-
【AI】机器学习——线性模型(逻辑斯蒂回归)
- 逻辑回归输出的是实例属于每个类别的似然概率,似然概率最大的类别就是分类结果
- 在一定条件下,逻辑回归模型与朴素贝叶斯分类器等价
- 多分类问题可以通过多次二分类或者Softmax回归解决
4.1 线性分类模型
目标:用判别模型解决分类问题
4.1.1 示例
图像分类
图像分类数据集:ImageNet

- 基于WordNet的层次结构
建模

流程:
将图片的 像素 × 像素 × 通道数 像素\times 像素\times 通道数 像素×像素×通道数 作为输入向量,学习到每个类别的模型 f c f_c fc 参数 ω c \omega_c ωc
假设将图像的向量张成4维向量 x i x_i xi ,问题为三分类问题,有三组模型 f c = ω c T ⋅ x + b c f_c=\omega_c^T\cdot x+b_c fc=ωcT⋅x+bc
将新的图片数据 x i x_i xi 分别代入三个模型,投票选出得分高的作为分类结果
涉及问题

- 图像分类
- 图像分类+目标定位
- 目标检测:图片中所有物体都要检测出来
- 实例分割:像素级图像分类
文本分类
-
垃圾邮件过滤
-
文档归类
-
情感分类

建模
将样本 x x x 从文本形式转为向量形式
词袋模型(Bag-of-Words,BoW)

4.1.2 线性分类模型
通过引入 单调可微 函数 g ( ⋅ ) g(\cdot) g(⋅) ,线性回归模型可以推广为 y = g − 1 ( w T x ) y=g^{-1}(w^Tx) y=g−1(wTx) ,进而将线性回归模型预测值与分类任务的离散标记联系起来
g ( f ( x ; ω ) ) = { 1 f ( x ; ω ) > 0 0 f ( x ; ω ) < 0 g(f(x;\omega))=g(f(x;ω))={10f(x;ω)>0f(x;ω)<0{ 1 f ( x ; ω ) > 0 0 f ( x ; ω ) < 0 -
f ( x ; ω ) f(x;\omega) f(x;ω) 判别函数
f ( x ; ω ) = 0 f(x;\omega)=0 f(x;ω)=0 的点组成一个 分割超平面 ,决策边界/决策平面
-
线性分类模型=线性判别函数 f ( x ) f(x) f(x) +线性决策边界 g ( ⋅ ) g(\cdot) g(⋅)
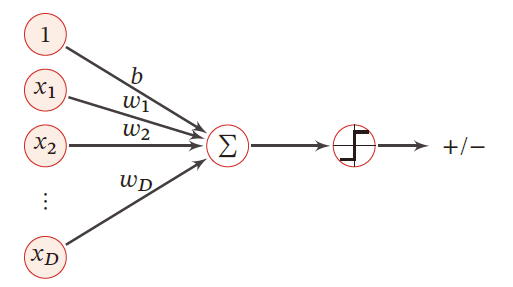
二分类问题
在简单的 二分类问题 中,分类的标记可以抽象为 0 0 0 和 1 1 1 ,因而线性回归中的实值输出需要映射为二进制的结果
训练集: { ( x i , y i ) } i = 1 N , x i ∈ R n \{(x_i,y_i)\}_{i=1}^{N},x_i\in R^{n} {(xi,yi)}i=1N,xi∈Rn
二分类问题: y i ∈ { 0 , 1 } y_i\in \{0,1\} yi∈{0,1}
模型
g ( f ( x ; ω ) ) = { 1 f ( x ; ω ) > 0 0 f ( x ; ω ) < 0 g(f(x;\omega))=g(f(x;ω))={10f(x;ω)>0f(x;ω)<0{ 1 f ( x ; ω ) > 0 0 f ( x ; ω ) < 0
损失函数:
L 01 [ y , g ( f ( x ; ω ) ) ] = I [ y ≠ g ( f ( x ; ω ) ) ] L 01 [ y , g ( f ( x ; ω ) ) ] = I [ y f ( x ; ω ) < 0 ] \mathcal{L}_{01}[y,g(f(x;\omega))]=I[y\neq g(f(x;\omega))]\\ \mathcal{L}_{01}[y,g(f(x;\omega))]=I[yf(x;\omega)<0] L01[y,g(f(x;ω))]=I[y=g(f(x;ω))]L01[y,g(f(x;ω))]=I[yf(x;ω)<0]多分类问题
训练集: { ( x i , y i ) } i = 1 N , x i ∈ R n \{(x_i,y_i)\}_{i=1}^{N},x_i\in R^{n} {(xi,yi)}i=1N,xi∈Rn
二分类问题: y i ∈ { 0 , ⋯ , C } , C > 2 y_i\in \{0,\cdots,C\},C>2 yi∈{0,⋯,C},C>2
