读前提示:
本文字数较多且紧凑,最好预留15min一次性看完,好营养,易吸收。
promQL详解
Prometheus提供了内置的数据查询语言PromQL(全称为Prometheus Query Language),支持用户进行实时的数据查询及聚合操作。
PromQL基本介绍#
Prometheus基于指标名称(metrics name)以及附属的标签集(labelset)唯一定义一条时间序列:
- 指标名称代表着监控目标上某类可测量属性的基本特征标识
- 标签则是这个基本特征上再次细分的多个可测量维度
时间序列数据:按照时间顺序记录系统、设备状态变化的数据,每个数据称为一个样本:
- 数据采集以特定的时间周期进行,因而,随着时间流逝,将这些样本数据记录下来,将生成一个离散的样本数据序列
- 该序列也称为向量(Vector);而将多个序列放在同一个坐标系内(以时间为横轴,以序列为纵轴),将形成一个由数据点组成的矩阵
Prometheus数据模型#
Prometheus中,每个时间序列都由指标名称(Metric Name)和标签(Label)来唯一标识,格式为“{
指标名称:通常用于描述系统上要测定的某个特征;
- 例如,http_requests_total表示接收到的HTTP请求总数;
- 支持使用字母、数字、下划线和冒号,且必须能匹配RE2规范的正则表达式;
标签:键值型数据,附加在指标名称之上,从而让指标能够支持多纬度特征;可选项;
- 例如,http_requests_total{method=GET}和http_requests_total{method=POST}代表着两个不同的时间序列;
- 标签名称可使用字母、数字和下划线,且必须能匹配RE2规范的正则表达式;
- 以“_ _”为前缀的名称为Prometheus系统预留使用

指标名称及标签使用注意事项#
指标名称和标签的特定组合代表着一个时间序列;
- 指标名称相同,但标签不同的组合分别代表着不同的时间序列
- 不同的指标名称自然更是代表着不同的时间序列
promQL的数据类型#
PromQL的表达式中支持4种数据类型:
- 即时向量(Instant Vector):特定或全部的时间序列集合上,具有相同时间戳的一组样本值称为即时向量;
- 范围向量(Range Vector):特定或全部的时间序列集合上,在指定的同一时间范围内的所有样本值;
- 标量(Scalar):一个浮点型的数据值;
- 字符串(String):支持使用单引号、双引号或反引号进行引用,但反引号中不会对转义字符进行转义
数据类型演示#
先看个例子,后边会详细讲解:
- 即时向量,例如:node_cpu_seconds_total{job="nodes"},返回同一时间一组样本值
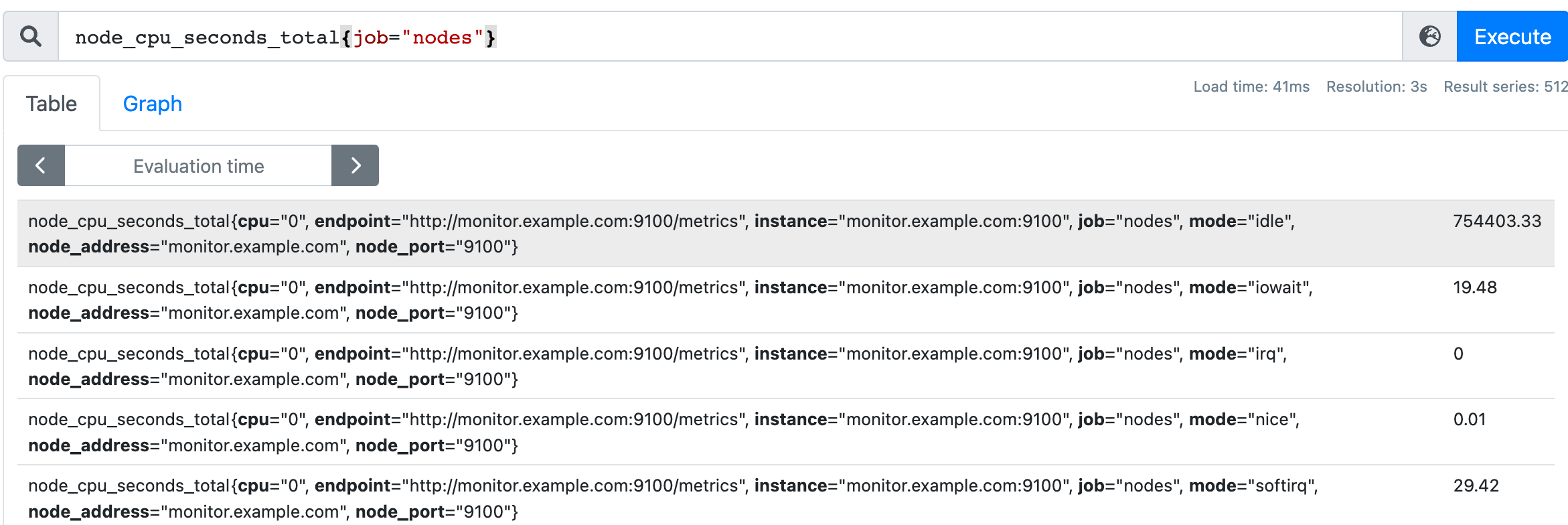
- 范围向量,例如:node_cpu_seconds_total{job="nodes"}[1m],返回1min内的所有样本值

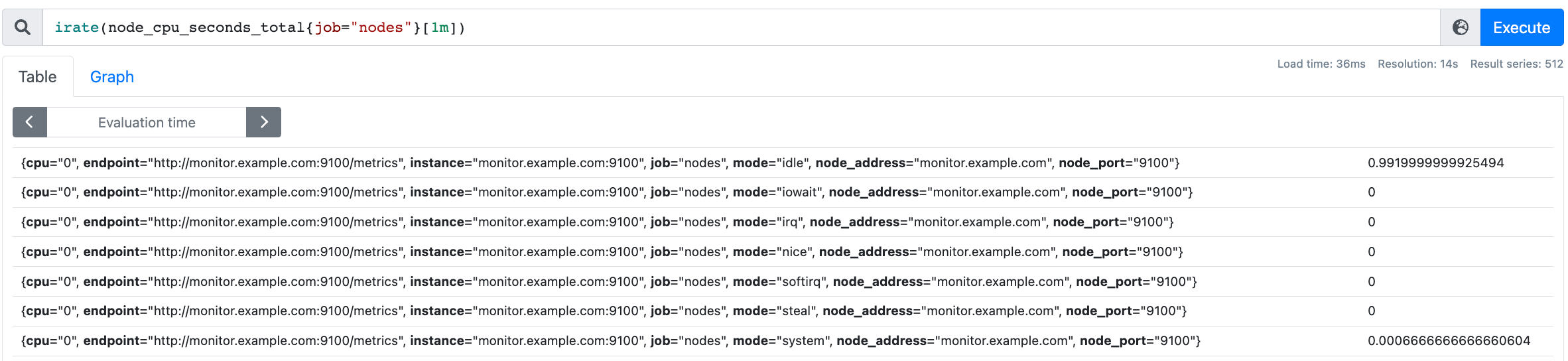
- 标量,例如:irate(node_cpu_seconds_total{job="nodes"}[1m]),返回一个浮点型的数据值
