-
宽表为什么横行?
宽表在 BI 业务中比比皆是,每次建设 BI 系统时首先要做的就是准备宽表。有时系统中的宽表可能会有上千个字段,经常因为 “过宽” 超过了数据库表字段数量限制还要再拆分。
为什么大家乐此不疲地造宽表呢?主要原因有两个。
一是为了提高查询性能。现代 BI 通常使用关系数据库作为后台,而 SQL 通常使用的 HASH JOIN 算法,在关联表数量和关联层级变多的时候,计算性能会急剧下降,有七八个表三四层级关联时就能观察到这个现象,而 BI 业务中的关联复杂度远远超过这个规模,直接使用 SQL 的 JOIN 就无法达到前端立等可取的查询需要了。为了避免关联带来的性能问题,就要先将关联消除,即将多表事先关联好采用单表存储(也就是宽表),再查询的时候就可以不用再关联,从而达到提升查询性能的目的。
二是为了降低业务难度。因为多表关联尤其是复杂关联在 BI 前端很难表达和使用。如果采用自动关联(根据字段类型等信息匹配)当遇到同维字段(如一个表有 2 个以上地区字段)时会 “晕掉” 不知道该关联哪个,表间循环关联或自关联的情况也无法处理;如果将众多表开放给用户来自行选择关联,由于业务用户无法理解表间关系而几乎没有可用性;分步关联可以描述复杂的关联需求,但一旦前一步出错就要推倒重来。所以,无论采用何种方式,工程实现和用户使用都很麻烦。但是基于单表来做就会简单很多,业务用户使用时没有什么障碍,因此将多表组织成宽表就成了 “自然而然” 的事情。
不过,凡事都有两面性,我们看到宽表好处而大量应用的同时,其缺点也不容忽视,有些缺点会对应用产生极大影响。下面来看一下。
宽表的缺点
数据冗余容量大
宽表不符合范式要求,将多个表合并成一个表会存在大量冗余数据,冗余程度跟原表数据量和表间关系有关,通常如果存在多层外键表,其冗余程度会呈指数级上升。大量数据冗余不仅会带来存储上的压力(多个表组合出来的宽表数量可能非常多)造成数据库容量问题,在查询计算时由于大量冗余数据参与运算还会影响计算性能,导致虽然用了宽表但仍然查询很慢。
数据错误
由于宽表不符合三范式要求,数据存储时可能出现一致性错误(脏写)。比如同一个销售员在不同记录中可能存储了不同的性别,同一个供应商在不同记录中的所在地可能出现矛盾。基于这样的数据做分析结果显然不对,而这种错误非常隐蔽很难被发现。
另外,如果构建的宽表不合理还会出现汇总错误。比如基于一对多的 A 表和 B 表构建宽表,如果 A 中有计算指标(如金额),在宽表中就会重复,基于重复的指标再汇总就会出现错误。
灵活性差
宽表本质上是一种按需建模的手段,根据业务需求来构建宽表(虽然理论上可以把所有表的组合都形成宽表,但这只存在于理论上,如果要实际操作会发现需要的存储空间大到完全无法接受的程度),这就出现了一个矛盾:BI 系统建设的初衷主要是为了满足业务灵活查询的需要,即事先并不知道业务需求,有些查询是在业务开展过程中逐渐催生出来的,有些是业务用户临时起意的查询,这种灵活多变的需求采用宽表这种要事先加工的解决办法极为矛盾,想要获得宽表的好就得牺牲灵活性,可谓鱼与熊掌不可兼得。
可用性问题
除了以上问题,宽表由于字段过多还会引起可用性低的问题。一个事实表会对应多个维表,维表又有维表,而且表之间还可能存在自关联/循环关联的情况,这种结构在数据库系统中很常见,基于这些结构的表构建宽表,尤其要表达多个层级的时候,宽表字段数量会急剧增加,经常可能达到成百上千个(有的数据库表有字段数量限制,这时又要横向分表),试想一下,在用户接入界面如果出现上千个字段要怎么用?这就是宽表带来的可用性差的问题。
总体来看,宽表的坏处在很多场景中经常要大于好处,那为什么宽表还大量横行呢?
