-
Python 音频处理以及可视化 Amplitude,MFCC,Mel Spectrogram, librosa 库
利用python库 librosa库对于音频文件进行预处理,以及可视化操作。
1. Load Audio Data 导入音频
将音频文件(这里使用苹果录音文件 .m4a 格式)导入librosa,音频格式可以为其它(甚至视频文件mp4也是可以的)
import librosa audio_data = 'Audio/1.m4a' y, sr = librosa.load(audio_data) print('y:', y, '\n') print('y shape:', np.shape(y), '\n') print('Sample Rate (Hz):', sr, '\n') print('Check Len of Audio:', np.shape(y)[0]/sr)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
返回值有两个 y 和 sr。
y 是音频时间序列并支持多声道,
sr 是采样率 (注意:librosa默认load使用的是22050hz的采样率)
如果想要用固定采样率,则可以使用y, sr = librosa.load(audio_data,sr=None)表示保持原音频的采样率。或者可以规定采样率sr:y, sr = librosa.load(audio_data,sr=44100)。想要获取音频的基本信息可以输入:
print('y:', y, '\n') print('y shape:', np.shape(y), '\n') print('Sample Rate (Hz):', sr, '\n') print('Check Len of Audio:', np.shape(y)[0]/sr)- 1
- 2
- 3
- 4
2. Audio Visualization 音频可视化
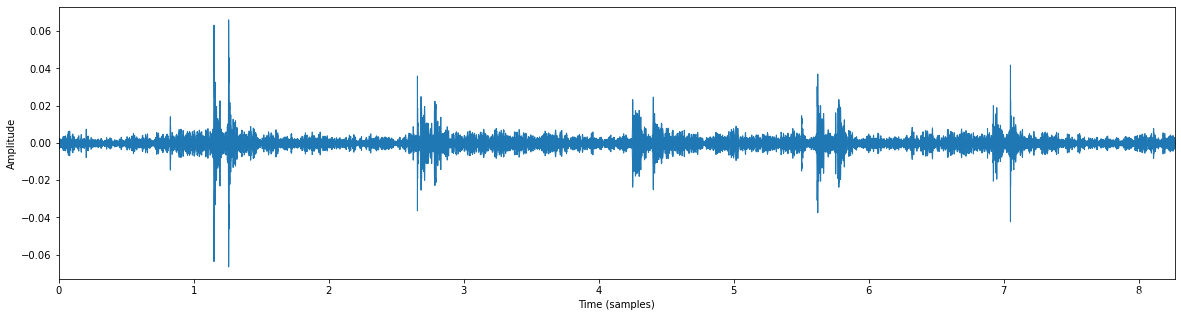
a) Amplitude
音频可视化,y轴 为 Amplitude (振幅)随时间变化曲线。- 1
import matplotlib.pyplot as plt import librosa.display plt.figure(figsize=(20, 5)) librosa.display.waveplot(y, sr=sr) plt.xlabel('Time (samples)') plt.ylabel('Amplitude') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
b) Amplitude to DB
X = librosa.stft(y) Xdb = librosa.amplitude_to_db(abs(X)) plt.figure(figsize=(20, 5)) librosa.display.specshow(Xdb, sr=sr, x_axis='time', y_axis='hz') plt.colorbar() plt.show()- 1
- 2
- 3
- 4
- 5
- 6

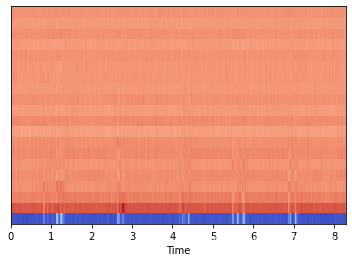
c) MFCC 梅尔频率倒谱系数
mfccs = librosa.feature.mfcc(y=y, sr=sr) librosa.display.specshow(mfccs, sr=sr, x_axis='time')- 1
- 2
d) Mel Spectrogram 梅尔频谱图
mel = librosa.feature.melspectrogram(y=y, sr=sr) librosa.display.specshow(mel, sr=sr, x_axis='time')- 1
- 2

以上。 -
相关阅读:
洛谷P6586 蒟蒻火锅的盛宴
【季度复盘】2022年5~7月复盘
一个支持将Html页面转为PDF的.Net开源项目
python冒泡排序,非常细节
vue封装的echarts组件被同一个页面多次引用无法正常显示问题(已解决)
Java中的SPI原理浅谈
微信小程序实现拍照并拿到图片对象功能
面试题(真题)
SpringMVC基本配置
Android UI 开发·界面布局开发·案例分析
- 原文地址:https://blog.csdn.net/qq_41608408/article/details/128086842