-
文献阅读-VQAR-基于计算机视觉和自然语言处理的信息检索技术综述
VQAR: Review on Information Retrieval Techniques based on Computer Vision and Natural Language Processing
标题:VQAR-基于计算机视觉和自然语言处理的信息检索技术综述
Authors:Shivangi ModiDhatri Pandya
Journal:2019 3rd International Conference on Computing Methodologies and Communication (ICCMC) (2019)
Date:2019-3
DOI:10.1109/iccmc.2019.8819803

Abstract:最近,计算机视觉和自然语言处理范式在各自领域包含了巨大的研究进展。 尽管这两个领域都取得了进展,但对于机器来说,提取图像语义并将提取的信息与所需用户进行交流仍然是一项具有挑战性的任务。 这些问题将通过连接计算机视觉和自然语言处理范式的视觉问答(VQA)系统来解决。 在 VQA 中,系统会收到与该图像相关的图像和文本问题。 系统将通过处理图像和文本特征来生成答案。 VQA 生成的答案是一个单词、短语或句子。 各种数据集可用于训练和评估 VQA 系统,其中包含真实或抽象图像以及与图像中可用语义相关的问答对。 VQA 被用于许多领域,例如盲人和视障用户、机器人、艺术画廊和更多领域。 本文讨论了 VQA 技术、VQA 数据集,并强调了这些技术的参数评估以及 VQA 系统中的一般问题。
Keywords: 视觉问答、计算机视觉、自然语言处理、注意力模型、联合嵌入、组合模型、外部知识库机制。
1. INTRODUCTION
📌CV的重要性和应用
由于视觉是智能的核心组成部分,计算机视觉对于计算机自行接收和分析视觉数据,进而对图像和视频做出决策具有重要作用。 例如,人脸识别、物体检测等各种计算机视觉应用领域都得到了很好的解决。
计算机视觉应用已经无处不在,谷歌的新产品 Goggles 使用了目标检测的概念,Facebook 的面部识别任务也使用了人脸识别的概念 。
📌NLP领域的应用
同样,自然语言处理领域也因其广泛的应用而受到广泛关注,例如机器人技术、语言翻译、文本摘要等等。
尽管这两个领域都取得了进展,但机器从图像中提取语义信息并将提取的信息传达给人类仍然是一项具有挑战性的任务 。
由于此任务需要理解图像并将提取的语义信息作为人类自然语言形式与机器进行交流,因此需要视觉和语言知识来推断正确答案 。这个问题将通过视觉问答 (VQA) 解决 技术 。
