-
cuda编程学习——GPU加速/时间计时Clock 干货向(五)
前言
参考资料:
高升博客
《CUDA C编程权威指南》
以及 CUDA官方文档
CUDA编程:基础与实践 樊哲勇
我已经更新了我的Github仓库,大家可以前往仓库下载代码
我的CUDA学习仓库
文章、讲解视频同步更新公众《AI知识物语》,B站:出门吃三碗饭
1:常用的计时方式
1cudaEvent_t start, stop; 2CHECK(cudaEventCreate(&start)); 3CHECK(cudaEventCreate(&stop)); 4CHECK(cudaEventRecord(start)); 5cudaEventQuery(start); // 此处不能用 CHECK 宏函数(见第 4 章的讨论) 6 7 需要计时的代码块 8 9 CHECK(cudaEventRecord(stop)); 10CHECK(cudaEventSynchronize(stop)); 11 float elapsed_time; 12 CHECK(cudaEventElapsedTime(&elapsed_time, start, stop)); 13printf("Time = %g ms.\n", elapsed_time); 14 15CHECK(cudaEventDestroy(start)); 16CHECK(cudaEventDestroy(stop));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
第1行:定义2个cuda事件类型cudaEvent的变量start,stop
第2 3行:使用cudaEventCreate函数初始化两个变量
第4行:将 start 传入 cudaEventRecord 函数,在需要计时的代码块之前记录一个代表 开始的事件
第5行:对处于 TCC 驱动模式的 GPU 来说可以省略,但对处于 WDDM 驱动模式 的GPU来说必须保留
第7行:代表一个需要计时的代码块
第9行:将stop传入cudaEventRecord函数,在需要计时的代码块之后记录一个代表结 束的事件。
第10行: cudaEventSynchronize 函数让主机等待事件 stop 被记录完毕
第11-13行:调用 cudaEventElapsedTime 函数计算 start 和 stop 这两个事件之间的时 间差(单位是 ms)并输出到屏幕
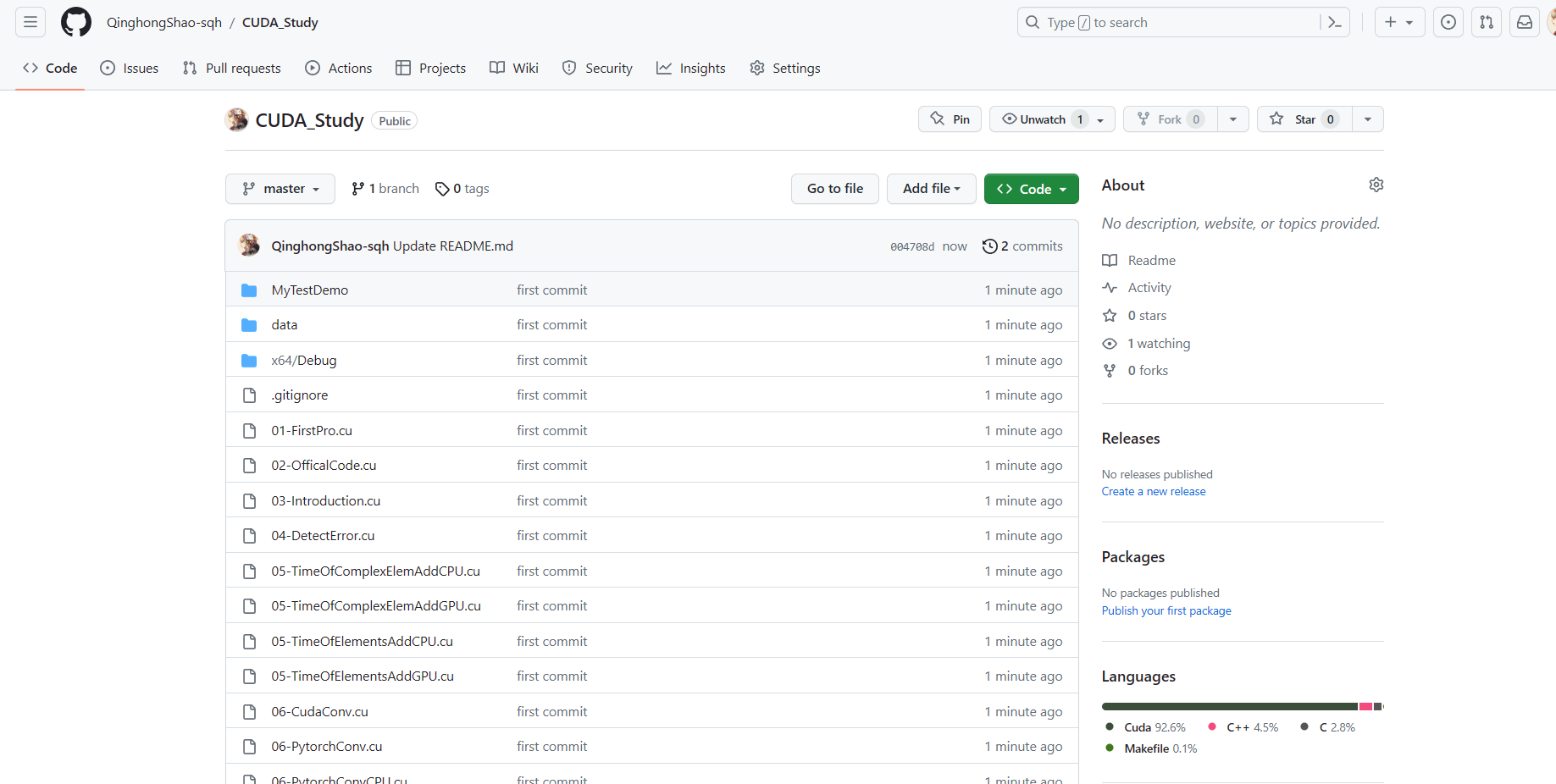
第15-16行:调用 cudaEventDestroy 函数销毁 start 和 stop 这两个CUDA事件2:测试add2cpu性能
100000000个元素相加,时间结果如下,在171ms上下
#include#include #include #include #include "cuda_runtime.h" #include "device_launch_parameters.h" #include #include #define CHECK(call) \ do \ { \ const cudaError_t error_code = call; \ if (error_code != cudaSuccess) \ { \ printf("CUDA Error:\n"); \ printf(" File: %s\n", __FILE__); \ printf(" Line: %d\n", __LINE__); \ printf(" Error code: %d\n", error_code); \ printf(" Error text: %s\n", \ cudaGetErrorString(error_code)); \ exit(1); \ } \ } while (0) #ifdef USE_DP typedef double real; const real EPSILON = 1.0e-15; #else typedef float real; const real EPSILON = 1.0e-6f; #endif const int NUM_REPEATS = 10; const real a = 1.23; const real b = 2.34; const real c = 3.57; void add(const real* x, const real* y, real* z, const int N); void check(const real* z, const int N); int main(void) { const int N = 100000000; const int M = sizeof(real) * N; real* x = (real*)malloc(M); real* y = (real*)malloc(M); real* z = (real*)malloc(M); for (int n = 0; n < N; ++n) { x[n] = a; y[n] = b; } float t_sum = 0; float t2_sum = 0; for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat) { cudaEvent_t start, stop; CHECK(cudaEventCreate(&start)); CHECK(cudaEventCreate(&stop)); CHECK(cudaEventRecord(start)); cudaEventQuery(start); add(x, y, z, N); CHECK(cudaEventRecord(stop)); CHECK(cudaEventSynchronize(stop)); float elapsed_time; CHECK(cudaEventElapsedTime(&elapsed_time, start, stop)); printf("Time = %g ms.\n", elapsed_time); if (repeat > 0) { t_sum += elapsed_time; t2_sum += elapsed_time * elapsed_time; } CHECK(cudaEventDestroy(start)); CHECK(cudaEventDestroy(stop)); } const float t_ave = t_sum / NUM_REPEATS; const float t_err = sqrt(t2_sum / NUM_REPEATS - t_ave * t_ave); printf("Time = %g +- %g ms.\n", t_ave, t_err); check(z, N); free(x); free(y); free(z); return 0; } void add(const real* x, const real* y, real* z, const int N) { for (int n = 0; n < N; ++n) { z[n] = x[n] + y[n]; } } void check(const real* z, const int N) { bool has_error = false; for (int n = 0; n < N; ++n) { if (fabs(z[n] - c) > EPSILON) { has_error = true; } } printf("%s\n", has_error ? "Has errors" : "No errors"); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
