-
AlphaFold2源码解析(6)--模型之特征表征
AlphaFold2源码解析(6)–模型之特征表征
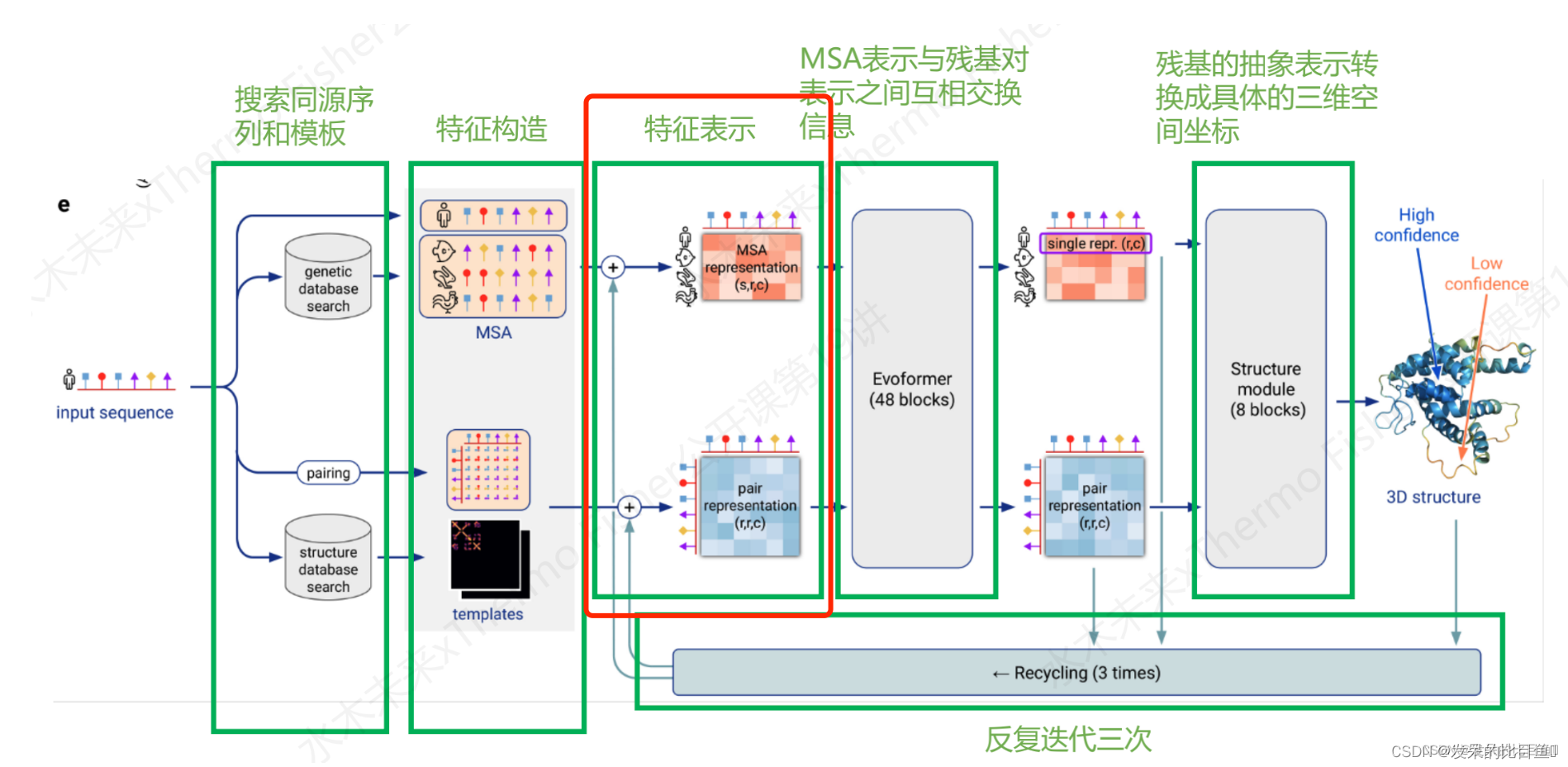 整体推理说明:
整体推理说明:

Embedding只是在推理使用,影响非常小(sup-Inference篇章)

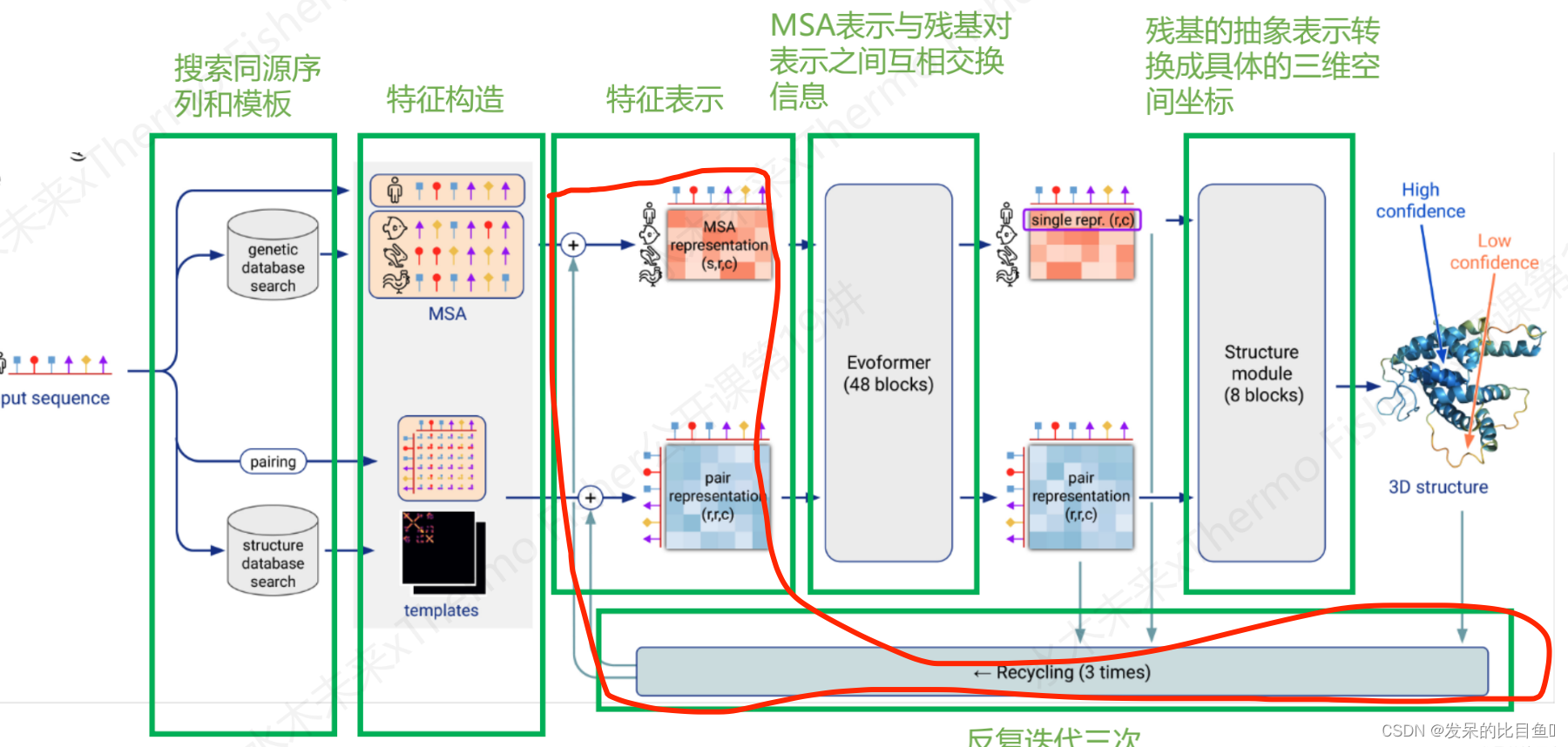
特征表征表示的入口模型如下:
evoformer_module = EmbeddingsAndEvoformer(self.config.embeddings_and_evoformer, self.global_config)
其中:embeddings_and_evoformer是模型的配置参数
self.config.embeddings_and_evoformer.keys() ['evoformer', 'evoformer_num_block', 'extra_msa_channel', 'extra_msa_stack_num_block', 'max_relative_feature', 'msa_channel', 'pair_channel', 'prev_pos', 'recycle_features', 'recycle_pos', 'seq_channel', 'template']- 1
- 2
global_config全局配置参数
self.global_config.keys() ['deterministic', 'multimer_mode', 'subbatch_size', 'use_remat', 'zero_init']- 1
- 2
整体Embedding流程
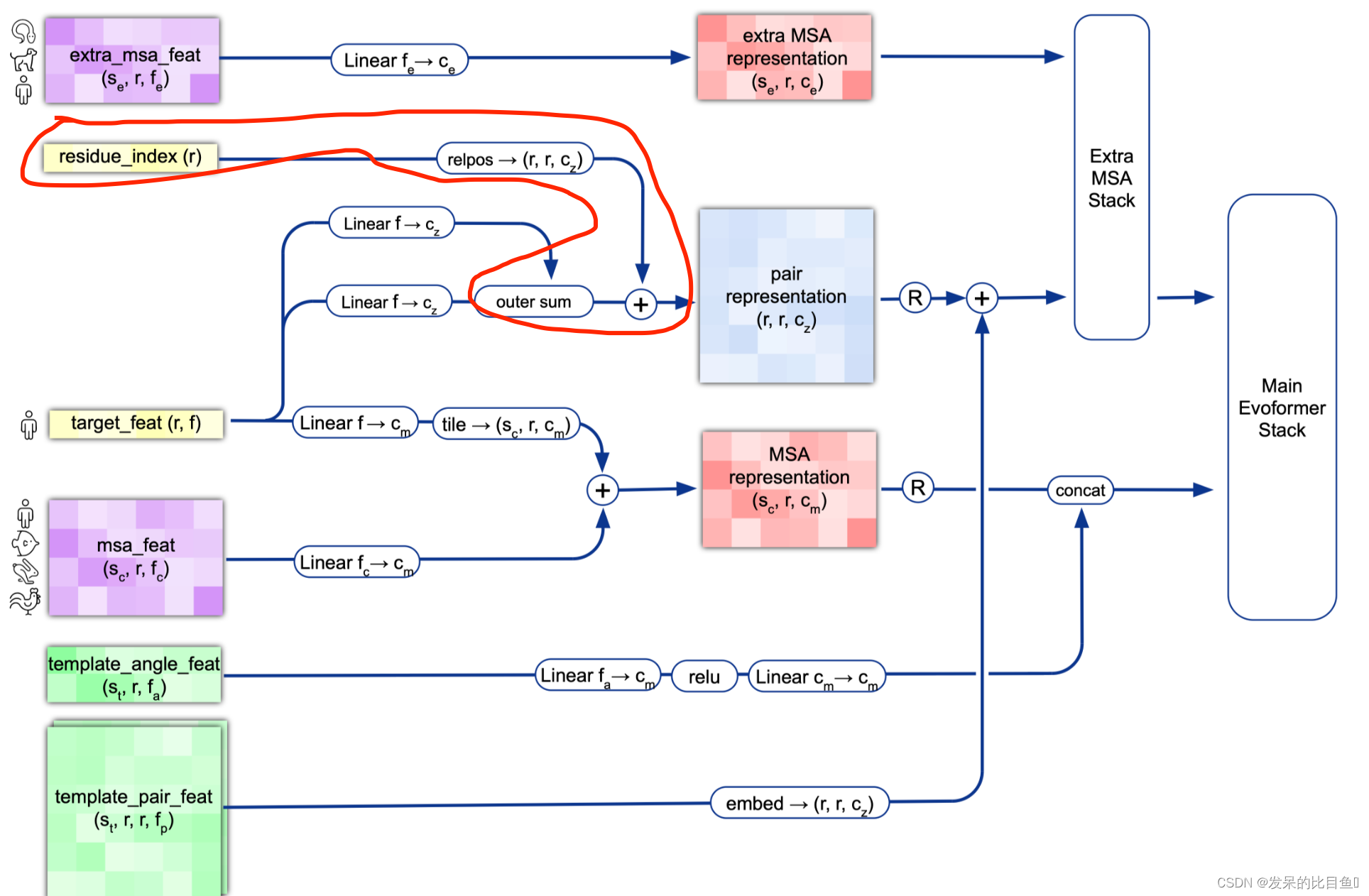
target_feat: shape(N_res, 21) 一个由aatype特征组成residue_index: shape(N_res), 由residue_index特征组成。msa_feat:shape(N_clust, N_res, 49)的特征,由cluster_msa、cluster_has_deletion、cluster_deletion_value、cluster_deletion_mean、cluster_profile拼接而成。extra_msa_feat: shape(N_extra_seq, N_res, 25)的特征,由extra_msa、extra_msa_has_deletion、extra_msa_deletion_value连接而成。与上面的msa_feat一起,还从这个特征中抽取N_cycle×N_ensemble随机样本template_pair_feat: shape(N_templ, N_res, N_res, 88), 由template_distogram和template_unit_vector组成,template_aatype特征是通过平铺和堆叠包含的(这在两个残基方向上完成了两次)。还包括掩码特征template_pseudo_beta_mask和template_backbone_frame_mask,其中特征f_ij=mas_ki·mas_kj。template_angle_feat: shape(N_templ, N_res, 51)特征,由template_aatype,template_torsion_angles,template_alt_torsion_angles, 和template_torsion_mask组成。