模型:

-
一对其余:将多分类问题转换成 C C C 个 “一对其余”的二分类问题;用投票的方式选出所属类
需要 C C C 个判别函数
如:训练 ω 1 \omega_1 ω1 对其余的判别函数时,训练集分为 ω 1 ; ω 2 + ω 3 \omega_1;\omega_2+\omega_3 ω1;ω2+ω3
-
一对一:每两个类别间生成一个分割超平面
转换为 ( C 2 ) = C ( C − 1 ) 2 \left(
\right)=\frac{C(C-1)}{2} (C2)=2C(C−1) 个 “一对一”二分类问题C 2 用投票的方式选出所属类
在类别数较多时,需要建立的分类器数量较多
-
argmax 方式:改进的一对其余方式需要 C C C 个判别函数
y = arg max c = 1 C f c ( x ; ω c ) y=\arg\max\limits_{c=1}^Cf_c(x;\omega_c) y=argc=1maxCfc(x;ωc)
哪个类别得分高,分为哪个类
“一对其余”方式和“一对一”方式都存在一个缺陷:特征空间中会存在一些难以确定类别的区域,而 argmax 方式很好地解决了这个问题
-
等效为直接将逻辑回归应用在每个类别上,对每个类别建立一个二分类器
如果输出的类别标记数为 m m m ,就可以得到 m m m 个针对不同标记的二分类逻辑回归模型,对一个实例的分类结果就是这 m m m 个分类函数中输出值最大的那个
-
对一个实例执行分类需要多次使用逻辑回归算法,效率低下
线性分类模型
二分类问题 —— g ( f ( x ) ) g(f(x)) g(f(x))
- 逻辑斯蒂回归
- 感知器
- 支持向量机
多分类问题
- Softmax回归 —— a r g m a x f ( x ) argmax f(x) argmaxf(x)
区别在于使用了不同的损失函数
4.1.3 二分类模型的损失函数
为明确定义损失函数,进而可以通过最优化算法求解, g ( ⋅ ) g(\cdot) g(⋅) 需要保证单调可微,其前提就是连续。
将分类问题看做条件概率估计问题
-
引入非线性函数 g g g 来预测类别标签的条件概率 p ( y = c ∣ x ) p(y=c\vert x) p(y=c∣x)
判别函数 f f f :线性函数, f ( x ; ω ) = ω T ⋅ x ∈ R f(x;\omega)=\omega^T\cdot x\in R f(x;ω)=ωT⋅x∈R
激活函数 g g g :把线性函数的值域从实数区间挤压到了 ( 0 , 1 ) (0,1) (0,1) 之间,可以用来表示概率
4.2 Logistic 回归
4.2.1 对数几率函数
在 Logistic 回归中,激活函数为 sigmod型 对数几率函数
σ ( z ) = 1 1 + e − z = 1 1 + e − w T x \sigma(z)=\frac{1}{1+e^{-z}}=\frac{1}{1+e^{-w^Tx}} σ(z)=1+e−z1=1+e−wTx1
-
对数几率函数能够将线性回归从负无穷到正无穷的输出范围压缩到 ( 0 , 1 ) (0,1) (0,1) 之间
-
当线性回归结果是 z = 0 z=0 z=0 时,逻辑回归的结果是 σ ( z ) = 0.5 \sigma(z)=0.5 σ(z)=0.5 ,这可以是做一个分界点
当 z > 0 z>0 z>0 ,则 σ ( z ) > 0.5 \sigma(z)>0.5 σ(z)>0.5 ,此时逻辑回归的结果就被判为正例
当 z < 0 z<0 z<0 ,则 σ ( z ) < 0.5 \sigma(z)<0.5 σ(z)<0.5 ,此时逻辑回归的结果就被判为负例
几率
如果将对数几率函数的结果 σ ( z ) \sigma(z) σ(z) 视为样本 x x x 作为正例的可能性 P ( y = 1 ∣ x ) P(y=1\vert x) P(y=1∣x),则 1 − σ ( z ) 1-\sigma(z) 1−σ(z) 就是其作为反例的可能性 P ( y = 0 ∣ x ) P(y=0\vert x) P(y=0∣x) ,两者比值 0 < σ ( z ) 1 − σ ( z ) < ∞ 0<\frac{\sigma(z)}{1-\sigma(z)}<\infty 0<1−σ(z)σ(z)<∞ ,称为 几率 。
