-
NIFI实现JSON转SQL并插入到数据库表中
说明
本文中的NIFI是使用docker进行安装的,所有的配置参考:docker安装Apache NIFI
需求背景
现在有一个文件,里面存储的是一些json格式的数据,要求将文件中的数据存入数据库表中,以下是一些模拟的数据和对应的数据库建表语句。
json数据
- [
- {
- "name": "张三",
- "age": 23,
- "gender": 1
- },{
- "name": "李四",
- "age": 24,
- "gender": 1
- },{
- "name": "小红",
- "age": 18,
- "gender": 0
- }
- ]
建表语句
- CREATE TABLE `sys_user` (
- `id` bigint NOT NULL AUTO_INCREMENT COMMENT '用户ID',
- `name` varchar(50) NOT NULL DEFAULT '' COMMENT '姓名',
- `age` int NOT NULL DEFAULT 0 COMMENT '年龄',
- `gender` tinyint NOT NULL COMMENT '性别,1:男,0:女',
- `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `is_deleted` tinyint NOT NULL DEFAULT '0' COMMENT '是否已删除',
- PRIMARY KEY (`id`) USING BTREE
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='用户表';
json数据中的属性名和数据库字段的名要一一对应,要不然后期还得做转换,比较麻烦
创建文件流
添加处理器:GetFile
点击工具栏的Processor,拖拽到画布中

筛选GetFile,点击ADD添加到画布中


配置GetFile处理器
双击添加的处理器,弹出对应的配置界面

(可选操作)点击SETTINGS选项,在Name中输入处理器的名称:获取文件内容

点击SCHEDULING,在Run Schedule中输入定时器的时间,这里设置每10秒运行一次,如果不设置后面运行处理器的时候会无限循环运行

点击PROPERTIES选项

配置PROPERTIES,分别填写Input Directory、File Filter、Keep Source File,其他选项默认即可。
说明:博主的NIFI是使用docker安装的,容器的数据全部挂载到了宿主机中,NIFI的HOME默认是在/opt/nifi/nifi-current,挂载到宿主机的路径为:/root/data/nifi/nifi-current。所以Input Directory中填写的路径/opt/nifi/nifi-current/mydata/file 实际对应宿主机路径为:/root/data/nifi/nifi-current/mydata/file,到时候把测试文件放到宿主机的/root/data/nifi/nifi-current/mydata/file下面即可

将文件放到对应的目录下
说明:mydata/file中的所有文件需要有读写的权限,否则后面读取文件会报错
修改权限:
chmod +777 /root/data/nifi/nifi-current/mydata/file

(可选操作)测试处理器配置是否成功
添加LogAttribute处理器


连接处理器
将鼠标放到第一个处理器上,然后点击出现的箭头,将其拖拽到第二个处理器中,等待线条由红色变为绿色后,松开鼠标即可。


在弹出的界面中勾选success,然后点击ADD

 第一个显示红色方框的代表当前处理器可以正常使用;第二个出现黄色三角感叹号的代表当前处理器有问题,双击第二个处理器。
第一个显示红色方框的代表当前处理器可以正常使用;第二个出现黄色三角感叹号的代表当前处理器有问题,双击第二个处理器。
在弹出的界面选择RELATIONSHIPS选项卡,在success下勾选terminate,最后点击APPLY
说明:success下面的两个选项:terminate和retry分别代表着当前处理器执行成功的操作
terminate代表成功后终止,retry代表成功后继续尝试

可以看到黄色的三角变成了红色的方框,表示当前处理器没问题了。
运行处理器
运行处理器有两种方式,第一种是一个一个单独运行另一种是直接运行全部
第一种
鼠标放到第一个处理器中然后右键,可以看到有一堆选项,这里运行处理器可以选择Sart或者Run Once,为了方便调试,这里选择Run Once即只运行一次