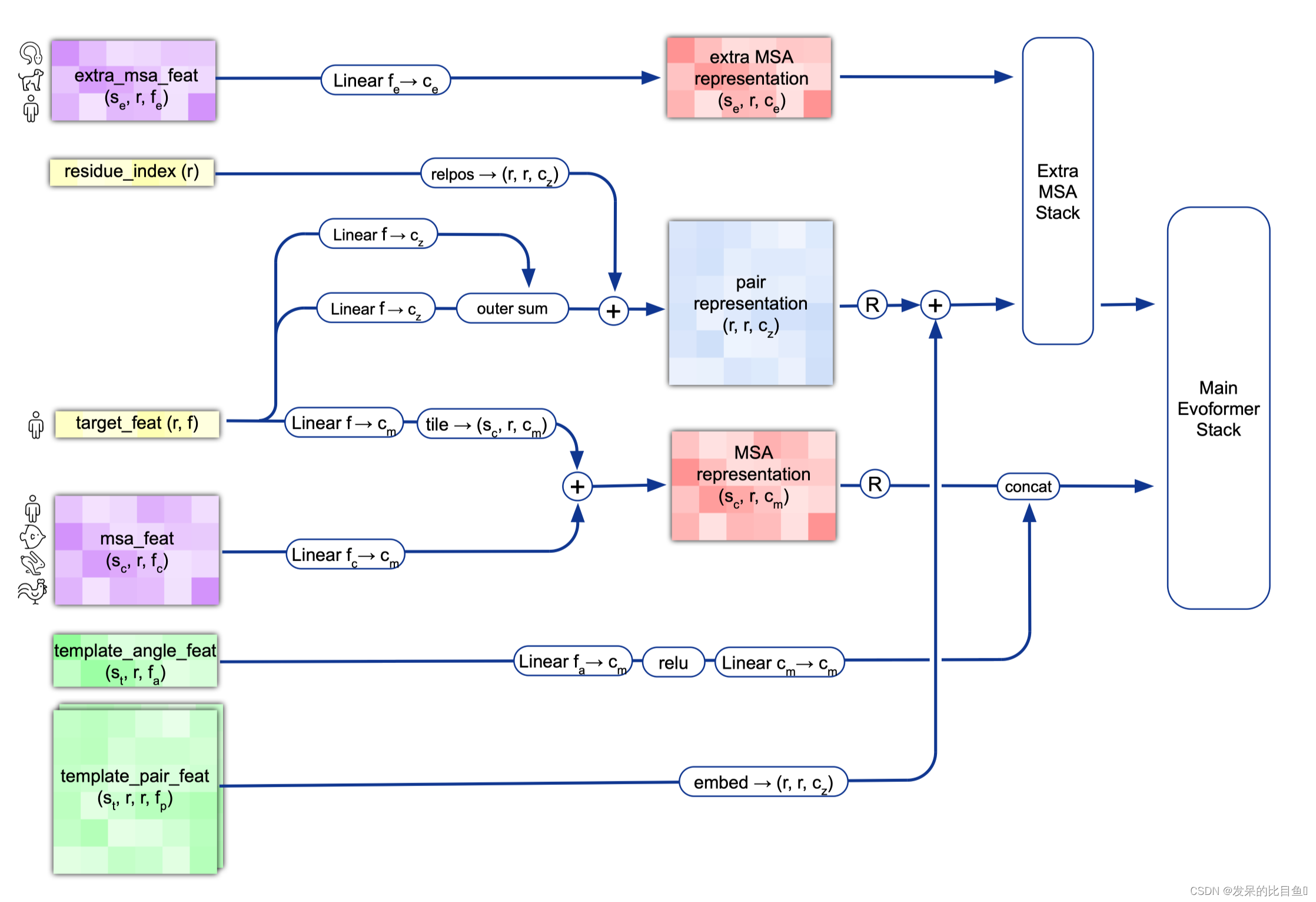

内容翻译如下:
MSA Embedding:
网络的第一部分首先从嵌入一个来自MSA的新示例开始,以创建MSA_{m_si}表示和pair_{z_ij}表示的初始版本。MSA表示的第一行和完整的对表示由来自前一个迭代的回收输出更新,对于第一个迭代,回收输出初始化为零。
Template Embedding和Pair Embedding:
接下来的步骤将集成来自模板的信息。template_angle_feat通过浅层MLP嵌入并连接到MSA表示。template_pair_feat由一个浅注意网络嵌入,并添加到pair表示中。嵌入过程的最后一步通过浅Evoformer-like网络处理额外的MSA特征,该网络针对大量序列进行了优化,以更新pair表示。

代码细节
MSA Representation
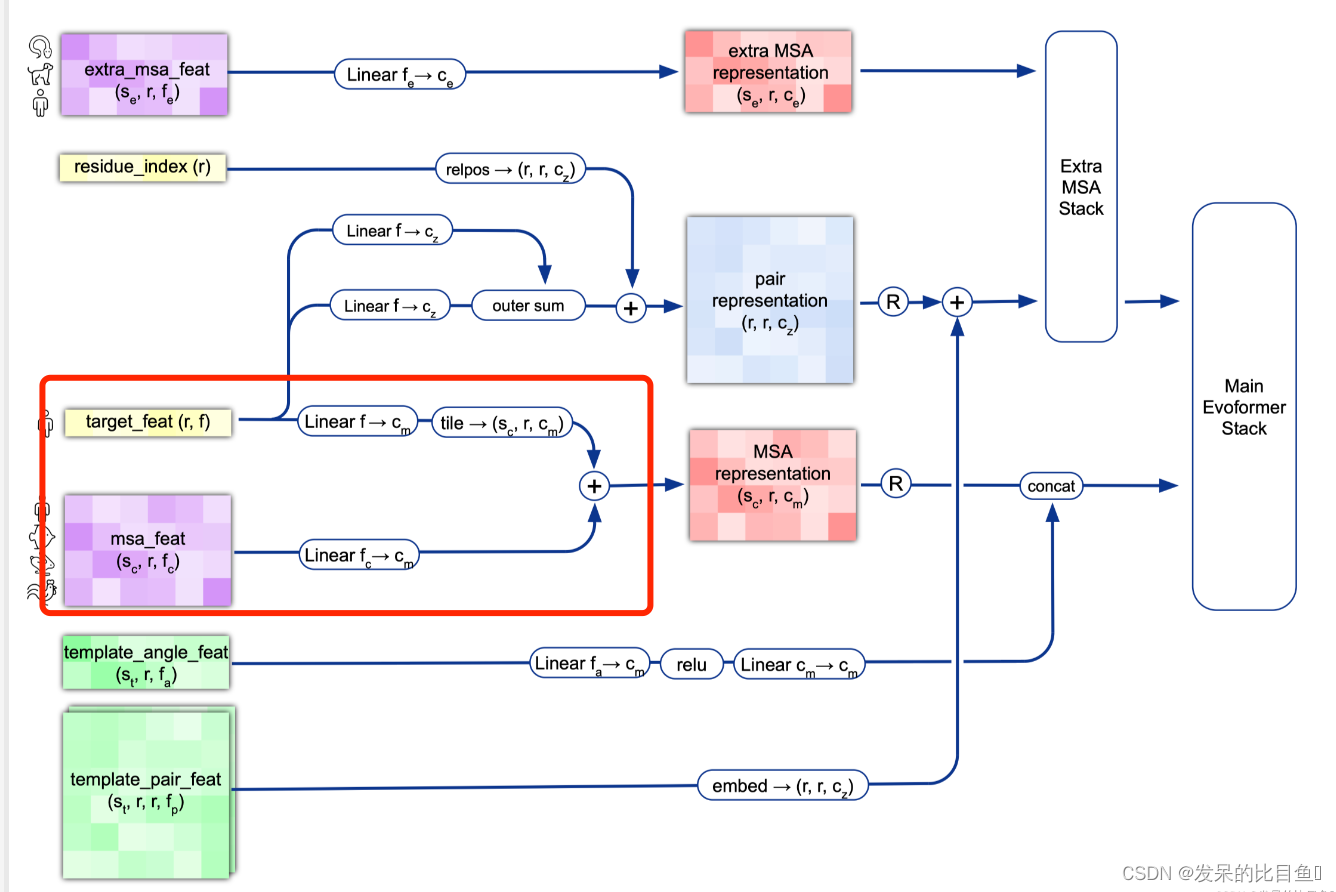

preprocess_1d = common_modules.Linear( # 初始化线性层 # c.msa_channel 256 c.msa_channel, name='preprocess_1d')(batch['target_feat']) #(84, 22) --> (84, 256) preprocess_msa = common_modules.Linear(c.msa_channel, name='preprocess_msa')( batch['msa_feat']) # (508, 84, 49) --> (508, 84, 256) msa_activations = jnp.expand_dims(preprocess_1d, axis=0) + preprocess_msa- 1
- 2
- 3
- 4
Pair Representation
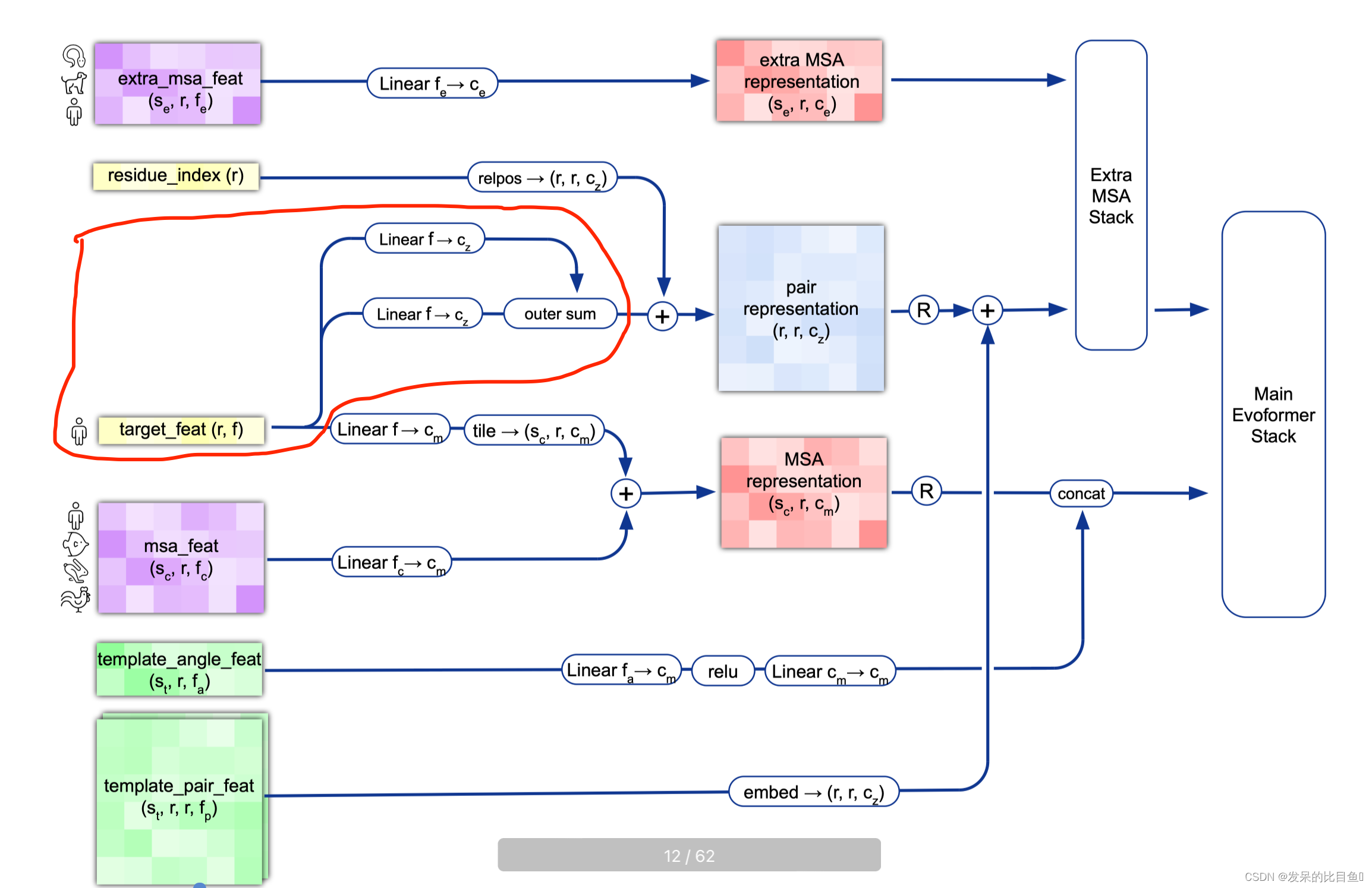
left_single = common_modules.Linear( c.pair_channel, name='left_single')( batch['target_feat']) #(84, 22) --> (84, 128) right_single = common_modules.Linear( c.pair_channel, name='right_single')( batch['target_feat']) #(84, 22) --> (84, 128) pair_activations = left_single[:, None] + right_single[None] # [84, 1, 128] + [1, 84, 128] --> [84, 84, 128] mask_2d = batch['seq_mask'][:, None] * batch['seq_mask'][None, :]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注入以前的输出进行回收