- = 1 =1 =1,则说明概率相等
- > 1 >1 >1 ,则说明 σ ( z ) \sigma(z) σ(z) 的概率大,分为1类
- < 1 <1 <1 ,则说明 1 − σ ( z ) 1-\sigma(z) 1−σ(z) 的概率大,为0类
对 几率 取对数,可得到
l n σ ( z ) 1 − σ ( z ) = w T x ln\frac{\sigma(z)}{1-\sigma(z)}=w^Tx ln1−σ(z)σ(z)=wTx- 线性回归的结果以对数几率的形式出现的
4.2.2 逻辑回归模型
输入: x = { x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) } ∈ X ⊆ R m x=\{x^{(1)},x^{(2)},\cdots,x^{(m)}\}\in \mathcal{X}\subseteq R^m x={x(1),x(2),⋯,x(m)}∈X⊆Rm ;
-
需对输入的特征向量进行归一化
若特征数值过大,样本会落在 sigmod 的饱和区,无法对 x x x 进行正确分类
输出: Y ∈ { 0 , 1 } Y\in \{0,1\} Y∈{0,1}
逻辑回归模型为 条件概率表示的判别模型
σ ( z ) = p ( y = 1 ∣ x ) = 1 1 + e − w T x = e w T x 1 + e w T x 1 − σ ( z ) = p ( y = 0 ∣ x ) = e − w T x 1 + e − w T x = 1 1 + e w T x \sigma(z)=p(y=1\vert x)=\frac{1}{1+e^{-w^Tx}}=\frac{e^{w^Tx}}{1+e^{w^Tx}}\\ 1-\sigma(z)=p(y=0\vert x)=\frac{e^{-w^Tx}}{1+e^{-w^Tx}}=\frac{1}{1+e^{w^Tx}} σ(z)=p(y=1∣x)=1+e−wTx1=1+ewTxewTx1−σ(z)=p(y=0∣x)=1+e−wTxe−wTx=1+ewTx1
- ω = { ω ( 0 ) , ω ( 1 ) , ω ( 2 ) , ⋯ , ω ( m ) } ∈ R m + 1 \omega=\{\omega^{(0)},\omega^{(1)},\omega^{(2)},\cdots,\omega^{(m)}\}\in R^{m+1} ω={ω(0),ω(1),ω(2),⋯,ω(m)}∈Rm+1
对于给定的实例,逻辑回归模型比较两个条件概率值的大小,并将实例划分到概率较大的分类中
4.2.3 损失函数
对于一个样本 ( x , y ∗ ) (x,y^*) (x,y∗) ,其真实条件概率为
p r ( y = 1 ∣ x ) = y ∗ p r ( y = 0 ∣ x ) = 1 − y ∗ p_r(y=1\vert x)=y^*\\ p_r(y=0\vert x)=1-y^* pr(y=1∣x)=y∗pr(y=0∣x)=1−y∗- eg:
y
∗
=
0
y^*=0
y∗=0
p r ( y = 1 ∣ x ) = 0 = 1 − y ∗ , p r ( y = 0 ∣ x ) = 1 = y ∗ p_r(y=1\vert x)=0=1-y^*,p_r(y=0\vert x)=1=y^*\\ pr(y=1∣x)=0=1−y∗,pr(y=0∣x)=1=y∗
如何衡量两个条件分布的差异?——交叉熵
H ( p r , p ω ) = − ∑ k = 0 1 p r log p ω = − [ p r ( y ∗ = 1 ∣ x ) log p ω ( y = 1 ∣ x ) + p r ( y ∗ = 0 ∣ x ) log p ω ( y = 0 ∣ x ) ] = − [ y ∗ log p ω ( y = 1 ∣ x ) + ( 1 − y ∗ ) log p ω ( y = 0 ∣ x ) ] = − [ y ∗ log σ ( z ) + ( 1 − y ∗ ) log ( 1 − σ ( z ) ) ]H(pr,pω)=−k=0∑1prlogpω=−[pr(y∗=1∣x)logpω(y=1∣x)+pr(y∗=0∣x)logpω(y=0∣x)]=−[y∗logpω(y=1∣x)+(1−y∗)logpω(y=0∣x)]=−[y∗logσ(z)+(1−y∗)log(1−σ(z))]H ( p r , p ω ) = − ∑ k = 0 1 p r log p ω = − [ p r ( y ∗ = 1 | x ) log p ω ( y = 1 | x ) + p r ( y ∗ = 0 | x ) log p ω ( y = 0 | x ) ] = − [ y ∗ log p ω ( y = 1 | x ) + ( 1 − y ∗ ) log p ω ( y = 0 | x ) ] = − [ y ∗ log σ ( z ) + ( 1 − y ∗ ) log ( 1 − σ ( z ) ) ]
对于交叉熵损失函数,模型在训练集的风险函数为
R = − 1 N ∑ i = 1 N [ y i log σ ( z i ) + ( 1 − y i ) log ( 1 − σ ( z i ) ) ] \mathcal{R}=-\frac{1}{N}\sum\limits_{i=1}^N\left[y_i\log \sigma(z_i)+(1-y_i)\log (1-\sigma(z_i))\right] R=−N1i=1∑N[yilogσ(zi)+(1−yi)log(1−σ(zi))]-
若不理解交叉熵,可以理解为
I ln P I\ln P IlnP 表示预测正确的部分,对于预测结果来说,越大越好;对于损失函数来说,越小越好,所以添加负号
对于损失函数的估计有极大似然估计
梯度为
∂ R ∂ ω = − 1 N ∑ i = 1 N [ y i ∂ ∂ ω log σ ( z i ) + ( 1 − y i ) ∂ ∂ ω log ( 1 − σ ( z i ) ) ] = − 1 N ∑ i = 1 N { y i [ 1 − σ ( z i ) ] x i − ( 1 − y i ) σ ( z i ) x i } = − 1 N ∑ i = 1 N x i [ y i − σ ( z i ) ]∂ω∂R=−N1i=1∑N[yi∂ω∂logσ(zi)+(1−yi)∂ω∂log(1−σ(zi))]=−N1i=1∑N{yi[1−σ(zi)]xi−(1−yi)σ(zi)xi}=−N1i=1∑Nxi[yi−σ(zi)]∂ R ∂ ω = − 1 N ∑ i = 1 N [ y i ∂ ∂ ω log σ ( z i ) + ( 1 − y i ) ∂ ∂ ω log ( 1 − σ ( z i ) ) ] = − 1 N ∑ i = 1 N { y i [ 1 − σ ( z i ) ] x i − ( 1 − y i ) σ ( z i ) x i } = − 1 N ∑ i = 1 N x i [ y i − σ ( z i ) ]
对于损失函数的最优化,通过梯度下降法/拟牛顿法 ⇒ \Rightarrow ⇒ 数值解
ω [ t + 1 ] ← ω [ t ] − α ∂ R ( ω ) ∂ ω = ω [ t ] + α 1 N ∑ i = 1 N x i [ y i − σ ( z i ) ]ω[t+1]←ω[t]−α∂ω∂R(ω)=ω[t]+αN1i=1∑Nxi[yi−σ(zi)]ω [ t + 1 ] ← ω [ t ] − α ∂ R ( ω ) ∂ ω = ω [ t ] + α 1 N ∑ i = 1 N x i [ y i − σ ( z i ) ] - y i ∗ = 1 y_i^*=1 yi∗=1 ,则 [ y i − σ ( z i ) ] > 0 \left[y_i-\sigma(z_i)\right]>0 [yi−σ(zi)]>0 ,迭代之后 ω [ t + 1 ] > ω [ t ] \omega^{[t+1]}>\omega^{[t]} ω[t+1]>ω[t]
- y i ∗ = 0 y_i^*=0 yi∗=0 ,则 [ y i − σ ( z i ) ] < 0 \left[y_i-\sigma(z_i)\right]<0 [yi−σ(zi)]<0 ,迭代之后 ω [ t + 1 ] < ω [ t ] \omega^{[t+1]}<\omega^{[t]} ω[t+1]<ω[t]
4.2.4 参数求解
假设样本独立同分布
学习时,逻辑回归模型在给定的训练数据集上应用 最大似然估计法 确定模型的参数
- 对于给定的数据 ( x i , y i ) (x_i,y_i) (xi,yi) ,逻辑回归 使每个样本属于其真实标记的概率最大化,以此为依据确定 w w w 的最优值
