-
generative-model [ From GAN to WGAN ]
目录
Kullback–Leibler and Jensen–Shannon Divergence
Generative Adversarial Network (GAN)
What is the optimal value for D?
What does the loss function represent?
Hard to achieve Nash equilibrium
Lack of a proper evaluation metric
Why Wasserstein is better than JS or KL divergence?
Use Wasserstein distance as GAN loss function
生成对抗网络 (GAN) 在许多生成任务中显示出出色的结果,以复制现实世界的丰富内容,如图像、人类语言和音乐。它受到博弈论的启发:两个模型,一个生成器和一个批评者,在相互竞争的同时使彼此变得更强大。然而,训练GAN模型是相当具有挑战性的,因为人们面临着训练不稳定或无法收敛等问题。
在这里,我想解释生成对抗网络框架背后的数学原理,为什么很难训练,最后介绍一个旨在解决训练困难的GAN的修改版本。
Kullback–Leibler and Jensen–Shannon Divergence
在我们开始仔细研究 GAN 之前,让我们首先回顾一下量化两个概率分布之间相似性的指标。

一些人认为(Huszar,2015)GANs取得巨大成功背后的一个原因是将损失函数从传统最大似然方法中的不对称KL散度转换为对称JS散度。
Generative Adversarial Network (GAN)
GAN由两个模型组成:
- 鉴别器D:估计给定样本来自真实数据集的概率。它充当评论家,并经过优化以区分假样品和真实样本。
- 发电机G:输出给定噪声变量输入的合成样本z (z带来潜在的产出多样性)。它被训练来捕获真实的数据分布,以便其生成样本可以尽可能真实,或者换句话说,可以欺骗鉴别器提供高概率。
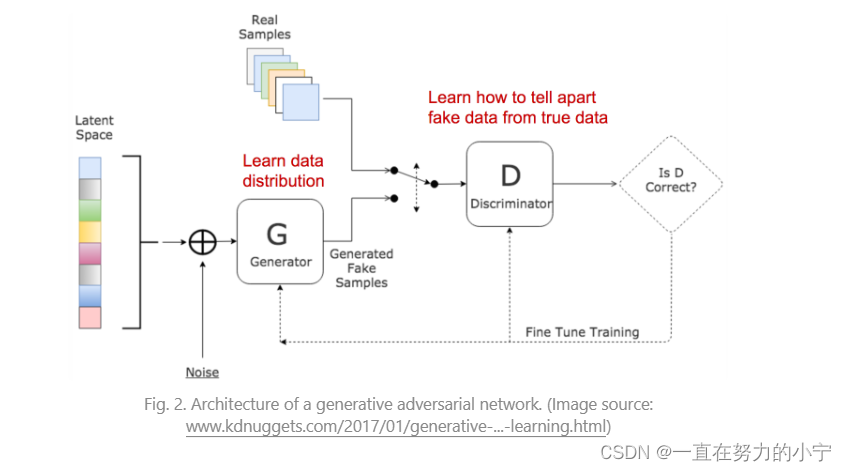
这两个模型在训练过程中相互竞争:
生成器G极力欺骗鉴别者,而批评者模特D正在努力不被骗。
两种模型之间这种有趣的零和博弈激励双方改进其功能。
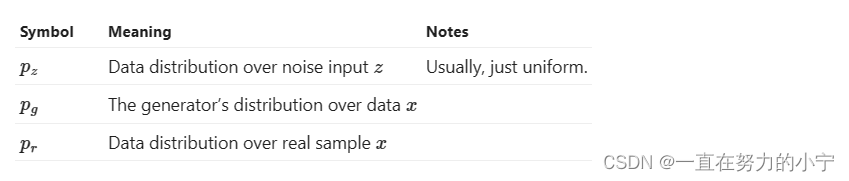
What is the optimal value for D?

What is the global optimal?
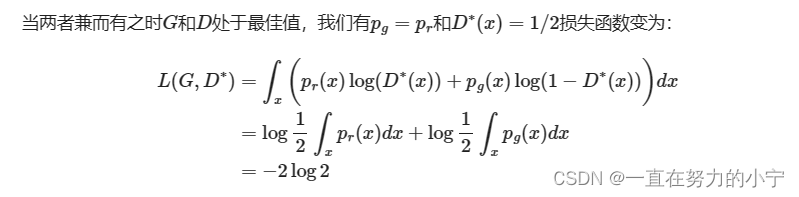
What does the loss function represent?

