-
[论文笔记] Gunrock: A High-Performance Graph Processing Library on the GPU
Gunrock: A High-Performance Graph Processing Library on the GPU
Gunrock: GPU 上的高性能图处理库 [Paper] [Code]
PPoPP’16摘要
Gunrock, 针对 GPU 的高层次批量同步图处理系统.
- 采用了一种新方法抽象 GPU 图分析: 实现了以数据为中心(data-centric)的抽象, 以在结点或边的边界(frontier)上的操作为中心.
- 将高性能 GPU 计算原语和优化策略与高级编程模型相结合, 实现了性能与表达的平衡.
1. 介绍
提出了 Gunrock, 基于 GPU 的图处理系统, 通过高层次的、以数据为中心的并行编程模型在计算图分析时提供高性能.
以数据为中心的模型的关键抽象是边界(frontier), 图中当前感兴趣的边或结点的子集.
Gunrock 的所有操作是批量同步的, 并对边界进行操作, 通过计算其中的值或从中计算新边界.高并行图处理系统的主要挑战: 管理工作分配的不规则性.
Gunrock 将负载均衡和工作效率策略融入其核心, 而对编程者隐藏.本文贡献:
- 为图操作提出了一种新的以数据为中心的抽象, 允许编程者在高层次抽象上开发图基本算法(graph primitive, 图原语)的同时提供高性能.
该抽象能够将有益的优化(内核融合、推拉遍历、幂等遍历和优先级队列)结合到实现的核心中. - 设计并实现了一组简单灵活的 API, 可以在高层次抽象上表达广泛的图处理原语.
- 描述了几种针对内存效率、负载均衡和工作负载管理的 GPU 特定优化策略来共同实现高性能.
实现了与硬件专用实现相当的性能, 并显著优于之前的可编程 GPU 抽象. - 对图基本算法进行了详细的实验评估, 并与几种 CPU 和 GPU 实现进行了性能比较.
2. 相关工作
- 单节点 CPU 系统
- 分布式 CPU 系统
- 特定于图基本算法的 GPU 硬件底层实现
- 用于图分析的高层次 GPU 编程模型
2.1 单节点和分布式 CPU 系统
2.2 专用并行图算法
2.3 高层次 GPU 编程模型
3. Gunrock 抽象与实现
3.1 Gunrock 的抽象
Gunrock 针对可表示为迭代收敛过程的图操作.
Gunrock 的抽象专注于操纵数据结构, 即表示激活参与计算的图子集的结点或边的边界.
同时支持结点边界和边边界, 并可以在同一个图基本算法中进行切换.
操作边界的批量同步"步骤"(由一系列步骤构建图算法): advance(推进)、filter(过滤)、compute(计算)- Advance(推进): 通过访问当前边界的邻居从当前边界生成一个新边界.
- Filter(过滤): 根据编程者指定的标准选择当前边界的子集, 从当前边界生成一个新边界.
- Compute(计算): 由编程者指定的对当前边界中所有元素(结点或边)的操作, 然后由 Gunrock 在所有元素上并行执行该操作.

3.2 可替代的抽象
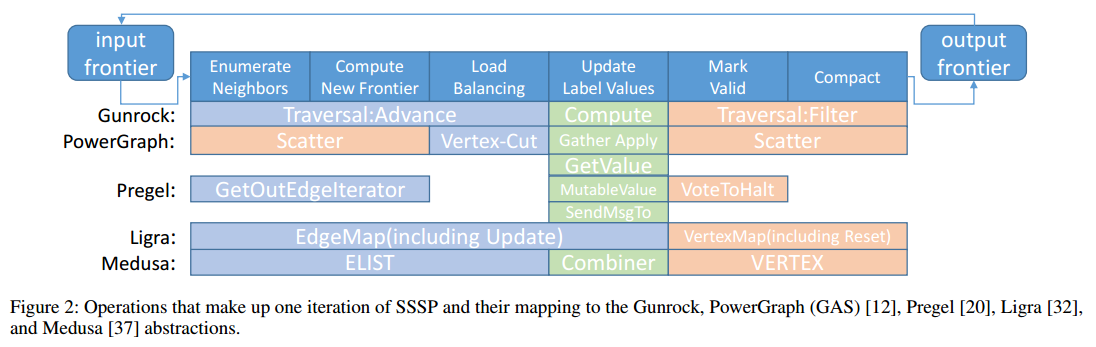
3.3 Gunrock API 及其内核融合优化
Gunrock 程序指定的三个组件:
- problem: 提供图拓扑数据和特定于算法的数据管理接口
- functors: 包含用户定义的计算代码并暴露内核融合机会
- enactor: 图算法的入口点并将计算指定为一系列具有用户定义的内核启动设置的 advance 和/或 filter 的内核调用
Gunrock 将其计算步骤公开为在编译时集成到 advance 和 filter 内核中的 functor, 以实现类似(基于硬件底层实现的算法)的效率.
支持应用于 {edges, verteices} 的 functor, 并且要么返回一个布尔值(“cond” functor), 用于过滤(filter 阶段); 要么执行计算(“apply” functor).

