-
长短期记忆网络(LSTM)重点!(自己汇集了很多资料在这篇博客)

参考资料推荐
心心念念 学了这么久 ,终于学到第57集了。
参考一篇掘金的图文LSTM李宏毅老师的手撕视频配套课件
27:39 开始手撕看完了李沐老师的LSTM又去找了李宏毅老师的课程然后发现又多了个导师。学成归来,感觉这块没听明白的同学也可以去找一下李宏毅的视频,李宏毅老师手算lstm真的猛,感觉看完他的视频之后对这块的理解更深了。链接:
【【LSTM长短期记忆网络】3D模型一目了然,带你领略算法背后的逻辑】
这个视频不错:基础知识

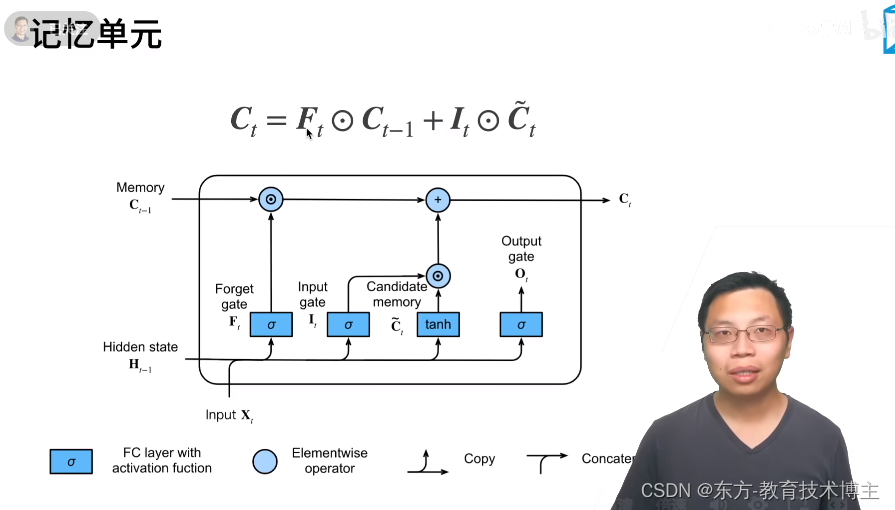
这两个东西相互独立,没有说 有了一个 ,就不能有另一个。
C 范围 是 -1—+1之间,
F 和 I 的值 都在0-1 之间,
所以这两个加起来的值,可能在 -2到+2之间。
所以再做一次 tanh,把取值放到-1到+1之间,
在做一次点乘,来决定要不要输出这个玩意。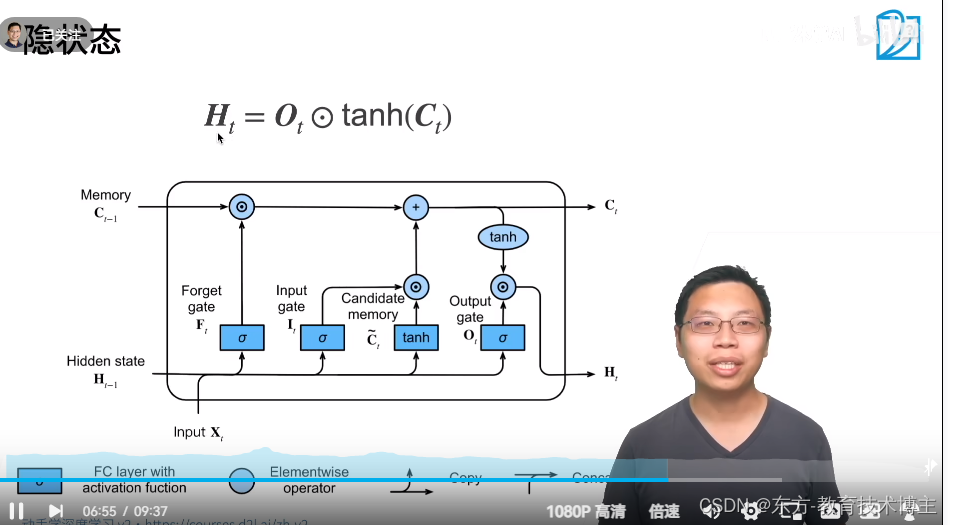
比起之前重置放在最前面,这个重置放在了最后面。比起GRU 多了个c。
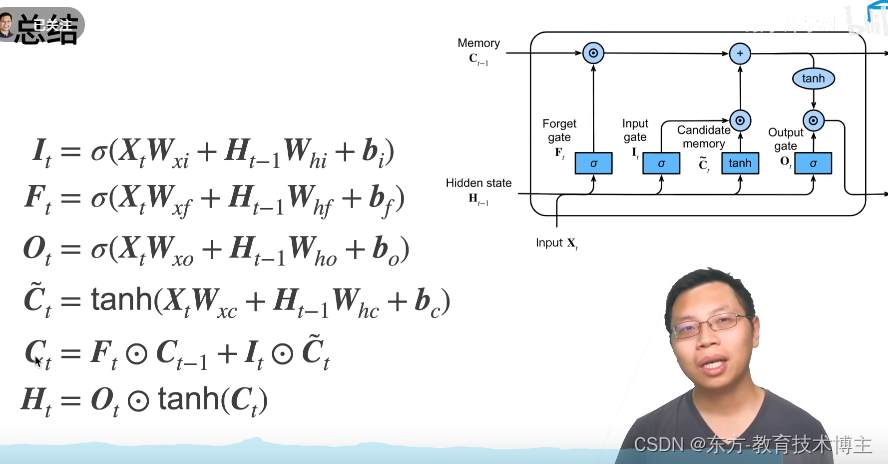
评论区精髓
代码实现
底层实现
import torch from torch import nn from d2l import torch as d2l batch_size, num_steps = 32, 35 train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) def get_lstm_params(vocab_size, num_hiddens, device): num_inputs = num_outputs = vocab_size def normal(shape): return torch.randn(size=shape, device=device) * 0.01 def three(): return (normal( (num_inputs, num_hiddens)), normal((num_hiddens, num_hiddens)), torch.zeros(num_hiddens, device=device)) W_xi, W_hi, b_i = three() W_xf, W_hf, b_f = three() W_xo, W_ho, b_o = three() W_xc, W_hc, b_c = three() W_hq = normal((num_hiddens, num_outputs)) b_q = torch.zeros(num_outputs, device=device) params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] for param in params: param.requires_grad_(True) return params # 初始化函数 def init_lstm_state(batch_size, num_hiddens, device): return (torch.zeros((batch_size, num_hiddens), device=device), torch.zeros((batch_size, num_hiddens),device=device)) # 实际模型 def lstm(inputs, state, params): [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params (H, C) = state outputs = [] for X in inputs: I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i) F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f) O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o) C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c) C = F * C + I * C_tilda H = O * torch.tanh(C) Y = (H @ W_hq) + b_q outputs.append(Y) return torch.cat(outputs, dim=0), (H, C) # 训练 vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu() num_epochs, lr = 500, 1 model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params, init_lstm_state, lstm) d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
简洁实现
# 简洁实现 num_inputs = vocab_size lstm_layer = nn.LSTM(num_inputs, num_hiddens) model = d2l.RNNModel(lstm_layer, len(vocab)) mode = model.to(device) d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)- 1
- 2
- 3
- 4
- 5
- 6
-
相关阅读:
高效管理企业固定资产的办法
pytorch+sklearn实现数据加载
物联网_01_物理设备的网络接入
【入门】.Net Core 6 WebApi 项目搭建
MT4选网页版还是桌面版?anzo capital昂首资本分析优劣
阿里二面:谈谈ThreadLocal的内存泄漏问题?问麻了。。。。
Kubernetes CRD 介绍
华为云云耀云服务器L实例评测 | 实例评测使用之硬件参数评测:华为云云耀云服务器下的 Linux 网络监控神器 bmon
WebStorm创建第一个Express项目
arm-none-eabi-gcc下实现printf的两种方式
- 原文地址:https://blog.csdn.net/qq_41517071/article/details/127691849
