-
采用BeautifulSoup&&pqQuery&&xpath三种方法爬取电影详情页
采用三个框架BeautifulSoup&&pqQuery&&xpath,爬取知名的电影网页
主要是想体验这三种框架爬同一个网页的不同。
当然具体的不同我也说不清道不明 只能是体验了一把
以下代码都是本人亲自撸
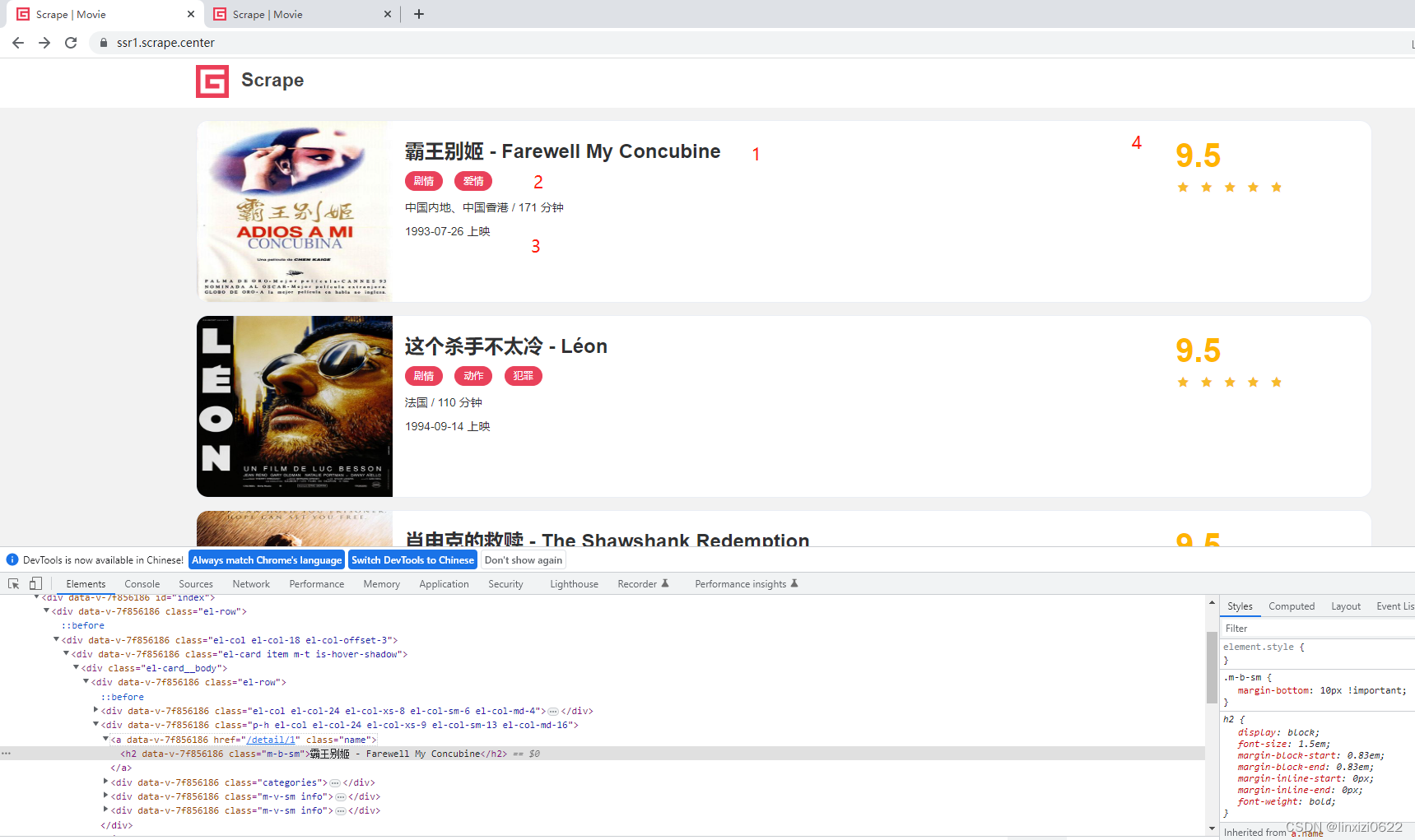
如图所示,四个位置。分别爬取 电影名字 -> 电影类别 -> 上映时间 -> 电影评分
以及点击电影名称获取特定电影的电影详情页面,如下图所示

- BeautifulSoup
- def save_demo_bs4():
- """
- :return: 采用BeautifulSoup 框架爬取单页中每部电影的名称, 类别, 评分, 上映时间等信息
- """
- url = 'https://ssr1.scrape.center'
- import re
- from bs4 import BeautifulSoup
- html = requests.get(url).text
- soup = BeautifulSoup(html, 'lxml')
- dict = []
- ret = soup.find_all(class_=re.compile("el-card item m-t is-hover-shadow")) # 找到所有的class属性为当前属性的文本
- for ret_ in ret:
- dict_ = {}
- title_ = ret_.find_all(class_=re.compile('name'))
- xiangqing_url = url + title_[0].attrs['href'] # 得到单页中每部电影的详情页面
- title_ = [i.text.replace('\n', "") for i in title_][0]
- categories_ = ret_.find_all(class_=re.compile('categories'))
- sy_date_ = ret_.find_all(class_=re.compile('m-v-sm info'))
- pingfen_ = ret_.find_all(class_=re.compile('score m-t-md m-b-n-sm'))