- 字符串,例如:node_cpu_seconds_total{job="nodes"},"nodes"就是字符串类型。
向量表达式使用要点#
表达式的返回值类型亦是即时向量、范围向量、标量或字符串四种类型之一,但是,有些使用场景要求表达式返回值必须满足特定的条件,例如:
- 需要将返回值绘制成图形时,仅支持即时向量类型的数据
- 对于诸如rate一类的速率函数来说,其要求使用的却又必须是范围向量型的数据
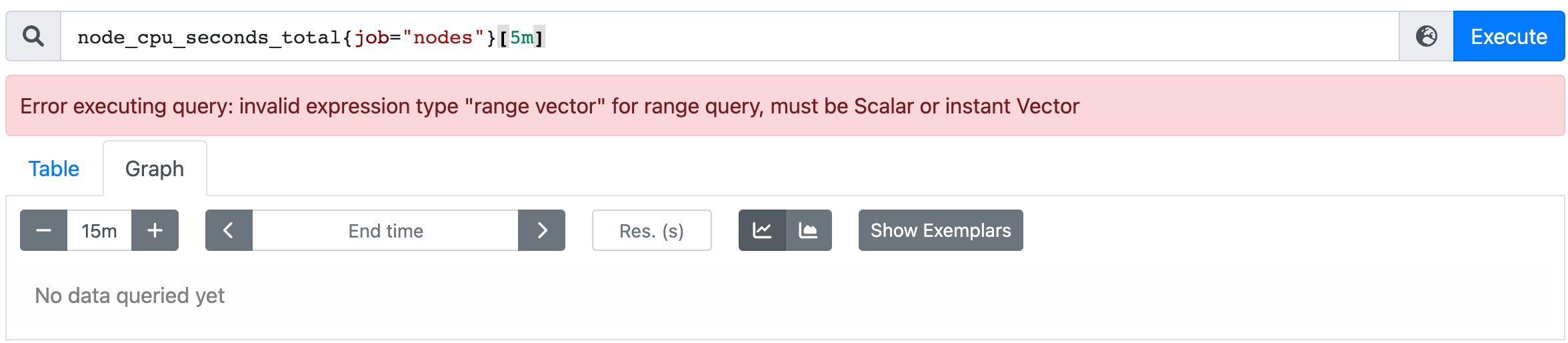
由于范围向量型数据不能用于表达式浏览器中图形绘制功能,若使用,浏览器会返回“Error executing query: invalid expression type "range vector" for range query, must be Scalar or instant Vector”一类的错误:
匹配器#
匹配器用于定义标签过滤条件,目前支持以下四种匹配操作符:
- =:选择与提供的字符串完全相同的标签
- !+:选择与提供的字符串不相同的标签
- =~:选择正则表达式与提供的字符串(或子字符串)相匹配的标签
- !~:选择正则表达式与提供的字符串(或子字符串)不匹配的标签。
注意事项:
- 匹配到空标签值的匹配器时,所有未定义该标签的时间序列同样符合条件
- 正则表达式将执行完全锚定机制,它需要匹配指定标签的整个值
- 向量选择器至少要包含一个指标名称,或者至少有一个不会匹配到空字符串的匹配器
- 使用"__name__"作为标签名称,还能够对指标名称进行过滤,例:{name=~"http_request.*"}
即时向量选择器#
即时向量选择器由两部分组成
- 指标名称:用于限定特定指标下的时间序列,即负责过滤指标;可选;
- 匹配器(Matcher):或称为标签选择器,用于过滤时间序列上的标签;定义在{}之中;可选;
定义即时向量选择器时,以上两个部分应该至少给出一个;于是,这将存在以下三种组合:
- 仅给定指标名称,或在标签名称上使用了空值的匹配器,例如node_cpu_seconds_total和node_cpu_seconds_total{}相等
- 仅给定匹配器,返回所有符合给定匹配器的所有时间的即使样本,例如:{job="nodes"}
- 指标名称和匹配器的组合,返回符合条件的所有时间序列上的即时样本,例如上边的node_cpu_seconds_total{job="nodes"}
范围向量选择器#
同即时向量选择器的唯一不同之处在于,范围向量选择器需要在表达式后紧跟一个方括号[ ]来表达需在时间时序上返回的样本所处的时间范围;
- 时间范围:以当前时间为基准时间点,指向过去一个特定的时间长度;例如[5m]便是指过去5分钟之内;
- 时间格式:一个整数后紧跟一个时间单位,例如“5m”中的“m”即是时间单位;
- 可用的时间单位有ms(毫秒)、s(秒)、m(分钟)、h(小时)、d(天)、w(周)和y(年);
- 必须使用整数时间,且能够将多个不同级别的单位进行串联组合,以时间单位由大到小为顺序,例如1h30m,但不能使用1.5h;
需要注意的是,范围向量选择器返回的是一定时间范围内的数据样本,虽然不同时间序列的数据抓取时间点相同,但它们的时间戳并不会严格对齐;多个Target上的数据抓取需要分散在抓取时间点前后一定的时间范围内,以均衡Prometheus Server的负载;因而,Prometheus在趋势上准确,但并非绝对精准。