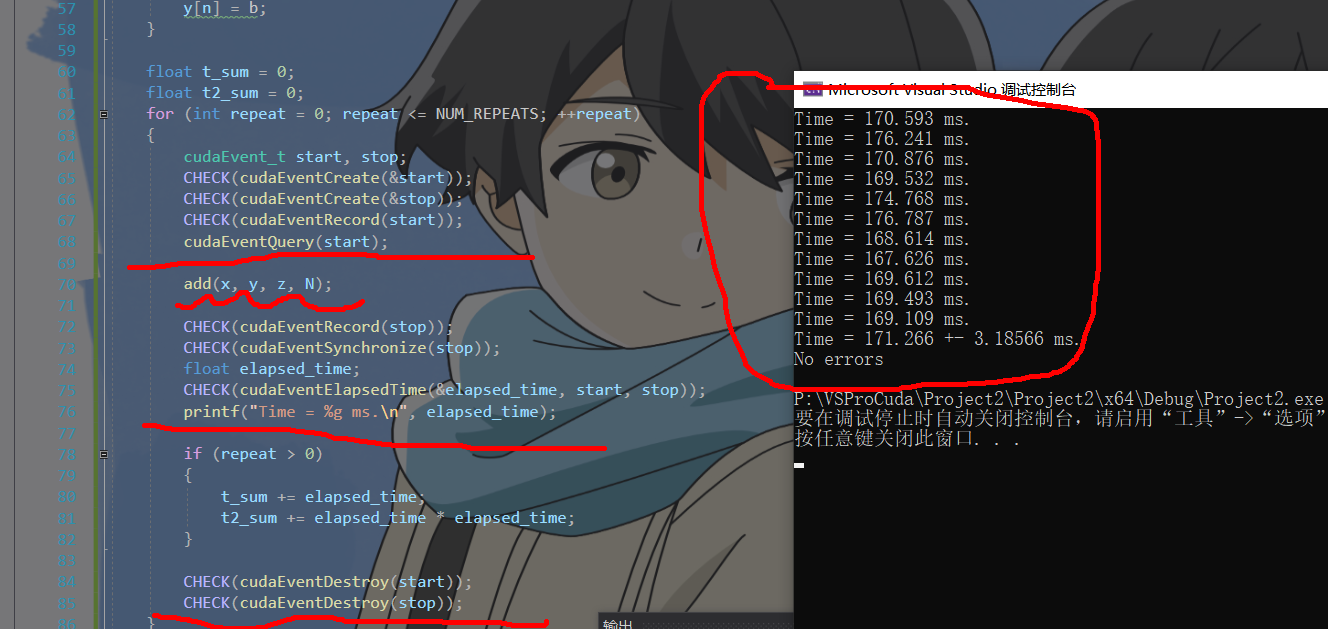
3:测试add2gpu性能
100000000个元素相加,时间结果如下,在7.94ms上下
其中我们还可以通过优化 grid_size,以及block_size的取值来进一步提速
add<<#include#include #include #include #include #include #include "cuda_runtime.h" #include "device_launch_parameters.h" #include #define CHECK(call) \ do \ { \ const cudaError_t error_code = call; \ if (error_code != cudaSuccess) \ { \ printf("CUDA Error:\n"); \ printf(" File: %s\n", __FILE__); \ printf(" Line: %d\n", __LINE__); \ printf(" Error code: %d\n", error_code); \ printf(" Error text: %s\n", \ cudaGetErrorString(error_code)); \ exit(1); \ } \ } while (0) #ifdef USE_DP typedef double real; const real EPSILON = 1.0e-15; #else typedef float real; const real EPSILON = 1.0e-6f; #endif const int NUM_REPEATS = 10; const real a = 1.23; const real b = 2.34; const real c = 3.57; void __global__ add(const real *x, const real *y, real *z, const int N); void check(const real *z, const int N); int main(void) { const int N = 100000000; const int M = sizeof(real) * N; real *h_x = (real*) malloc(M); real *h_y = (real*) malloc(M); real *h_z = (real*) malloc(M); for (int n = 0; n < N; ++n) { h_x[n] = a; h_y[n] = b; } real *d_x, *d_y, *d_z; CHECK(cudaMalloc((void **)&d_x, M)); CHECK(cudaMalloc((void **)&d_y, M)); CHECK(cudaMalloc((void **)&d_z, M)); CHECK(cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice)); CHECK(cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice)); const int block_size = 128; const int grid_size = (N + block_size - 1) / block_size; float t_sum = 0; float