-
【大数据工具】Kafka伪分布式、分布式安装和Kafka-manager工具安装与使用
Kafka 安装
Kafka 安装包下载地址:https://archive.apache.org/dist/kafka/
1. Kafka 伪分布式安装
1. 上传并解压 Kafka 安装包
- 使用 FileZilla 或其他文件传输工具上传 Kafka 安装包:
kafka_2.11-0.10.0.0.tgz - 解压安装包
[root@bigdata software]# tar -zxvf kafka_2.11-0.10.0.0.tgz- 1
2. 编辑配置文件
[root@bigdata software]# mv kafka_2.11-0.10.0.0 kafka [root@bigdata software]# cd kafka/config/ [root@bigdata config]# cp server.properties server1.properties [root@bigdata config]# vi server1.properties # 每台 brokerId 都不相同,此处设置1 broker.id=1 # 在 log.retention.hours=168 后新增下面三行 message.max.byte=5242880 default.replication.factor=1 replica.fetch.max.bytes=5242880 # 设置zookeeper的连接端口(按实际填写即可,下边zk也是伪分布的) # 说明:直接用节点名:端口,需要在本机 /etc/hosts 中编写解析 172.16.15.111 bigdata zookeeper.connect=bigdata:2181,bigdata:2182,bigdata:2183 # 日志文件的目录,自定义即可,注意区分 log.dirs=/software/kafka/logs/worker1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3. 拷贝并修改配置文件
[root@bigdata config]# cp server1.properties server2.properties [root@bigdata config]# cp server1.properties server3.properties- 1
- 2
分别修改 server2.properties、server3.properties
[root@bigdata config]# vi server2.properties broker.id=2 log.dirs=/software/kafka/logs/worker2 [root@bigdata config]# vi server3.properties broker.id=3 log.dirs=/software/kafka/logs/worker3- 1
- 2
- 3
- 4
- 5
- 6
- 7
4. 创建日志文件
[root@bigdata config]# cd ../logs [root@bigdata logs]# mkdir worker1 worker2 worker3- 1
- 2
5. 验证
[root@bigdata kafka]# ./bin/kafka-server-start.sh -daemon ./config/server1.properties [root@bigdata kafka]# ./bin/kafka-server-start.sh -daemon ./config/server2.properties [root@bigdata kafka]# ./bin/kafka-server-start.sh -daemon ./config/server3.properties [root@bigdata kafka]# jps 10131 Kafka 10611 Kafka 10389 Kafka 10693 Jps- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6. 创建 Topic
# 创建Topic t1 [root@bigdata kafka]# ./bin/kafka-topics.sh --create --zookeeper bigdata:2181 --replication-factor 1 --partitions 1 --topic t1 Created topic "t1". # 查看Topic列表(list) [root@bigdata kafka]# ./bin/kafka-topics.sh --list --zookeeper bigdata:2181 t1 # 查看指定Topic信息(describe) [root@bigdata kafka]# ./bin/kafka-topics.sh --describe --zookeeper bigdata:2181 --topic t1 Topic:t1 PartitionCount:1 ReplicationFactor:1 Configs: Topic: t1 Partition: 0 Leader: 1 Replicas: 1 Isr: 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
7. 测试生产和消费消息
- 打开生产者客户端并发送消息
[root@bigdata kafka]# ./bin/kafka-console-producer.sh --broker-list bigdata:9092 --topic t1 hello world # 输入 hello world 后回车,即表示已发送消息- 1
- 2
- 新打开一个终端窗口链接 bigdata,并启动客户端接收消息
[root@bigdata kafka]# ./bin/kafka-console-consumer.sh --bootstrap-server bigdata:9092 --zookeeper bigdata:2182 --topic t1 --from-beginning hello world- 1
- 2
至此,Kafka 伪分布式集群安装完成!