偏移量修改器#
默认情况下,即时向量选择器和范围向量选择器都以当前时间为基准时间点,而偏移量修改器能够修改该基准;
偏移量修改器的使用方法是紧跟在选择器表达式之后使用“offset”关键字指定,例如:
- “http_requests_total offset 5m”,表示获取以http_requests_total为指标名称的所有时间序列在过去5分钟之时的即时样本
- “http_requests_total[5m] offset 1d”,表示获取距此刻1天时间之前的5分钟之内的所有样本
PromQL的指标类型#
PromQL有四个指标类型,它们主要由Prometheus的客户端库使用:
- Counter:计数器,单调递增,除非重置(例如服务器或进程重启)
- Gauge:仪表盘,可增可减的数据
- Histogram:直方图,将时间范围内的数据划分成不同的时间段,并各自评估其样本个数及样本值之和,因而可计算出分位数
- 可用于分析因异常值而引起的平均值过大的问题
- 分位数计算要使用专用的histogram_quantile函数
- Summary:类似于Histogram,但客户端会直接计算并上报分位数
Counter#
通常,Counter的总数并没有直接作用,而是需要借助于rate、topk、increase和irate等函数来生成样本数据的变化状况(增长率):
- rate(http_requests_total[2h]),获取2小内,该指标下各时间序列上的http总请求数的增长速率;
- topk(3, http_requests_total),获取该指标下http请求总数排名前3的时间序列;
- irate(http_requests_total[2h]),高灵敏度函数,用于计算指标的瞬时速率;
- 基于样本范围内的最后两个样本进行计算,相较于rate函数来说,irate更适用于短期时间范围内的变化速率分析;
Gauge#
Gauge用于存储其值可增可减的指标的样本数据,常用于进行求和、取平均值、最小值、最大值等聚合计算;也会经常结合PromQL的predict_linear和delta函数使用:
- predict_linear(v range-vector, t, scalar)函数可以预测时间序列v在t秒后的值,它通过线性回归的方式来预测样本数据的Gauge变化趋势;
- predict_linear(node_sockstat_TCP_inuse{node_port="9100"}[2h],4*3600)根据近两小时的数据,预测出接下来4小时的tcp socket的活跃连接数

- delta(v range-vector)函数计算范围向量中每个时间序列元素的第一个值与最后一个值之差,从而展示不同时间点上的样本值的差值;
- delta(node_netstat_Tcp_CurrEstab{node_port="9100"}[2h]),返回该服务器活跃状态的TCP连接数与2小时之前的差异;

Histogram#
Histogram是一种对数据分布情况的图形表示,由一系列高度不等的长条图(bar)或线段表示,用于展示单个测度的值的分布:
- 它一般用横轴表示某个指标维度的数据取值区间,用纵轴表示样本统计的频率或频数,从而能够以二维图的形式展现数值的分布状况
- 为了构建Histogram,首先需要将值的范围进行分段,即将所有值的整个可用范围分成一系列连续、相邻(相邻处可以是等同值)但不重叠的间隔,而后统计每个间隔中有多少值
- 从统计学的角度看,分位数不能被聚合,也不能进行算术运算
对于Prometheus来说,Histogram会在一段时间范围内对数据进行采样(通常是请求持续时长或响应大小等),并将其计入可配置的bucket(存储桶)中
- Histogram事先将特定测度可能的取值范围分隔为多个样本空间,并通过对落入bucket内的观测值进行计数以及求和操作
- 与常规方式略有不同的是,Prometheus取值间隔的划分采用的是累积(Cumulative)区间间隔机制,即每个bucket中的样本均包含了其前面所有bucket中的样本,因而也称为累积直方图:
- 可降低Histogram的维护成本
- 支持粗略计算样本值的分位数
- 单独提供了_sum和_count指标,从而支持计算平均值
Histogram类型的每个指标有一个基础指标名称,它会提供多个时间序列:
- _bucket{le=""}:观测桶的上边界(upper inclusive bound),即样本统计区间,最大区间(包含所有样本)的名称为_bucket{le="+Inf"};
- _sum:所有样本观测值的总和;
- _count :总的观测次数,它自身本质上是一个Counter类型的指标;
累积间隔机制生成的样本数据需要额外使用内置的histogram_quantile()函数即可根据Histogram指标来计算相应的分位数(quantile),即某个bucket的样本数在所有样本数中占据的比例:
- histogram_quantile()函数在计算分位数时会假定每个区间内的样本满足线性分布状态,因而它的结果仅是一个预估值,并不完全准确;
- 预估的准确度取决于bucket区间划分的粒度;粒度越大,准确度越低;
Summary#
指标类型是客户端库的特性,而Histogram在客户端仅是简单的桶划分和分桶计数,分位数计算由Prometheus Server基于样本数据进行估算,因而其结果未必准确,甚至不合理的bucket划分会导致较大的误差;
- Summary是一种类似于Histogram的指标类型,但它在客户端于一段时间内(默认为10分钟)的每个采样点进行统计,计算并存储了分位数数值,Server端直接抓取相应值即可;
- 但Summary不支持sum或avg一类的聚合运算,而且其分位数由客户端计算并生成,Server端无法获取客户端未定义的分位数,而Histogram可通过PromQL任意定义,有着较好的灵活性;
对于每个指标,Summary以指标名称为前缀,生成如下几个个指标序列:
- {quantile="<φ>"},其中φ是分位点,其取值范围是(0 ≤φ≤ 1);计数器类型指标;如下是几种典型的常用分位点;
- 0、0.25、0.5、0.75和1几个分位点;
- 0.5、0.9和0.99几个分位点;
- 0.01、0.05、0.5、0.9和0.99几个分位点;
- _sum,抓取到的所有样本值之和;