t2_sum = 0; for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat) { cudaEvent_t start, stop; CHECK(cudaEventCreate(&start)); CHECK(cudaEventCreate(&stop)); CHECK(cudaEventRecord(start)); cudaEventQuery(start); add<<<grid_size, block_size>>>(d_x, d_y, d_z, N); CHECK(cudaEventRecord(stop)); CHECK(cudaEventSynchronize(stop)); float elapsed_time; CHECK(cudaEventElapsedTime(&elapsed_time, start, stop)); printf("Time = %g ms.\n", elapsed_time); if (repeat > 0) { t_sum += elapsed_time; t2_sum += elapsed_time * elapsed_time; } CHECK(cudaEventDestroy(start)); CHECK(cudaEventDestroy(stop)); } const float t_ave = t_sum / NUM_REPEATS; const float t_err = sqrt(t2_sum / NUM_REPEATS - t_ave * t_ave); printf("Time = %g +- %g ms.\n", t_ave, t_err); CHECK(cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost)); check(h_z, N); free(h_x); free(h_y); free(h_z); CHECK(cudaFree(d_x)); CHECK(cudaFree(d_y)); CHECK(cudaFree(d_z)); return 0; } void __global__ add(const real *x, const real *y, real *z, const int N) { const int n = blockDim.x * blockIdx.x + threadIdx.x; if (n < N) { z[n] = x[n] + y[n]; } } void check(const real *z, const int N) { bool has_error = false; for (int n = 0; n < N; ++n) { if (fabs(z[n] - c) > EPSILON) { has_error = true; } } printf("%s\n", has_error ? "Has errors" : "No errors"); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
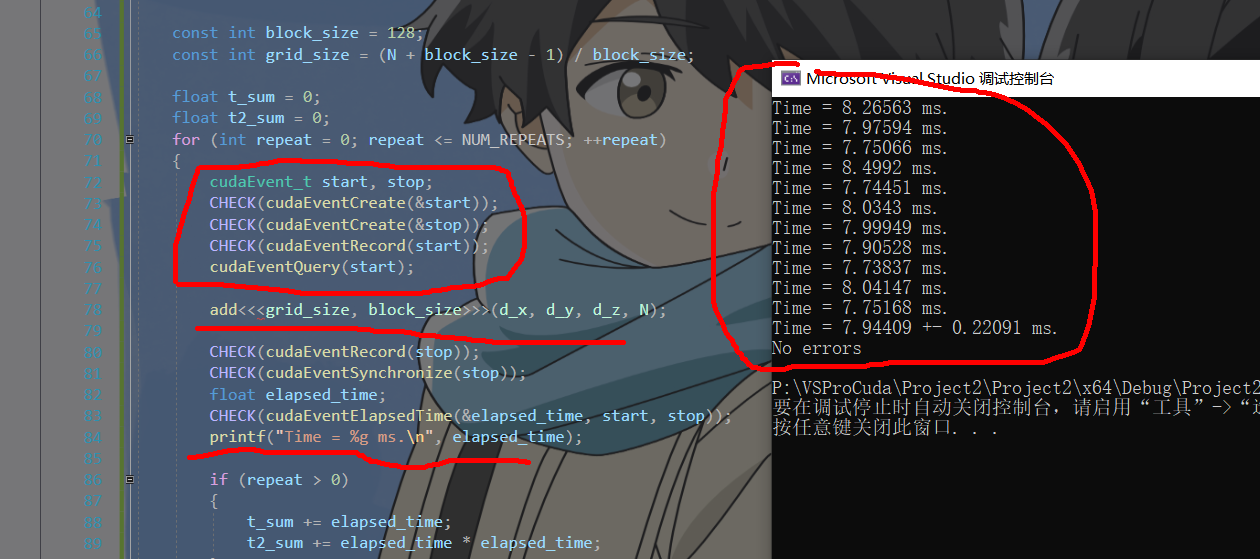
4: 提高算术复杂度 arithmetic2cpu
在计算过程使用了循环 、sqrt等方式,增加计算复杂性,设N为10000,
