-
一文看懂推荐系统:物品冷启03:聚类召回
一文看懂推荐系统:物品冷启03:聚类召回
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
【10】一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
【11】一文看懂推荐系统:召回09:地理位置召回、作者召回、缓存召回
【12】一文看懂推荐系统:排序01:多目标模型
【13】一文看懂推荐系统:排序02:Multi-gate Mixture-of-Experts (MMoE)
【14】一文看懂推荐系统:排序03:预估分数融合
【15】一文看懂推荐系统:排序04:视频播放建模
【16】一文看懂推荐系统:排序05:排序模型的特征
【17】一文看懂推荐系统:排序06:粗排三塔模型,性能介于双塔模型和精排模型之间
【18】一文看懂推荐系统:特征交叉01:Factorized Machine (FM) 因式分解机
【19】一文看懂推荐系统:物品冷启01:优化目标 & 评价指标
【20】一文看懂推荐系统:物品冷启02:简单的召回通道
提示:文章目录
聚类召回
这节介绍聚类召回,它是基于笔记的图文内容做推荐,
聚类召回在物品能启动的时候特别有用。聚类召回的基本思想是这样的,
如果用户喜欢一篇笔记,那么他会喜欢内容相似的笔记。

假如我收藏了一篇在上海买房的笔记,系统给我推更多上海买房的笔记,我有可能会点开。
刚才说了,我们需要判断两篇笔记的内容相似度,
这个可以用神经网络来做事,先训练一个神经网络。
基于笔记的类目和图文内容,把笔记映射到向量,
向量的相似度就是笔记内容相似度。我们对笔记向量做聚类,划分为1000个cluster,
记录每个cluster的中心方向,对笔记向量做聚类,
所以这种召回通道叫做聚类召回,可以用k-means聚类,聚类的时候需要指定一个相似度,比如用余弦相似度。
聚类召回通道有一个索引,当新笔记发布的时候,新笔记就会上索引,
我讲一下索引是怎么样建的。

当一篇新笔记发布之后,用神经网络把它的图文内容映射到一个特征向量,
然后把这个特征向量去跟1000个cluster中心向量做比较,
找到最相似的向量作为新笔记的cluster。到这一步,新笔记绑定了一个cluster,把新笔记的ID添加到索引上,
索引是从cluster到笔记ID列表。
一共有1000个cluster,每个cluster后面是笔记ID列表,列表是按照笔记的发布时间倒排的,最新的笔记排在最前面。概括一下,一篇新笔记发布之后,就要判断它跟1000个cluster中哪个最相似,
然后把笔记ID添加到索引上,有了索引就可以在线上做召回,
当一个用户刷新小红书发推荐的请求,

