-
彻底搞懂MySql的B+Tree
1.什么是索引
官方定义:一种能为mysql提高查询效率的数据结构,索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构。好比如,一本书,你想找到自己想看的章节内容,直接查询目录就行。这里的目录就类似索引的意思。
1.1索引的工作原理

如上图中,如果现在有一条sql语句 select * from user where id = 40,如果没有索引的条件下,我们要找到这条记录,我们就需要在数据中进行全表扫描,匹配id = 40的数据。
如果有了索引,我们就可以通过索引进行快速查找,如上图中,可以先在索引中通过id = 40进行二分查找,再根据定位到的地址取出对应的行数据。
现在看来,索引是不是也不过如此。咋们接着往下看。
- 索引的优点:
- 1.大大加快数据的查询速度。
- 索引的缺点:
- 1.维护索引需要耗费数据库资源。
- 2.索引需要占用磁盘空间
- 3.当对表的数据增删改的时候,因为要维护索引,速度会受到影响。</pre>
那么有的同学可能会问,既然索引缺点这么多,那我为什么还要用索引啊?也就是提高了查询速度而已。
提高了查询速度呀,这个绝对是个大优势,在数据量庞大的情况下,我们通过命中索引,能大大的提高查询速度,增删改基本消耗忽略不计。摘抄阿里P3C开发规范。

2.索引的分类
- 1.主键索引
- 设定为主键后,数据库会自动为其创建主键索引,innodb为聚簇索引。
- 2.普通索引:用表中的普通列构建的索引,没有任何限制,用于加速查询。
- 3.组合索引:用多个列组合构建的索引,这多个列中的值不允许有空值。
- 4.全文索引(mysql5.7之前,由MyISAM提供):用大文本对象的列构建的索引,主要用来查找文件中的关键字。
3.B+Tree
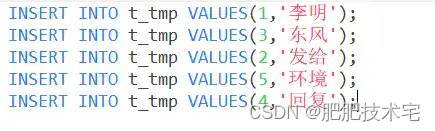
我们先来看一个sql
image
执行完后:

奇怪?为什么数据和我插入的顺序不一致呢,竟然给我自动排序好了!!!我们接着看
其实mysql每条数据的存储是这样子的(图自己画的,—_—,将就下)