似然函数可表示为
L ( w ∣ x ) = P ( ω ∣ x ) = x i 独立同分布 ∏ i = 1 n [ p ( y = 1 ∣ x i , w ) ] y i [ 1 − p ( y = 1 ∣ x i , w ) ] 1 − y i L(w\vert x)=P(\omega\vert x)\xlongequal{x_i独立同分布}\prod\limits_{i=1}^n[p(y=1\vert x_i,w)]^{y_i}[1-p(y=1\vert x_i,w)]^{1-y_i} L(w∣x)=P(ω∣x)xi独立同分布i=1∏n[p(y=1∣xi,w)]yi[1−p(y=1∣xi,w)]1−yi取对数后简化运算
ln L ( w ∣ X ) = ∑ i = 1 n { y i ln p ( y = 1 ∣ x i , w ) + ( 1 − y i ) ln [ 1 − p ( y = 1 ∣ x i , w ) ] } \ln L(w\vert X)=\sum\limits_{i=1}^n\left\{y_i\ln p(y=1\vert x_i,w)+(1-y_i)\ln \left[1-p(y=1\vert x_i,w)\right]\right\} lnL(w∣X)=i=1∑n{yilnp(y=1∣xi,w)+(1−yi)ln[1−p(y=1∣xi,w)]}
由于单个样本的标记 y i y_i yi 只能取得0或1,因而上式中的两项中只有一个非零值,代入对数几率,经过化简后可以得到
ln L ( w ∣ X ) = ∑ i = 1 n [ y i ( w T x i ) − ln ( 1 + e w T x i ) ] \ln L(w\vert X)=\sum\limits_{i=1}^n\left[y_i(w^Tx_i)-\ln(1+e^{w^Tx_i})\right] lnL(w∣X)=i=1∑n[yi(wTxi)−ln(1+ewTxi)]
寻找上述函数的最大值就是以对数似然函数为目标函数的最优化问题,通常使用 梯度下降法 或 牛顿法 求解逻辑斯蒂回归策略
后验概率最大化原则 ⟺ \iff ⟺ 期望风险最小化策略
a r g max ω L ( ω ) = a r g max ω ∑ i = 1 n [ y i ( w T x i ) − ln ( 1 + e w T x i ) ] arg\max\limits_{\omega}L(\omega)=arg\max\limits_{\omega}\sum\limits_{i=1}^n\left[y_i(w^Tx_i)-\ln(1+e^{w^Tx_i})\right] argωmaxL(ω)=argωmaxi=1∑n[yi(wTxi)−ln(1+ewTxi)]
基于 ω ^ \hat{\omega} ω^ 得到概率判别模型
{ P ( y = 1 ∣ x ) = e ω ^ T ⋅ x 1 + e ω ^ T ⋅ x P ( y = 0 ∣ x ) = 1 1 + e ω ^ T ⋅ x⎩ ⎨ ⎧P(y=1∣x)=1+eω^T⋅xeω^T⋅xP(y=0∣x)=1+eω^T⋅x1{ P ( y = 1 | x ) = e ω ^ T ⋅ x 1 + e ω ^ T ⋅ x P ( y = 0 | x ) = 1 1 + e ω ^ T ⋅ x 4.2.5 应用:语句情感判断
将一句话映射为向量形式,对每句话进行逻辑斯蒂回归
{ x i : 某个词词频 ω i : 每个词权重 { 正面词 ω i > 0 中性词 ω i = 0 负面词 ω i < 0\end{cases} ⎩ ⎨ ⎧xi:某个词词频ωi:每个词权重⎩ ⎨ ⎧正面词ωi>0中性词ωi=0负面词ωi<0\begin{cases} x_i:某个词词频\\ \omega_i:每个词权重\begin{cases} 正面词\quad \omega_i>0\\ 中性词\quad \omega_i=0\\ 负面词\quad \omega_i<0 \end{cases}
整句话表示为
h = f ( ∑ i = 1 n ω i x i ) = f ( ω T ⋅ x ) h=f(\sum\limits_{i=1}^n\omega_i x_i)=f(\omega^T\cdot x) h=f(i=1∑nωixi)=f(ωT⋅x)