cpu运行时长从171ms增长到了370ms (虽然N减少了,但因为复杂度上去了,计算更加耗时)#include#include #include #include #include #include #include "cuda_runtime.h" #include "device_launch_parameters.h" #include #define CHECK(call) \ do \ { \ const cudaError_t error_code = call; \ if (error_code != cudaSuccess) \ { \ printf("CUDA Error:\n"); \ printf(" File: %s\n", __FILE__); \ printf(" Line: %d\n", __LINE__); \ printf(" Error code: %d\n", error_code); \ printf(" Error text: %s\n", \ cudaGetErrorString(error_code)); \ exit(1); \ } \ } while (0) #ifdef USE_DP typedef double real; #else typedef float real; #endif const int NUM_REPEATS = 10; const real x0 = 100.0; void arithmetic(real* x, const real x0, const int N); int main(void) { const int N = 10000; const int M = sizeof(real) * N; real* x = (real*)malloc(M); float t_sum = 0; float t2_sum = 0; for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat) { for (int n = 0; n < N; ++n) { x[n] = 0.0; } cudaEvent_t start, stop; CHECK(cudaEventCreate(&start)); CHECK(cudaEventCreate(&stop)); CHECK(cudaEventRecord(start)); cudaEventQuery(start); arithmetic(x, x0, N); CHECK(cudaEventRecord(stop)); CHECK(cudaEventSynchronize(stop)); float elapsed_time; CHECK(cudaEventElapsedTime(&elapsed_time, start, stop)); printf("Time = %g ms.\n", elapsed_time); if (repeat > 0) { t_sum += elapsed_time; t2_sum += elapsed_time * elapsed_time; } CHECK(cudaEventDestroy(start)); CHECK(cudaEventDestroy(stop)); } const float t_ave = t_sum / NUM_REPEATS; const float t_err = sqrt(t2_sum / NUM_REPEATS - t_ave * t_ave); printf("Time = %g +- %g ms.\n", t_ave, t_err); free(x); return 0; } void arithmetic(real* x, const real x0, const int N) { for (int n = 0; n < N; ++n) { real x_tmp = x[n]; while (sqrt(x_tmp) < x0) { ++x_tmp; } x[n] = x_tmp; } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
