-
XXL-JOB核心源码解读及时间轮原理剖析
你好,今天我想和你分享一下XXL-JOB的核心实现。如果你是XXL-JOB的用户,那么你肯定思考过它的实现原理;如果你还未接触过这个产品,那么可以通过本文了解一下。
XXL-JOB的架构图(2.0版本)如下:

它是如何工作的呢?从使用方的角度来看,首先执行器要向服务端注册。那么这里你可能就有疑问了,执行器向服务端注册?怎么注册的?多久注册一次?采用什么通信协议?
注册完了之后,服务端才能知道有哪些执行器,并触发任务调度。那么服务端是如何记录每个任务的触发时机,并完成精准调度的呢?XXL-JOB采用的是Quartz调度框架,本文我打算用时间轮方案来替换。
最后,执行器接收到调度请求,是怎么执行任务的呢?
带着这些问题,我们开启XXL-JOB的探索之旅。我先来说说XXL-JOB项目模块,项目模块很简单,有2个:
-
xxl-job-core:这个模块是给执行器依赖的;
-
xxl-job-admin:对应架构图中的调度中心;
本文内容较干,请搭配源码食用。源码版本是:2.0.2
1、Job服务自动注册
第一个核心技术点,服务注册。
服务注册要从
xxl-job-core模块的XxlJobSpringExecutor类说起,这是一个 Spring 的 Bean,它是这么定义的:@Bean(initMethod = "start", destroyMethod = "destroy") public XxlJobSpringExecutor xxlJobExecutor() { XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor(); xxlJobSpringExecutor.setAdminAddresses(adminAddresses); // 其他的一些注册信息 return xxlJobSpringExecutor; }进行代码追踪,最终会是下面的调用链路:
xxl-job-core模块 spring bean: XxlJobSpringExecutor # start() -> XxlJobExecutor # start() -> initRpcProvider() xxl-rpc-core.jar -> XxlRpcProviderFactory # start() -> ServiceRegistry # start() -> ExecutorServiceRegistry # start() -> ExecutorRegistryThread # start()
ExecutorRegistryThread就是服务注册的核心实现了,start()方法核心代码如下:public void start(String appName, String address) { registryThread = new Thread(new Runnable() { @Override public void run() { // registry while (!toStop) { // do registry adminBiz.registry(registryParam); TimeUnit.SECONDS.sleep(JobConstants.HEARTBEAT_INTERVAL);// 30s } // registry remove adminBiz.registryRemove(registryParam); } }); registryThread.setDaemon(true); registryThread.start(); }可以看到执行器每 30s 执行注册一次,我们继续往下看。
2、自动注册通信技术实现
通过上面
ExecutorRegistryThread # start()方法核心代码,可以看到,注册是通过adminBiz.registry(registryParam)代码实现的,调用链路总结如下:xxl-job-core模块 AdminBiz # registry() -> AdminBizClient # registry() -> XxlJobRemotingUtil # postBody() -> POST api/registry (jdk HttpURLConnection)
最终还是通过 HTTP 协议的 POST 请求,注册数据格式如下:
{ "registryGroup": "EXECUTOR", "registryKey": "example-job-executor", "registryValue": "10.0.0.10:9999" }看到这里,我们回到文章开头问题部分。
执行器向服务端注册?怎么注册的?多久注册一次?采用什么通信协议?
答案已经很明显了。
3、任务调度实现
我们接着来看第二个核心技术点,任务调度。
XXL-JOB采用的是Quartz调度框架,这里我打算向你介绍一下时间轮的实现方案,核心源码如下:
@Component public class JobScheduleHandler { private Thread scheduler; private Thread ringConsumer; private final MapjobIds = ring.remove(nowSecond % 60); // 触发任务调度 } catch (Exception e) { log.error("ring consumer error", e); } sleep(1000 - System.currentTimeMillis() % 1000); } } } } 上述通过两个线程池来实现,
job-scheduler为预读线程,job-ring-handler为时间轮线程。那么时间轮是怎么实现任务的精准调度的呢?时间轮的实现原理
我们常见的时钟根据秒针转动的类型,可以分为嘀嗒式秒针和流动式秒针。

我以嘀嗒式秒针时钟为例,可以把时钟环看作一个数组,秒针 1~60 秒停留的位置作为数组下标,60s 为数组下标 0。假设现在有 3 个待执行的任务,分别如下:
jobid: 101 0秒时刻开始执行,2s/次 jobid: 102 0秒时刻开始执行,3s/次 jobid: 103 3秒时刻开始执行,4s/次
对应 0 秒时刻的数组模型如下图所示:

这里我把 0 时刻拆成了三个阶段,分别是:
-
执行前:读取该时刻有哪些任务待执行,拿到任务 id;
-
执行中:通过任务 id 查询任务的运行策略,执行任务;
-
执行后:更新任务的下次执行时间;
然后时间指针往前推动一个时刻,到了 1 秒时刻。此时刻时间轮中的任务并未发生变化。
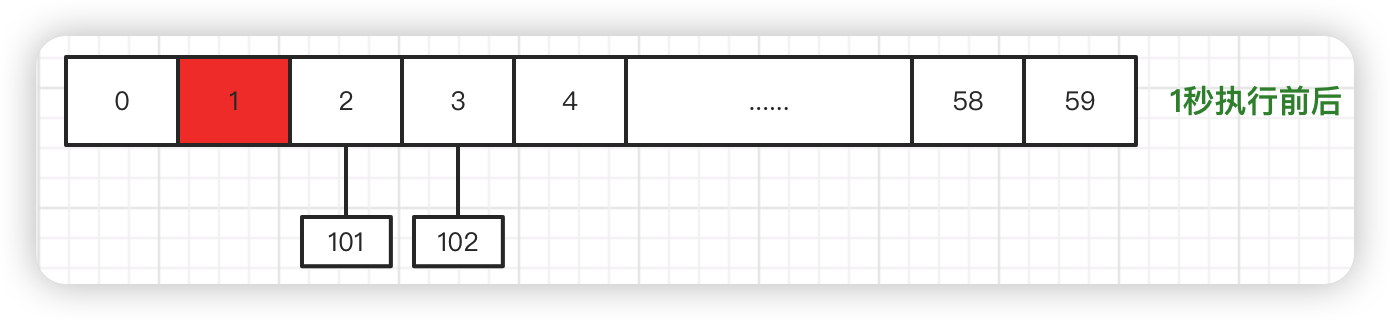
到了第 2 秒时刻,预读线程将 jobid 103 加入时间轮,并执行该数组下标下的任务:

