-
Redis的缓存穿透,缓存击穿,缓存雪崩
1. 缓存穿透
什么是缓存穿透?
缓存穿透说简单点就是大量请求的 key 是不合理的,根本不存在于缓存中,也不存在于数据库中 。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。

eg:某个黑客故意制造一些非法的 key 发起大量请求,导致大量请求落到数据库,结果数据库上也没有查到对应的数据。也就是说这些请求最终都落到了数据库上,对数据库造成了巨大的压力。
方案:最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
(1)缓存无效 key
如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下:SET key value EX 10086 。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。另外,这里多说一嘴,一般情况下我们是这样设计 key 的:表名:列名:主键名:主键值 。
代码:public Object getObjectInclNullById(Integer id) { // 从缓存中获取数据 Object cacheValue = cache.get(id); // 缓存为空 if (cacheValue == null) { // 从数据库中获取 Object storageValue = storage.get(key); // 缓存空对象 cache.set(key, storageValue); // 如果存储数据为空,需要设置一个过期时间(300秒) if (storageValue == null) { // 必须设置过期时间,否则有被攻击的风险 cache.expire(key, 60 * 5); } return storageValue; } return cacheValue; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(2)布隆过滤器
布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。加入布隆过滤器之后的缓存处理流程图如下。
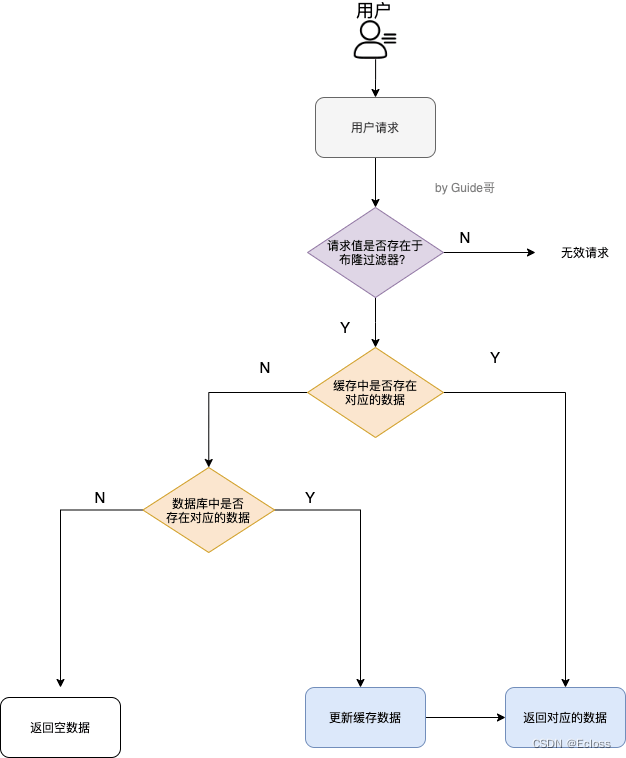
但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理来说!
我们先来看一下,当一个元素加入布隆过滤器中的时候,会进行哪些操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
我们再来看一下,当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行哪些操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
然后,一定会出现这样一种情况:不同的字符串可能哈希出来的位置相同。 (可以适当增加位数组大小或者调整我们的哈希函数来降低概率)
2. 缓存击穿
什么是缓存击穿
缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期) 。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
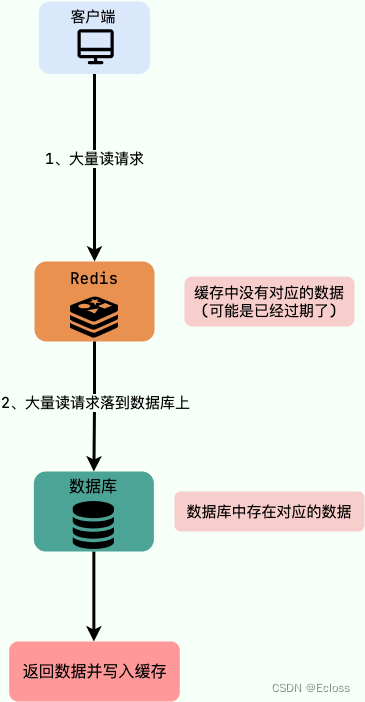
eg:秒杀进行过程中,缓存中的某个秒杀商品的数据突然过期,这就导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成了巨大的压力。方案:
- 设置热点数据永不过期或者过期时间比较长。
- 针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
- 请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力。
3. 缓存雪崩
什么是缓存雪崩
实际上,缓存雪崩描述的就是这样一个简单的场景:缓存在同一时间大面积的失效,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
另外,缓存服务宕机也会导致缓存雪崩现象,导致所有的请求都落到了数据库上。
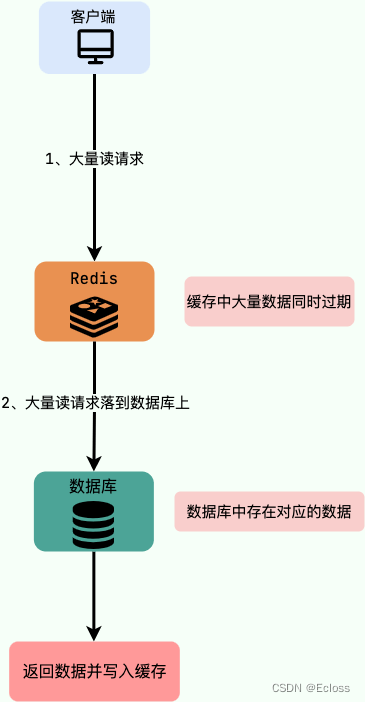
eg:数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。解决方案:
针对 Redis 服务不可用的情况:
- 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
- 限流,避免同时处理大量的请求。
针对热点缓存失效的情况:
- 设置不同的失效时间比如随机设置缓存的失效时间。
- 缓存永不失效(不太推荐,实用性太差)。
- 设置二级缓存。
-
相关阅读:
持安科技孙维伯:零信任在攻防演练下的最佳实践|DISCConf 2023
华为OD机试之最小调整顺序次数、特异性双端队列(Java源码)
敏捷与xjbg的细微差别
JavaScript基础知识11——运算符:赋值运算符
selenium也能过某数、5s盾..
element ui 中文离线文档(百度云盘下载)
31.下一个排列
vue+ts vite环境项目取不到process 解决方法
如何选择适合你的隧道爬虫ip?
客厅、厨房、卫生间瓷砖怎么挑选,看完不再烦恼!福州中宅装饰,福州装修
- 原文地址:https://blog.csdn.net/Ecloss/article/details/132596940