- pingfen_ = [i.string.replace('\n', '').replace(' ', '') for i in pingfen_][0]
- dict_['标题'] = title_
- categories_ = [i.text.replace('\n', ' ') for i in categories_]
- dict_['类别'] = categories_
- sy_date_ = [i.text.replace('\n', '') for i in sy_date_][1]
- dict_['上映时间'] = sy_date_
- dict_['评分'] = float(pingfen_)
- xiangqin_html = requests.get(xiangqing_url).text
- soup_xiangqin = BeautifulSoup(xiangqin_html, 'lxml')
- ret__ = soup_xiangqin.find_all(class_=re.compile("drama")) # 找到所有的class属性为当前属性的文本
- for x in ret__:
- for idx, y in enumerate(x.children):
- if idx == 2:
- xiangqing = y.text.replace('\n', '').replace(' ', '')
- dict_['电影详情'] = xiangqing
- dict.append(dict_)
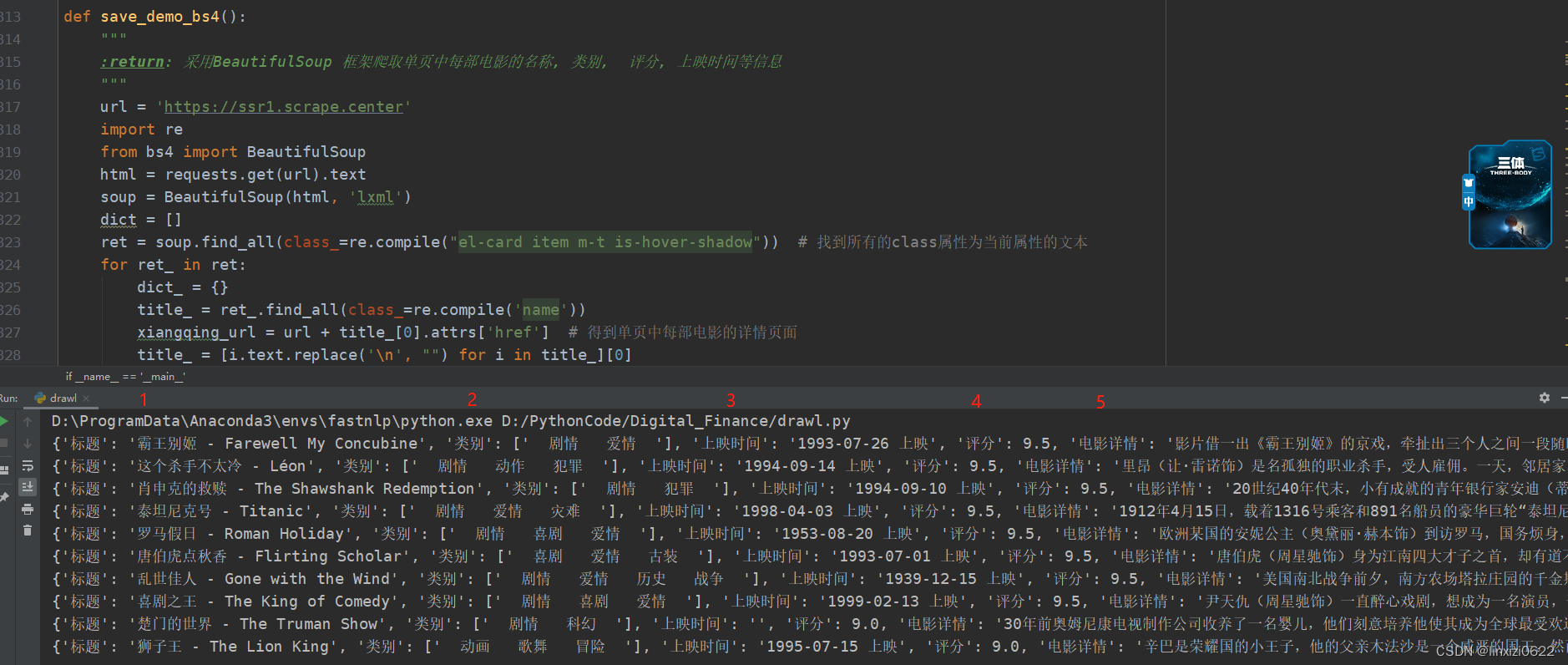
代码的运行效果图如下
2. XPATH
- def save_demo_xpath():
- """
- :return: 采用xpath框架爬取单页中每部电影的名称, 类别, 评分, 上映时间等信息
- """
- url = 'https://ssr1.scrape.center'
- import requests
- from lxml import etree
- html = requests.get(url).text
- html = etree.HTML(html)
- title_xxpath = '//*[@id="index"]/div[1]/div[1]/div[{page}]/div/div/div[2]/a/h2'
