字符串转数字的用途和场景很多,其中主要包括以下几个方面:
- 数据清洗:在进行数据处理时,经常会遇到一些数据类型不匹配的问题,比如某些列中的字符串类型被误认为是数字类型,此时需要将这些字符串类型转换为数字类型,才能进行后续的数值计算或统计分析。
- 数据整理:有时候输入的原始数据可能存在格式问题,例如有些数值前面带有美元符号或者其他符号,这些符号会干扰后续的计算,因此需要将它们去掉并转换为数字类型。
- 数据可视化:在进行数据可视化时,需要将含有数字信息的字符串转换成数字类型,以便于更好地展示数据、制作图表。
- 机器学习:在机器学习领域中,经常需要将文本或其他非数字类型的特征转换为数字型特征,从而应用各种基于数值型特征的算法模型。
本篇介绍一些常用的字符串转数值的方法。
1. 一般情况
一般情况下,只需要通过 astype 函数就可以改变列的数据类型。
import pandas as pd
df = pd.DataFrame({
"A": [1,2,3],
"B": [1.1,2.2, 3.3],
"C":["1.2", "2.3", "3.3"],
})
df.dtypes
df.C = df.C.astype("float64")
df.dtypes
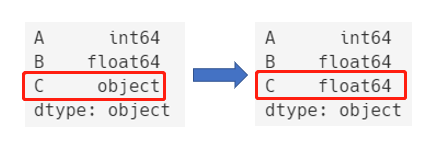
上面的示例把C列有字符串类型转换成了浮点数类型。
2. 异常值情况
上面的示例中,C列中每个字符串都可以正常转换成浮点数,所以用astype函数就可以了。
不过,大部分情况下,待转换的列中会存在无法正常转换的异常值。
直接转换会报错:
df = pd.DataFrame({
"A": [1,2,3],
"B": [1.1,2.2, 3.3],
"C":["1.2", "2.3", "xxx"],
})
df.dtypes
df.C = df.C.astype("float64")
df

这时,可以用 to_numeric 函数,此函数的 errors 参数有3个可选值:
- ignore:出现错误时忽略错误,但是正常的值也不转换
- raise:抛出错误,和
astype函数一样 - coerce:无法转换的值作为
NaN,可转换的值正常转换
df = pd.DataFrame({
"A": [1,2,3],
"B": [1.1,2.2, 3.3],
"C":["1.2", "2.3", "xxx"],
})
df
df.C = pd.to_numeric(df.C, errors="coerce")
df
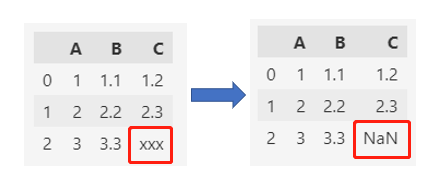
C列正常转换为float64,无法转换的值变成NaN。
如果不希望用NaN来填充异常的值,可以再用 fillna 填充自己需要的值。
df.C = pd.to_numeric(
df.C, errors="coerce"
).fillna(0.0)
df

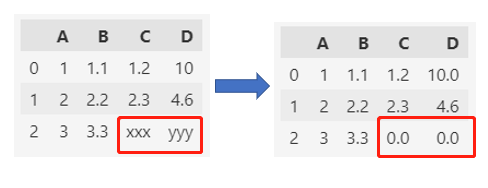
3. 全局转换
如果需要转换成数值类型的列比较多,用上面的方法一个列一个列的转换效率不高。
可以用apply方法配合 to_numeric 一次转换所有的列。
df = pd.DataFrame({
"A": [1,2,3],
"B": [1.1,2.2, 3.3],
"C":["1.2", "2.3", "xxx"],
"D":["10", "4.6", "yyy"],
})
df
df = df.apply(
pd.to_numeric, errors="coerce"
)
df

同样,apply也可以通过fillna填充缺失值NaN。
df = df.apply(
pd.to_numeric, errors="coerce"
).fillna(0.0)
df