-
深度学习-全卷积神经网络(FCN)
1. 简介
全卷积神经网络(Fully Convolutional Networks,FCN)是Jonathan Long等人于2015年在Fully Convolutional Networks for Semantic Segmentation一文中提出的用于图像语义分割的一种框架,是深度学习用于语义分割领域的开山之作。我们知道,对于一个各层参数结构都设计好的神经网络来说,输入的图片大小是要求固定的,比如AlexNet,VGGNet, GoogleNet等网络,都要求输入固定大小的图片才能正常工作。 而 F C N 的精髓就是让一个已经设计好的网络可以输入任意大小的图片 \color{blue}{而FCN的精髓就是让一个已经设计好的网络可以输入任意大小的图片} 而FCN的精髓就是让一个已经设计好的网络可以输入任意大小的图片。
2. FC网络结构
FCN网络结构主要分为两个部分:全卷积部分和反卷积部分。其中全卷积部分为一些经典的CNN网络(如VGG,ResNet等),用于提取特征;反卷积部分则是通过上采样得到原尺寸的语义分割图像。FCN的输入可以为任意尺寸的彩色图像,输出与输入尺寸相同,通道数为n(目标类别数)+1(背景)。
3. CNN和FCN网络结构对比
CNN网络
假如我们要设计一个用来区分猫,狗和背景的网络,CNN的网络的架构应该是如下图:
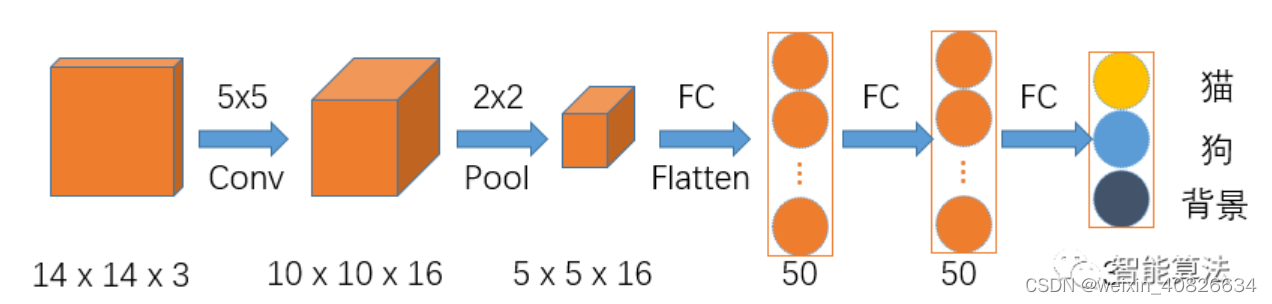
假如输入图片size为14x14x3的彩色图,如上图,首先经过一个5x5的卷积层,卷积层的输出通道数为16,得到一个10x10x16的一组特征图,然后经过2x2的池化层,得到5x5x16的特征图,接着Flatten后进入两个50个神经元的全连接层,最后输出分类结果。
其中 F l a t t e n 要求卷积输出的特征图的大小是固定的,因为它要把特征图的所有像素点连接起来,这就导致反推出卷积层的输入大小要求是固定的。 \color{blue}{其中Flatten要求卷积输出的特征图的大小是固定的,因为它要把特征图的所有像素点连接起来,这就导致反推出卷积层的输入大小要求是固定的。} 其中Flatten要求卷积输出的特征图的大小是固定的,因为它要把特征图的所有像素点连接起来,这就导致反推出卷积层的输入大小要求是固定的。
比如:在含有全连接层的神经网络中,假设输入的图像大小一样,那经过卷积得到特征的尺寸也都是相同的。如输入特征尺寸为 a × b,之后连接一个1 × c 的全连接层,那么卷积层的输出与全连接层间的权值矩阵大小为( a × b ) × c。但如果输入与原图像大小不同,得到新的卷积输出为 a ′ × b ′
。与之对应,卷积层的输出与全连接层间的权值矩阵大小应为 ( a ′ × b ′ ) × c 。很明显,权值矩阵大小发生了变化,故而也就无法使用和训练了。FCN网络
全卷积神经网络,顾名思义是该网络中全是卷积层链接,如下图:
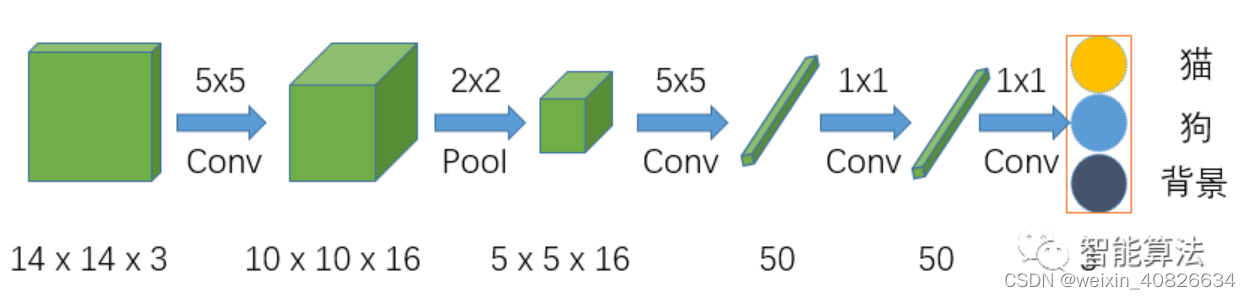
该网络在前面两步跟CNN的结构是一样的,但是在CNN网络Flatten的时候,FCN网络将之换成了一个卷积核size为5x5,输出通道为50的卷积层,之后的全连接层都换成了1x1的卷积层。1x1的卷积其实就相当于全连接操作。
从上两个图比较可知全卷积网络和CNN网络的 主要区别在于 F C N 将 C N N 中的全连接层换成了卷积操作。 \color{blue}{主要区别在于FCN将CNN中的全连接层换成了卷积操作。} 主要区别在于FCN将CNN中的全连接层换成了卷积操作。
换成全卷积操作后,由于没有了全连接层的输入层神经元个数的限制,所以卷积层的输入可以接受不同尺寸的图像,也就不用要求训练图像和测试图像size一致。
那么问题也来了,如果输入尺寸不一样,那么输出的尺寸也肯定是不同的,那么该如何去理解FCN的输出呢?