- 每次插入数据的时候,mysql会给我们自己排序好,因为这样可以快速的查询数据。并且会通过P的指针链接到下一条数据。这里看起来是不是像某种数据结构?链表的数据结构,对了,就是这样。
- 疑问点???
- 我们都知道链表查询数据的时间复杂度为On,那么当数据量一多的话,我要查的id特别大呢,这和全表扫描有什么区别呢?接着往下看。
mysql给我们提供了页的概念,并且有页目录,页目录数据为叶族节点每页的第一条数据id,页目录和每页大小均默认为16KB,如下图:
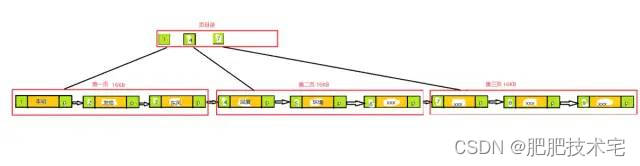
举个例子:
那么这个时候假如我想要查询id 为2的这条数据,在页目录中,2在1~4之间,直接去到第一页,查询第一页第一条数据为1,因为有指针P的存在,那么就可以顺着指针往下找即可。即找到了2。此时呢只进行了一次IO操作。现在想想看,是不是查询速度快很多。P指针的概念也很强大,是不是。那么有的小伙伴可能会问,你这样也存不了多少数据呀,那假如我数据量非常多呢,这颗数怎么存呢。
以上表而言,一个id占用8个字节(long类型),name 20个字节,p指针也要占用字节的(大概4~8个字节),我们以最大8来算,那么一条数据大概就是:8+20+8=36,36个字节,那么一页换算一下是 16x1024 = 16384 个字节,那么叶子节点一页可以存储数据量为:16384/36 = 455 条数据。那么页目录又存着id,一个id8个字节,能存储16x1024/8 =2048,2048x455 = 931,840 …粗略的算了下3层数,能存储数据量为1,908,408,320个 很多了,可能表的字段很多的话,存储数据量稍微少点,但是也很多了。3.对比B-Tree
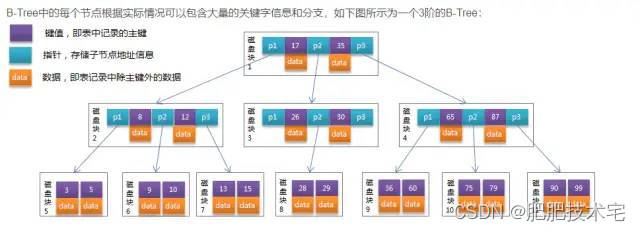
可以看到b-Tree上的每个节点都存储了数据,那么,我们刚刚说了,mysql一页的大小为16KB,那么这样的话,一页能存储的数据就很少了,因为数据要占用每页的字节呀。这样树的深度可能就深了。我们知道mysql每次读取数据时会进行一次IO操作,那么深度越深,IO的次数不是会越多。说白了优化优化,大多数都是在IO层做优化的。那么对比B+Tree,数据只存在叶子节点上,树的深度就不是那么深了(一般企业级不会超过3层深度)B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
我们来总结下B+Tree和B-Tree的区别
- 1.B+Tree非叶子结点只存储键值信息。
- 2.B+Tree所有叶子节点都有一个指针(上面说到了指针的用途)。
- 3.B+Tree数据都存储在叶子节点上,B-Tree节点上都存储数据。
- innoDB存储引擎页大小为16KB,一般主键类型为INT(占用4个字节)或BIGINT(占用8个字节)。
这个时候有个问题思考下?为什么mysql推荐ID自增呢?这个时候是不是心里有了答案呢?或许自己可以先想想再看。
- 在InnoDB的实践里面
- 其中一个建议是按主键的自增顺序插入记 录,就是为了避免Page Split问题。比如一个Page里依次装入了Key为(1,3,5,9)四条记录,并且假设这个Page满了。接下来如果插入一个 Key =4的记录,就不得不建一个新的Page,同时把(1,3,5,9)分成两半,前一半(1,3,4)还在旧的Page中,后一半(5,9)拷贝到新的Page 里,并且要调整Page前后的双向链表的指针关系,这显然会影响插入速 度。但如果插入的是Key = 10的记录,就不需要做Page Split,只需要建 一个新的Page,把Key = 10的记录放进去,然后让整个链表的最后一个 Page指向这个新的Page即可。
- 另外一个点,如果只是插入而不硬删除记录(只是软删除),也会 避免某个Page的记录数减少进而发生相邻的Page合并的问题。
3.聚簇索引和非聚簇索引
聚簇索引:将数据与索引放到了一块,索引的叶子节点保存了行数据。
非聚簇索引:将数据分开存储,索引结构的叶子节点指向了数据对应的位置。
总结:InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分;
我们日常工作中,根据实际情况自行添加的索引都是辅助索引,辅助索引就是一个为了需找主键索引的二级索引,现在找到主键索引再通过主键索引找数据;(这就是所谓的回表查询)
聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分,每张表只能拥有一个聚簇索引。
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。具体细节依赖于其实现方式。
聚簇索引的优缺点
优点:
1.数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
2.聚簇索引对于主键的排序查找和范围查找速度非常快 缺点:
1.插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键 2.更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。 3.二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
辅助索引(非聚簇索引)
在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找。辅助索引叶子节点存储的不再是行的物理位置,而是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据页,再通过数据页中的Page Directory找到数据行。
总之,其实说白了也就是,我们平常定义的索引就是辅助索引,平常通过普通索引查询数据时,先通过辅助索引查询到主键索引,再通过主键索引查询到具体的数据。 -
相关阅读:
【从零开始一步步学习VSOA开发】同步RPC客户端
Jetson系统烧录环境搭建
概率dp学习
零基础入门网络渗透到底要怎么学?_网络渗透技术自学
尼尔·唐纳德·沃尔什《与神对话》
【Java开发】 Spring 05 :Project Reactor 响应式流框架(以Reactive方式访问Redis为例)
基于leetcode的算法训练:Day2
(附源码)python《C语言程序设计》课程案例库研究 毕业设计 030946
计算机毕业设计ssm+vue基本微信小程序的拼车自助服务小程序
BigDecimal使用的时候需要注意什么?
- 原文地址:https://blog.csdn.net/m0_71777195/article/details/128199207