那么系统就要用他的ID找到他的last-n个记录包括点赞、收藏、转发的笔记列表,
把这些笔记作为种子笔记,去找回相似的笔记,
用神经网络把用户的每篇种子笔记映射到一个特征向量,
然后与1000个中心向量做比较,寻找最相似的cluster。
这样做完,系统就知道用户对哪些cluster感兴趣,
然后从每个cluster笔记的列表中取回最新发布的M篇笔记,这样的话最多取回m ×N篇型笔记
N的意思是保留最新N条用户行为记录,包括点赞、收藏、转发等行为
把这N篇笔记作为种子,笔记M的意思是每篇种子笔记召回M篇新笔记,所以一共召回M乘以N篇。新笔记聚类召回跟类目召回有相同的缺点,都是只对刚刚发布的新笔记有效。
一篇笔记发布一两个小时之后,就不太可能被召回了。聚类召回需要调用一个神经网络,把笔记图文内容映射到一个向量。
如果两篇笔记的内容相似,那么两篇笔记的向量就应该有较大的一些相似度。内容相似度模型
下面我们来搭建这样一个神经网络。
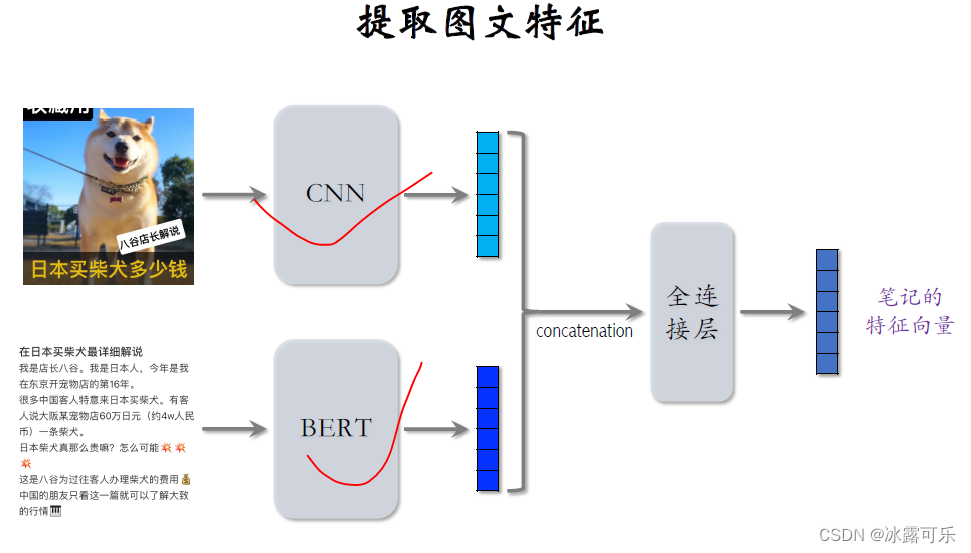
我们以小红书的图文笔记为例,笔记中有几张图和几段文字,
这里只考虑最简单的情况,笔记中只有一张图,
用cnn提取图片的特征得到一个向量,
用bert提取文字的特征得到另一个向量,
把两个向量做congratulation,输入全连接层神经网络输出一个向量。
这个向量是对笔记图文的表征。
如果两篇笔记内容相似,它们的向量会相似。
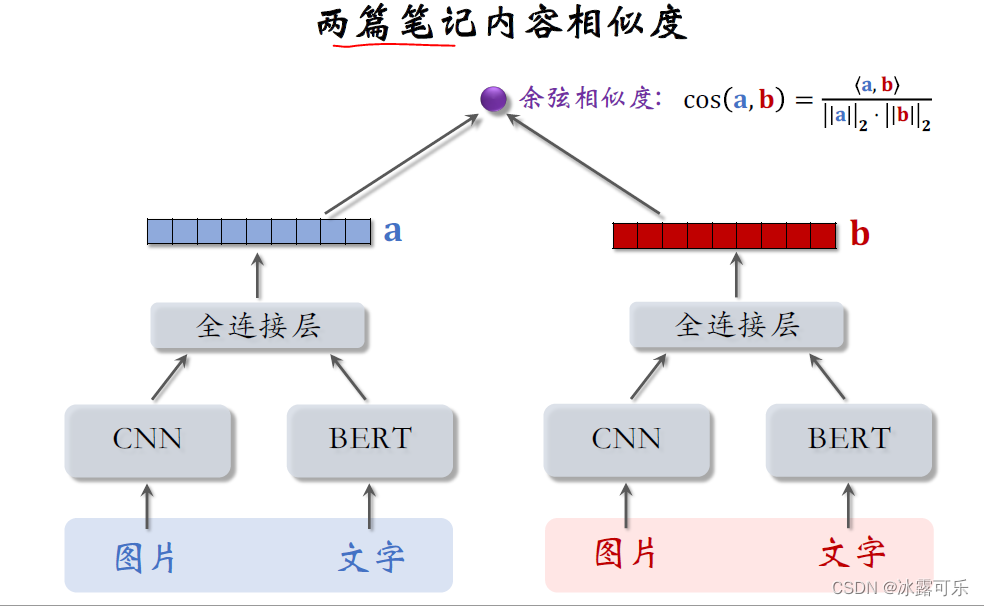
有两篇笔记,各自都有图片和文字,把左边的笔记输入刚才定义的神经网。
