-
移动端异构运算技术 - GPU OpenCL 编程(基础篇)
一、前言
随着移动端芯片性能的不断提升,在移动端上实时进行计算机图形学、深度学习模型推理等计算密集型任务不再是一个奢望。在移动端设备上,GPU 凭借其优秀的浮点运算性能,以及良好的 API 兼容性,成为移动端异构计算中非常重要的计算单元。现阶段,在 Android 设备市场,高通 Adreno 和华为 Mali 已经占据了手机 GPU 芯片的主要份额,二者均提供了强劲的 GPU 运算能力。OpenCL,作为 Android 的系统库,在两个芯片上均得到良好的支持。
目前,百度 APP 已经将 GPU 计算加速手段,应用在深度模型推理及一些计算密集型业务上,本文将介绍 OpenCL 基础概念与简单的 OpenCL 编程。
(注:Apple 对于 GPU 推荐的使用方式是 Metal,此处暂不做展开)二、基础概念
2.1 异构计算
异构计算(Heterogeneous Computing),主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。常见的计算单元类别包括 CPU、GPU 等协处理器、DSP、ASIC、FPGA 等。
2.2 GPU
GPU(Graphics Processing Unit),图形处理器,又称显示核心、显卡、视觉处理器、显示芯片或绘图芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上执行绘图运算工作的微处理器。传统方式中提升 CPU 时钟频率和内核数量而提高计算能力的方式已经遇到了散热以及能耗的瓶颈。虽然 GPU 单个计算单元的工作频率较低,却具备更多的内核数及并行计算能力。相比于 CPU,GPU 的总体性能 - 芯片面积比,性能 - 功耗比都更高。
三、OpenCL
OpenCL(Open Computing Language)是一个由非盈利性技术组织 Khronos Group 掌管的异构平台编程框架,支持的异构平台涵盖 CPU、GPU、DSP、FPGA 以及其他类型的处理器与硬件加速器。OpenCL 主要包含两部分,一部分是一种基于 C99 标准用于编写内核的语言,另一部分是定义并控制平台的 API。
OpenCL 类似于另外两个开放的工业标准 OpenGL 和 OpenAL ,二者分别用于三维图形和计算机音频方面。OpenCL 主要扩展了 GPU 图形生成之外的计算能力。
3.1 OpenCL 编程模型
使用 OpenCL 编程需要了解 OpenCL 编程的三个核心模型,OpenCL 平台、执行和内存模型。
平台模型(Platform Model)
Platform 代表 OpenCL 视角上的系统中各计算资源之间的拓扑联系。对于 Android 设备,Host 即是 CPU。每个 GPU 计算设备(Compute Device)均包含了多个计算单元(Compute Unit),每个计算单元包含多个处理元素(Processing Element)。对于 GPU 而言,计算单元和处理元素就是 GPU 内的流式多处理器。

执行模型 (Execution Model)
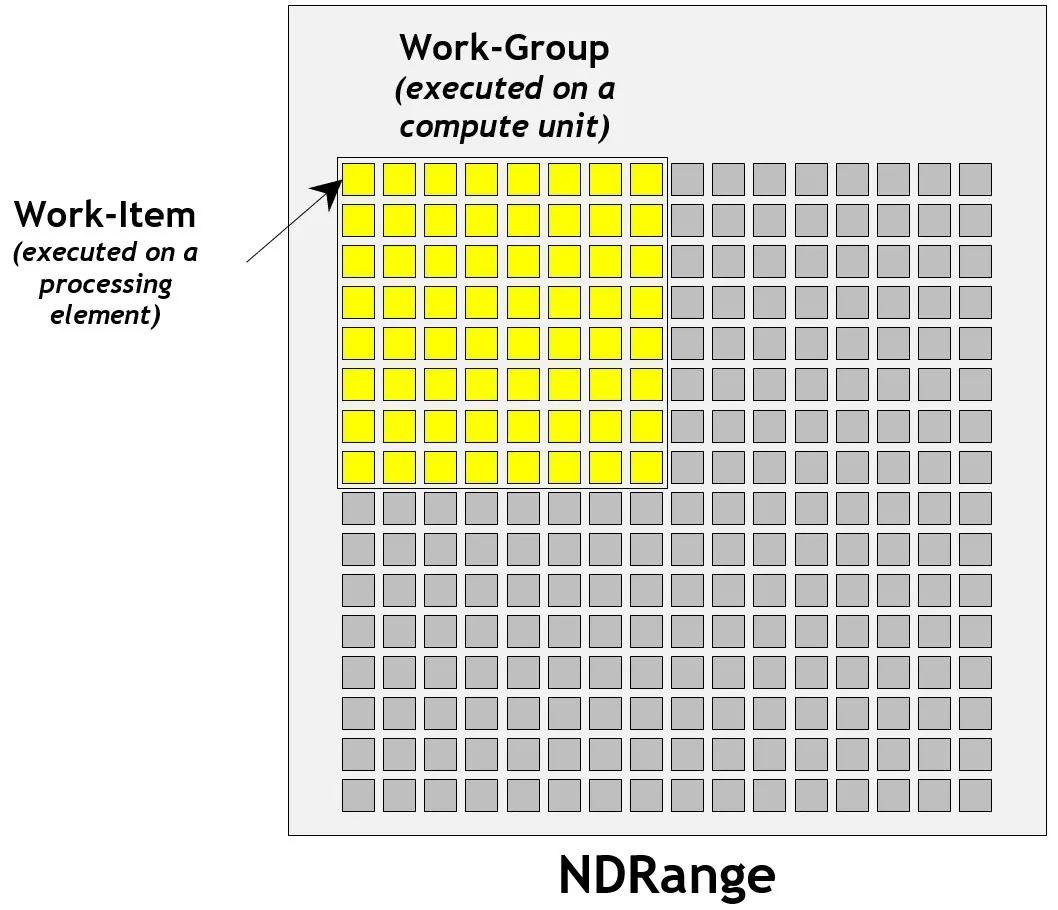