**VQA 是一个系统,可以预测与图像相关的给定问题的答案 **。 该系统提供了对计算机视觉和自然语言处理领域两个重要信息源之间关系的见解。
在 VQA 中,系统将图像和文本问题作为输入,并生成文本答案作为输出 。
VQA 是一项具有挑战性的任务,因为系统需要处理图像和文本问题,然后系统才能给出答案。 VQA系统的示例如图1所示。

VQA 由于其在日常生活中的各种用途而引起了广泛的关注,例如盲人或视障用户、图像检索、机器人技术、美术馆和更多领域 。例如,盲人用户捕获图像并使用 VQA 系统获取有关视觉信息的知识。
视觉问答中有两种不同类型的评估格式 。
- 开放式评价格式
在开放式中,VQA 系统提供输入图像和文本问题。系统会通过处理图像和文本问题来生成答案。输入图像是自然场景图像或卡通场景图像 。
在开放式视觉问答中,问题主要分为十二个不同的类别,例如对象存在、从属对象识别、计数、颜色属性、其他属性、活动识别、运动识别、位置推理、场景分类、对象实用程序、情感理解 和荒谬的。
- 选择题式评价格式
在选择题型格式中,系统提供输入图像、文本问答选项。 这些选项将是正确的、似是而非的、流行的或随机的。
VQA 方法分为基于联合嵌入、注意、组合和外部知识的模型,用于实现 VQA 系统。
本文旨在对 VQA 模型和技术进行综述。 本文组织如下:在第 2 节中,讨论了 VQA 系统框架、VQA 模型及其不同的 VQA 技术。 第 3 节讨论 VQA 技术的参数评估。 现有 VQA 技术的主要问题在第 4 节中介绍。
2.RELATED WORK
本节详细介绍各种视觉问答模型; 他们的技术和各种 VQA 技术的参数评估。
2.1 VQA系统框架
VQA系统的总体框架如图2所示。VQA框架包括系统输入、计算机视觉任务、自然语言处理任务和答案生成模块。
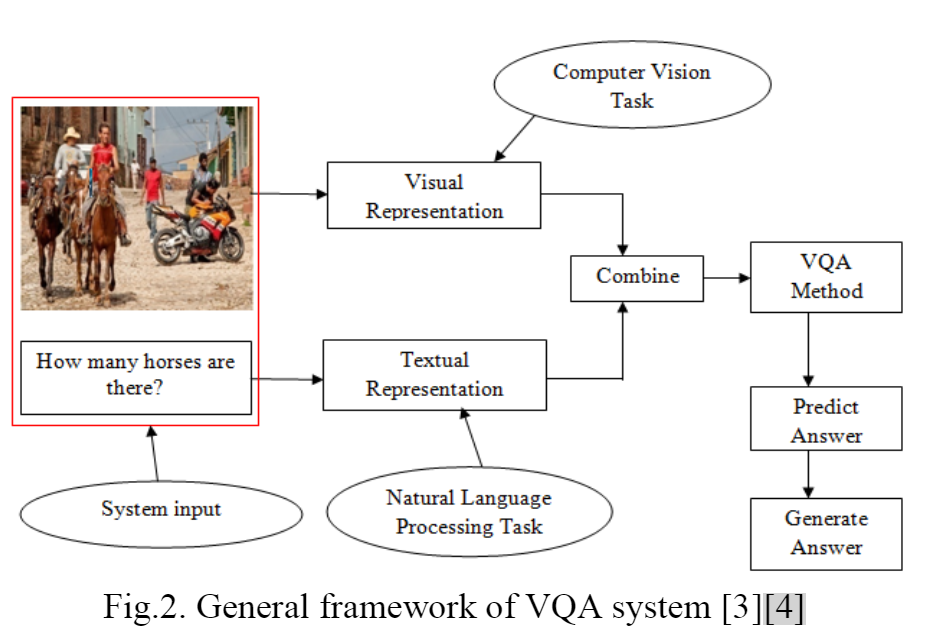
最初,VQA 系统以图像和文本问题作为输入。
然后通过计算机视觉和自然语言处理任务系统对输入图像和文本问题进行处理并生成视觉和文本表示。
在生成图像特征和问题编码向量系统后,将两个输出向量组合在一起。
生成的输出向量将进入适当的 VQA 模型,VQA 模型根据输入图像中存在的语义预测并生成给定问题的答案。
- CV Task
为了生成输入图像的视觉表示,不同的 VQA 技术使用不同的 CNN(卷积神经网络),如 AlexNet 、VggNet 、GoogleNet 、ResNet 等。
- NLP Task
CNN 将图像作为输入并提取图像的语义特征 。 CNN 的初始层提取图像的较低级别特征,如边缘、线条、角、亮度等,然后 CNN 层提取整个对象。
为了生成输入问题的文本表示,不同的 VQA 技术使用 RNN(递归神经网络或 LSTM(长短期记忆))。为了对输入问题的特征进行编码,VQA 系统需要多项自然语言处理任务,例如标记化、词嵌入等。对输入的文本问题执行标记化操作并生成标记。然后将这些标记传递到词嵌入技术中。 词嵌入将标记或单词或文本转换为数字形式。
