-
自然语言处理:提取长文本进行文本主要内容(文本意思)概括 (两种方法,但效果都一般)
本文主要针对长文本进行文本提取和中心思想概括,原文档放在了附件里面:<科大讯飞公告>
-----------------------------------方法一:jieba分词提取文本(句子赋分法)-------------------------
1、首先导入相关库并读取文档内容:
- import pandas as pd
- df=pd.read_csv(r'C:\Users\59980\Desktop\peixun\科大讯飞_公告.csv',encoding='GBK')
- #df['公告内容']
- text=""
- for line in df['公告内容'][0]:
- text+=line
- text
这里仅作演示所以只读取了文档的第一条数据文本,如果要对每一行文本处理,可以做个for循环,这里就不演示,比较简单。
原文档内容格式:
- 证券代码:002230 证券简称:科大讯飞 公告编号:2022-001
- 科大讯飞股份有限公司
- 关于合肥连山创新产业投资基金完成备案的公告
- 本公司及董事会全体成员保证信息披露内容真实、准确和完整,没有虚假记载、误导性陈述或者重大遗漏。
- 为加快构建人工智能技术应用生态体系,借助专业机构的投资管理经验及其他产业投资人在生命科技、新能源、智能制造、新消费等领域的产业资源优势,深化人工智能技术在新领域应用的探索,进行优质项目的发掘与培育,提升赋能支持能力,并推动人工智能在各行业应用的深度融合和广泛落地,科大讯飞股份有限公司(以下简称 “公司”)与普通合伙人合肥科讯创业投资管理合伙企业(有限合伙),及有限合伙人田明、曹仁贤、陈先保、安徽安科生物工程(集团)股份有限公司、三亚高卓佳音信息科技合伙企业(有限合伙)、郭子珍、魏臻、朱庆龙和吴华峰等共同出资设立合肥连山创新产业投资基金合伙企业(有限合伙)(以下简称“基金”)。其中科大讯飞以自有资金作为基金的有限合伙人出
- 资 11,000 万元,占基金总认缴出资额的 22%。具体内容详见公司于 2021 年 11 月 19 日在
- 《证券时报》《中国证券报》《上海证券报》《证券日报》和巨潮资讯网(www.cninfo.com.cn)披露的《关于对外投资的公告》(公告编号:2021-096)。
- 近日,公司接到通知,该基金已根据《证券投资基金法》和《私募投资基金监督管理暂行办法》等法律法规的要求,在中国证券投资基金业协会完成备案手续,并取得《私募投资基金备案证明》。主要情况如下:
- 备案编码:STP473
- 基金名称:合肥连山创新产业投资基金合伙企业(有限合伙)
- 管理人名称:合肥科讯创业投资管理合伙企业(有限合伙)
- 托管人名称:招商银行股份有限公司
- 公司将根据该基金的后续进展情况,按照有关法律法规的规定和要求,及时履行信息披露义务。敬请广大投资者注意投资风险。
- 特此公告。
- 科大讯飞股份有限公司
- 董 事 会
- 二〇二二年一月八日
看文本提取的内容:

整理成一行了。
2、数据清洗
- #清洗数据
- import re
- import jieba
- text = re.sub(r'[[0-9]*]',' ',text)#去除类似[1],[2]
- text = re.sub(r'\s+',' ',text)#用单个空格替换了所有额外的空格
- sentences = re.split('(。|!|\!|\.|?|\?)',text)#分句
- sentences
这部分要安装的库包括:jieba,re,这部分作用是利用正则表达式把文本去除类似于:[数字];空格等符号,并按标点符号进行分句。分完句子后效果如下:
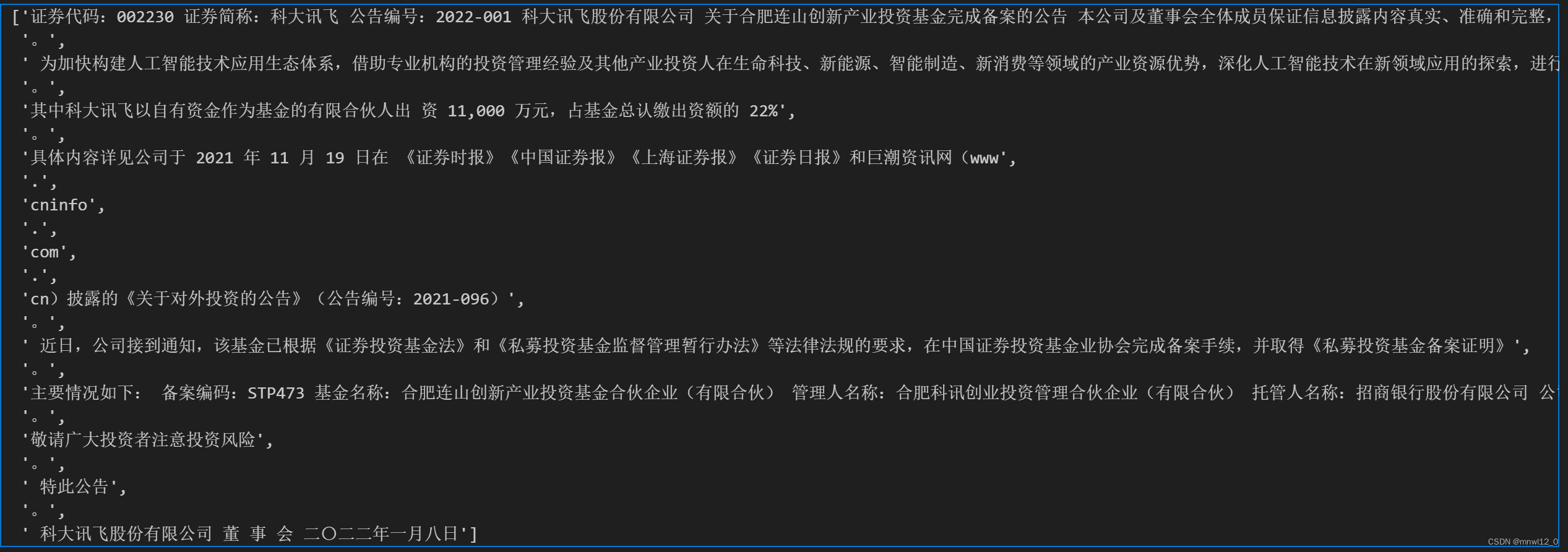
3、加载停用词:
文档已经上传到附件里,利用停用词对上述句子进行切分:
- #加载停用词
- def stopwordslist(filepath):
- stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
- return stopwords
- stopwords = stopwordslist(r'C:\Users\59980\Desktop\peixun\data_stop_word\stop_words.txt')
停用词内容如图:
4、对句子进行打分,形成最终文档:
- #统计词频,首次出现赋值为1,否则统计
- word2count = {} #line 1
- for word in jieba.cut(text): #对整个文本分词
- if word not in stopwords:
- if word not in word2count.keys():
- word2count[word] = 1
- else:
- word2count[word] += 1
- for key in word2count.keys():
- word2count[key] = word2count[key] / max(word2count.values())
- #根据句子中单词的频率计算每个句子的得分
- sent2score = {}#根据句子中单词的频率计算每个句子的得分
- for sentence in sentences:#遍历句子
- for word in jieba.cut(sentence):#对每个句子进行分词
- if word in word2count.keys():#每个单词,检查它是否存在于word2count字典中
- if len(sentence)<300:
- if sentence not in sent2score.keys():
- sent2score[sentence] = word2count[word]#每个单词,检查它是否存在于word2count字典中
- else:
- sent2score[sentence] += word2count[word]#句子已经在sent2score中,则将来自word2count的单词频率的值加到该句子的现有得分上
- #字典排序
- def dic_order_value_and_get_key(dicts, count):
- # by hellojesson
- # 字典根据value排序,并且获取value排名前几的key
- final_result = []
- # 先对字典排序
- sorted_dic = sorted([(k, v) for k, v in dicts.items()], reverse=True)
- tmp_set = set() # 定义集合 会去重元素 --此处存在一个问题,成绩相同的会忽略,有待改进
- for item in sorted_dic:
- tmp_set.add(item[1])
- for list_item in sorted(tmp_set, reverse=True)[:count]:
- for dic_item in sorted_dic:
- if dic_item[1] == list_item:
- final_result.append(dic_item[0])
- return final_result
- #摘要输出
- final_resul=dic_order_value_and_get_key(sent2score,5)
- print(final_resul)
最终输出文本内容如图:

为加快构建人工智能技术应用生态体系,借助专业机构的投资管理经验及其他产业投资人在生命科技、新能源、智能制造、新消费等领域的产业资源优势,深化人工智能技术在新领域应用的探索,进行优质项目的发掘与培育,提升赋能支持能力,并推动人工智能在各行业应用的深度融合和广泛落地,科大讯飞股份有限公司(以下简称 “公司”)与普通合伙人合肥科讯创业投资管理合伙企业(有限合伙),及有限合伙人田明、曹仁贤、陈先保、安徽安科生物工程(集团)股份有限公司、三亚高卓佳音信息科技合伙企业(有限合伙)、郭子珍、魏臻、朱庆龙和吴华峰等共同出资设立合肥连山创新产业投资基金合伙企业(有限合伙)(以下简称“基金”)', '主要情况如下: 备案编码:STP473 基金名称:合肥连山创新产业投资基金合伙企业(有限合伙) 管理人名称:合肥科讯创业投资管理合伙企业(有限合伙) 托管人名称:招商银行股份有限公司 公司将根据该基金的后续进展情况,按照有关法律法规的规定和要求,及时履行信息披露义务', '证券代码:002230 证券简称:科大讯飞 公告编号:2022-001 科大讯飞股份有限公司 关于合肥连山创新产业投资基金完成备案的公告 本公司及董事会全体成员保证信息披露内容真实、准确和完整,没有虚假记载、误导性陈述或者重大遗漏', ' 近日,公司接到通知,该基金已根据《证券投资基金法》和《私募投资基金监督管理暂行办法》等法律法规的要求,在中国证券投资基金业协会完成备案手续,并取得《私募投资基金备案证明》', '具体内容详见公司于 2021 年 11 月 19 日在 《证券时报》《中国证券报》《上海证券报》《证券日报》和巨潮资讯网(www'-----------------------------------方法二:封装成界面(句子赋分法)-------------------------
二、把输入和输出封装成界面,最终效果如图:
全代码实现:(不用修改的部分)
- import nltk
- import jieba
- import numpy
- #pip install pyQt5,需要安装的库
- #分句
- def sent_tokenizer(texts):
- start=0
- i=0#每个字符的位置
- sentences=[]
- punt_list=',.!?:;~,。!?:;~'#标点符号
- for text in texts:#遍历每一个字符
- if text in punt_list and token not in punt_list: #检查标点符号下一个字符是否还是标点
- sentences.append(texts[start:i+1])#当前标点符号位置
- start=i+1#start标记到下一句的开头
- i+=1
- else:
- i+=1#若不是标点符号,则字符位置继续前移
- token=list(texts[start:i+2]).pop()#取下一个字符.pop是删除最后一个
- if start<len(texts):
- sentences.append(texts[start:])#这是为了处理文本末尾没有标点符号的情况
- return sentences
- #对停用词加载,读取本地文档的停用词
- def stopwordslist(filepath):
- stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
- return stopwords
- #对句子打分
- def score_sentences(sentences,topn_words):#参数 sentences:文本组(分好句的文本,topn_words:高频词组
- scores=[]
- sentence_idx=-1#初始句子索引标号-1
- for s in [list(jieba.cut(s)) for s in sentences]:# 遍历每一个分句,这里的每个分句是分词数组 分句1类似 ['花', '果园', '中央商务区', 'F4', '栋楼', 'B33', '城', ',']
- sentence_idx+=1 #句子索引+1。。0表示第一个句子
- word_idx=[]#存放关键词在分句中的索引位置.得到结果类似:[1, 2, 3, 4, 5],[0, 1],[0, 1, 2, 4, 5, 7]..