通过 OpenCL 的 clEnqueueNDRangeKernel 命令,可以启动预编译好的 OpenCL 内核,OpenCL 架构上可以支持 N 维的数据并行处理。以二维图片为例,如果将图片的宽高作为 NDRange,在 OpenCL 的内核中可以把图片的每个像素放在一个处理元素上执行,借此可以达到并行化执行的目地。
从上面平台模型部分可以知道,为了提高执行效率,处理器通常会将处理元素分配到执行单元中。我们可以在 clEnqueueNDRangeKernel 中指定工作组大小。同一个工作组中的工作项可以共享本地内存,可以使用屏障(Barriers)去进行同步,也可以通过特定的工作组函数(比如 async_work_group_copy)来进行协作。
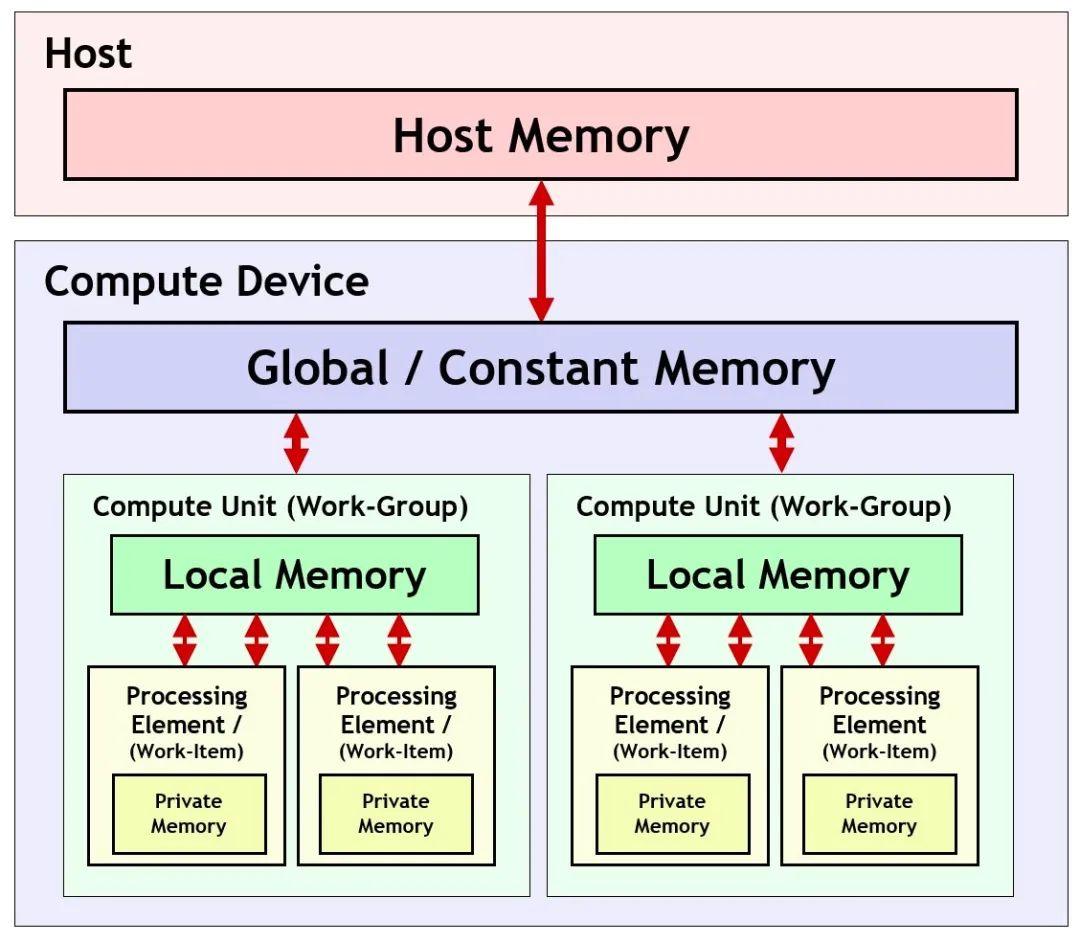
内存模型 (Memory Model)
下图中描述了 OpenCL 的内存结构:
-
宿主内存(Host Memory):宿主 CPU 可直接访问的内存。
-
全局 / 常量内存 (Global/Constant Memory):可以用于计算设备中的所有计算单元。
-
本地内存(Local Memory):对计算单元中的所有处理元素可用。
-
私有内存(Private Memory):用于单个处理元素。
3.2 OpenCL 编程
OpenCL 的编程实际应用中需要一些工程化的封装,本文仅以两个数组相加作为举例,并提供一个简单的示例代码作为参考 ARRAY_ADD_SAMPLE (https://github.com/xiebaiyuan/opencl_cook/blob/master/array_add/array_add.cpp)。
本文将用此作为示例,来阐述 OpenCL 的工作流程。
OpenCL 整体流程主要分为以下几个步骤:
初始化 OpenCL 相关环境,如 cl_device、cl_context、cl_command_queue 等
- cl_int status;
- // init device
- runtime.device = init_device();
- // create context
- runtime.context = clCreateContext(nullptr, 1, &runtime.device, nullptr, nullptr, &status);
- // create queue
- runtime.queue = clCreateCommandQueue(runtime.context, runtime.device, 0, &status);
初始化程序要执行的 program、kernel
- cl_int status;
- // init program
- runtime.program = build_program(runtime.context, runtime.device, PROGRAM_FILE);
- // create kernel
- runtime.kernel = clCreateKernel(runtime.program, KERNEL_FUNC, &status);
准备输入输出,设置到 CLKernel
- // init datas
- float input_data[ARRAY_SIZE];
- float bias_data[ARRAY_SIZE];
- float output_data[ARRAY_SIZE];
- for (int i = 0; i < ARRAY_SIZE; i++) {