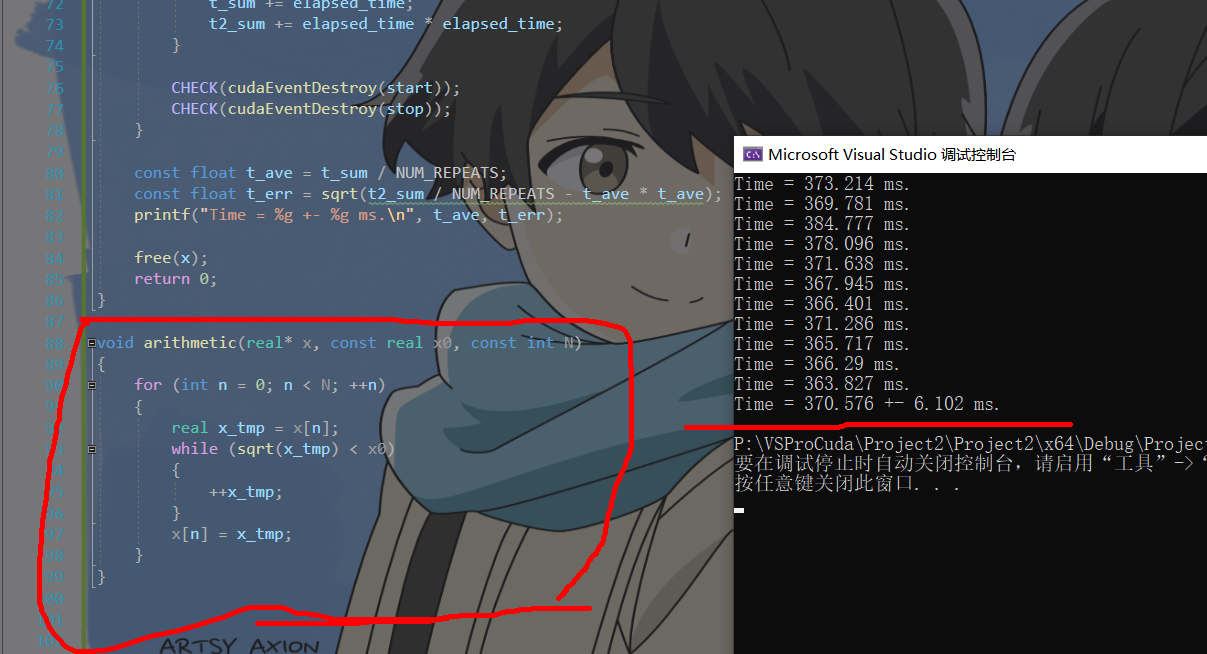
5: 提高算术复杂度 arithmetic2Gpu
在计算过程使用了循环 、sqrt等方式,增加计算复杂性,设N为10000,
gpu运行时长从7.94ms增长到了10.97ms(虽然N减少了,但因为复杂度上去了,计算更加耗时)#include#include #include #include #include #include #include "cuda_runtime.h" #include "device_launch_parameters.h" #include #define CHECK(call) \ do \ { \ const cudaError_t error_code = call; \ if (error_code != cudaSuccess) \ { \ printf("CUDA Error:\n"); \ printf(" File: %s\n", __FILE__); \ printf(" Line: %d\n", __LINE__); \ printf(" Error code: %d\n", error_code); \ printf(" Error text: %s\n", \ cudaGetErrorString(error_code)); \ exit(1); \ } \ } while (0) #ifdef USE_DP typedef double real; #else typedef float real; #endif const int NUM_REPEATS = 10; const real x0 = 100.0; void arithmetic(real* x, const real x0, const int N); int main(void) { const int N = 10000; const int M = sizeof(real) * N; real* x = (real*)malloc(M); float t_sum = 0; float t2_sum = 0; for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat) { for (int n = 0; n < N; ++n) { x[n] = 0.0; } cudaEvent_t start, stop; CHECK(cudaEventCreate(&start)); CHECK(cudaEventCreate(&stop)); CHECK(cudaEventRecord(start)); cudaEventQuery(start); arithmetic(x, x0, N); CHECK(cudaEventRecord(stop)); CHECK(cudaEventSynchronize(stop)); float elapsed_time; CHECK(cudaEventElapsedTime(&elapsed_time, start, stop)); printf("Time = %g ms.\n", elapsed_time); if (repeat > 0) { t_sum += elapsed_time; t2_sum += elapsed_time * elapsed_time; } CHECK(cudaEventDestroy(start)); CHECK(cudaEventDestroy(stop)); } const float t_ave = t_sum / NUM_REPEATS; const float t_err = sqrt(t2_sum / NUM_REPEATS - t_ave * t_ave); printf("Time = %g +- %g ms.