-
Redis与数据库的爱恨纠葛
Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。
早期数据库只要有数据库的操作---增--删--改--查

当用户量特别多的情况下,数据库的数量一定是跟不上用户的数量,对数据库来说是特别繁忙的
看着每天都累趴下的数据库,顿时有种心疼的感觉。
对数据库操作进行了分析,发现读取的业务大于其它业务的总和,那为给数据库介绍了一个专门干缓存的对象----redis
redis
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
自从给数据库分配了对象之后,大量的读取内容都登记在redis中,后续有相同的读取可以直接找redis要了,不用再跑数据库进行I/O操作了,数据库顿时感觉到了工作轻松了不少
redis缓存过期
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,而内存是有限的,如果一直存下去,迟早会有溢满的情况
那能不能清理掉一些老旧过期的数据呢?好像是可行了,那怎么让redis知道它们是老旧的数据呢?
如果我们给这个数据加上标识,那不就可以知道了吗,那又出来一个问题,我们这个数据要使用多久什么时候过期,----------不如就把这个标识改成它的过期时间,只要到了过期时间我们就去把这个数据给删除掉
那redis清理缓存最简单的就是定期清理的比如1000ms去清理一次这个已经过期的缓存,但是如果redis有1000个缓存,redis没有办法一次性清理完毕否则会影响到其它业务的正常存取,为了兼容redis每次只能随机清理100个,能保证缓解一定的内存压力
那么又出来了一个问题既然是随机删的话,我一边删一边又有新的数据过期,那有没有一种可能,redis有一部分数据已经不需要了也长时间没有随机到它,成了漏网之鱼,又霸占着内存
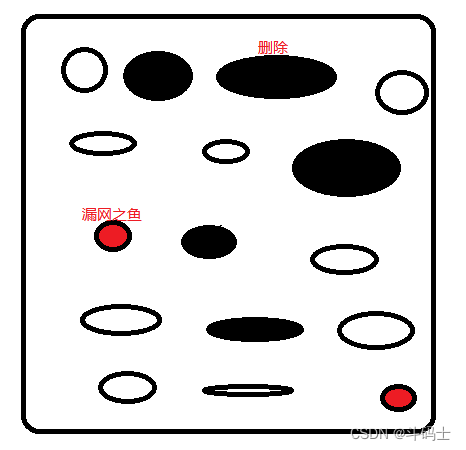
如果再做个一旦遇到查询请求,发现已经超期了,就立即删除,惰性删除,被动触发时发现就删除,但是也会存在一直不被请求到但是也一直在随机之外的过期数据(缓存数据几千上万是非常大概率出现这种漏中漏的漏网之鱼)
缓存淘汰
缓存过期这种情况非常有可能把我们的内存溢满,就算能非常好的处理完这些过期数据,但是还是有一种情况
redis还没过期的时候,数据量redis的内存就给溢满了,怎么办?
- volatile-lru:针对设置了过期时间的key,使用LRU算法进行淘汰
- allkeys-lru:针对所有key使用LRU算法进行淘汰
- volatile-lfu:针对设置了过期时间的key,使用LFU算法进行淘汰
- allkeys-lfu:针对所有key使用LFU算法进行淘汰
- volatile-random: 从设置了过期时间的key中随机删除
- allkeys-random: 从所有key中随机删除
- volatile-ttl:删除生存时间最近的一个键
- noeviction(默认策略):不删除键,返回错误OOM,只能读取不能写入
LRU
Least Recently Used 最近很少使用(最长时间)
LFU
Least Frequently Used最少使用(最少频率) 在LRU的算法上加了次数
图1:

当我输入为5的时候,我需要删除一个数字,我这个时候按LRU算法来 我应该删出的是2,因为3在2出现之后再出现了一次距离5出现的时间比2近
如果按LFU算法 我应该删除的是4 因为3我使用了3次,2我使用2次,4只出现了一次,频率最低
图2:
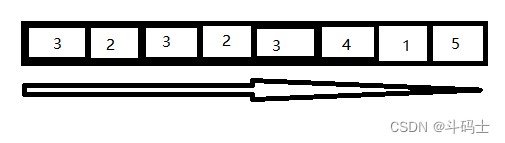
当图2情况下 输入到5的情况下,我需要删除一个数字
LRU 删除2
LFU 这个删除的就是4了,首先按频率来3出现最多 4和1出现次数相同,但是 还会按LRU算法来算一次,1距离5比4距离5的时间短
缓存穿透
当查询的数据不存在时,redis里面也没有缓存,就会去数据库里面查询,但是也有可能数据库也不存在,导致同样的请求来了每次都要去让 MySQL 白忙活一场。作为缓存的价值就没得到体现啦!这就是人们常说的缓存穿透。
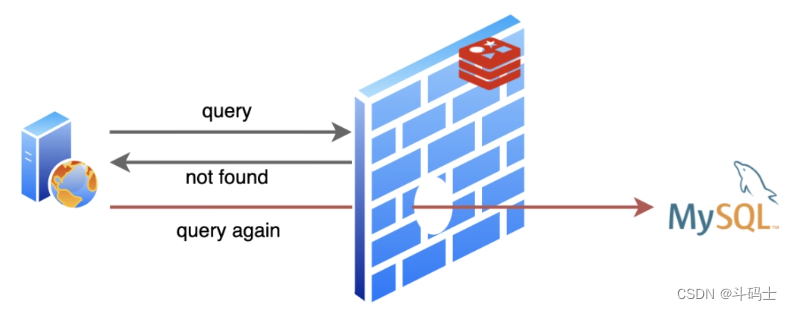
解决方案
(1)布隆过滤器
在控制层对请求先进行校验,不符合条件的请求则被丢弃,从而避免对持久层数据库造成的查询压力。
(2)缓存空对象
当查询的数据不存在于redis中时,请求到了持久层数据库中去查询数据,但查询不出数据,这时会返回空对象,同时把该空对象缓存到redis里,然后设置一个过期时间,往后只要再次请求查询该条数据,该条数据都会从redis中获取(获取redis返回的空对象),从而保护了后端的数据源。
缓存击穿redis里面有一个高频的热点key,可能有大量的访问针对这个key进行访问,如果这个key在某个时间过期了,会导致大量的请求越过redis直接作用在数据库上,而数据库连接资源有限,直接导致其它业务宕机
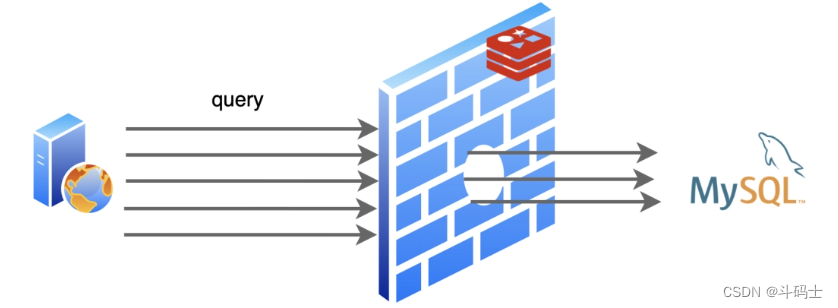
解决方案:
(1)设置热点key永不过期。
(2)加锁对redis与数据库中间加锁,保证每次只有可控的线程数量访问,其它线程等待
缓存雪崩
这个相对缓存击穿更加严重,多个key在统一时间批量失效或者redis直接宕机,导致大批量/所有访问直接作用在数据库上,导致数据库直接挂掉,或者其它大量服务宕机

解决方案:
(1)redis高可用
1.主从
2.哨兵
3.集群
(2)限流降级:通过加锁或队列来控制读取持久层数据库的线程数量
(3)数据预热:预先把可能被大量访问的数据加载到缓存中,并给这些key设置不同的过期时间,让key失效的时间点尽量均匀开来。
-
相关阅读:
GD32F103ZET6奋斗者开发板W5500通信——01 基础移植
Spring循环依赖问题——从源码画流程图
小唐源代码搜索引擎上线,可搜索28种程序语言源代码,源码来自123万个star数量超过100的github项目
第一性原理谈安全性和可靠性
14个Flink SQL性能优化实践分享
layui中页面切分
计算机组成原理---第五章中央处理器---指令执行过程
centos下编译安装各个版本的python
java基本数据类型的包装类[34]
这3个扩展人脉小技巧,你还不来学?
- 原文地址:https://blog.csdn.net/qq_14926283/article/details/128096302