-
kafka原理与应用
架构图
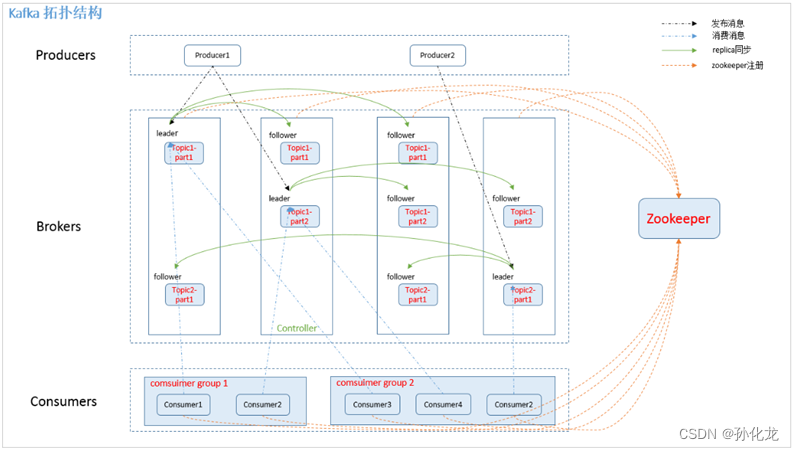
Broker
- Kafka集群包含多个服务器,服务器节点称为Broker
- Broker存储Topic数据
- 如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
- 如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
- 如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
Leader&Follower
- 每个Partition有多个副本,有且仅有一个作为Leader
- Leader是当前负责数据读写的Partition
- 所有写请求通过Leader路由,数据变更会广播给Follower。
- 若Leader失效,会送Follower中选举Leader。
- 当Follower与Leader卡住、挂掉、同步慢,Leader会将Follower删除,重新创建Follower。
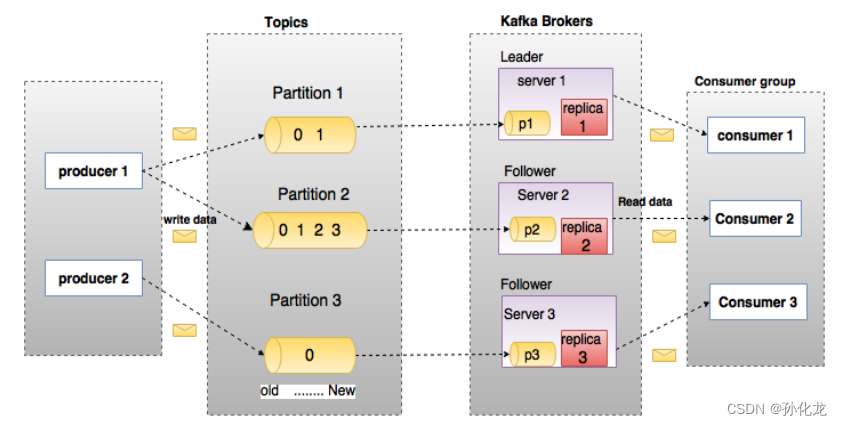
Topics和Partition
- Topic逻辑上理解为一个queue,每条消息都对应一个Topic
- Partition:物理上一个Topic分成多个Partition,对应一个文件夹,存储消息和索引文件
- Topic可以指定分区数,越多,吞吐量越大,资源越多,不可用性越高
- 单个Partition中数据有序
- 收到消息,均衡策略,append到Partition。属于顺序写磁盘,高效
- Partition可分布在不同的broker,同一Topic消息可并行写入Partition,高效
- Kafka会保留所有消息,提供时间空间删除策略
- Consumer的offset控制消费位点,所以broker无状态,不标记是否被消费,不需要锁避免重复消费,高效
Producer
- Producer发送消息到broker
- Partition机制选择存储到哪一个partition
- 消息可以制定key,producer根据key和partition机制判断发送到那个partition
- Partition机制可以通过指定Producer的
partition.class。该calss必须实现Partitioner接口
Consumer Group
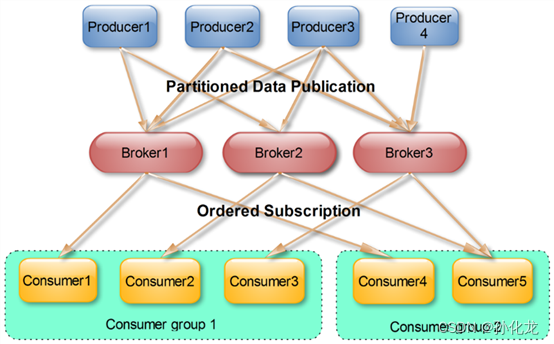
- 同一Topic的消息只能被一个Consumer Group的一个Consumer消费,多个Comsumer Group可以同时消费。
- 借此实现广播和单点。广播时,每个Consumer独立Group;单点时,所有Consumer在同一个Group
Push&Pull
- Producer向Broker push消息。
- Consumer从Broker pull消息。
Replication(副本)
- 0.8以前版本没有Replic,一旦某个Broker宕机,其上所有Partition都不可消费
- 为了负载均衡,Kafka尽量将Partition均匀分配到每个Broker。
- 为了提高容错,Kafka尽量将同一个Partition的Replic分散到不同的Broker。
- 分配Replication的算法
- 将所有Broker(假设共n个Broker)和待分配的Partition排序
- 将第i个Partition分配到第(i mod n)个Broker上