\n", t_ave, t_err); free(x); return 0; } void arithmetic(real* x, const real x0, const int N) { for (int n = 0; n < N; ++n) { real x_tmp = x[n]; while (sqrt(x_tmp) < x0) { ++x_tmp; } x[n] = x_tmp; } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
6:实验结果:
运行设环,Nvidia11.6,显卡3050Ti
1w次循环复杂运算 1亿元素相加 CPU 370ms 171ms GPU 10.97ms 7.94ms- 1
- 2
- 3
- 4
- 5
7:总结(优化性能)
优化性能必要条件:
(1)数据传输比例较小。
(2) 核函数的算术强度较高。
(3)核函数中定义的线程数目较多。编程手段:
• 减少主机与设备之间的数据传输。
• 提高核函数的算术强度。
• 增大核函数的并行规模。8:拓展
(1)数据传输的比例
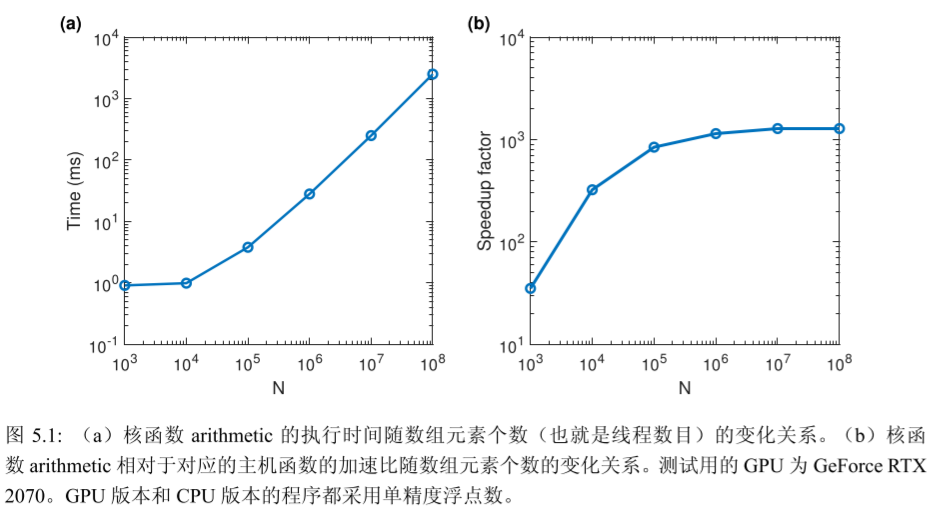
如果一个程序的目的仅仅是计算两个数组的和,那么 用GPU可能比用CPU还要慢。这是因为,花在数据传输(CPU与GPU之间)上的时间比计算(求和)本身还要多很多。GPU计算核心和设备内存之间数据传输的峰值理论带宽要 远高于 GPU 和 CPU 之间数据传输的带宽。
设计算任务不是做一次数组相加的计算,而是做10000次数组相加的计算,而且只需 要在程序的开始和结束部分进行数据传输,那么数据传输所占的比例将可以忽略不计。此时,整个 CUDA 程序的性能就大为提高。(2)算术强度
数组相加的问题之 所以很难得到更高的加速比,是因为该问题的算术强度(arithmetic intensity)不高。一个 计算问题的算术强度指的是其中算术操作的工作量与必要的内存操作的工作量之比。
例如, 在数组相加的问题中,在对每一对数据进行求和时需要先将一对数据从设备内存中取出来, 然后对它们实施求和计算,最后再将计算的结果存放到设备内存。这个问题的算术强度其 实是不高的,因为在取两次数据、存一次数据的情况下只做了一次求和计算。在CUDA中,设备内存的读、写都是代价高昂(比较耗时)的。(3)并行规模:
并行规模可用 GPU 中总的线程数目来衡量。
从硬件的角度来看,一个GPU由多个流多处理器(streaming multiprocessor,SM)构成,而每个SM中有若干CUDA核心。每个SM是相对独立的。从开普勒架构到伏特架 构,一个SM中最多能驻留(reside)的线程个数是 2048。对于图灵架构,该数目是 1024。 一块GPU中一般有几个到几十个SM(取决于具体的型号)。所以,一块GPU一共可以驻 留几万到几十万个线程。如果一个核函数中定义的线程数目远小于这个数的话,就很难得到很高的加速比。
-
相关阅读:
Python实现MYSQL蜜罐
隧道代理vs普通代理:哪种更适合您的爬虫应用?
Snort中pcre和正则表达式的使用
初识链表(7.25)
springboot+jsp商城会员积分管理系统
缓存中间件技术选型Memcached、MongoDB、Redis
MySql安全加固:无关或匿名帐号&是否更改root用户&避免空口令用户&是否加密数据库密码
Python学习3(函数、装饰器)
SQL Server 2017 各版本之间的差异
3.Tornado注意事项
- 原文地址:https://blog.csdn.net/qq_40514113/article/details/130902279