权重的计算
{ 某个词重要性:在本篇大量出现,在其他文章出现较少 t e r m f r e q u e n c y :文档中词频,越大表示越重要 I n v e r s e D o c u m e n t f r e q u e n c y :其他语料库中出现的词频,越小表示其他文档中出现少,当前文档中的词比较重要⎩ ⎨ ⎧某个词重要性:在本篇大量出现,在其他文章出现较少termfrequency:文档中词频,越大表示越重要InverseDocumentfrequency:其他语料库中出现的词频,越小表示其他文档中出现少,当前文档中的词比较重要{ 某 个 词 重 要 性 : 在 本 篇 大 量 出 现 , 在 其 他 文 章 出 现 较 少 t e r m f r e q u e n c y : 文 档 中 词 频 , 越 大 表 示 越 重 要 I n v e r s e D o c u m e n t f r e q u e n c y : 其 他 语 料 库 中 出 现 的 词 频 , 越 小 表 示 其 他 文 档 中 出 现 少 , 当 前 文 档 中 的 词 比 较 重 要 4.2.6 多角度分析逻辑回归
信息论角度
当训练数据集是从所有数据中均匀抽取且数据量较大时,可以 从信息论角度 解释:
对数似然的最大化可以等效为待求模型与最大熵模型之间的KL散度(交叉熵)的最小化。即逻辑回归对参数做出的额外假设是最少的。
数学角度
从 数学角度 看,线性回归与逻辑回归之间的关系在于非线性的对数似然函数
-
从特征空间看,两者的区别在于数据判断边界上的变化
利用回归模型只能得到线性的判定边界;
逻辑回归则在线性回归的基础上,通过对数似然函数的引入使判定边界的形状不再受限于直线
与朴素贝叶斯对比
联系
逻辑回归与朴素贝叶斯都是利用条件概率 P ( Y ∣ X ) P(Y\vert X) P(Y∣X) 完成分类任务,二者在特定条件下可以等效
- 用朴素贝叶斯处理二分类任务时,假设对每个属性
x
i
x_i
xi ,属性条件概率
P
(
X
=
x
i
∣
Y
=
y
k
)
P(X=x_i\vert Y=y_k)
P(X=xi∣Y=yk) 都满足正态分布,且正态分布的标准差与输出标记
Y
Y
Y 无关,则根据贝叶斯定理,后验概率可写成
P ( Y = 0 ∣ X ) = P ( Y = 0 ) ⋅ P ( X ∣ Y = 0 ) P ( Y = 1 ) ⋅ P ( X ∣ Y = 1 ) + P ( Y = 0 ) ⋅ P ( X ∣ Y = 0 ) = 1 1 + e l n P ( Y = 1 ) ⋅ P ( X ∣ Y = 1 ) P ( Y = 0 ) ⋅ P ( X ∣ Y = 0 ) P(Y=0\vert X)=\frac{P(Y=0)\cdot P(X\vert Y=0)}{P(Y=1)\cdot P(X\vert Y=1)+P(Y=0)\cdot P(X\vert Y=0)}\\ =\frac{1}{1+e^{ln\frac{P(Y=1)\cdot P(X\vert Y=1)}{P(Y=0)\cdot P(X\vert Y=0)}}} P(Y=0∣X)=P(Y=1)⋅P(X∣Y=1)+P(Y=0)⋅P(X∣Y=0)P(Y=0)⋅P(X∣Y=0)=1+elnP(Y=0)⋅P(X∣Y=0)P(Y=1)⋅P(X∣Y=1)1
在条件独立性假设的前提下,类条件概率可以表示为属性条件概率的乘积。令先验概率 P ( Y = 0 ) = p 0 P(Y=0)=p_0 P(Y=0)=p0 并将满足正态分布的属性条件概率 P ( X ( i ) ∣ Y = y k ) P(X^{(i)}\vert Y=y_k) P(X(i)∣Y=yk) 代入,可得
P ( Y = 0 ∣ X ) = 1 1 + e l n 1 − p 0 p 0 + ∑ i ( μ i 1 − μ i 0 σ 2 X i + μ i 0 2 − μ i 1 2 2 σ i 2 ) P(Y=0\vert X)=\frac{1}{1+e^{ln\frac{1-p_0}{p_0}+\sum\limits_{i}\left(\frac{\mu_{i1}-\mu_{i0}}{\sigma^2}X_i+\frac{\mu_{i0}^2-\mu_{i1}^2}{2\sigma^2_i}\right)}} P(Y=0∣X)=1+elnp01−p0+i∑(σ2μi1−μi0Xi+2σi2μi02−μi12)1