4. 理解FCN网络的输出
特征图尺寸变化
我们首先不考虑通道数,来看一下上面网络中的特征图尺寸的具体变化,如下图,图中绿色为卷积核,蓝色为特征图:
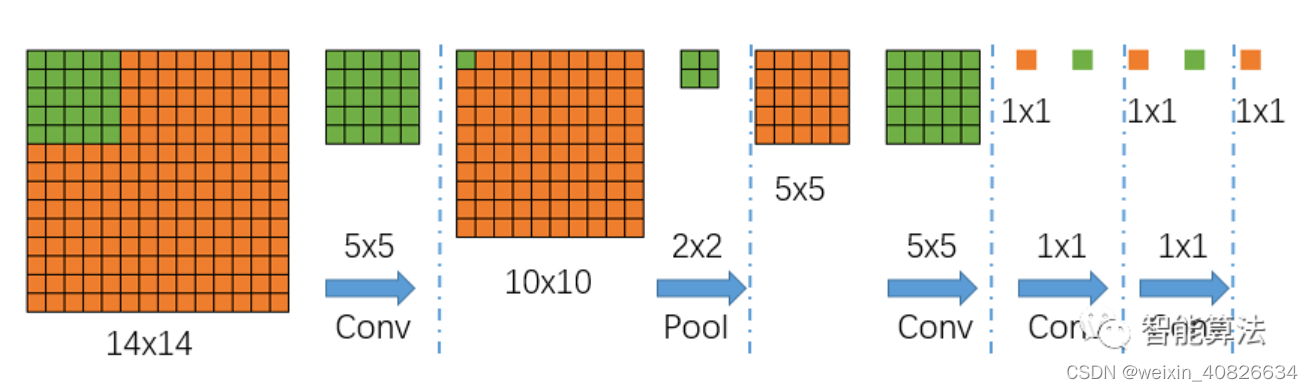
从上图中,我们可以看到,输入是一个14x14大小的图片,经过一个5x5的卷积(不填充)后,得到一个10x10的特征图,然后再经过一个2x2的池化后,尺寸缩小到一半变成5x5的特征图,再经过一个5x5的卷积后,特征图变为1x1,接着后面再进行两次1x1的卷积(类似全连接操作),最终得到一个1x1的输出结果,那么该1x1的输出结果,就代表最前面14x14图像区域的分类情况,如果对应到上面的猫狗和背景的分类任务,那么最后输出的结果应该是一个1x3的矩阵,其中每个值代表14x14的输入图片中对应类别的分类得分。
不同尺寸的输入图片
好了,不是说可以接收任意尺寸的输入吗?我们接下来看一个大一点的图片输入进来,会得到什么样的结果,如下图:
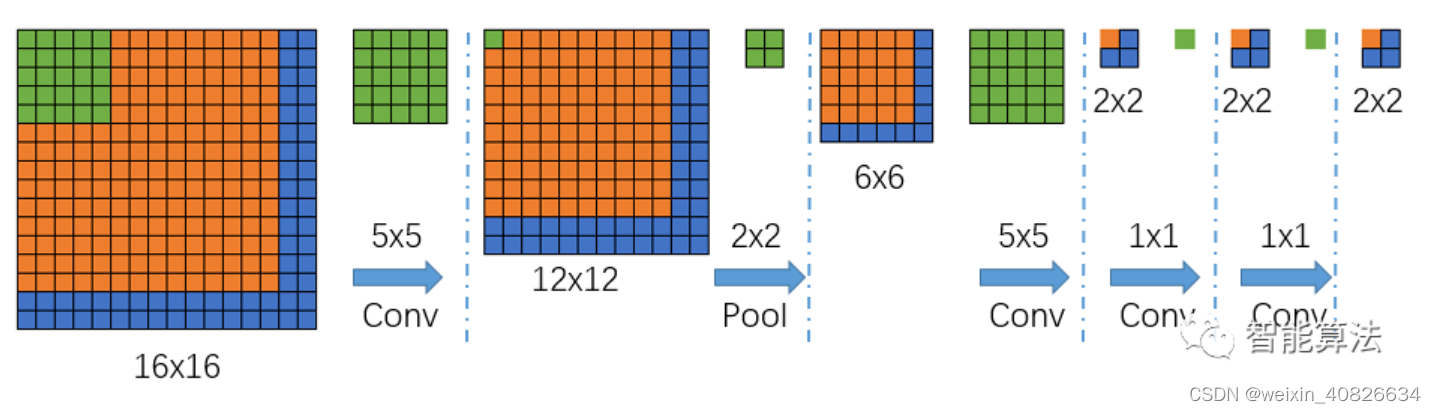
我们可以看到上面的图,输入尺寸由原来的14x14变成了16x16,那么经过一个5x5的卷积(不填充)后,得到一个12x12的特征图,然后再经过一个2x2的池化后,尺寸缩小到一半变成6x6的特征图,再经过一个5x5的卷积后,特征图变为2x2,接着后面再进行两次1x1的卷积(类似全连接操作),最终得到一个2x2的输出结果,那么该2x2的输出结果,就代表最前面16x16图像区域的分1类情况,然而,输出是2x2,怎么跟前面对应呢?