点击Run Once之后可以看到,在处理器的右上角多了一个标志,这个代表当前有几个线程在运行中

当处理器的任务执行结束后可以看到两个处理器的连接处会显示当前有几个队列,以及队列数据总的大小

将鼠标放到两个处理器的连接处,鼠标右键,选择List queue
 在弹出的界面中可以看到等待中的队列列表
在弹出的界面中可以看到等待中的队列列表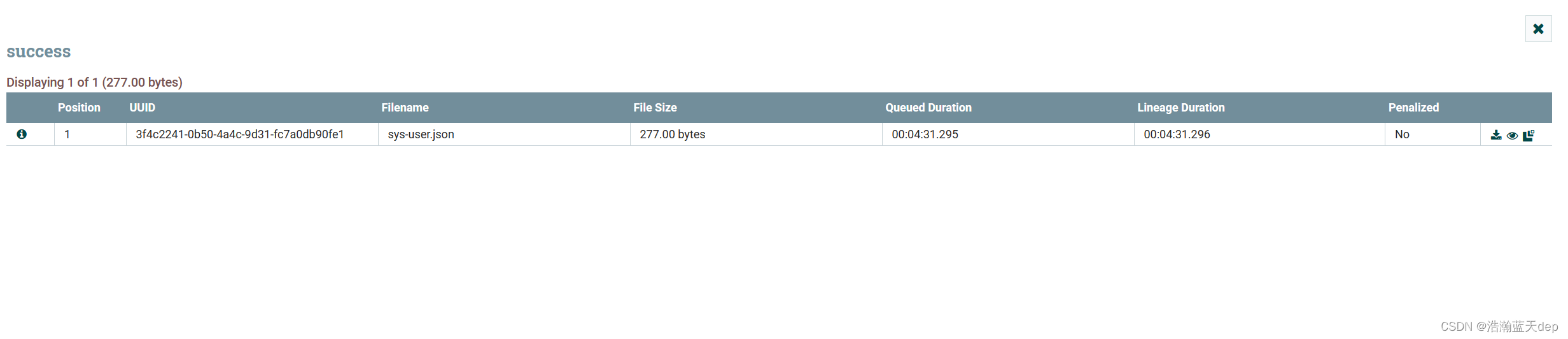
选择其中一个队列,点击左上角的提示,可以看到上一个处理器(GetFile)的一些信息,包括一些属性啊什么的,这个可以自己去看,这里不再仔细说明。点击OK可以关闭当前的弹框

 点击某一个队列的右上角,第一个可以下载当前的内容,中间的小眼睛可以查看队列中的数据
点击某一个队列的右上角,第一个可以下载当前的内容,中间的小眼睛可以查看队列中的数据
点击小眼睛,可以看到文件中的内容显示在了页面中,默认是original,也可以选择formatted和hex

运行第二个处理器(LogAttribute),同样的鼠标放到处理器上,然后选择Run Once即可
然后可以在nifi的日志中看到打印了一些日志,主要包括了处理器的属性和内容
说明:如果要想打印出文件的内容,LogAttribute处理器需要选择以下内容


正常打印数据说明GetFile处理器配置的没问题
Json数组分隔
添加处理器:SplitJson


配置SplitJson处理器
双击处理器,在弹出的界面点击PROPERTIES选项卡,配置以下内容
JsonPath Expression(JSON 路径表达式):指定要提取的 JSON 对象的路径。例如,如果要提取根级别的 JSON 对象,可以将路径设置为
$。
连接处理器
将GetFile处理器和SplitJson处理器连接起来,勾选For Relationships,然后选择ADD
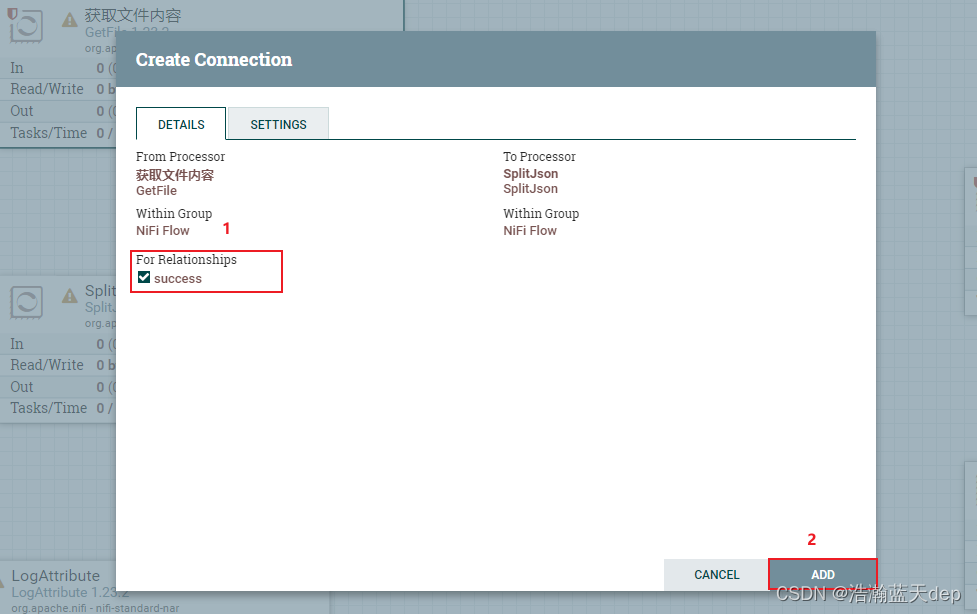
(可选操作)测试处理器配置是否成功
将SplitJson处理器和LogAttribute处理器连接,连接处理器中的For Relationships选择split


此时发现SplitJson处理器还在告警,双击SplitJson处理器,选择RELATIONSHIPS,按照如图勾选

此时所有的处理器已正常显示

开启所有的处理器(在画布空白处鼠标右键,点击Start),查看nifi容器的日志,可以看到此时日志打印出来的不再是整个文件的内容,而是单独一条一条json数据

停止所有处理器(画布空白处鼠标右键,选择Stop),清空队列中的数据,在连接处鼠标右键,选择Empty queue

Json转为SQL
添加处理器:ConvertJSONToSQL


配置ConvertJSONToSQL处理器
双击处理器,在弹出的界面点击PROPERTIES选项卡,配置以下内容
配置JDBC Connection Pool
Value下面点击,选择Create new service
根据自己的情况选择对应的services,我这里选择的是默认的