有多种词嵌入技术,例如 CBOW(Continuous bag of Word)、Skip-gram 模型 、GloVe 等。 然后在每个实数值向量被传递到 LSTM 网络并生成问题编码向量之后。生成的图像特征矩阵和问题编码向量通过连接、乘法、加法等不同操作之一相互组合。
2.2 VQA模型
视觉问答能够通过不同的 VQA 方法回答自由形式的开放式问题。 VQA 方法分为四种模型,如图 3 所示。
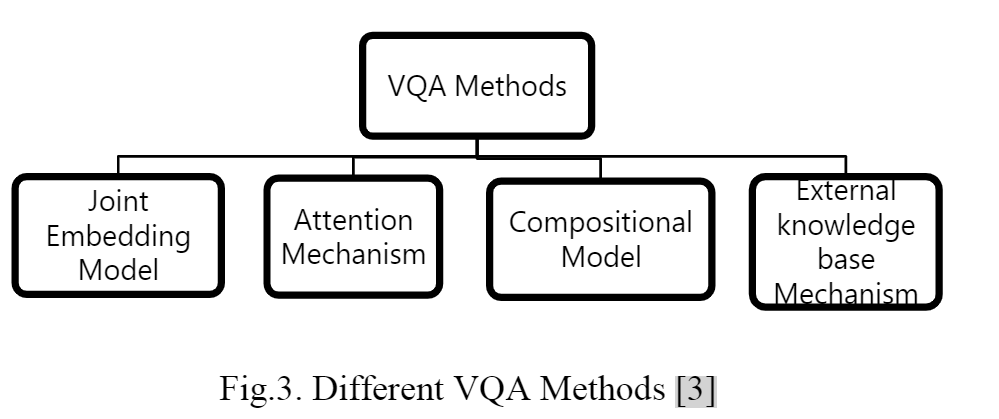
2.2.1 Joint Embedding Model
H. 高等人 提出了用于实现 VQA 的联合嵌入模型。 在这个模型中,图像和文本问题作为输入。
然后通过不同的深度学习和NLP技术提取残像和文本问题特征。 在获得这两个特征之后,这两个特征向量被联合嵌入到公共特征空间中。
然后将这个组合的特征向量输入分类器。 最后分类器预测给定问题的答案。
该模型的主要部分是它关注图像的全局特征。
该模型的示例如图 4 所示。 与图像相关的问题如“背景是什么?” 图 4 图像包含两个人的所有全局特征,山、棍子、滑板和所有其他小功能。 为了嵌入图像和文本问题,现在使用基于深度神经网络的机制。

2.2.2 Attention Mechanism
Z. 杨等提出了一种注意力机制,它是联合嵌入模型的扩展。 在联合嵌入模型中,VQA 系统关注图像的所有全局特征,而不是仅关注图像的问题特定特征。
单独提取全局特征可能难以理解图像的问题特定语义信息。因此,联合嵌入模型的这种局限性正在通过注意力机制来解决。 注意力模型将关注图像的特定区域而不是图像的所有全局特征。
图 5 是 VQA 系统回答“雨伞的颜色是什么?”的模型示例 然后系统将关注图像的问题特定伞状区域而不是其他图像区域。

有很多不同的方法来应用注意力。 将注意力应用于这种表示的一种方法是通过抑制或改进各个空间区域的特征。
利用具有这些局部图像特征的问题特征,例如仅伞状区域,可以计算出每个格子区域的权重因子,该权重因子决定空间区域对问题的重要性,然后可以将其用于处理注意力加权图像特征。
2.2.3 Compositional Model
R.胡等提出了组合模型。 当问题需要多步推理才能正确回答时,此模型很有用。
该模型的视觉问题是“狗的左边是什么?” 然后这个模型首先找到狗,然后识别出狗剩下的物体。
已经为 VQA 提出了两个组合系统,它们试图在一系列子步骤中处理解决 VQA。 第一个框架是神经模块网络(NMN),第二个结构是循环应答单元(RAU)。
NMN 结构利用外部问题解析器来查找问题中的子任务,而 RAU 是端到端准备的,子任务可以隐式学习。