- title_xxpath = '{page}'
- dict = []
- for i in range(10):
- dict_ = {}
- title_xxpath = '//*[@id="index"]/div[1]/div[1]/div[{page}]/div/div/div[2]/a/h2'.format(page=i + 1)
- title = html.xpath(title_xxpath)
- title_ = [i.text for i in title][0]
- category_xxpath = '//*[@id="index"]/div[1]/div[1]/div[{page}]/div/div/div[2]/div[1]'.format(page=i + 1)
- category_ = html.xpath(category_xxpath)
- category_ = [i.xpath('./button/span/text()') for i in category_][0]
- sy_date_xxpath = '//*[@id="index"]/div[1]/div[1]/div[{page}]/div/div/div[2]/div[2]/span[3]'.format(page=i + 1)
- sy_date_ = html.xpath(sy_date_xxpath)
- sy_date_ = [i.text for i in sy_date_][0]
- pingfen_xxpath = '//*[@id="index"]/div[1]/div[1]/div[{page}]/div/div/div[3]/p[1]'.format(page=i + 1)
- pingfen_ = html.xpath(pingfen_xxpath)
- pingfen_ = [i.text.replace("\n", "").replace(" ", "") for i in pingfen_][0]
- dict_['类别'] = category_
- dict_['标题'] = title_
- dict_['上映时间'] = sy_date_
- dict_['评分'] = pingfen_