哪一个像素对应哪个区域呢?
我们看下图:
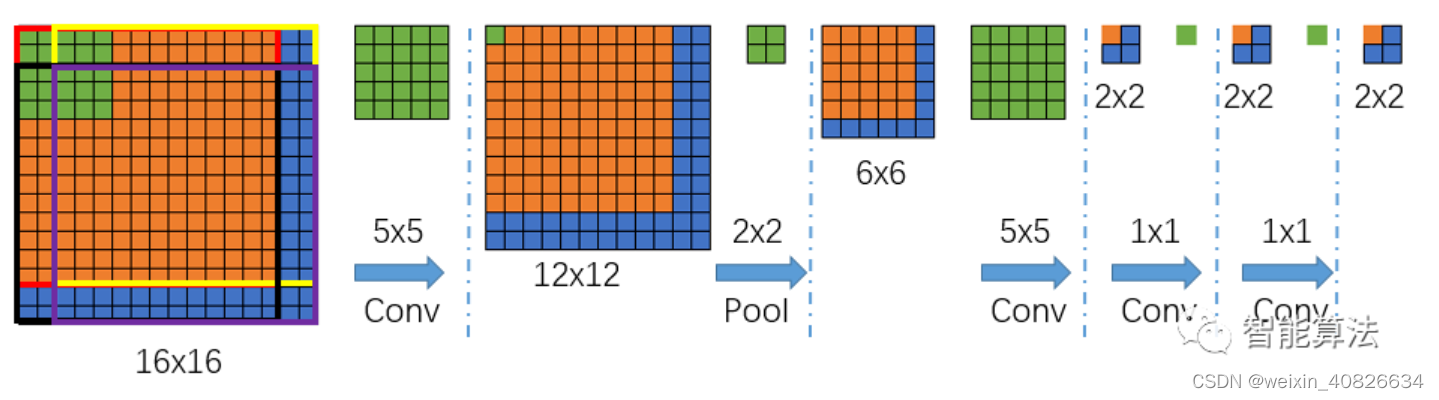
根据卷积池化反推,前面图3,我们知道,最后的输出1x1代表了前面14x14的输入的分类结果,那么我们根据卷积核的作用范围可以推出,上图中最后输出2x2中左上角的橙色输出就代表了16x16中的橙色区域(红色框),依次类推,输出2x2中右上角的蓝色输出就代表了16x16中的黄色框区域,输出2x2中左下角的蓝色输出就代表了16x16中的黑色框区域,输出2x2中右下角的蓝色输出就代表了16x16中的紫色框区域,其中每个框的大小都是14x14.也就是说输出的每个值代表了输入图像中的一个区域的分类情况。 -
相关阅读:
VSCode工具使用
vivo 自研Jenkins资源调度系统设计与实践
B站短视频如何去水印?一键解析下载B站视频!
Mysql计算一行最大最小值
使用VC++输出调频波
2023App测试必掌握的核心测试:UI、功能测试
邮件安全不容忽视,教你如何防止邮件泄密!
Apollo插件:个性化你的开发流程
聚观早报|苹果高管称ipad在走下坡路;罗永浩新公司完成融资
Java:如何提高自己的Java编程技能?
- 原文地址:https://blog.csdn.net/weixin_40826634/article/details/128197818