2. Kafka 分布式安装
部署安装 Kafka 与 ZooKeeper。理论上 Kafka 与 ZooKeeper 不应该搭建到一起
1、上传解压重命名
tar –zxvf kafka_2.12-2.2.0.tar.gz mv kafka_2.12-2.2.0 kafka- 1
- 2
2、修改配置
cd /software/kafka/config/ vi server.properties # 在log.retention.hours=168 后新增下面三项 message.max.byte=5242880 default.replication.factor=1 replica.fetch.max.bytes=5242880 # 设置zookeeper的连接端口 zookeeper.connect=hadoop0:2181,hadoop1:2181,hadoop2:2181 # 日志文件的目录,设置成刚刚创建的logs目录 log.dirs=/software/kafka/logs/- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3、将 kafka 拷贝到集群节点
scp -r kafka/ root@172.16.15.101:/software/ scp -r kafka/ root@172.16.15.102:/software/- 1
- 2
4、修改集群节点
kafka/config/server.properties中 broker.id 值cd /software/kafka/config/ vi server.properties # 每台brokerId都不相同,Hadoop1修改broker.id=1,Hadoop2修改broker.id=2 broker.id=0- 1
- 2
- 3
- 4
5、验证集群
- 启动 Kafka(集群各节点全部执行):
# 启动命令(Kafka目录下): ./bin/kafka-server-start.sh -daemon ./config/server.properties # 执行jps会打印kafka进程 [root@hadoop0 kafka]# jps 18295 Kafka 19086 Jps # 或使用ps -ef | grep kafka 也可以查到 # 停止命令(Kafka目录下): ./bin/kafka-server-stop.sh- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3. Kafka监控软件 Kafka-manager
1. Kafka-manager 功能介绍
