋值,我们只需将这个链表按照原节点与拷贝节点的种类进行拆分即可,只需要遍历一次。同样需要注意最后一个拷贝节点的后继节点为空,我们需要特别判断这种情况。
class Solution { public: Node* copyRandomList(Node* head) { if (head == nullptr) return nullptr; for (Node* node = head; node; node = node->next->next) { Node* nodeNew = new Node(node->val); nodeNew->next = node->next; node->next = nodeNew; } for (Node* node = head; node; node = node->next->next) { Node* nodeNew = node->next; nodeNew->random = node->random ? node->random->next : nullptr; } Node* headNew = head->next; for (Node* node = head; node; node = node->next) { Node* nodeNew = node->next; node->next = node->next->next; nodeNew->next = nodeNew->next ? nodeNew->next->next : nullptr; } return headNew; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
复杂度分析:
- 时间复杂度: O ( n ) O(n) O(n) ,其中 n n n 是链表的长度。如果在计算拷贝节点的随机指针的同时计算其后继指针,只需遍历两次(好像需要修改原链表)。
- 空间复杂度: O ( 1 ) O(1) O(1) 。注意返回值不计入空间复杂度。
-
相关阅读:
【C#实战】控制台游戏 勇士斗恶龙(3)——营救公主以及结束界面
Framework 为何被称为 Android 开发者必修?
智慧气象解决方案-最新全套文件
RocketMQ 分布式事务消息实战指南:确保数据一致性的关键设计
10步开启SAFe敏捷发布列车
python实现科研通定时自动签到
关于linux 双网卡能上外网却ping 不通局域网的问题
docker套娃实践(待续)
Tuxera NTFS2023破解版苹果电脑磁盘读写工具
华为手机安卓扫描安装包apk在哪
- 原文地址:https://blog.csdn.net/myRealization/article/details/132691931