2.2.4 External Knowledge base Mechanism
Q.吴等提出外部知识库模式。 当一些常识或附加背景知识类型的问题需要一些外部知识来源才能正确回答时,此模型很有用。
例如,像“这张图片中哪种交通方式比出租车便宜?”这样的问题可能需要一些外部知识来源来回答。

外部知识来源的一种方式是支持事实。 支持事实就像“公共汽车比出租车便宜”。 由于这些额外的知识来源,现在系统能够正确回答问题。 有很多其他方法可以为系统提供外部知识源。
2.3 VQA技术
视觉问答中有许多不同的技术可用。 这些所有技术都是基于 VQA 四种方法。 在本节中,我们将讨论所有四种方法联合嵌入、基于注意力、组合、基于外部知识和基于混合模型的技术。
2.3.1 mQA Model based Technique
H.gao 等人。 [8] 论文提出了基于 mQA 模型的技术,该技术基于联合嵌入方法来回答与图像相关的问题。 在这种技术中,答案将是单个单词、短语或句子。
该技术包含四个主要组成部分。
-
第一个组成部分是问题表示。为此,他们使用 LSTM 来提取问题的特征。
-
第二个组成部分是视觉表示。 为此,他们使用 CNN 来提取视觉特征。该组件在 ImageNet 分类任务上进行了预训练。
-
最重要的是第三个组件,它是另一个 LSTM 组件。 该组件的主要目的是生成句子形式的答案。这个 LSTM 组件将答案的当前词和之前的词编码为密集表示。
-
第四个组件是融合组件。 该组件融合了前三个组件的信息来预测答案中的下一个单词。
mQA 模型在 Freestyle Multilingual ImageQuestion Answering (FM-IQA) 数据集上训练和评估。 该数据集包含中文问答对及其英文翻译。该数据集具有动作、对象识别、对象之间的位置和交互、基于常识的识别和视觉内容类型的问题。
2.3.2 询问你的神经元技术
M. Malinowski 等人论文提出了基于联合嵌入的方法来实现视觉问答。 他们评估了他们在** DAQUAR 和 VQA 数据集上的方法。 他们使用深度学习方法CNN 对图像信息进行编码 **。编码后的图像信息和问题一起输入 LSTM 网络。 CNN 与 LSTM 的组合可以预测多个单词或单个单词的答案。
2.3.3 Stacked Attention Network (SAN) Technique堆叠注意力网络技术
Z. 杨等论文提出了基于注意力机制的 SAN 技术。 该技术通过多个注意力层执行多步推理以实现视觉问答。
SAN 技术由三个主要部分组成。 在所有三个组件中:
-
第一个组件是通过 VGGNet CNN 提取图像特征。
-
第二个组件是使用 CNN 或 LSTM 模型提取问题特征的问题模型。
-