Problems in GANs
尽管GAN在逼真的图像生成方面取得了巨大的成功,但培训并不容易;众所周知,该过程缓慢且不稳定。
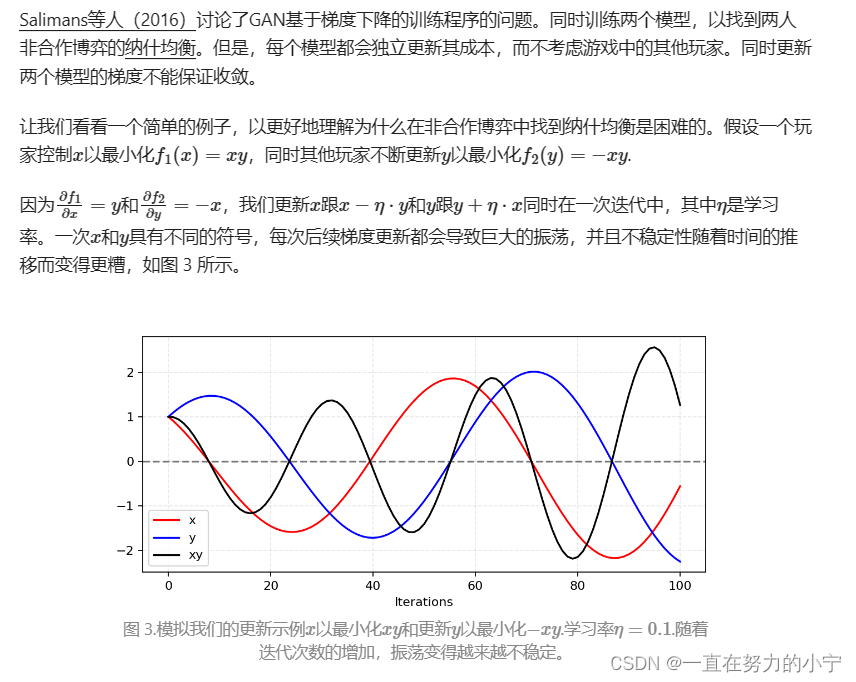
Hard to achieve Nash equilibrium
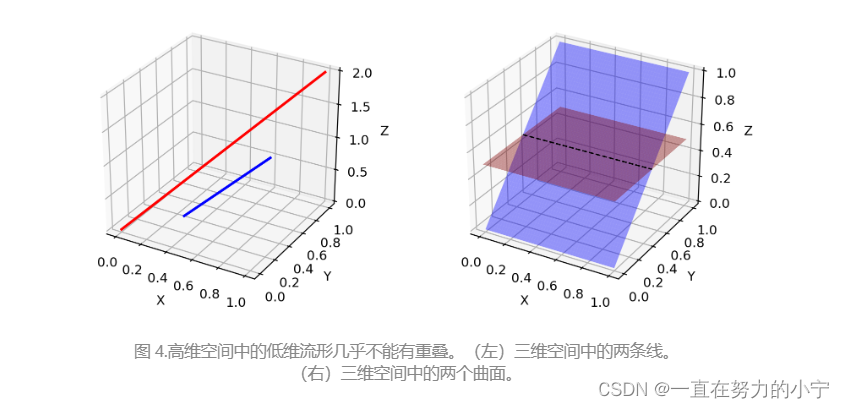
Low dimensional supports

Vanishing gradient
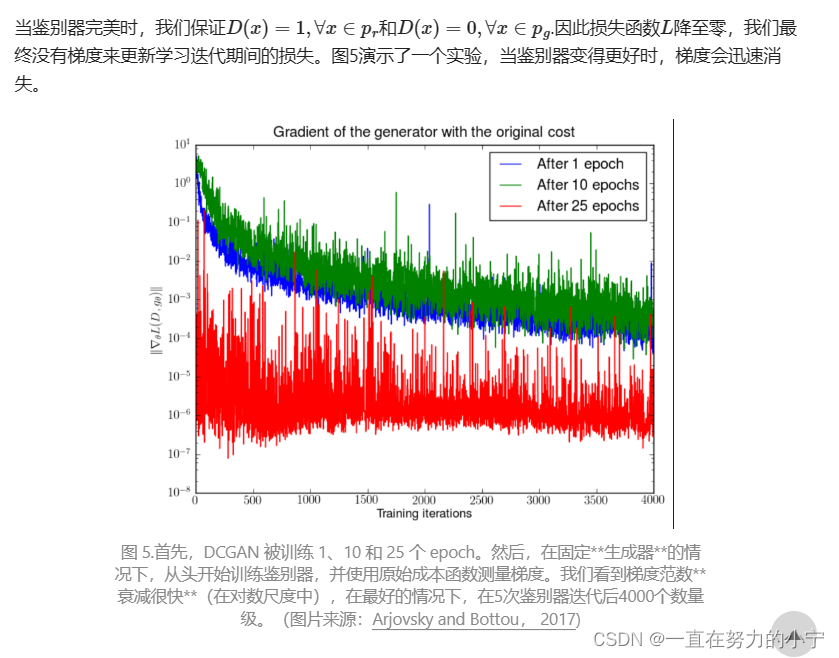
因此,训练GAN面临两难境地:
- 如果鉴别器行为不佳,则生成器没有准确的反馈,损失函数无法代表现实。
- 如果鉴别器做得很好,损失函数的梯度会下降到接近零,学习变得非常慢甚至卡住。
这种困境显然能够使GAN培训变得非常艰难。
Mode collapse
在训练期间,生成器可能会折叠到始终产生相同输出的设置。这是 GAN 的常见故障情况,通常称为模式崩溃。尽管生成器可能能够欺骗相应的鉴别器,但它无法学习表示复杂的真实世界数据分布,并且被困在一个种类极低的小空间中。