点击最后面的右箭头


点击右侧的小齿轮

切换到SETTINGS选项卡,给驱动起个名字,方便以后识别

切换到PROPERTIES选项卡 ,配置数据库相关参数,其他按照默认的即可

校验参数配置是否正确,点击右上角的对号

校验通过会出现绿色对钩,如果配置不对会有对应提示,最后点击APPLY
 开启JDBC的配置,点击闪电符号,在弹出的界面点击ENABLE,最后点击CLOSE
开启JDBC的配置,点击闪电符号,在弹出的界面点击ENABLE,最后点击CLOSE
 最后可以看到state已经变为Enabled,点击右上角的X关闭
最后可以看到state已经变为Enabled,点击右上角的X关闭
到此JDBC的配置结束
配置Statement Type
再次双击处理器,配置Statement Type,选择INSERT,代表生成的是INSERT语句

配置Table Name

校验配置是否正确
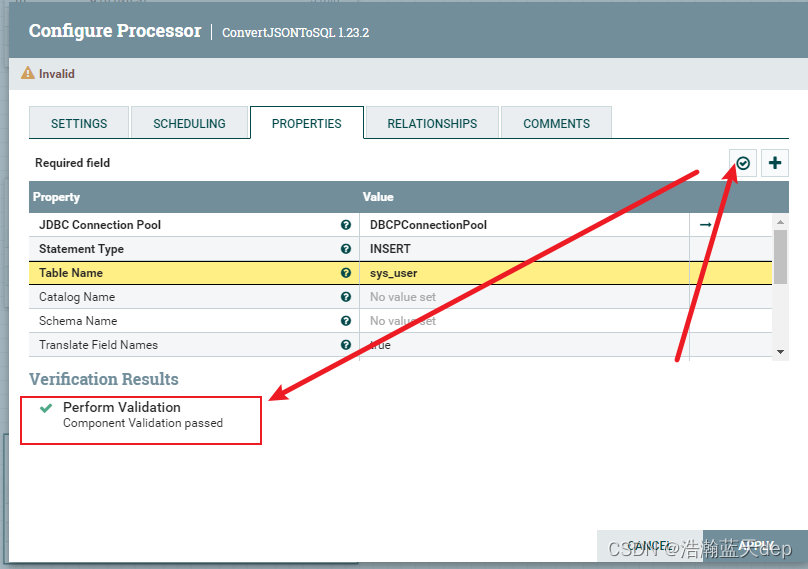
最后点击APPLY
连接处理器
将SplitJson处理器和ConvertJSONToSQL处理器进行连接,Relationships选择split

(可选操作)测试处理器配置是否成功
这里跳过测试,如果需要测试自己的配置是否正确的,可以自行将处理器和LogAttribute处理器进行连接进行测试,以下是博主自己的测试结果,做个参考,最后面会打印生成的SQL语句

执行生成的SQL
添加处理器:PutSQL


配置PutSQL处理器
双击处理器,在PROPERTIES选项卡中配置以下内容,其他内容默认即可


校验配置是否正确

最后点击APPLY
连接处理器
将ConvertJSONToSQL处理器和PutSQL处理器进行连接,Relationships选择sql

处理PutSQL处理器的告警
双击处理器,在RELATIONSHIPS选项卡配置勾选以下内容

完整的配置结果
包含四个处理器,依次为GetFile=>SplitJson=>ConvertJSONToSQL=>PutSQL
 开启所有的处理器
开启所有的处理器数据库是否有数据
可以看到现在的数据库里面还是没有数据的

开启处理器
在画布的空白位置,鼠标右键选择Start

开启后可以看到所有的处理器左上角都显示为绿色三角,表示处理器已经启动了,过十几秒再看处理器,发现已经有数据流入

查看数据库数据
此时数据库已经有数据插入,重复数据是因为每隔10秒执行一次任务,就会读取一次文件,然后重复往数据库插入数据,如果不想让数据不停插入数据库,可以将GetFile中的PROPERTIES下的Keep Source File设置为false即可(此操作需要停止处理器才能够设置)

结束语
NIFI学习需要花费一定的时间去仔细研究,它里面内置了大概300多个处理器,每个处理器实现的功能都不一样,配置也都不同。博主也正在不断地学习中,后续也会不断分享关于NIFI的内容,如果有什么疑问欢迎评论区进行评论。
-
相关阅读:
(赠源码)基于SSM&Mysql网上购物系统12503-计算机毕业设计
云服务器安装docker环境
轻松掌握组件启动之MongoDB(上):高可用复制集架构环境搭建
备战秋招--mysql篇
Spring AOP
数字音频处理--延时音效实现
Linux 之 split 切分大文件 cat 合并多个小文件
js将带标签的内容转为纯文本
【MM小贴士】从 purchase 到 payment 全流程演示
【C#数据的存储】
- 原文地址:https://blog.csdn.net/LSW_JAVADP/article/details/132673455