- _count,抓取到的所有样本总
Prometheus的聚合函数#
聚合表达式#
PromQL中的聚合操作语法格式可采用如下面两种格式之一:
- ([parameter,] ) [without|by (
- [without|by (
分组聚合:先分组、后聚合
- without:从结果向量中删除由without子句指定的标签,未指定的那部分标签则用作分组标准;
- by:功能与without刚好相反,它仅使用by子句中指定的标签进行聚合,结果向量中出现但未被by子句指定的标签则会被忽略;
- 为了保留上下文信息,使用by子句时需要显式指定其结果中原本出现的job、instance等一类的标签
事实上,各函数工作机制的不同之处也仅在于计算操作本身,PromQL对于它们的执行逻辑相似。
11个聚合函数#
- sum( ):对样本值求和;
- avg ( ) :对样本值求平均值,这是进行指标数据分析的标准方法;
- count ( ) :对分组内的时间序列进行数量统计;
- stddev ( ) :对样本值求标准差,以帮助用户了解数据的波动大小(或称之为波动程度);
- stdvar ( ) :对样本值求方差,它是求取标准差过程中的中间状态;
- min ( ) :求取样本值中的最小者;
- max ( ) :求取样本值中的最大者;
- topk ( ) :逆序返回分组内的样本值最大的前k个时间序列及其值;
- bottomk ( ) :顺序返回分组内的样本值最小的前k个时间序列及其值;
- quantile ( ) :分位数用于评估数据的分布状态,该函数会返回分组内指定的分位数的值,即数值落在小于等于指定的分位区间的比例;
- count_values ( ) :对分组内的时间序列的样本值进行数量统计;
二元运算符#
PromQL支持基本的算术运算和逻辑运算,这类运算支持使用操作符连接两个操作数,因而也称为二元运算符或二元操作符;
支持的运算:#
- 两个标量间运算;
- 即时向量和标量间的运算:将运算符应用于向量上的每个样本;
- 两个即时向量间的运算:遵循向量匹配机制;
将运算符用于两个即时向量间的运算时,可基于向量匹配模式(Vector Matching)定义其运算机制;
算术运算#
支持的运算符:+(加)、-(减)、*(乘)、/(除)、%(取模)和^(幂运算);
比较运算#
支持的运算符:==(等值比较)、!=(不等)、>、<、>=和<=(小于等于);
逻辑/集合运算#
支持的运算符:and(并且)、or(或者)和unless(除了);
目前,该运算仅允许在两个即时向量间进行,尚不支持标量参与运算;
二元运算符优先级#
- ^
- *, /, %
- +, -
- ==, !=, <=, <, >=, >
- and, unless
- or
- 具有相同优先级的运算符满足结合律(左结合),但幂运算除外,因为它是右结合机制;
- 可以使用括号( )改变运算次序;
向量匹配#
即时向量间的运算是PromQL的特色之一;运算时,PromQL为会左侧向量中的每个元素找到匹配的元素,其匹配行为有两种基本类型
- 一对一 (One-to-One)
- 一对多或多对一 (Many-to-One, One-to-Many)
向量一对一匹配#
即时向量的一对一匹配