- 管理多个 Kafka 集群
- 便捷的检查 Kafka 集群状态(topic,broker,备份分布情况,分区分布情况)
- 选择要运行的副本
- 基于当前分区状况进行
- 可以选择 topic 配置并创建 topic(0.8.1.1 和 0.8.2 的配置不同)
- 删除 topic(只支持 0.8.2 以上的版本并且要在 broker 配置中设置 delete.topic.enable=true)
- Topic list 会指明哪些 topic 被删除(0.8.2 以上版本使用)
- 为已存在的 topic 增加分区
- 为已存在的 topic 更新配置
- 在多个 topic 上批量重分区
- 在多个 topic 上批量重分区(可选 partition broker 位置)
2. Kafka-manager 安装
将 kafka-manager-1.3.3.7.zip 安装包导入
Hadoop0:/software/下进行解压:[root@hadoop0 software]# unzip kafka-manager-1.3.3.7.zip -d .- 1
修改配置:
[root@hadoop0 software]# cd kafka-manager-1.3.3.7/ [root@hadoop0 kafka-manager-1.3.3.7]# vim conf/application.conf # 注释下面一行行,添加第二行 # kafka-manager.zkhosts="localhost:2181" kafka-manager.zkhosts="172.16.15.100:2181,172.16.15.101:2181,172.16.15.102:2181"- 1
- 2
- 3
- 4
- 5
启动:
# Kafka-manager目录下: # 方式一:按默认方式启动,默认端口为9000 bin/kafka-manager # 方式二:指定配置文件位置和启动端口号: # 可通过 -Dconfig.file=conf/application.conf 指定配置文件; -Dhttp.port 指定端口 nohup bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=8080 & [root@hadoop0 kafka-manager-1.3.3.7]# bin/kafka-manager 15:03:48,422 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Could NOT