- xiangqing_url_ = html.xpath('//*[@id="index"]/div[1]/div[1]/div[{page}]/div/div/div[2]'.format(page=i+1))
- xiangqing_url_ = url + [i.xpath('./a/@href') for i in xiangqing_url_][0][0]
- html_xiangqin = requests.get(xiangqing_url_).text
- html_xiangqin = etree.HTML(html_xiangqin)
- xiangqing = html_xiangqin.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[4]/p')
- dict_['电影详情'] = [i.text.replace('\n', '').replace(' ', '') for i in xiangqing][0]
- dict.append(dict_)
- print(dict_)
- print(dict)
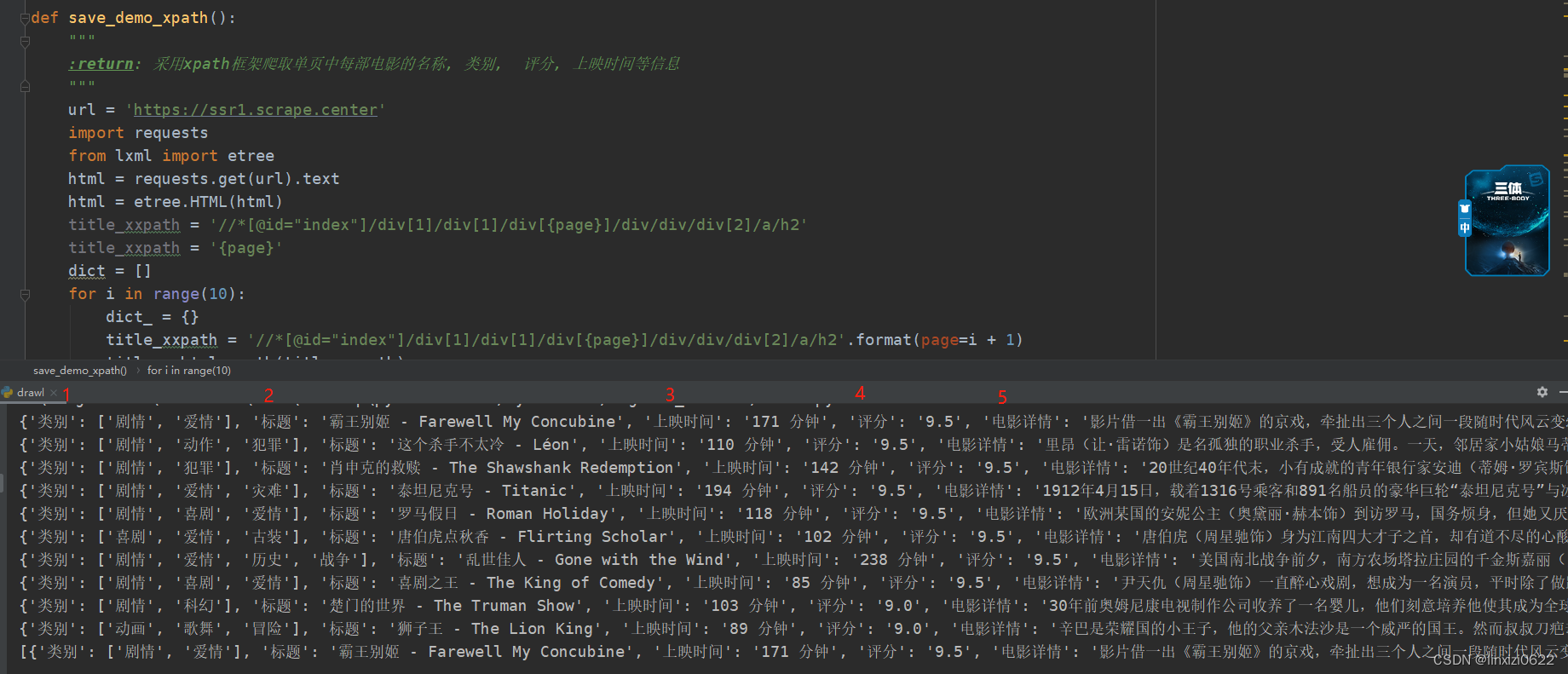
代码效果图
3.pqQuery
- def save_demo_pq():
- """
- :return: 采用pyQuery 框架爬取单页中每部电影的名称, 类别, 评分, 上映时间等信息
- """
- url = 'https://ssr1.scrape.center'
- from pyquery import PyQuery as pq
- import requests
- html = requests.get(url).text
- doc = pq(html)
- items = doc('.el-card .el-card__body .el-row ').items()
- dict = []
- for item in items:
- dict_ = {}
- title = item.find('a > h2').text()
- categories = item.find('.categories .el-button span').items()
- cate_list = [i.text() for i in categories]
- sy_date = item.find('.m-v-sm.info')
