-
Briefings in bioinformatics2021 | QSAR模型中,传统表征要优于molecular embedding?

论文标题:Using molecular embeddings in QSAR modeling: does it make a difference?
一、问题提出
尽管已有的分子表征方法层出不穷,但如何选择最适合QSAR分析的表征方法还没有实证研究。最近发表的一些研究表明,分子embedding在QSAR建模中似乎只匹配或略超过传统表示。虽然在分子embedding和传统表示之间建立一个公平的比较不是很直接,但这样的比较是必要的,它需要通过广泛和仔细的实验工作流程来进行。
旨在回答一下问题:
Q1: 文献中用于QSAR建模的主要分子embedding方法是什么? 在分类/回归任务中,它们是否优于传统的分子表示?
Q2: 将生物目标的信息整合到分子embedding(有监督embedding)中是否会比从无监督embedding中获得更高的预测性能?
Q3: 不同的预处理决策,例如SMILES标准形式或最终embedding的大小,是否对使用分子embedding的QSAR模型的预测性能有显著影响?
二、模型方法
1、Materials and methods
ZINC数据库:200M数据。
预处理阶段结束后,随机选择了4000万个化合物的子集用于训练。
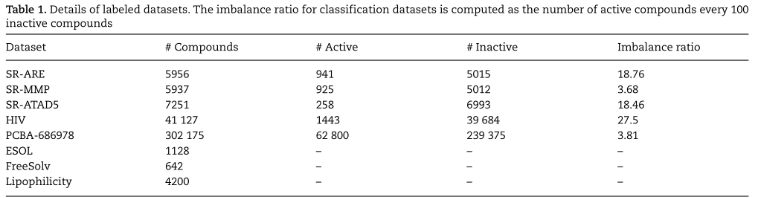
选择了8个不同的标记数据集、5个分类数据集和3个回归数据集用于评估。
对比模型(5个,3个有监督、2个无监督):

2、Experimental design

Training and embedding extraction

Evaluation of the molecular embeddings

三、实验
1、回答第一个问题:
比较使用传统分子表征molecular descriptors、ECFPs、MACCS

在NB、SVM和RF分类器中,传统分子表示对所有数据集都产生了最好的结果,显著优于大多数学习嵌入。在不平衡数据集—“SR-ATAD5”和“HIV”—的情况下,“ECFP”显著优于使用NB的其他表示,在其他分类器的最佳表现表示中,如图5C所示。“MACCS”和“molecular descriptors”也产生了明显优于大多数数据集和分类器中的学习embedding的结果。在' PCBA-686978 '(图E)的情况下,除FFNN外,在所有分类器中使用传统表示都获得了最佳结果。使用三种传统表示方法得到的结果无显著差异。FFNN的最佳结果通常是使用' SA-BiLSTM '获得的:这是对' SR-ARE ', ' SR-MMP '和' SR-ATAD5 '数据集观察到的。对于数据集“HIV”,“ECFP”获得了最好的FFNN结果,显示出对所有学习嵌入的显著差异,而“Mol2Vec_300”对数据集“PCBA-686978”获得了最好的FFNN结果。这些表现出:在所有情况下,这些结果都明显优于使用其他学习过的embedding得到的结果,如下图所示:

2、回答第二个问题:
确定在分类和回归任务中,有监督分子embedding是否可以超过无监督分子embedding。

使用监督表示SA-BiLSTM得到的结果普遍显著优于使用无监督embedding得到的结果。可以得出这样的结论: 总的来说,学习分子embedding并没有远远超过传统分子表示所得到的结果。而且,大多数无监督嵌入方法与传统分子表示的结果不匹配。
在无监督嵌入技术中,“Mol2Vec”产生了最好的结果,通常表现明显优于使用“SMILESVec”或“Seq2Seq”获得的结果。这可能与SMILES公式的预处理步骤有关,该步骤基于计算“ECFP”指纹的算法,与其他两种技术中应用于SMILES公式的简单标记步骤相反。
然而,这样的结果并不是决定性的,因为它们要么没有得到任何显著性检验的支持,要么没有对超参数进行合理调优的系统比较。结果证明了对分子embedding技术进行彻底和仔细的实验比较的重要性,以及学习表示在QSAR建模中的潜在作用。
虽然传统的表示是按照标准算法计算的,每次只观察一个分子,但学习嵌入可以从大量的化合物集合中计算,这可能会产生更丰富的表示,适合于分子相似性分析。此外,自注意等技术可能为分子子结构搜索、分子对接或将分子子结构与生物活性图谱连接等任务提供良好的embedding。
论文中提出的各种方法虽然大量细致的工作证明传统表征要molecular embedding好,但是模型都是老模型,在smiles embedding或者graph中目前已经大幅超过传统表征(eg:MoleculeNet上)。因此......
-
相关阅读:
【黑马-SpringCloud技术栈】【04】Nacos注册中心
数据库系统概论的一些知识点
JVM运行时数据 堆
Java开发从入门到精通(一):Kafka基础知识
【深度学习】基于YOLOV5模型的图像识别-目标检测的性能指标详解与计算方法
docker创建service时动态获取服务名 模版占位符
2022,程序员应该如何找工作
一文深入了解 Hybrid 的实现原理
E. Mishap in Club
tomcat映射本地文件路径
- 原文地址:https://blog.csdn.net/justBeHerHero/article/details/128077217