- for w in topn_words:#遍历每一个高频词
- try:
- word_idx.append(s.index(w))#关键词出现在该分句子中的索引位置
- except ValueError:#w不在句子中
- pass
- word_idx.sort()
- if len(word_idx)==0:
- continue
- #对于两个连续的单词,利用单词位置索引,通过距离阀值计算族
- clusters=[] #存放的是几个cluster。类似[[0, 1, 2], [4, 5], [7]]
- cluster=[word_idx[0]] #存放的是一个类别(簇) 类似[0, 1, 2]
- i=1
- while i<len(word_idx):#遍历 当前分句中的高频词
- CLUSTER_THRESHOLD=2#举例阈值我设为2
- if word_idx[i]-word_idx[i-1]<CLUSTER_THRESHOLD:#如果当前高频词索引 与前一个高频词索引相差小于3,
- cluster.append(word_idx[i])#则认为是一类
- else:
- clusters.append(cluster[:])#将当前类别添加进clusters=[]
- cluster=[word_idx[i]] #新的类别
- i+=1
- clusters.append(cluster)
- #对每个族打分,每个族类的最大分数是对句子的打分
- max_cluster_score=0
- for c in clusters:#遍历每一个簇
- significant_words_in_cluster=len(c)#当前簇 的高频词个数
- total_words_in_cluster=c[-1]-c[0]+1#当前簇里 最后一个高频词 与第一个的距离
- score=1.0*significant_words_in_cluster*significant_words_in_cluster/total_words_in_cluster
- if score>max_cluster_score:
- max_cluster_score=score
- scores.append((sentence_idx,max_cluster_score))#存放当前分句的最大簇(说明下,一个分解可能有几个簇) 存放格式(分句索引,分解最大簇得分)
- return scores;
需要修改的部分:(路径修改成自己的)
- def results(texts,topn_wordnum,n):#texts 文本,topn_wordnum高频词个数,为返回几个句子
- stopwords = stopwordslist(r'C:\Users\59980\Desktop\peixun\data_stop_word\stop_words.txt')#加载停用词
- sentence = sent_tokenizer(texts) # 分句
- words = [w for sentence in sentence for w in jieba.cut(sentence) if w not in stopwords if
- len(w) > 1 and w != '\t'] # 词语,非单词词,同时非符号
- wordfre = nltk.FreqDist(words) # 统计词频
- topn_words = [w[0] for w in sorted(wordfre.items(), key=lambda d: d[1], reverse=True)][:topn_wordnum] # 取出词频最高的topn_wordnum个单词
- scored_sentences = score_sentences(sentence, topn_words)#给分句打分
- # 1,利用均值和标准差过滤非重要句子
- avg = numpy.mean([s[1] for s in scored_sentences]) # 均值
- std = numpy.std([s[1] for s in scored_sentences]) # 标准差
- mean_scored = [(sent_idx, score) for (sent_idx, score) in scored_sentences if
- score > (avg + 0.5 * std)] # sent_idx 分句标号,score得分
- # 2,返回top n句子
- top_n_scored = sorted(scored_sentences, key=lambda s: s[1])[-n:] # 对得分进行排序,取出n个句子
- top_n_scored = sorted(top_n_scored, key=lambda s: s[0]) # 对得分最高的几个分句,进行分句位置排序
- c = dict(mean_scoredsenteces=[sentence[idx] for (idx, score) in mean_scored])
- c1=dict(topnsenteces=[sentence[idx] for (idx, score) in top_n_scored])
- return c,c1
封装成界面,在界面里输入和输出:
- from PyQt5.QtWidgets import QApplication, QWidget, QTextEdit, QVBoxLayout, QPushButton,QLabel,QLineEdit,QFormLayout
- import sys
- class TextEditDemo(QWidget):
- def __init__(self, parent=None):
- super(TextEditDemo, self).__init__(parent)
- self.setWindowTitle("中文摘要提取")