我得到笔记的特征向量同样的操作,把右边的笔记映射到另一个特征向量,
这两个神经网络的参数是相同的,
计算两个向量夹角的余弦,
得到一个介于负一到正一之间的数,它叫做余弦相似度
衡量两篇笔记有多相似,训练内容相似度模型
搭好模型之后需要训练模型,模型中的bert是预训练好的,可以固定bert的参数,也可以做finetune,怎么样都可以。
CNN也是预训练好的。比如用imageNet数据集上预训练好的神经网络可以做finetune更新CNBN的参数,
全联接层是随机初始化的,需要从数据中学习。刚才介绍了模型结构,下面具体讲解如何训练神经网络
训练的方法跟双塔模型比较类似,每个训练样本都是三元组。
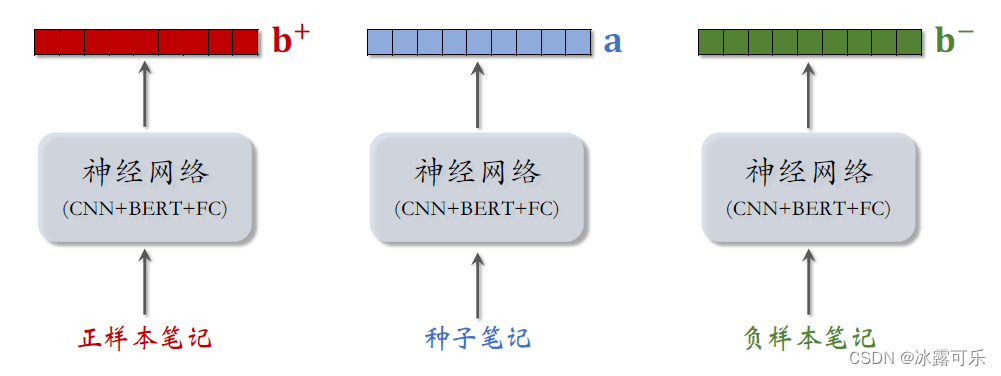
正样本笔记、种子笔记、负样本笔记,
把三篇笔记输入神经网络,神经网络包含cnn bird以及全连接层,
这三个神经网络的参数是完全相同的。神经网络输出三个向量记作b加,a,b减
分别对应正样本笔记、种子笔记、负样本笔记、
计算向量B加和a的余弦相似度,这个数值表示种子笔记和正样本的内容相似度,越大越好,
再计算B减和a这两个向量的运行相似度,这个数值表示种子笔记和负样本之间的相似度,数值越小越好。
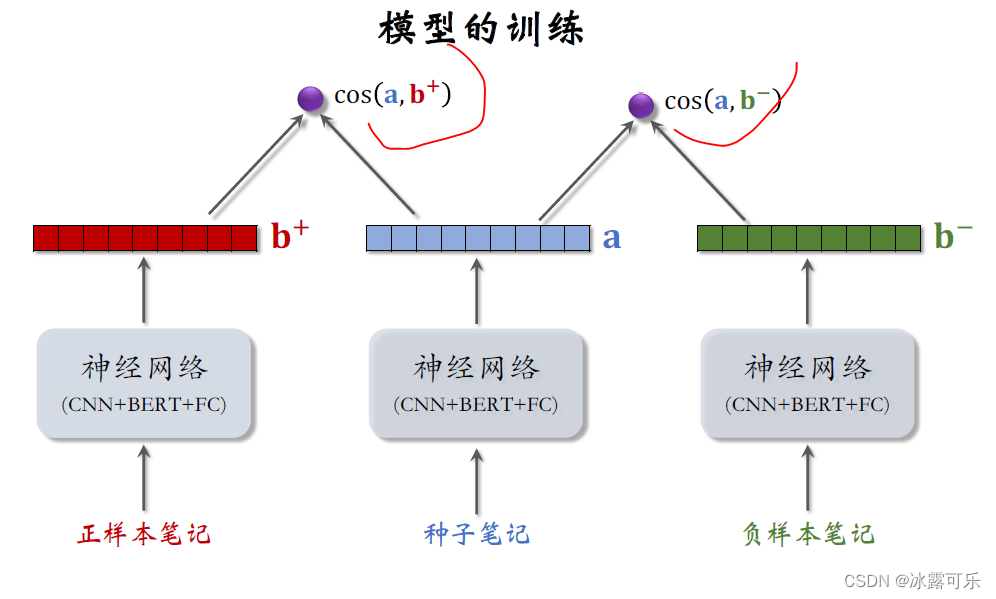
做训练的目标是这样的,
让种子笔记跟正样本的相似度尽量大,
让种子笔记跟负样本的相似度尽量小,
也就是让这两个运行相似度的差尽量大,这是triplelet hinge loss。