find resource [logback.groovy] 15:03:48,422 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Could NOT find resource [logback-test.xml] ... [info] play.api.Play - Application started (Prod) [info] p.c.s.NettyServer - Listening for HTTP on /0:0:0:0:0:0:0:0:9000 [info] k.m.a.KafkaManagerActor - Updating internal state... [info] k.m.a.KafkaManagerActor - Updating internal state... # 以下页面的操作完成后,使用 Ctrl+C 退出- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这样就说明kafka_manager服务端口已经监听啦,我们可以直接去访问kafka-manager的web UI页面了:
172.16.15.100:9000 # 默认端口 9000- 1

- 可以在当前目录下看到新生成了
RUNNING_PID文件:
[root@hadoop0 kafka-manager-1.3.3.7]# ll 总用量 28 drwxr-xr-x 3 root root 18 11月 4 22:47 application.home_IS_UNDEFINED drwxr-xr-x 2 root root 52 11月 4 22:37 bin drwxr-xr-x 2 root root 136 11月 4 23:56 conf drwxr-xr-x 2 root root 8192 11月 4 22:37 lib -rw------- 1 root root 98 11月 4 23:44 nohup.out -rw-r--r-- 1 root root 6335 6月 5 2017 README.md -rw-r--r-- 1 root root 5 11月 5 00:02 RUNNING_PID # this one! drwxr-xr-x 3 root root 17 11月 4 22:37 share- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3. Kafka-manager 使用
1. 创建集群
- 点击【Cluster】,选择【Add Cluster】添加集群