## 位置信息 if c.recycle_pos: prev_pseudo_beta = pseudo_beta_fn(batch['aatype'], batch['prev_pos'], None) # (84, 3) dgram = dgram_from_positions(prev_pseudo_beta, **self.config.prev_pos) pair_activations += common_modules.Linear(c.pair_channel, name='prev_pos_linear')(dgram) # 特征信息 if c.recycle_features: prev_msa_first_row = hk.LayerNorm(axis=[-1], create_scale=True, create_offset=True, name='prev_msa_first_row_norm')( batch['prev_msa_first_row']) # (84, 256) --> (84, 256) 取第一行MSA msa_activations = msa_activations.at[0].add(prev_msa_first_row) # 第一行的加到msa_activations第一行 ## Pair 信息 pair_activations += hk.LayerNorm( axis=[-1], create_scale=True, create_offset=True, name='prev_pair_norm')(batch['prev_pair']) ## (84, 84, 128) --> (84, 84, 128) ....... def pseudo_beta_fn(aatype, all_atom_positions, all_atom_masks): """Create pseudo beta features. 创建伪测试功能""" # (84, 37, 3) --> atom 空间位置信息 is_gly = jnp.equal(aatype, residue_constants.restype_order['G']) # 是否是gly氨基酸 ca_idx = residue_constants.atom_order['CA'] # C_α 索引 1 cb_idx = residue_constants.atom_order['CB'] # C_β 索引 3 pseudo_beta = jnp.where( # is_gly 1 选择 ca_idx 否则 选择 cb_idx --> (84, 3) jnp.tile(is_gly[..., None], [1] * len(is_gly.shape) + [3]), # 将函数沿着X或者Y轴扩大n倍,jnp.tile((84,1), [1,3]) -> (84, 3) all_atom_positions[..., ca_idx, :], all_atom_positions[..., cb_idx, :]) # all_atom_positions[..., cb_idx, :]--> (3,) if all_atom_masks is not None: pseudo_beta_mask = jnp.where( is_gly, all_atom_masks[..., ca_idx], all_atom_masks[..., cb_idx]) pseudo_beta_mask = pseudo_beta_mask.astype(jnp.float32) return pseudo_beta, pseudo_beta_mask else: return pseudo_beta def dgram_from_positions(positions, num_bins, min_bin, max_bin): """Compute distogram from amino acid positions. 