第三个组成部分是堆叠注意力模型。该模型通过多个注意力层定位与问题相关的图像区域以进行答案预测。
最后结合最后一个注意力层和最后一个查询向量的图像特征来预测答案。 该技术将预测单个单词的答案。
2.3.4 ABC-CNN Technique
K.陈等人论文提出了一种基于注意力的可配置卷积神经网络技术。该技术侧重于基于问题引导注意力的图像信息区域。
该技术包含四个主要组成部分。
-
第一个组成部分是图像特征提取部分。 该组件使用 VGG-19 deepCNN 提取图像特征。
-
第二个组成部分是问题理解部分。该组件使用 LSTM 模型对问题特征进行编码。
-
第三部分是注意力提取部分。 该组件设置了将问题特征与图像特征进行映射并生成问题引导注意力图的卷积核。
-
第四部分是答案生成部分。 该组件使用基于问题引导注意力图的分类器并生成答案。 答案将以单个单词生成。
2.3.5 Graph based Technique基于图形的技术
W. 布朗等人 论文提出了一种基于图形的方法来实现视觉问答。 该技术使用图学习器模块来制作与问题相关的输入图像的图。由于创建了问题特定图,现在系统能够回答高级推理类型的问题,例如语义和空间表示类型的问题。
该技术包含四个主要组成部分。
-
第一个组件是问题编码器,它通过词嵌入和递归神经网络嵌入问题。
-
第二个组件是对象检测器。该对象检测器对图像执行并获取图像的边界框坐标和特征向量。
-
第三个组成部分是图学习器模块,它结合了图像和问题特征向量,并生成图像对象和给定问题的邻接矩阵。
-
第四个组成部分是空间图卷积,它关注与问题相关的对象、对象关系。
最后执行最大池和元素乘积操作以获得与输入图像相关的输入问题的最终答案。
2.3.6 Ask Me Anything (AMA) Technique问我任何事 (AMA) 技术
吴等论文提出了 AMA 模型,该模型处理来自外部来源的基于一般知识的问题。 他们将自动生成的图像描述与外部知识库相结合,以提供一般问题答案对的答案。
该模型包含两个主要组成部分。
-
第一个组件是提取、编码和合并。 该组件的首要任务是通过 CNN 预测图像的属性集。基于属性的图像字幕模型生成一系列字幕。该组件的第二个任务是根据图像中检测到的前 5 个属性从 DBpedia 知识库中提取相关信息。然后通过 Doc2Vec 将该信息编码为固定长度的特征表示。
-
第二个组件是具有多个输入的 VQA 模型。 在此组件中,编码属性、标题和 KB 信息被作为单一输入并输入 LSTM 以解释问题并生成答案。
2.3.7 FVQA: Fact based Technique基于事实的技术
P.王等人论文提出了基于事实的视觉问答任务。 这种技术是处理常识和基本事实知识类型的推理问题。