在双塔模型的文章里面我讲过最小化triple hinge loss会鼓励种子和正样本的相似度尽量大,
和种子的负样本的相似度尽量小,下面是triple logistic loss,作用跟triple hinge loss是一样的,
我们可以通过最小化这个损失函数来学习神经网络参数。刚才说了,每一条训练数据都是一个三元组,包含一个种子样本,一个正样本,一个负样本。
下面讲解正负样本的选取,
先看正样本。正样本就是相似度高的笔记,最直接的方法就是人工标注二元组的相似度,
这样就得到了正样本,但是人工标注的代价太大,不划算,
也可以用算法自动选取正样本,代价比较小。

设置这样的筛选条件,一个是只用高曝光的笔记作为二元组,
因为高曝光的笔记有充足的用户交互信息,算法选的正样本会比较准。

另一个条件是两篇笔记有相同的二级类目,比如都是菜谱教程。
做这样一道筛选,可以过滤掉完全不相似的笔记,
最后用item cf的物品相似度选择正样本。前面讲过item cf,它是靠用户和笔记的交互记录判断笔记的相似度,
有越多的用户同时对两篇笔记感兴趣,就说明两篇笔记越相似,负样本的选择很容易,直接从全体笔记中选出一篇笔记。

满足下面两个条件就行,一个条件是次数比较多,这样的话神经网络提取的文本信息比较有效。
另一个条件是笔记质量高,避免图文无关的劣质笔记。总结一下,这节讲的聚类召回
聚类召回的基本思想是根据用户的点赞、收藏、转发、记录推荐内容相似的笔记,
想做聚类召回,需要线下训练一个多模态神经网络,它可以把图文内容映射到向量,
通过比较向量的cos相似度就知道哪两个向量最相似。在线上服务的时候,我们根据用户历史上喜欢的笔记召回相似的新笔记。
首先把用户历史上喜欢的笔记输入给神经网络,计算出一个特征向量,
然后把特征向量跟1000个cluster中心向量做比较,找到最相似的中心向量。选择这个cluster,每个cluster都有一个笔记列表。
按照时间顺序倒打来,选择列表上前几篇笔记,也就是最新的几篇作为召回结果,这节就讲到这里,下节课介绍look like召回。
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:基本思想是根据用户的点赞、收藏、转发、记录推荐内容相似的笔记 -
相关阅读:
【计算机视觉 | CNN】Image Model Blocks的常见算法介绍合集(二)
[Linux]记录plasma-wayland下无法找到HDMI接口显示器的问题解决方案
3. Longest Substring Without Repeating Characters (python)
人工神经网络与神经网络,人工神经网络控制系统
C++ 学习之旅(2.5)——变量与函数
【Python学习】--跳过pip安装错误继续执行
2024年华为OD机试真题- 项目排期-Python-OD统一考试(C卷)
Webpack 5 超详细解读(二)
SpringBoot中有几种定义Bean的方式?
arcgis添加天地图山东wtms服务
- 原文地址:https://blog.csdn.net/weixin_46838716/article/details/126494231