根据氨基酸位置计算距离图 positions: [N_res, 3] Position coordinates. 位置:[N_res,3]位置坐标。 num_bins: The number of bins in the distogram. num_bins:分布图中的箱数。 min_bin: The left edge of the first bin. min_bin:第一个bin的左边缘。 max_bin: The left edge of the final bin. The final bin catches max_bin:最终bin的左边缘。最后一个bin将捕获大于“max_bin”的 """ def squared_difference(x, y): return jnp.square(x - y) lower_breaks = jnp.linspace(min_bin, max_bin, num_bins) lower_breaks = jnp.square(lower_breaks) # 下限(15) upper_breaks = jnp.concatenate([lower_breaks[1:], jnp.array([1e8], dtype=jnp.float32)], axis=-1) # 上限 dist2 = jnp.sum( squared_difference( jnp.expand_dims(positions, axis=-2), # (84, 1, 3) jnp.expand_dims(positions, axis=-3)), # (1, 84, 3) ## 上下两部分正好是残基对相互匹配求差, axis=-1, keepdims=True) ##[84, 84, 1] dgram = ((dist2 > lower_breaks).astype(jnp.float32) * (dist2 < upper_breaks).astype(jnp.float32)) return dgram ## 保留残基之间距离为〉lower_breaks 〈 upper_breaks , 这个是mask (84, 84, bin)-> 最后一维是不同桶的分布 。。。。。。。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
if c.recycle_features: # 特征信息 prev_msa_first_row = hk.LayerNorm( axis=[-1], create_scale=True, create_offset=True, name='prev_msa_first_row_norm')( batch['prev_msa_first_row']) # (84, 256) --> (84, 256) 取第一行MSA- 1
- 2
- 3
- 4
- 5
- 6
- 7
关联最大距离特征