- input_data[i] = 1.f * (float) i;
- bias_data[i] = 10000.f;
- }
- // create buffers
- runtime.input_buffer = clCreateBuffer(runtime.context, CL_MEM_READ_ONLY |
- CL_MEM_COPY_HOST_PTR, ARRAY_SIZE * sizeof(float), input_data, &status);
- runtime.bias_buffer = clCreateBuffer(runtime.context, CL_MEM_READ_ONLY |
- CL_MEM_COPY_HOST_PTR, ARRAY_SIZE * sizeof(float), bias_data, &status);
- runtime.output_buffer = clCreateBuffer(runtime.context, CL_MEM_READ_ONLY |
- CL_MEM_COPY_HOST_PTR, ARRAY_SIZE * sizeof(float), output_data, &status);
- // config cl args
- status = clSetKernelArg(runtime.kernel, 0, sizeof(cl_mem), &runtime.input_buffer);
- status |= clSetKernelArg(runtime.kernel, 1, sizeof(cl_mem), &runtime.bias_buffer);
- status |= clSetKernelArg(runtime.kernel, 2, sizeof(cl_mem), &runtime.output_buffer);
执行获取结果
- // clEnqueueNDRangeKernel
- status = clEnqueueNDRangeKernel(runtime.queue, runtime.kernel, 1, nullptr, &ARRAY_SIZE,
- nullptr, 0, nullptr, nullptr);
- // read from output
- status = clEnqueueReadBuffer(runtime.queue, runtime.output_buffer, CL_TRUE, 0,
- sizeof(output_data), output_data, 0, nullptr, nullptr);
- // do with output_data
- ...
四、总结
随着 CPU 瓶颈的到来,GPU 或者其他专用计算设备的编程将是未来的一个重要的技术方向。
-
-
相关阅读:
C语言相关习题(移位操作、递归)
k8s network-attachment-definition
Linux命令(96)之seq
02Python基础知识
Mac和VScode配置fortran
数据探索电商平台用户行为流失分析
晶振不仅仅是可以振荡就够了
高德地图用法
【持续更新】C/C++ 踩坑记录(一)
flink sql -mysql cdc 到hudi表在输出到kafka中
- 原文地址:https://blog.csdn.net/m0_65038841/article/details/128144498
