-
mapper-reducer编程搭建
一、虚拟机安装CentOS7并配置共享文件夹
二、CentOS 7 上hadoop伪分布式搭建全流程完整教程
三、本机使用python操作hdfs搭建及常见问题
四、mapreduce搭建
五、mapper-reducer编程搭建
六、hive数据仓库安装一、打开hadoop
二、创建mapper.py、reducer.py及参数文件
1.创建 mapper.py
cd /home/huangqifa/software/- 1
touch mapper.py- 1
编辑内容
sudo gedit mapper.py- 1
粘贴如下内容:
#!/usr/bin/env python import sys for line in sys.stdin: line = line.strip() words = line.split() for word in words: print '%s\t%s' % (word, 1) # input comes from standard input # remove leading and trailing whitespace # split the line into words # write the results to STDOUT- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.创建reducer.py
touch reducer.py- 1
sudo gedit reducer.py- 1
粘贴如下
#!/usr/bin/env python from operator import itemgetter import sys current_word = None current_count = 0 word = None for line in sys.stdin: line = line.strip() word, count = line.split('\t', 1) try: count = int(count) except ValueError: Continue if current_word == word: current_count += count else: if current_word: print '%s\t%s' % (current_word, current_count) current_count = count current_word = word if current_word == word: print '%s\t%s' % (current_word, current_count)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
赋权
sudo chmod +x mapper.py sudo chmod +x reducer.py- 1
- 2
3.创建参数文件
touch test00.txt- 1
粘贴如下
foo foo quux labs foo bar quux- 1
4.本地测试map与reduce
测试mapper.py
echo "foo foo quux labs foo bar quux" | ./mapper.py- 1
测试reducer.py
echo "foo foo quux labs foo bar quux" | ./mapper.py | sort -k1,1 | ./reducer.py- 1
#其中sort -k 1起到了将mapper的输出按key排序的作用:-k, -key = POS1[,POS2] .

三、测试
1.hadfs中创建目录
hdfs dfs -mkdir -p /user/input- 1
2.上传test00.txt到hdfs中
上传test00.txt到hdfs中的 /user/input目录
hdfs dfs -put /home/huangqifa/software/test00.txt /user/input- 1

3.执行测试例程
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.7.jar -files /home/huangqifa/software/mapper.py,/home/huangqifa/software/reducer.py -mapper "mapper.py" -reducer "reducer.py" -input /user/input/test00.txt -output /user/output- 1
注意修改为自己的mapper.py、reducer.py路径
若已存在/user/output执行时会报错
hdfs dfs -rm -r /user/output- 1
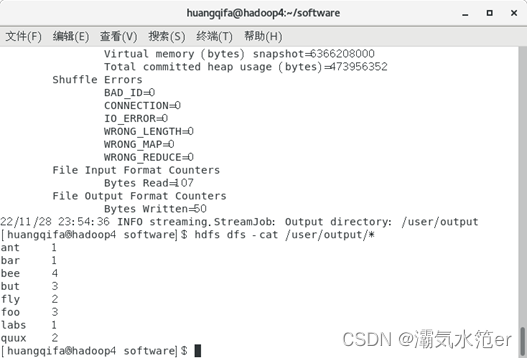
查看输出文件
hdfs dfs -cat /user/output/*- 1
4.下载结果文件
hadoop fs -ls /user/output/- 1
hadoop fs -get /user/output/part-00000- 1

或者通过浏览器网页下载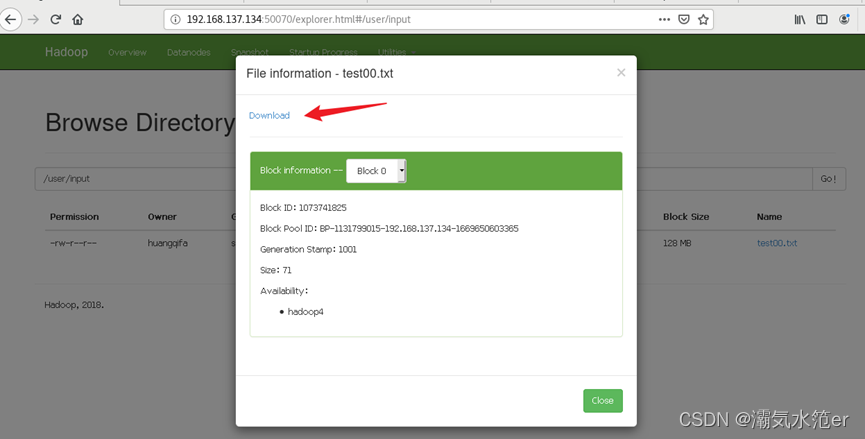
参考
https://blog.csdn.net/andy_wcl/article/details/104610931
https://blog.csdn.net/qq_39315740/article/details/98108912 -
相关阅读:
linux常见环境安装
Mini Homer——几百块钱也能搞到一台远距离图数传链路?
NET9 AspnetCore将整合OpenAPI的文档生成功能而无需三方库
java毕业生设计学生用品交换平台计算机源码+系统+mysql+调试部署+lw
AWS无服务器 应用程序开发—第九章 文件存储(Amazon S3)
【Unity3D】反射和折射
【ML07】Linear Regression using Scikit-Learn
【Codeforces Round #805 (Div. 3)(A~C)】
Android 12(S) 图像显示系统 - BufferQueue的工作流程(十一)
unity学习之汇总解答
- 原文地址:https://blog.csdn.net/qq_52584391/article/details/128118350