if c.max_relative_feature: # 相互关联的最大距离 # Add one-hot-encoded clipped residue distances to the pair activations. pos = batch['residue_index'] offset = pos[:, None] - pos[None, :] # (84, 84) pair相对位置相减 rel_pos = jax.nn.one_hot( jnp.clip( offset + c.max_relative_feature, a_min=0, a_max=2 * c.max_relative_feature), 2 * c.max_relative_feature + 1) ## 位置差信息 pair_activations += common_modules.Linear( c.pair_channel, name='pair_activiations')( rel_pos) # (84, 84, 65) -> (84, 84, 128)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
模版特征
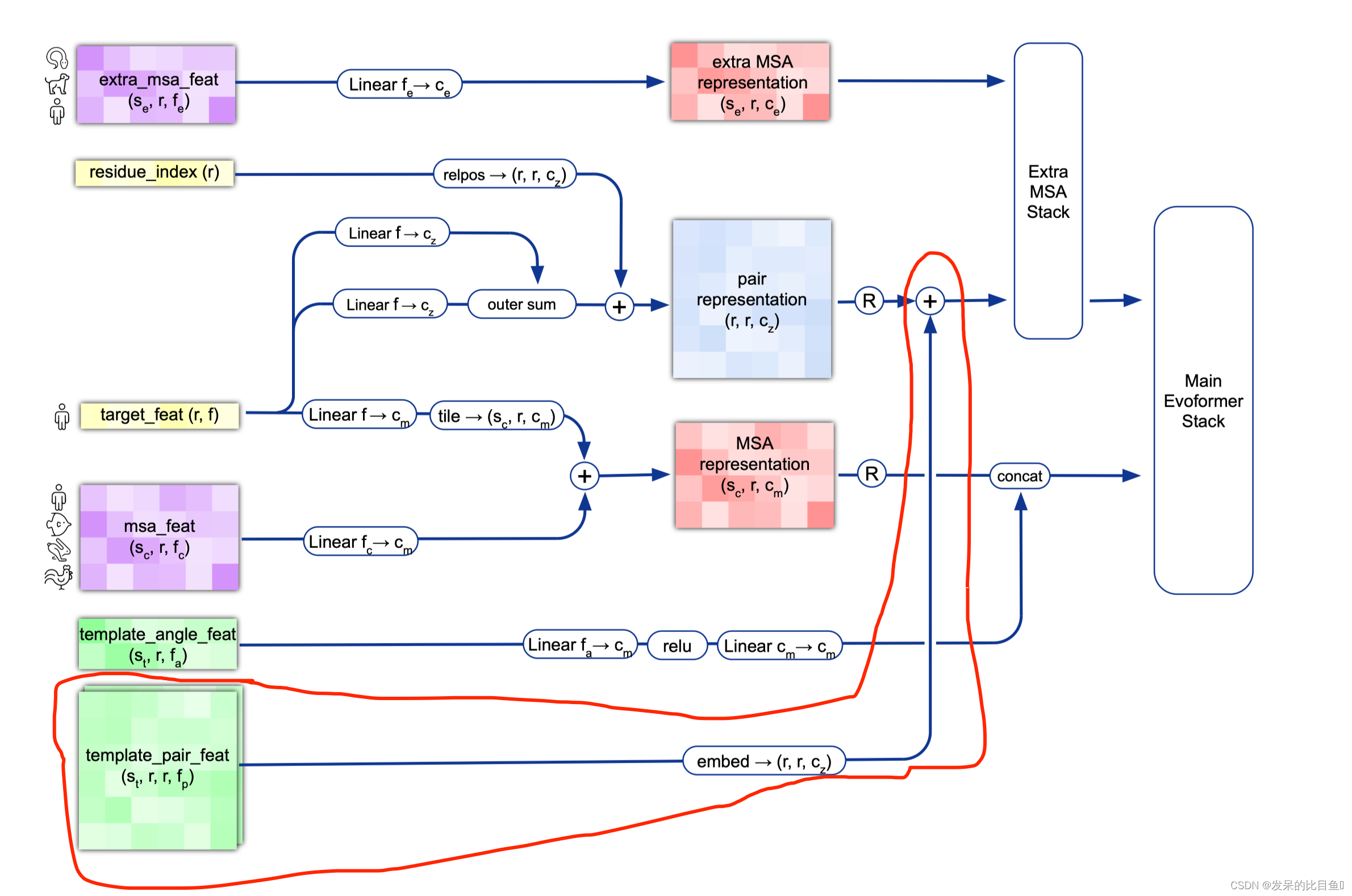
** Alg. 2 “Inference” lines 9-13**
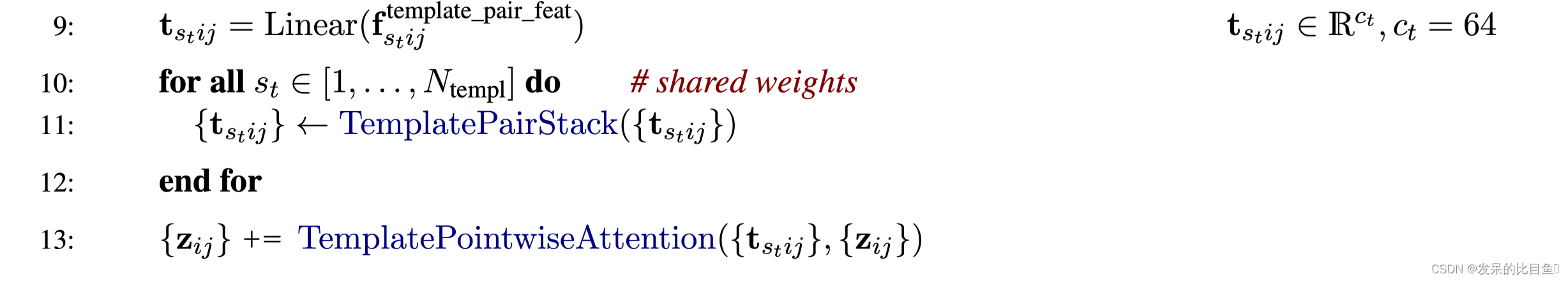
使用的预处理信息
[k for k in batch.keys() if k.startswith('template_')] ['template_aatype', # 氨基酸序列的one-hot表示 [N_temp, N_res, 22] 'template_all_atom_masks', # [N_temp, n_res, 37] 'template_all_atom_positions', #原子信息 [N_temp, n_res, 37, 3] 'template_mask', #[N-temp] 'template_pseudo_beta', #[N_temp, N_res, 3] 'template_pseudo_beta_mask', # [N_temp, N_res] 指示β-碳(甘氨酸的α-碳)原子是否具有该残基处模板的坐标的掩码 'template_sum_probs'] # [n_temp, 1]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
if c.template.enabled: # 是否使用模版 template_batch = {k: batch[k] for k in batch if k.startswith('template_')} template_pair_representation = TemplateEmbedding(c.template, gc)( pair_activations, template_batch, mask_2d, is_training=is_training) pair_activations += template_pair_representation ...... class SingleTemplateEmbedding(hk.Module): """Embeds a single template.""" ........ act = common_modules.Linear(num_channels, initializer='relu', name='embedding2d')(act) # Jumper et al. (2021) Suppl. Alg. 2 "Inference" line 11 act = TemplatePairStack( self.config.template_pair_stack, self.global_config)(act, mask_2d, is_training) act = hk.LayerNorm([-1], True, True, name='output_layer_norm')(act) return act ## stack template pair 信息 class TemplatePairStack(hk.Module): def __call__(self, pair_act, pair_mask, is_training, safe_key=None): """Builds TemplatePairStack module. """ ..... def block(x): ...... pair_act = dropout_wrapper_fn( TriangleAttention(c.triangle_attention_starting_node, gc, name='triangle_attention_starting_node'), pair_act, pair_mask, next(sub_keys)) TriangleAttention(c.triangle_attention_ending_node, gc, name='triangle_attention_ending_node'), ..... TriangleMultiplication(c.triangle_multiplication_outgoing, gc, name='triangle_multiplication_outgoing'), ...... TriangleMultiplication(c.triangle_multiplication_incoming, gc, name='triangle_multiplication_incoming'), ....... Transition(c.pair_transition, gc, name='pair_transition'), ...... res_stack = layer_stack.layer_stack(c.num_block)(block) pair_act, safe_key = res_stack((pair_act, safe_key)) return pair_act- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
额外的MSA Representation


extra_msa_feat = create_extra_msa_feature(batch) # 将extra_msa扩展为one-hot,并使用其他额外的msa功能 extra_msa_activations = common_modules.Linear(c.extra_msa_channel, name='extra_msa_activations')(extra_msa_feat) def create_extra_msa_feature(batch): """将extra_msa扩展为1hot,并与其他额外的msa功能合并。 