在本文中,通过支持事实提供了明确的推理。 为了添加带有问答对的支持事实,他们引入了名为 FVQA 数据集的新数据集。
支持事实与视觉概念相关联。 视觉概念分为三类:物体、场景和动作。
每个视觉概念的知识都是从 DBpedia、ConceptNet 和 WebChild 等知识库中提取的。
在构建知识库后,他们通过 RNN 或 LSTM 执行问题查询映射。
为了检索正确的支持事实,他们使用查询; 这是在整个知识库上执行的。 ** LSTM 或 SVM 分类器**用于在查询返回的成对列表中选择最相关的支持事实。
2.3.8 End-to-End Module Network Technique端到端模块组网技术
R.胡等。 [12] 论文提出了一个没有解析器帮助的端到端模块网络。
该模型用于处理组合推理类型的视觉问答。 为了解决组合推理问题,他们将问题分解为一组神经模块。
然后在使用** RNN 实施布局策略后预测每个问题的布局表达式 **。 该表达式被传递给网络构建器,以动态预测问题的实例特定神经网络,并将其应用于输入图像以获得答案。
2.3.9 R-VQA Technique
P. Lu 等人论文提出了一种用于视觉问答的新型语义注意模型框架。框架对于学习视觉关系事实作为图像中的语义知识很有用。
他们构建了基于大规模视觉基因组数据集的 Relational-VQA (R-VQA) 数据集。 R-VQA 数据集中的每个数据实例由图像、问题、关系事实和答案组成。
该技术由三个主要部分组成。
-
第一个组件是上下文感知视觉注意模块。该组件用于提取图像特征表示。
-
第二个组件是事实感知语义注意模块。在这个模块中,第一个组件的输出被馈送到第二个组件以选择相关的关系事实。 这些关系事实是由关系检测器根据图像和问题生成的。
-
第三个组成部分是联合知识嵌入学习。 该组件同时合并最终的视觉和语义注意表示以学习视觉和语义知识。
3.VQA 技术的参数评估
本节显示了先前讨论的 VQA 技术的比较。表 1 显示了基于参数的 VQA 技术比较,如下所示。
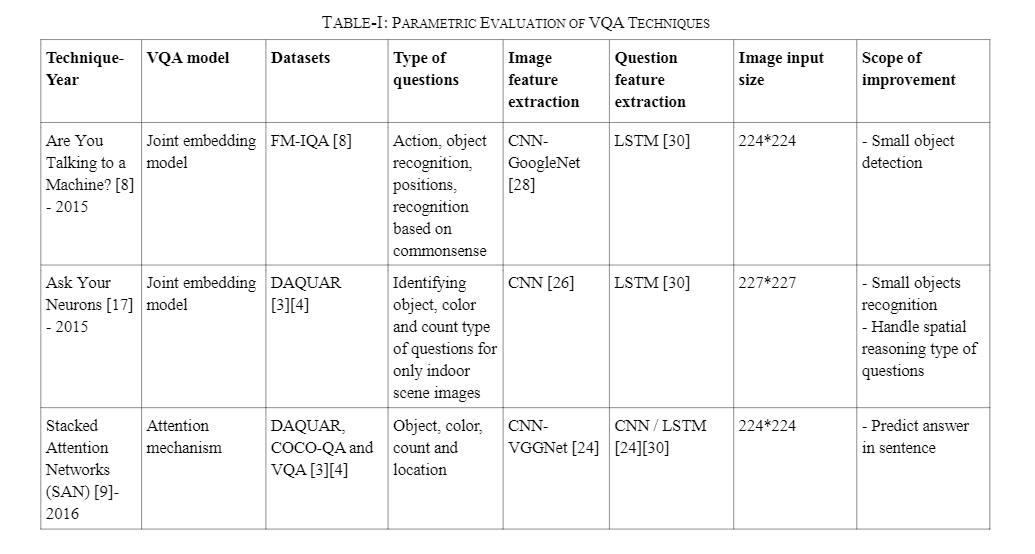
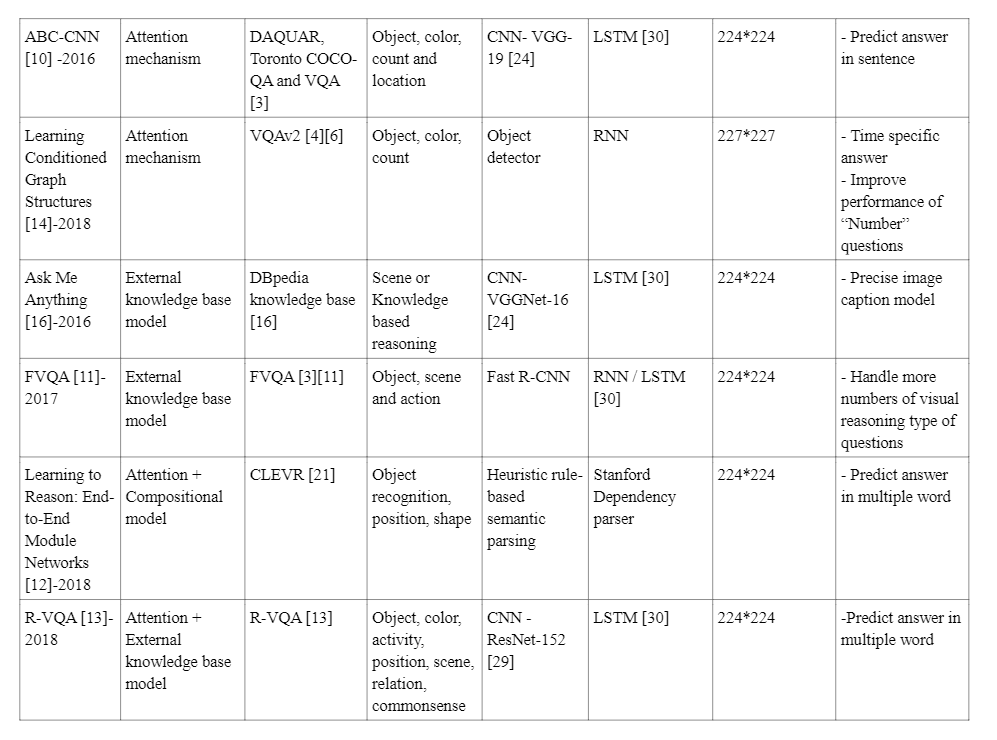
VQA 模型参数指示该技术使用哪个模型来预测与图像相关的给定问题的答案。
Datasets 参数用于确定不同的 VQA 技术使用哪个数据集进行训练和评估。
问题类型参数表示该特定技术处理的问题类型。
关键特征参数表示技术的主要特征,
改进范围参数表示技术的改进或未来工作。
4.主要问题
视觉问答系统由于其广泛的应用范围和更广泛的研究领域,包含许多开放的研究问题。 在研究了所有视觉问答方法和技术之后,我们已经确定了视觉问答中的某些问题。
