-
Commonsense Knowledge Base Completion with Structural and Semantic Context
摘要
与研究较多的传统知识库(如Freebase)相比,常识性知识图(如ATOMIC和ConceptNet)的自动知识库补全提出了独特的挑战。常识知识图使用自由形式的文本来表示节点,与传统知识库相比,导致节点数量增加了几个数量级(与Freebase (FB15K237)相比,ATOMIC中的节点数量增加了18倍)。重要的是,这意味着更稀疏的图结构——这是现有的KB补全方法面临的主要挑战,这些方法假设在相对较小的节点集上密集连接的图。
在本文中,我们提出了新的知识库补全模型,可以通过利用节点的结构和语义上下文来解决这些挑战。具体来说,我们研究了两个关键思想:(1)从局部图结构中学习,使用图卷积网络和自动图密度化;(2)从预训练的语言模型到知识图的迁移学习,以增强知识的上下文表示。我们描述了将这两个来源的信息合并到一个联合模型中的方法,并提供了在ATOMIC上完成知识库和在ConceptNet上使用排名指标进行评估的第一个经验结果。我们的结果证明了语言模型表示在提高链接预测性能方面的有效性,以及在子图上训练时从局部图结构学习的优势(ConceptNet的MRR增加1.5点)。对模型预测的进一步分析揭示了语言模型能够很好地捕获的常识类型
1.引言与动机
虽然在传统知识库(如Freebase)的知识库补全方面已经有了大量的工作,但对于ATOMIC (Sap et al . 2019)和ConceptNet (Speer and Havasi 2013)等常识性知识图的知识库完成方面的工作相对较少。本文的明确目标是确定常识性知识库完成中的独特挑战,研究解决这些挑战的有效方法,并提供全面的经验见解和分析。
补全常识性KGs的关键挑战是图的规模和稀疏性。与传统的kb不同,常识性kb由由非规范化、自由格式的文本表示的节点组成,如图1所示。例如,节点“防止蛀牙”和“蛀牙”在概念上是相关的,但不是等价的,因此表示为不同的节点。图的概念多样性和表达性是表示常识的必要条件,这意味着节点的数量要大几个数量级,而且图比传统的kb要稀疏得多。例如,像FB15K-237这样的百科全书式知识库(Toutanova和Chen 2015)的密度是ConceptNet和ATOMIC的100倍(图2所示的节点度)。

图1:来自ConceptNet的子图说明了节点的语义多样性。蓝色虚线表示要添加到图中的潜在边
在这项工作中,我们提供了关于常识知识库的稀疏性如何对隐式假设密集连接图的现有知识库补全模型构成挑战的经验见解。图3提供了这一证据的简要预览,其中,当我们降低FB15K-237的图密度时,高性能KB补全模型ConvTransE (Shang et al . 2019)的性能会迅速下降。
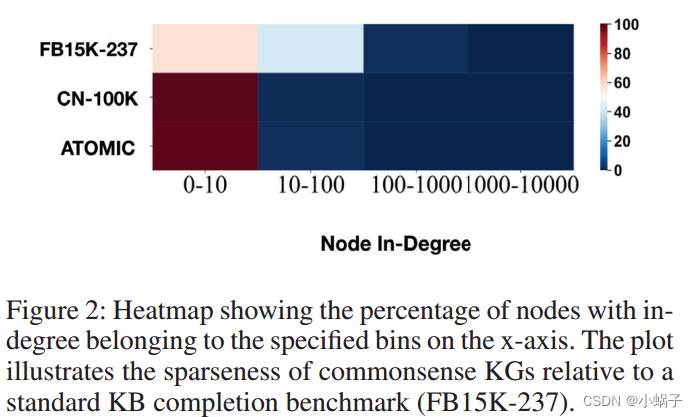
图2:热图显示了x轴上属于指定bin的节点的百分比。该图说明了相对于标准KB补全基准(FB15K-237),常识性KB的稀疏性。