这样到了第 3 秒时刻,任务的数组下标又会被更新。

那么这种以秒为刻度的时间轮有没有误差呢?
任务调度的精准度是取决于时间轮的刻度的。举个例子,我们把 0 秒时刻的这 1s 拆成 1000ms。

假设任务都是在第 500ms 完成该时刻秒内所有任务的调度的,501ms 有一个新的任务被预读线程加载进来了,那么轮到下次调度,就要等到第 1 秒时刻的第 500ms,误差相差了一个刻度即 1s。如果以 0.5 秒为一个刻度,那么误差就变小了,是 500ms。
所以说,刻度越小,误差越小。不过这也要根据业务的实际情况来决定,毕竟要想减少误差,就要耗费更多的 CPU 资源。
了解完任务调度的实现原理,那调度器与执行器间的服务通信是如何实现的呢?
4、任务调度通信技术实现
在
xxl-job-admin模块,梳理调用链路如下:xxl-job-admin模块 JobTriggerPoolHelper # trigger() -> ThreadPoolExecutor # execute() (分快慢线程池) -> XxlJobTrigger # trigger() -> processTrigger() -> runExecutor() -> XxlJobDynamicScheduler # getExecutorBiz() -> ExecutorBiz # run() (动态代理实现, 这里调用的 run 会作为参数) [1] -> XxlRpcReferenceBean. new InvocationHandler() # invoke() xxl-rpc-core.jar -> NettyHttpClient # asyncSend() (POST...请求参数 XxlRpcRequest 设置 methodName 为[1]处的调用方法即 "run")
最终是通过 HTTP 协议进行通信的,核心通信代码如下:
public void send(XxlRpcRequest xxlRpcRequest) throws Exception { byte[] requestBytes = serializer.serialize(xxlRpcRequest); DefaultFullHttpRequest request = new DefaultFullHttpRequest(HttpVersion.HTTP_1_1, HttpMethod.POST, new URI(address).getRawPath(), Unpooled.wrappedBuffer(requestBytes)); request.headers().set(HttpHeaderNames.HOST, host); request.headers().set(HttpHeaderNames.CONNECTION, HttpHeaderValues.KEEP_ALIVE); request.headers().set(HttpHeaderNames.CONTENT_LENGTH, request.content().readableBytes()); this.channel.writeAndFlush(request).sync(); }调度器将执行请求发送到执行器后,接着就是执行器的工作了。
5、执行器接收任务接口实现
执行器的工作,梳理调用链路如下:
xxl-job-core模块 spring bean: XxlJobSpringExecutor # start() -> XxlJobExecutor # start() -> initRpcProvider() xxl-rpc-core.jar -> XxlRpcProviderFactory # start() -> Server # start() -> NettyHttpServer # start() netty 接口实现 NettyHttpServerHandler # channelRead0() -> process() (线程池执行) -> XxlRpcProviderFactory # invokeService() (根据请求参数 XxlRpcRequest 里的 methodName 反射调用) -> ExecutorBizImpl # run()
我们也可以通过 HTTP 请求查看接口实现:
GET http://localhost:17711/services
结果如下:
- com.xxl.job.core.biz.ExecutorBiz: com.xxl.job.core.biz.impl.ExecutorBizImpl@d579177
执行器接收任务,总结来说用的是下面的接口:
POST http://localhost:17711
要注意的是,这里如果通过 Postman 来调用是调不通的,因为序列化方式和 HTTP 协议是不一样的。
接下来就是执行器接收到任务逻辑,代码链路如下:
xxl-job-core模块 spring bean: XxlJobSpringExecutor # start() -> XxlJobExecutor # start() -> initRpcProvider() -> new ExecutorBizImpl() -> JobThread # pushTriggerQueue() spring bean: XxlJobExecutor # registJobThread() 启动 jobThead -> JobThread # run()
到这里,我们就把核心流程梳理了一遍。
小结
通过上文的梳理,如果想要从 0 搭建一个分布式任务调度系统,想必你已胸有成竹了。本文所描述的时间轮方案,也是敝司基于XXL-JOB的重构方案,后来也应用在了消息中间件的延迟消息实现中。
欢迎交流,公众号【杨同学technotes】
-
-
相关阅读:
【LeetCode】回溯题解汇总
wpf devexpress实现输入验证使用验证规则
Nacos2.1.2源码修改支持高斯,postresql
如何在Linux服务器上安装Gerrit
<四>虚函数 静态绑定 动态绑定
HashMap原理
学习C语言的好处:
【数据结构基础_链表】Leetcode 707.设计链表(好题)
U-Net在2022年相关研究的论文推荐
Redis的使用--集群模式
- 原文地址:https://blog.csdn.net/yang237061644/article/details/128193922