可见,上式的形式和逻辑回归中条件概率 P ( Y = 0 ∣ X ) P(Y=0\vert X) P(Y=0∣X) 是完全一致的,朴素贝叶斯学习器和逻辑回归模型学习到的是同一个模型
区别
属于不同的监督学习类型
- 朴素贝叶斯是生成模型的代表:先由训练数据估计出输入和输出的联合概率分布,再根据联合概率分布来生成符合条件的输出, P ( Y ∣ X ) P(Y\vert X) P(Y∣X) 以后验概率的形式出现
- 逻辑回归是判别模型的代表:先由训练数据集估计出输入和输出的条件概率分布,再根据条件概率分布判定对于给定的输入应该选择哪种输出, P ( Y ∣ X ) P(Y\vert X) P(Y∣X) 以似然概率的形式出现
当朴素贝叶斯学习器的条件独立性假设不成立时,逻辑回归与朴素贝叶斯方法通常会学习到不同的结果
-
当训练样本数接近无穷大时,逻辑回归的渐进分类准确率要优于朴素贝叶斯方法
逻辑回归不依赖于条件独立性假设,偏差更小,但方差更大
-
当训练样本稀疏时,朴素贝叶斯的性能优于逻辑回归
收敛速度不同:逻辑回归的收敛速度慢于朴素贝叶斯方法
4.3 Softmax回归
Logistic问题应用于多分类问题
要让逻辑回归处理多分类问题,需要做一些改进
4.3.1 softmax模型
直接修改逻辑回归的似然概率,使之适应多分类问题
softmax回归转换为对条件概率的建模,给出的是实例在每一种分类结果下出现的概率
κ ^ = s o f t m a x ( f k ( x ; ω k ) ) = a r g max k = 1 K y ^ ( k ) y ^ ( k ) = p ω k ( y = k ∣ x ) , k ∈ { 1 , ⋯ , K } , K > 2 = e w k T x ∑ k = 1 K e w k T xκ^y^(k)=softmax(fk(x;ωk))=argk=1maxKy^(k)=pωk(y=k∣x),k∈{1,⋯,K},K>2=k=1∑KewkTxewkTxκ ^ = s o f t m a x ( f k ( x ; ω k ) ) = a r g max k = 1 K y ^ ( k ) y ^ ( k ) = p ω k ( y = k | x ) , k ∈ { 1 , ⋯ , K } , K > 2 = e w k T x ∑ k = 1 K e w k T x - w k w_k wk 表示和类别 k k k 相关的权重参数
4.3.2 损失函数
交叉熵损失函数
− ∑ y = 1 K p r ( y ∣ x ) log p ω ( y ∣ x ) -\sum\limits_{y=1}^Kp_r(y\vert x)\log p_\omega(y\vert x) −y=1∑Kpr(y∣x)logpω(y∣x)

对于某个真实类别为 κ \kappa κ 的样本 y i y_i yi ,其向量形式为
y i = [ I ( 1 = κ ) , I ( 2 = κ ) , ⋯ , I ( K = κ ) ] T y_i=\left[I(1=\kappa),I(2=\kappa),\cdots,I(K=\kappa)\right]^T yi=[I(1=κ),I(2=κ),⋯,I(K=κ)]T
其交叉熵形式的损失函数为
L ( y i ) = − ∑ k = 1 K y i ( k ) log y ^ i ( k ) = − y i ( κ ) log y ^ i ( κ ) = − ( y i ) T ⋅ log y ^ i →L(yi)=−k=1∑Kyi(k)logy^i(k)=−yi(κ)logy^i(κ)=−(yi)T⋅logy^iL ( y i ) = − ∑ k = 1 K y i ( k ) log y ^ i ( k ) = − y i ( κ ) log y ^ i ( κ ) = − ( y i ) T ⋅ log y ^ i → - 对于一个三分类问题,某样本类别为
[
0
,
0
,
1
]
[0,0,1]
[0,0,1] ,预测各类别概率为
[
0.3
,
0.3
,
0.4
]
[0.3,0.3,0.4]
[0.3,0.3,0.4] ,则交叉熵损失函数为