- self.resize(500, 570)
- self.label1 = QLabel('输入文本')
- self.textEdit1 = QTextEdit()
- self.lineedit1 = QLineEdit()#请输入高频词数
- self.lineedit2 = QLineEdit()#请输入返回句子数
- self.btnPress1 = QPushButton("点击运行")
- self.textEdit2 = QTextEdit()#方法1显示
- self.textEdit3 = QTextEdit()#方法2 显示
- flo = QFormLayout()#表单布局
- flo.addRow("请输入高频词数:", self.lineedit1)
- flo.addRow("请输入返回句子数:", self.lineedit2)
- layout = QVBoxLayout()
- layout.addWidget(self.label1)
- layout.addWidget(self.textEdit1)
- layout.addLayout(flo)
- layout.addWidget(self.btnPress1)
- layout.addWidget(self.textEdit2)
- layout.addWidget(self.textEdit3)
- self.setLayout(layout)
- self.btnPress1.clicked.connect(self.btnPress1_Clicked)
- def btnPress1_Clicked(self):
- try:
- text = self.textEdit1.toPlainText() # 返回输入的文本
- topn_wordnum = int(self.lineedit1.text()) # 高频词 20
- n = int(self.lineedit2.text()) # 3个返回句子
- c, c1 = results(str(text), topn_wordnum, n)
- self.textEdit2.setPlainText(str(c))
- self.textEdit2.setStyleSheet("font:10pt '楷体';border-width:5px;border-style: inset;border-color:gray")
- self.textEdit3.setPlainText(str(c1))
- self.textEdit3.setStyleSheet("font:10pt '楷体';border-width:5px;border-style: inset;border-color:red")
- except:
- self.textEdit2.setPlainText('操作失误')
- self.lineedit1.setText('操作失误,请输入整数')
- self.lineedit2.setText('操作失误,请输入整数')
- if __name__ == "__main__":
- app = QApplication(sys.argv)
- win = TextEditDemo()
- win.show()
- sys.exit(app.exec_())
最终效果如图:

总结起来就是没有大模型训练的文本含义提取其效果都比较一般。
下面是上面封装界面代码的在python实现,非封装成界面:
- #coding:utf-8
- import nltk
- import jieba
- import numpy
- #分句
- def sent_tokenizer(texts):
- start=0
- i=0#每个字符的位置
- sentences=[]
- punt_list=',.!?:;~,。!?:;~'#标点符号
- for text in texts:#遍历每一个字符
- if text in punt_list and token not in punt_list: #检查标点符号下一个字符是否还是标点
- sentences.append(texts[start:i+1])#当前标点符号位置
- start=i+1#start标记到下一句的开头
- i+=1
- else:
- i+=1#若不是标点符号,则字符位置继续前移
- token=list(texts[start:i+2]).pop()#取下一个字符.pop是删除最后一个
- if start<len(texts):
- sentences.append(texts[start:])#这是为了处理文本末尾没有标点符号的情况
- return sentences
- #对停用词加载
- def stopwordslist(filepath):
- stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
- return stopwords
- #对句子打分
- def score_sentences(sentences,topn_words):#参数 sentences:文本组(分好句的文本,topn_words:高频词组
- scores=[]
- sentence_idx=-1#初始句子索引标号-1
- for s in [list(jieba.cut(s)) for s in sentences]:# 遍历每一个分句,这里的每个分句是 分词数组 分句1类似 ['花', '果园', '中央商务区', 'F4', '栋楼', 'B33', '城', ',']
- sentence_idx+=1 #句子索引+1。。0表示第一个句子
- word_idx=[]#存放关键词在分句中的索引位置.得到结果类似:[1, 2, 3, 4, 5],[0, 1],[0, 1, 2, 4, 5, 7]..