Gunrock 数据结构:
- 每个结点和每条边的数据表示为阵列结构(structure-of-array, SOA)数据结构
- 图数据结构: 使用压缩稀疏行(CSR)格式的稀疏矩阵, 允许用户选择仅边列表的表示(无边数据)
3.4 工作负载映射和负载均衡详情
Gunrock 将之前应用于单个硬件底层实现的 GPU 图基本算法的两种工作负载分配和负载均衡策略推广到 Gunrock 的 advance 操作.
负载映射:
每个线程细粒度: 将一个边界结点的邻接表映射到一个线程.- 将所有邻接表偏移加载到共享内存
- 使用 CTA 来协同处理邻接表中每条边上的操作
- 使用结点切割(vertex-cut)来划分邻接表由多个线程处理
- 适合具有相对均匀分布的大直径图
每个 warp 和每个 CTA 粗粒度: 根据邻接表大小将其分为三类, 然后使用针对该大小的策略单独处理每个类别.
- 三种邻接表大小: (1) 比 CTA 大; (2) 大于 warp(32线程) 但小于 CTA ; (3) 比 warp 小
- 先将边界的一个子集分配给一个 block, 其中每个线程有一个结点.
- 拥有大列表结点的线程决定对整个块的控制
- block 中所有线程协同处理获胜者结点的邻接表, 直到所有大列表结点处理完
- 每个 warp 中线程开始类似过程处理邻接表为中等大小的所有结点
- 使用每个线程细粒度工作负载映射策略处理剩余结点
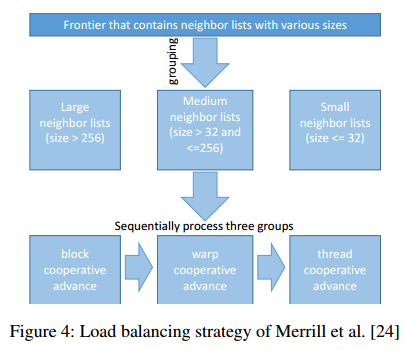
负载均衡:
负载均衡划分: 将边组织成等长的分块(chunk), 并将每个分块分配给一个 block.- 使用排序搜索对分块的索引和扫描的边偏移队列进行映射.
- 处理结点邻接表时使用二分搜索找到要处理结点的 ID.

Gunrock 对邻接表较小的结点使用细粒度动态分组策略; 对邻接表较大的结点使用粗粒度负载均衡策略, 其中边界大小小于设置的静态阈值时在结点上使用粗粒度负载均衡, 否则(大于阈值)则在边上使用粗粒度负载均衡.
3.5 Gunrock 的优化
Gunrock 以数据中心的抽象和关注操作边界, 适合将现有和新的替代方案和优化的集成.
幂等与非幂等操作:
- 幂等操作: Gunrock 的 filter 步骤可以减少输出边界的冗余条目
- 非幂等操作: 在内部使用原子运算保证每个元素在输出边界中只出现一次
Push 和 Pull 遍历:
Gunrock 不仅支持 Push, 还支持 Pull.
Gunrock 在内部将边界转换为结点位图, 生成所有未访问结点的新边界, 然后使用 advance 步骤来从这些结点的前驱结点中进行"Pull"计算.优先队列:
Gunrock 允许用户定义优先级函数来将输出边界组织为"远"和"近"两种切片.
Gunrock 在接下来的处理步骤中先只考虑近切片, 并将不符合的新元素添至远切片, 直至近切片处理完; 再对远切片进行操作.4 应用

4.1 广度优先搜索 (BFS)
4.2 单源最短路径
4.3 中介中心性 (Betweenness Centrality)
4.4 连通分量标记
4.5 PageRank 和其他结点排名算法
5 实验和结果
性能: Table 2, Table 3, Figure 7,

warp 效率: Table 4
优化策略带来的性能提升: Figure 8
笔者总结
本文的核心在于提出了基于 GPU 的以数据为中心的并行编程模型来对边界进行操作 的图处理系统, 并提出了几种工作负载映射和负载均衡的 GPU 特定优化策略.
Gunrock 属于 GPU 图计算系统. -
相关阅读:
一场由Integer引发的血案
性能测试面试题总结(答案全)
接口测试2-jmeter快速上手
vue实现弹窗的动态导入(:is=“dialogName“)
Django--ORM 多表查询
【postgres】docker desktop全部署后端MVC + postgres + Adminer可视化数据库
深度度量学习(Deep Metric Learning)函数求导公式
python表白程序,无法拒绝
PyTorch框架中torch、torchvision、torchaudio与python之间的版本对应关系(9月最新版)
使用 cURL 发送 HTTP 请求: 深入探讨与示例
- 原文地址:https://blog.csdn.net/LostUnravel/article/details/132763622