L ( y i ) = − [ 0 × log 0.3 + 0 × log 0.3 + 1 log ( 0.4 ) ] = − log ( 0.4 ) \mathcal{L}(y_i)=-[0\times \log 0.3+0\times \log 0.3+1\log(0.4)]=-\log(0.4) L(yi)=−[0×log0.3+0×log0.3+1log(0.4)]=−log(0.4)
损失函数——交叉熵
R = − 1 N ∑ i = 1 N ∑ k = 1 K y i ( k ) log y ^ i ( k ) = − 1 N ∑ i = 1 N ( y i ) T ⋅ log y ^ i →R=−N1i=1∑Nk=1∑Kyi(k)logy^i(k)=−N1i=1∑N(yi)T⋅logy^iR = − 1 N ∑ i = 1 N ∑ k = 1 K y i ( k ) log y ^ i ( k ) = − 1 N ∑ i = 1 N ( y i ) T ⋅ log y ^ i → 4.3.3 优化算法
优化算法:梯度下降法
∂ R ( ω ) ∂ ω = − 1 N ∑ i = 1 N x i ( y i − y ^ i ) T \frac{\partial \mathcal{R}(\omega)}{\partial \omega}=-\frac{1}{N}\sum\limits_{i=1}^Nx_i(y_i-\hat{y}_i)^T ∂ω∂R(ω)=−N1i=1∑Nxi(yi−y^i)T

采用梯度下降法
ω [ t + 1 ] ← ω [ t ] + α ( 1 N ∑ i = 1 N x i ( y i − y ^ i ) T ) \omega^{[t+1]}\leftarrow \omega^{[t]}+\alpha\left(\frac{1}{N}\sum\limits_{i=1}^Nx_i(y_i-\hat{y}_i)^T\right) ω[t+1]←ω[t]+α(N1i=1∑Nxi(yi−y^i)T)Softmax回归模型的训练与逻辑回归模型类似,都可以转化为通过梯度下降法或者拟牛顿法解决最优化问题
4.3.4 softmax与logistic对比
输出结果只能是属于一个类别时,Softmax分类器更加高效
输出结果可能出现交叉情况时,多个二分类逻辑回归模型性能好,可以得到多个类别的标记
当 K = 2 K=2 K=2 时,softmax回归的决策函数为
y ^ = a r g max y ∈ [ 0 , 1 ] p ( y ∣ x ) = a r g max y ∈ [ 0 , 1 ] e w y T x ∑ k = 1 K e w y T x ⟺ a r g max y ∈ [ 0 , 1 ] I ( ω 1 T x > ω 0 T x ) = a r g max y ∈ [ 0 , 1 ] I ( ( ω 1 − ω 0 ) T x > 0 )y^=argy∈[0,1]maxp(y∣x)=argy∈[0,1]maxk=1∑KewyTxewyTx⟺argy∈[0,1]maxI(ω1Tx>ω0Tx)=argy∈[0,1]maxI((ω1−ω0)Tx>0)y ^ = a r g max y ∈ [ 0 , 1 ] p ( y | x ) = a r g max y ∈ [ 0 , 1 ] e w y T x ∑ k = 1 K e w y T x ⟺ a r g max y ∈ [ 0 , 1 ] I ( ω 1 T x > ω 0 T x ) = a r g max y ∈ [ 0 , 1 ] I ( ( ω 1 − ω 0 ) T x > 0 ) -
相关阅读:
UVa10537 The Toll! Revisited(Dijkstra)
与开发斗智斗勇的日子
【C++】基础知识点回顾 上:命名空间与输入输出
HTML——列表,表格,表单内容的讲解
技术实践|大模型内容安全蓝军的道与术
「UG/NX」Block UI 从列表选择部件SelectPartFromList
华为十年大佬带你开启springboot实战之旅,从源码到项目,一步到位!
SpringCloud OpenFeign token中转
解决websocket不定时出现1005错误
【Arduino+ESP32专题】Visual Studio Code+PlatformIO开发环境安装
- 原文地址:https://blog.csdn.net/qq_40479037/article/details/132775345