我们尽可能晚做这件事,因为一个小时的额外msa可能非常大。 """ # 23 = 20 amino acids + 'X' for unknown + gap + bert mask msa_1hot = jax.nn.one_hot(batch['extra_msa'], 23) msa_feat = [msa_1hot, jnp.expand_dims(batch['extra_has_deletion'], axis=-1), jnp.expand_dims(batch['extra_deletion_value'], axis=-1)] return jnp.concatenate(msa_feat, axis=-1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Extra MSA Stack


EvoformerIteration这部分内容我们在Evoformer中仔细讲, 我们大概了解一下,输入的是extra_msa_activations和pair_activationsextra_msa_stack_iteration = EvoformerIteration( c.evoformer, gc, is_extra_msa=True, name='extra_msa_stack') 。。。。。。。 extra_msa_stack = layer_stack.layer_stack( c.extra_msa_stack_num_block)( extra_msa_stack_fn) extra_msa_output, safe_key = extra_msa_stack( (extra_msa_stack_input, safe_key)) 。。。。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
MSA 与模版角度特征concat

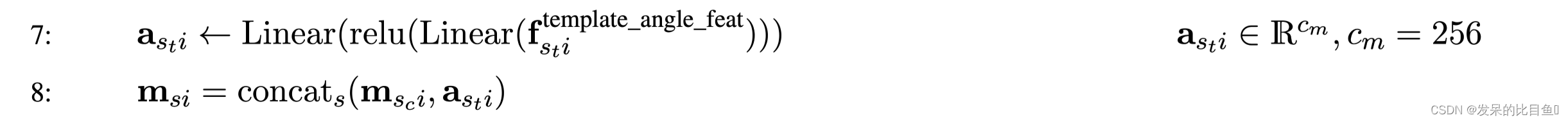
。。。。。。。 # 模板aatype、扭角和掩模嵌入。 # Shape (templates, residues, msa_channels) ret = all_atom.atom37_to_torsion_angles( # 计算每个残基7个扭转角(sin,cos编码)。 aatype=batch['template_aatype'], all_atom_pos=batch['template_all_atom_positions'], all_atom_mask=batch['template_all_atom_masks'], # Ensure consistent behaviour during testing: placeholder_for_undefined=not gc.zero_init) template_activations = common_modules.Linear( c.msa_channel, initializer='relu', name='template_single_embedding')( template_features) template_activations = jax.nn.relu(template_activations) template_activations = common_modules.Linear( c.msa_channel, initializer='relu', name='template_projection')( template_activations) # Concatenate the templates to the msa. evoformer_input['msa'] = jnp.concatenate( [evoformer_input['msa'], template_activations], axis=0)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
网络主干线evoformer

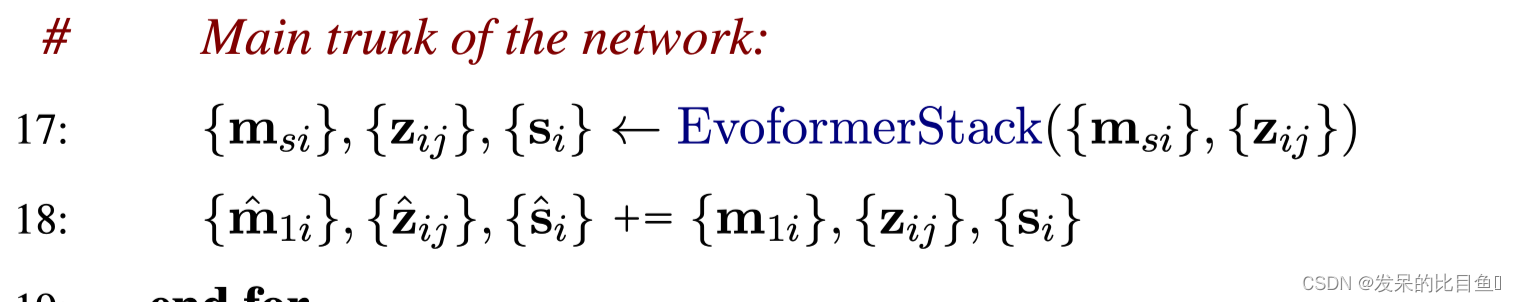
EvoformerIteration网络的处理过程比较复杂, 我们这里省略,这里只讲解该网络的输入和输出。
输入的特征- msa:(512, N_res, 256)
- pair: (N_res, N_res, 128)
evoformer_iteration = EvoformerIteration( c.evoformer, gc, is_extra_msa=False, name='evoformer_iteration') 。。。。。 evoformer_stack = layer_stack.layer_stack(c.evoformer_num_block)(evoformer_fn) evoformer_output, safe_key = evoformer_stack((evoformer_input, safe_key)) ...... single_activations = common_modules.Linear(c.seq_channel, name='single_activations')(msa_activations[0]) ## 取第一条msa # (N_res, 384) output = { 'single': single_activations,# (N_res, 384) 'pair': pair_activations, # (N_res, N_res, 128) # 裁剪模板行,使其不在MaskedMsaHead中使用。 'msa': msa_activations[:num_sequences, :, :], 'msa_first_row': msa_activations[0], }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
相关阅读:
【Python】文件路径操作之split函数
【第五篇】- 深入学习Git 创建仓库
CoreData + CloudKit 在初始化 Schema 时报错 A Core Data error occurred 的解决
useCallBack
Spring Boot 的创建和运行
【iOS】面试整理
LNMP架构&部署Discuz论坛系统
数据库常见面试题 —— 12. SQL 如何优化才能解决数据倾斜类问题
Android 内核加载fw通用方法分析
【附源码】Python计算机毕业设计培训中心管理系统
- 原文地址:https://blog.csdn.net/weixin_42486623/article/details/128125045