- sy_date = [i.text() for i in sy_date('.m-v-sm span').items()][-1]
- pingfen = item.find('.el-col .score').items()
- pingfen = [i.text() for i in pingfen][0]
- dict_['评分'] = float(pingfen)
- dict_['类别'] = cate_list
- dict_['标题'] = title
- dict_['上映时间'] = str(sy_date).replace("上映", "").replace(" ", "")
- dict.append(dict_)
- xiangqing_utl_ = item.find('a').attr('href')
- xiangqing_utl_ = url + xiangqing_utl_
- html_xiangqing = requests.get(xiangqing_utl_).text
- doc_xiangqing = pq(html_xiangqing)
- xiangqing = [i.find('p').text() for i in doc_xiangqing.find('.drama').items()][0]
- dict_['影片详情'] = xiangqing
- print(dict_)
- print(dict)
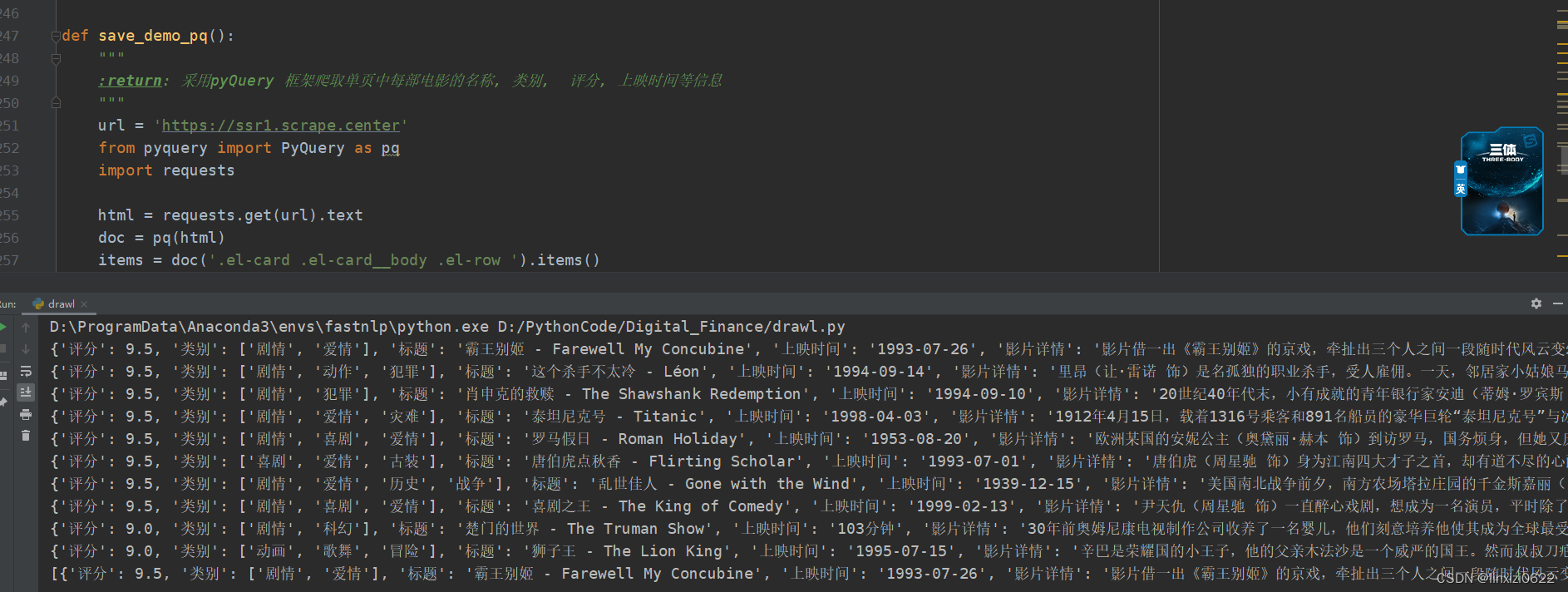
代码效果图
综合来讲 我觉得pqQuery 用起来更顺手一点
完毕
-
相关阅读:
【ICer的脚本练习】通过perl脚本来检查仿真log的结果
2022年企业数字化技术应用 5 大趋势丨三叠云
HTML <meta> 标签常见属性及应用场景
微电网鲁棒性研究(Matlab代码实现)
量化风控的规则开发,如何更好做策略定规则,抓坏人
Day705.Tomcat拒绝连接原因分析及网络优化 -深入拆解 Tomcat & Jetty
分布式调用与高并发处理(二)| Dubbo
使用easyexcel实现Excel数据导入以及数据库数据导出成Excel
设计模式原则——单一职责原则(SPS)
飞机降落(dfs全排列)
- 原文地址:https://blog.csdn.net/linxizi0622/article/details/132779377