Lack of a proper evaluation metric
生成对抗网络并不是天生就有良好的反对函数,可以通知我们训练进度。如果没有一个好的评估指标,就像在黑暗中工作一样。没有好的迹象可以告诉何时停止;没有很好的指标来比较多个模型的性能。
Improved GAN Training
前五种方法是实现GAN训练更快收敛的实用技术,在“改进训练GAN的技术”中提出。 最后两个在“面向训练生成对抗网络的原则方法”中提出,以解决不相交分布问题。
(1) Feature Matching

(2) Minibatch Discrimination

(3) Historical Averaging

(4) One-sided Label Smoothing
馈送鉴别器时,不要提供 1 和 0 标签,而是使用 0.9 和 0.1 等软化值。它被证明可以减少网络的脆弱性。
(5) Virtual Batch Normalization (VBN)
每个数据样本都基于固定的数据批次(“参考批次”)进行规范化,而不是在其小批量中。参考批次在开始时选择一次,并在整个训练过程中保持不变。
(6) Adding Noises.

(7) Use Better Metric of Distribution Similarity

Wasserstein GAN (WGAN)
What is Wasserstein distance?


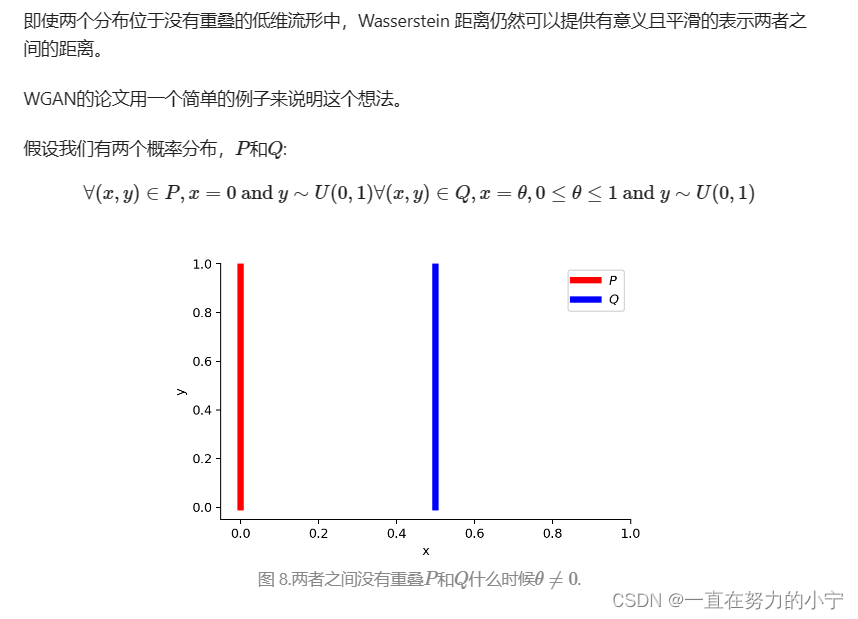
Why Wasserstein is better than JS or KL divergence?

Use Wasserstein distance as GAN loss function

Lipschitz continuity?


与原始GAN算法相比,WGAN进行了以下更改:
可悲的是,Wasserstein GAN并不完美。甚至原始WGAN论文的作者也提到“权重裁剪显然是强制执行Lipschitz约束的可怕方法”(哎呀!WGAN仍然存在不稳定的训练,权重裁剪后收敛缓慢(当裁剪窗口太大时)和梯度消失(当裁剪窗口太小时)。
Gulrajani 等人 2017 年讨论了一些改进,精确地用梯度惩罚代替了重量裁剪。我将把这个问题留到以后的帖子中。
Example: Create New Pokemons!

笔记摘自Lil'Log
From GAN to WGAN
 https://lilianweng.github.io/posts/2017-08-20-gan/
https://lilianweng.github.io/posts/2017-08-20-gan/ -
相关阅读:
【C++】:模板的使用
Redis巡检检查 redis-check-aof
微服务间的测试策略
最强大脑记忆曲线(9)——按错误频率排序待听写内容
2022-05-05 mybatis-plus 批量插入修改操作
【数据结构】深入理解AVL树:实现和应用
Win11怎么以管理员身份运行?Win11以管理员身份运行的设置方法
深入理解 Docker 核心原理:Namespace、Cgroups 和 Rootfs
初探Matrix Android ApkChecker
数据挖掘——matplotlib
- 原文地址:https://blog.csdn.net/qq_53826699/article/details/132603422