- 填写 zk 集群的各机器 ip 与端口,选择 kafka 版本(尽量选择版本比较低的,相对稳定一些),下边默认为 1 的输入框输入 3(大于等于 2)即可:

-
注意:如果没有在 Kafka 中配置过
JMX_PORT,千万不要选择第一个复选框:Enable JMX Polling。如果选择了该复选框,Kafka-manager 可能会无法启动。 -
保存之后,就可以看到详细的信息了:

- 选择集群列表即可看到刚才创建的 Kafka 集群了:

- 可以修改(modify)和禁用(disable)
2. 创建主题
- 顶部菜单栏选择【Topic】,点击【Create】,填写名称、分区、副本:
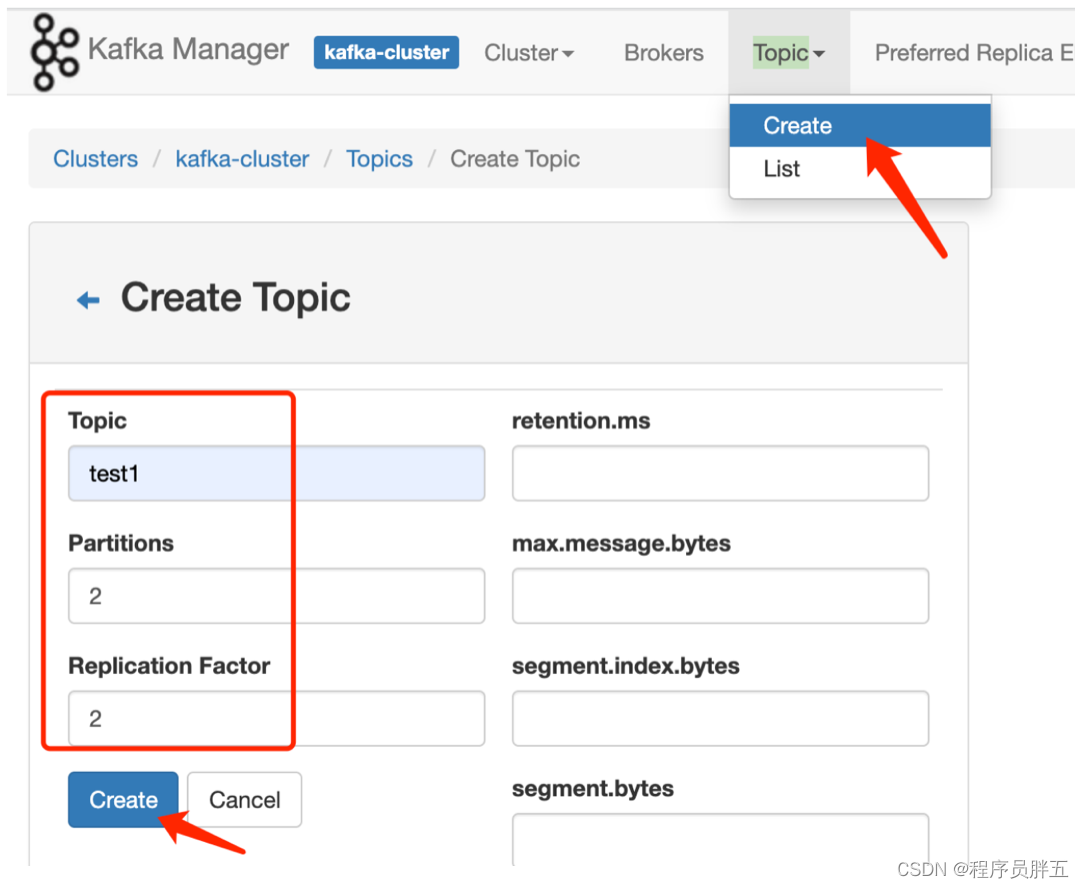
- 图解:

说明:
- 在上图的一个 Kafka 集群中,有两个服务器,每个服务器上都有 2 个分区。P0、P3 可能属于同一个主题,也可能是两个不同的主题;
- 如果设置的 Partitions 和 Replication Factor 都是 2,这种情况下该主题的分布就和上图中 Kafka 集群显示的相同,此时,P0、P3 是同一个主题的两个分区;P1、P2 也是同一个主题的两个分区,Server1、Server2 其中一个会作为 Leader 进行读写操作,另一个通过复制进行同步;
- 如果设置的 Partitions 和 Replication Factor 都是 1,则只会根据算法在某个 Server 上创建一个分区,可以是 P0~P4 中的某一个(分区都是新建的,不是先存在 4 个然后从中取 1)
创建完成即可看到:
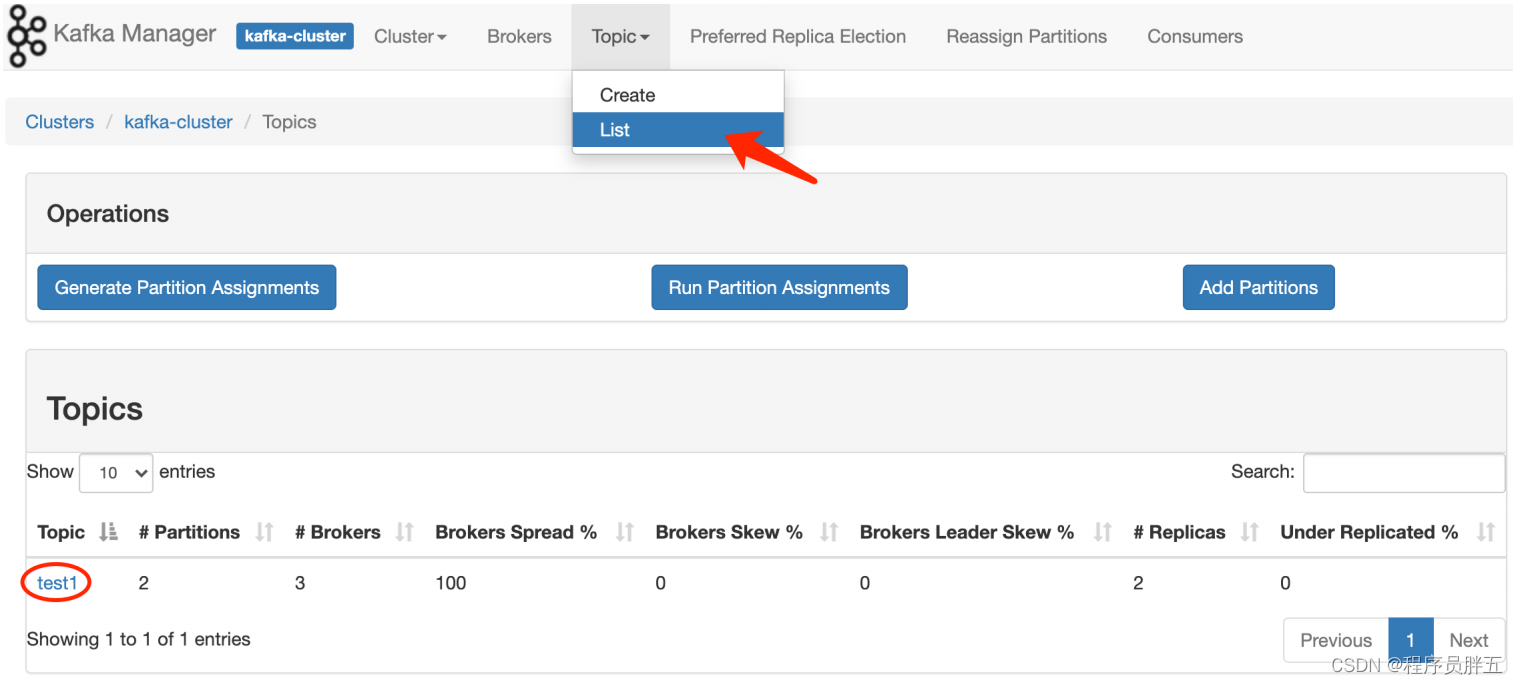
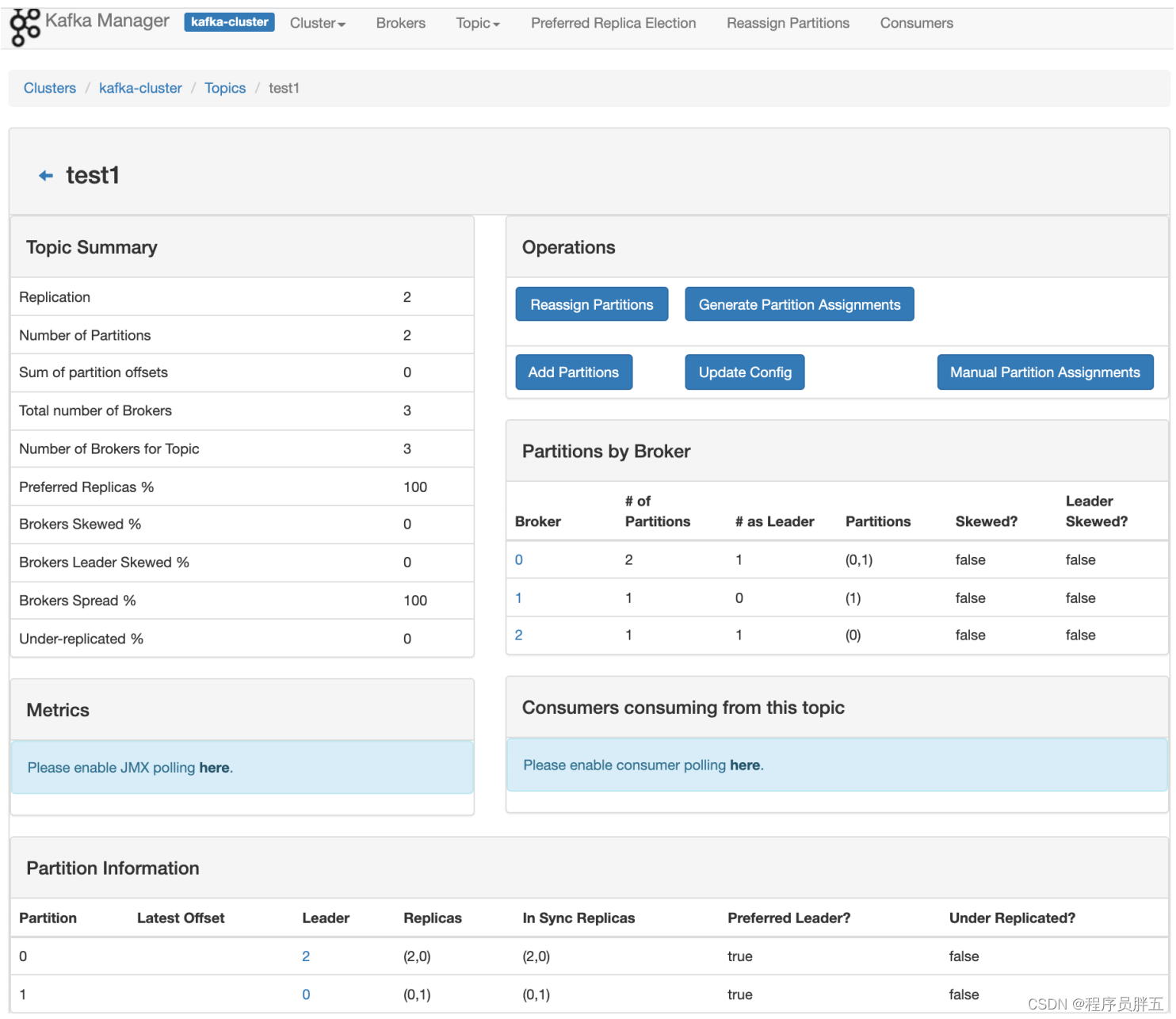
- 点击详细内容:
- 使用 FileZilla 或其他文件传输工具上传 Kafka 安装包:
-
相关阅读:
一文了解企业云盘和大文件传输哪个更适合企业传输
冰冰学习笔记:快速排序
【NLP】第 6 章:用于文本分类的卷积神经网络
驱动初级Day03_内核模块下_参数和依赖
2311d更好C析构类
ESP8266与单片机通信共地问题
linux中配置qt OpenCV的环境
Theme Studio(主题工作室)
docker 容器内服务随容器自动启动
C/C++ 如何实现和使用链表(linked list)
- 原文地址:https://blog.csdn.net/weixin_45579026/article/details/131080525