A. 单词答案:最近的视觉问答系统以单词生成答案。 很少有 VQA 技术会生成多个单词的答案。 然而,这几种技术并没有以句子形式或人类可理解的适当形式生成答案。 下面显示了属于此问题的一些示例。
在下面的第一个例子中,一些奶牛是黑色的,一些奶牛是棕色的。 然而,当前的 VQA 系统只生成“棕色”答案。 正确的人类可以理解的答案就像“有些奶牛是棕色的,有些奶牛是黑色的”。

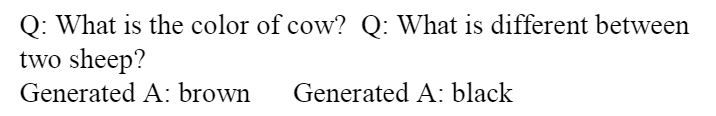
B. 时间特定的答案 :最近的视觉问答技术能够回答图像特定的问题,如“现在几点了?”、“时钟显示几点?”以及更多时间特定的问题。 下图显示了属于本期的一些示例。

**C. 数字特定视觉问题答案 **:最近的视觉问答技术能够回答图像特定的问题,比如“桌子的号码是多少?”、“公交车号码是多少?”以及更多数字特定的视觉问题 . 下面显示了属于本期的一些示例。

D.常识推理 :现有的 VQA 系统无法处理所有类型的常识推理类型的问题,例如“这个孩子是男孩还是女孩?”,“男人的年龄是多少?
E. 处理有限数量的知识库推理类型问题:现有的 VQA 系统是在以外部资源或支持事实的形式提供给系统的附加和背景知识的帮助下处理知识库推理类型的问题。 因此,他们只处理那些已提供背景信息的问题。
F. 不处理太小的物体检测和识别:现有的 VQA 系统能够回答物体检测并识别那些物体。 然而当时的物体太小,现有系统无法检测和识别这些物体。
5.结论和未来的工作
在本文中,我们研究了视觉问答 (VQA) 方法及其用于实现 VQA 的不同技术。
VQA 中主要有四种方法可用。这四种方法是联合嵌入、基于注意力、组合和基于外部知识的方法。
我们详细研究了这四种方法及其技术。 在研究这些所有技术时,我们发现了现有视觉问答系统中的几个问题。 这些所有技术都基于计算机视觉和自然语言处理领域。 这些所有技术都用于预测与图像相关的给定问题的答案。 VQA 技术在许多应用中都很有用,例如盲人或视障用户、与机器人交互、为美术馆的观众提供信息等等。
视觉问答系统的主要挑战是开发一种更有效的技术,该技术将以主观形式预测答案并处理时间特定的问题答案对。
-
相关阅读:
聚鑫数藏平台——引领数字资产管理新风向
nvm的使用 nodejs版本管理,解决用户名是汉字的问题
基于EasyExcel实现的分页数据下载封装
Redis数据结构之quicklist
vue3(vite+typeScript+pina)使用记录
Magisk隐藏外挂解决方案
6.0、C语言——递归函数
深度系统(Deepin)开机无法登录,提示等待一千五百分钟
Spring web MVC(入门)
CRF+BiLSTM代码分步骤解读
- 原文地址:https://blog.csdn.net/weixin_55500281/article/details/128178863