- 从运算符的两边表达式所获取的即时向量间依次比较,并找到唯一匹配(标签完全一致)的样本值;
- 找不到匹配项的值则不会出现在结果中;
匹配表达式语法:
expr >ignoring(
ignore:定义匹配检测时要忽略的标签;
on:定义匹配检测时只使用的标签;
举例
有这样一组数据:

method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
运算表达式:
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m
如果不加 ignoring(code) 的话,左边将无法匹配到右边的结果,因为两边向量没有完全一致的标签,此时是这种情况:
#左边
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="post", code="500"} 6
#右边
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
只有将code标签忽略,成为这种情况:
#左边
method_code:http_errors:rate5m{method="get"} 24
method_code:http_errors:rate5m{method="post"} 6
#右边
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
这时左边和右边就有一模一样的标签组合,所以完成了1对1匹配。
最终结果:
{method="get"} 0.04 // 24 / 600
{method="post"} 0.05 // 6 / 120
向量一对多/多对一匹配#
- “一”侧的每个元素,可与“多”侧的多个元素进行匹配;
- 必须使用group_left或group_right明确指定哪侧为“多”侧;
匹配表达式语法:
expr >ignoring(
ignore:定义匹配检测时要忽略的标签;
on:定义匹配检测时只使用的标签;
举例
还是这样一组数据:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
运算表达式:
method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m
此时的数据是这样的:
#左边:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
#右边
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
因为忽略的code标签,最终结果:
{method="get", code="500"} 0.04 // 24 / 600
{method="get", code="404"} 0.05 // 30 / 600
{method="post", code="500"} 0.05 // 6 / 120
{method="post", code="404"} 0.175 // 21 / 120
至此,promQL聚合语句基本总结完毕,后续会prometheus的自动发现,以及relabel等常用功能进行演示,欢迎关注。