- for w in topn_words:#遍历每一个高频词
- try:
- word_idx.append(s.index(w))#关键词出现在该分句子中的索引位置
- except ValueError:#w不在句子中
- pass
- word_idx.sort()
- if len(word_idx)==0:
- continue
- #对于两个连续的单词,利用单词位置索引,通过距离阀值计算族
- clusters=[] #存放的是几个cluster。类似[[0, 1, 2], [4, 5], [7]]
- cluster=[word_idx[0]] #存放的是一个类别(簇) 类似[0, 1, 2]
- i=1
- while i<len(word_idx):#遍历 当前分句中的高频词
- CLUSTER_THRESHOLD=2#举例阈值我设为2
- if word_idx[i]-word_idx[i-1]<CLUSTER_THRESHOLD:#如果当前高频词索引 与前一个高频词索引相差小于3,
- cluster.append(word_idx[i])#则认为是一类
- else:
- clusters.append(cluster[:])#将当前类别添加进clusters=[]
- cluster=[word_idx[i]] #新的类别
- i+=1
- clusters.append(cluster)
- #对每个族打分,每个族类的最大分数是对句子的打分
- max_cluster_score=0
- for c in clusters:#遍历每一个簇
- significant_words_in_cluster=len(c)#当前簇 的高频词个数
- total_words_in_cluster=c[-1]-c[0]+1#当前簇里 最后一个高频词 与第一个的距离
- score=1.0*significant_words_in_cluster*significant_words_in_cluster/total_words_in_cluster
- if score>max_cluster_score:
- max_cluster_score=score
- scores.append((sentence_idx,max_cluster_score))#存放当前分句的最大簇(说明下,一个分解可能有几个簇) 存放格式(分句索引,分解最大簇得分)
- return scores;
- #结果输出
- def results(texts,topn_wordnum,n):#texts 文本,topn_wordnum高频词个数,为返回几个句子
- stopwords = stopwordslist(r'C:\Users\59980\Desktop\peixun\data_stop_word\stop_words.txt')#加载停用词
- sentence = sent_tokenizer(texts) # 分句
- words = [w for sentence in sentence for w in jieba.cut(sentence) if w not in stopwords if
- len(w) > 1 and w != '\t'] # 词语,非单词词,同时非符号
- wordfre = nltk.FreqDist(words) # 统计词频
- topn_words = [w[0] for w in sorted(wordfre.items(), key=lambda d: d[1], reverse=True)][:topn_wordnum] # 取出词频最高的topn_wordnum个单词
- scored_sentences = score_sentences(sentence, topn_words)#给分句打分
- # 1,利用均值和标准差过滤非重要句子
- avg = numpy.mean([s[1] for s in scored_sentences]) # 均值
- std = numpy.std([s[1] for s in scored_sentences]) # 标准差
- mean_scored = [(sent_idx, score) for (sent_idx, score) in scored_sentences if
- score > (avg + 0.5 * std)] # sent_idx 分句标号,score得分
- # 2,返回top n句子
- top_n_scored = sorted(scored_sentences, key=lambda s: s[1])[-n:] # 对得分进行排序,取出n个句子
- top_n_scored = sorted(top_n_scored, key=lambda s: s[0]) # 对得分最高的几个分句,进行分句位置排序
- c = dict(mean_scoredsenteces=[sentence[idx] for (idx, score) in mean_scored])
- c1=dict(topnsenteces=[sentence[idx] for (idx, score) in top_n_scored])
- return c,c1
- if __name__=='__main__':
- texts = str(input('请输入文本:'))
- topn_wordnum=int(input('请输入高频词数:'))
- n=int(input('请输入要返回的句子个数:'))
- c,c1=results(texts,topn_wordnum,n)
- print(c)
- print(c1)
结果如图:

-
相关阅读:
在ComboBox1中塞入key和value,并取值。
Python实现基于Optuna超参数自动优化的xgboost回归模型(XGBRegressor算法)项目实战
【机器学习知识点】【1】二维与三维空间梯度下降微分求解及可视化展示
域名不部署SSL证书有什么影响?
代码随想录第50天 | 84.柱状图中最大的矩形
分布式架构 --- 分布式锁
ubuntu安装debian包的命令dpkg和apt的详解
双指针--反转字符串,数组拆分,两数之和,移除元素,最大连续1的个数,长度最小子数组
Java中Date实现比较大小
电脑重装系统后usbcleaner怎么格式化u盘
- 原文地址:https://blog.csdn.net/mnwl12_0/article/details/132636293