图3:使用ConvTransE模型的FB15K-237数据集,不同图密度值(log scale)下KB Completion Scores的下降趋势。
这激发了研究常识知识库补全新方法的强烈需求。我们认为,新方法需要更好地适应所有节点(包括结构和语义)之间的隐式概念连通性,而不仅仅是在现有常识知识库中显式编码的。具体来说,我们研究了两个关键思想:(1)从局部图结构中学习,使用图卷积网络和自动图密度化。(2)将学习从语言模型转移到知识图,以提高节点的上下文表示。
为了整合图结构信息,我们提出了一种基于图卷积网络(GCN)的方法(Kipf and Welling 2017),根据节点的局部邻域将节点的表示上下文化。对于迁移学习,我们提出了将预训练语言模型(Devlin et al . 2019)微调到常识性KGs的有效方法,从本质上实现了从语言到知识的迁移学习。我们的工作分享了Petroni等人(2019)最近的工作的高水平精神,该工作展示了使用预训练的LMs来重建知识库条目,但我们提供了一个专门针对常识知识库的更集中的研究。实证分析表明,尽管GCNs在各种密集连接图上有效(Schlichtkrull等人2018),但在常识知识库上却没有那么有效,因为稀疏连接不允许有效的知识传播。因此,我们提出了一种基于节点间语义相似度评分的自动图密度化方法。最后,我们强调了使用来自图结构和语言模型的信息来训练模型所需的策略。


Our main contributions are highlighted below:
- 1.与传统的百科式知识库完井相比,关于常识知识库补全的独特挑战的经验见解。
- 2. 新颖的知识库补全方法,对现有知识库中明确可用的知识的隐式结构和语义上下文进行建模。
- 3.在ConceptNet上使用排名指标对知识库完成和评价进行了ATOMIC的第一个实证结果。
- 4. 对语言模型捕获的常识性知识类型的分析和见解。
总之,我们的研究结果表明,迁移学习通常比从图结构中学习更有效。此外,我们发现图结构确实可以提供互补信息,从而提高性能,特别是在使用子图进行效率训练时。
2.Knowledge Graphs
在建立常识的图形结构表示方面已经有了一些努力(Lenat 1995;Speer and Havasi 2013;Cambria, Olsher, and Rajagopal 2014;Sap et al 2019)。我们将实验重点放在两个重要的知识图上:ConceptNet和ATOMIC。表1提供了这两个图的统计数据,以及FB15K-237——一个标准的KB补全数据集。

ConceptNet-100K2: CN-100K包含关于世界的一般常识事实。这个版本(Li et al . 2016)包含了来自ConceptNet (Speer and Havasi 2013)的开放思维常识(OMCS)条目。图中的节点平均包含2.85个单词。我们使用数据集的原始分割,并将两个提供的开发集结合起来创建一个更大的开发集。开发集和测试集各由1200个元组组成。
ATOMIC3: ATOMIC知识图包含关于日常事件的社会常识性知识。数据集指定事件中参与者的效果、需求、意图和属性。节点平均短语长度(4.40 words)略高于CN-100K。一个源实体和关系可能存在多个目标。在关系类型不需要注释的情况下,此图中的元组也可能包含一个none目标。创建原始数据集分割是为了使训练和评估分割之间的种子实体集互斥。由于KB补全任务要求实体至少被看到一次,因此我们为数据集创建了一个新的随机80-10-10分割。开发集和测试集分别由87K元组组成。
3 Machine Commonsense Completion
我们研究了补全常识知识图谱的两个关键思想:1)从语言到知识图的迁移学习和2)从图结构的学习。为了解决常识KGs的稀疏性问题,我们使用合成语义相似链接来丰富图的连通性,从而使GCNs能够有效地使用。我们模型的整体架构如图4所示。
3.1Problem Formulation

3.2Transfer Learning from Text to Knowledge Graphs
从语言到知识图谱的迁移学习最近被证明对常识知识图谱的构建是有效的(Bosselut et al . 2019)。为了从语言转移到知识图进行补全,我们对BERT (Devlin et al . 2019)进行了微调,利用被掩盖的语言建模损失,并根据节点的文本短语获得节点的丰富语义表示。这允许BERT调整到KG的特定文本样式。调优的输入是用于表示KG中的节点的唯一短语列表。模型的输入格式为
 ,其中e¯i是由节点表示的自然语言短语。我们使用BERT模型最后一层的[CLS]令牌表示作为模型中的节点表示。我们将BERT模型得到的节点嵌入矩阵表示为
,其中e¯i是由节点表示的自然语言短语。我们使用BERT模型最后一层的[CLS]令牌表示作为模型中的节点表示。我们将BERT模型得到的节点嵌入矩阵表示为 ,其中M为BERT嵌入的维数。
,其中M为BERT嵌入的维数。3.3Learning from Graph Structure
图卷积网络(GCNs) (Kipf and Welling 2017)在整合图中节点的局部邻域信息方面是有效的。图卷积编码器以图G为输入,将每个节点编码为所有节点
 的d维嵌入
的d维嵌入 。GCN编码器的操作方式是从一个节点向它的邻居发送消息,可以选择由边指定的关系类型进行加权。该操作在多个层中进行,包含从一个节点到另一个节点的多个跃点的信息。最后一层的表示用作节点的图嵌入。几种变体(Schlichtkrull et al . 2018;Velickovi等人(2018)最近提出了这些模型,所有这些模型都使用相同的底层局部邻域聚集机制。我们选择使用GCN的一个版本,它允许我们1)参数化与边对应的关系类型,2)在聚合期间考虑节点邻居的重要性。给定具有R个关系类型的图G和具有L层的GCN,计算第1层节点ei的节点表示的操作为:
。GCN编码器的操作方式是从一个节点向它的邻居发送消息,可以选择由边指定的关系类型进行加权。该操作在多个层中进行,包含从一个节点到另一个节点的多个跃点的信息。最后一层的表示用作节点的图嵌入。几种变体(Schlichtkrull et al . 2018;Velickovi等人(2018)最近提出了这些模型,所有这些模型都使用相同的底层局部邻域聚集机制。我们选择使用GCN的一个版本,它允许我们1)参数化与边对应的关系类型,2)在聚合期间考虑节点邻居的重要性。给定具有R个关系类型的图G和具有L层的GCN,计算第1层节点ei的节点表示的操作为:其中,Ji表示图中节点ei的邻居,Wl是层1特定的线性投影矩阵。初始节点表示h0 i是使用嵌入层计算的。方程1中的第二项表示节点的自连接,用于将信息从一层传播到下一层。αr是边的关系类型的权值,β I是表示ei的每个邻居的相对重要性的向量:


Graph Densification
常识KGs的稀疏性使得GCNs在节点的邻域上执行信息传播具有挑战性。为了解决这个问题,我们在语义相似的节点之间添加了合成边,以提高图嵌入的学习速度。这些边缘形成了一种新的合成sim关系,仅用于计算图嵌入而不被解码器评分。为了形成这些边,我们使用前面描述的微调BERT模型来提取节点表示,并使用这些表示来计算图中所有节点对之间的余弦相似度。
在计算两两相似度时,我们使用硬阈值τ来过滤最相似的节点对。这个阈值是对每个图使用不同的标准来计算的,每个标准都优先考虑这些链接的精度。对于CN100K(122,618条sim边中τ = 0.95的结果),我们绘制了所有节点对之间的成对相似值分布,并选择顶部的σ/2对节点来形成这些合成链接,其中σ为正态分布的成对相似分布的标准差。对于ATOMIC (τ = 0.98导致89,682条sim边),我们获得了非正态的两两相似性分布,因此使用阈值(测量到2小数点),该阈值只会在图中增加最多100K条边5。这一步之后,我们得到一组边
 。
。 3.4Progressive Masking for Fusion
使用来自GCNs和BERT的节点嵌入的模型往往过度依赖BERT嵌入,使图嵌入无效(我们使用随机排列测试验证这一点(Fisher, Rudin, and Dominici 2018),我们在一个小批量中随机洗牌图嵌入,并观察到性能几乎没有下降)。在训练开始时,图嵌入不提供信息,而微调的BERT嵌入提供有用的信息-导致模型安全地忽略图嵌入。为了防止这个问题,我们随机屏蔽BERT嵌入,从开始的全零掩码到100个epoch结束的全一掩码。对于前100个epoch,被遮挡的维度比率设置为(epoch/100)。这种策略迫使模型依赖于两个信息源。类似的技术被用于通过屏蔽源中的标记来强制多模态机器翻译模型依赖于图像(Caglayan et al 2019)。
3.5Convolutional Decoder

3.6Subgraph Sampling
随着图大小的增加,在内存中使用整个图进行训练变得计算密集。具体来说,在整个图上执行图卷积并使用解码器计算图中所有节点的分数是密集的。例如,具有GCN和BERT表示的atom模型占用~ 30GB内存,在Quadro RTX 8000 GPU上进行训练需要8-10天。因此,我们选取较小的子图进行训练。我们用不同的采样标准进行了实验,发现均匀随机采样的边缘提供了最好的性能对于图密度化,我们将子图中所有跨越语义相似阈值τ的节点对连接起来。
-
相关阅读:
大数据第二章Hadoop习题
冥想第六百三十四天
SQLite—免费开源数据库系列文章目录
Redis技术
C++ - 双指针_盛水最多的容器
2023中国(深圳)国际激光及焊接展览会
.Net C# 使用 IKVM 调用 Java 代码
元宇宙003 | 在虚拟现实中感受到的压力真实吗?
将风险前置
[附源码]计算机毕业设计基于springboot框架的资产管理系统设计与实现
- 原文地址:https://blog.csdn.net/weixin_44466434/article/details/132752456