- 将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
消息同步流程
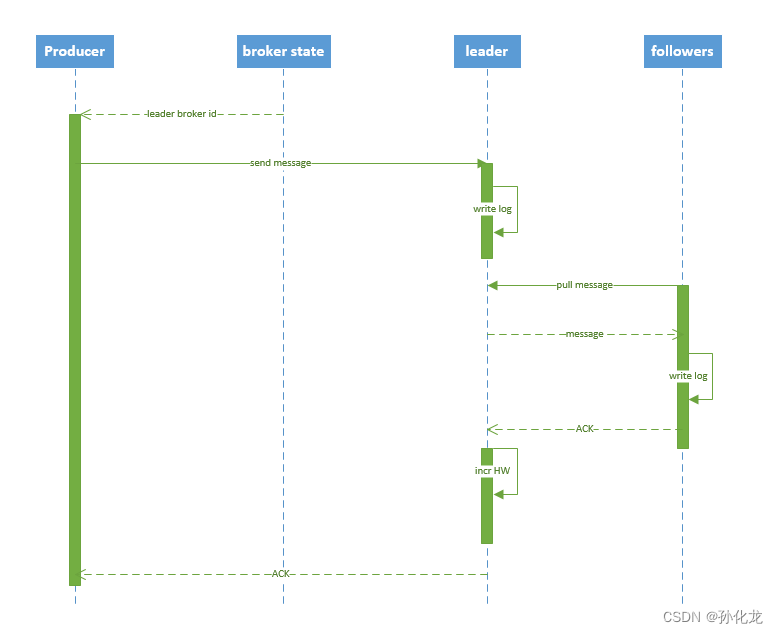
- 同步流程
- Producer发送消息
- Leader接收,写入本地log
- Follower pull,写入log,发送ACK
- Leader收到所有ISR(in sync replication)的ACK,增加HW,向Producer发送ACK
- Consumer从Leader读取已被commit的消息
- ZooKeeper的心跳机制检测Broker是否存活
- Leader会将Broker从ISR中移除
- Follower宕机
- Follower消息数落后于Leader指定值
- Follower指定时间未向Leader发送fetch请求
集成SpringBoot
-
<dependency> <groupId>org.springframework.kafkagroupId> <artifactId>spring-kafkaartifactId> <version>1.3.5.RELEASEversion> dependency>- 1
- 2
- 3
- 4
- 5
-
spring: kafka: bootstrap-servers: 127.0.0.1:9092 #指定kafka server的地址,集群配多个,中间,逗号隔开 producer: key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group-id: default_consumer_group #群组ID enable-auto-commit: true auto-commit-interval: 1000 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer server: port: 8500- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-
@Autowired private KafkaTemplate<String,Object> kafkaTemplate; kafkaTemplate.send("Topic", msg);- 1
- 2
- 3
-
@KafkaListener(topics = "demo") public void listen (ConsumerRecord<?, ?> record){ System.out.printf("topic is %s, offset is %d, value is %s \n", record.topic(), record.offset(), record.value()); }- 1
- 2
- 3
- 4
-
相关阅读:
Minio安装
Day656.数据传输加密问题 -Java业务开发常见错误
《最新出炉》系列初窥篇-Python+Playwright自动化测试-3-离线搭建playwright环境
验证了一遍CVAT的安装(Windows 11)
求质数的方法
郑州分销商城小程序开发完成后如何营销?
笔试题知识点
JAVA实现兔子问题--递归
java基于微信小程序的学习打卡系统 uniapp 小程序
亚马逊运营中动态/静态住宅IP代理的应用有哪些?跨境电商必备
- 原文地址:https://blog.csdn.net/shope9/article/details/132584324