因为没办法。一直没有比宽表更好的方案来解决前面提到的查询性能和业务难度的问题。其实只要解决这两个问题,宽表就可以不用,由宽表产生的各类问题也就解决了。
SPL+DQL 消灭宽表
借助开源集算器 SPL 可以完成这个目标。
SPL(Structured Process Language)是一个开源结构化数据计算引擎,本身提供了不依赖数据库的强大计算能力,SPL 内置了很多高性能算法,尤其是对关联运算做了优化,对不同的关联场景采用不同的手段,可以大幅提升关联性能,从而不用宽表也能实时关联以满足多维分析时效性的需要。同时,SPL 还提供了高性能存储,配合高效算法可以进一步发挥性能优势。
只有高性能还不够,SPL 原生的计算语法不适合多维分析应用接入(生成 SPL 语句对 BI 系统改造较大)。目前大部分多维分析前端都是基于 SQL 开发的,但 SQL 体系(不用宽表时)在描述复杂关联计算上又很困难,基于这样的原因,SPL 设计了专门的类 SQL 查询语法 DQL(Dimensional Query Language)用于构建语义层。前端生成 DQL 语句,DQL Server 将其转换成 SPL 语句,再基于 SPL 计算引擎和存储引擎完成查询返回给前端,实现全链路 BI 查询。需要注意的是,SPL 只作为计算引擎存在,前端界面仍要由用户自行实现(或选用相应产品)。

SPL:关联实现技术
SPL 如何不用宽表也能实现实时关联以满足性能要求的目标?
在 BI 业务中绝大部分的 JOIN 都是等值 JOIN,也就是关联条件为等式的 JOIN。SPL 把等值关联分为外键关联和主键关联。外键关联是指用一个表的非主键字段,去关联另一个表的主键,前者称为事实表,后者称为维表,两个表是多对一的关系,比如订单表和客户表。主键关联是指用一个表的主键关联另一个表的主键或部分主键,比如客户表和 VIP 客户表(一对一)、订单表和订单明细表(一对多)。
这两类 JOIN 都涉及到主键,如果充分利用这个特征采用不同的算法,就可以实现高性能的实时关联了。
不过很遗憾,SQL 对 JOIN 的定义并不涉及主键,只是两个表做笛卡尔积后再按某种条件过滤。这个定义很简单也很宽泛,几乎可以描述一切。但是,如果严格按这个定义去实现 JOIN,理论上没办法在计算时利用主键的特征来提高性能,只能是工程上做些有限的优化,在情况较复杂时(表多且层次多)经常无效。
SPL 改变了 JOIN 的定义,针对这两类 JOIN 分别处理,就可以利用主键的特征来减少运算量,从而提高计算性能。
外键关联
和 SQL 不同,SPL 中明确地区分了维表和事实表。BI 系统中的维表都通常不大,可以事先读入内存建立索引,这样在关联时可以少计算一半的 HASH 值。
对于多层维表(维表还有维表的情况)还可以用外键地址化的技术做好预关联。即将维表(本表)的外键字段值转换成对应维表(外键表)记录的地址。这样被关联的维表数据可以直接用地址取出而不必再进行 HASH 值计算和比对,多层维表仅仅是多个按地址取值的时间,和单层维表时的关联性能基本相当。
类似的,如果事实表也不大可以全部读入内存时,也可以通过预关联的方式解决事实表与维表的关联问题,提升关联效率。
预关联可以在系统启动时一次性读入并做好,以后直接使用即可。
当事实表较大无法全内存时,SPL 提供了外键序号化方法:将事实表中的外键字段值转换为维表对应记录的序号。关联计算时,用序号取出对应维表记录,这样可以获得和外键地址化类似的效果,同样能避免 HASH 值的计算和比对,大幅提升关联性能。
主键关联
有的事实表还有明细表,比如订单和订单明细,二者通过主键和部分主键进行关联,前者作为主表后者作为子表(还有通过全部主键关联的称为同维表,可以看做主子表的特例)。主子表都是事实表,涉及的数据量都比较大。
SPL 为此采用了有序归并方法:预先将外存表按照主键有序存储,关联时顺序取出数据做归并,不需要产生临时缓存,只用很小的内存就可以完成计算。而 SQL 采用的 HASH 分堆算法复杂度较高,不仅要计算 HASH 值进行对比,还会产生临时缓存的读写动作,运算性能很差。
HASH 分堆技术实现并行困难,多线程要同时向某个分堆缓存数据,造成共享资源冲突;某个分堆关联时又会消费大量内存,无法实施较大的并行数量。而有序归则易于分段并行。数据有序时,子表就可以根据主表键值进行同步对齐分段以保证正确性,无需缓存,且因为占用内存很少可以采用较大的并行数,从而获得更高性能。
预先排序的成本虽高,但是一次性做好即可,以后就总能使用归并算法实现 JOIN,性能可以提高很多。同时,SPL 也提供了在有追加数据时仍然保持数据整体有序的方案。
对于主子表关联 SPL 还可以采用更有效的存储形式将主子表一体化存储,子表作为主表的集合字段,其取值是由与该主表数据相关的多条子表记录构成。这相当于预先实现了关联,再计算时直接取数计算即可,不需要比对,存储量也更少,性能更高。
存储机制
高性能离不开有效的存储。SPL 也提供了列式存储,在 BI 计算中可以大幅降低数据读取量以提升读取效率。SPL 列存采用了独有的倍增分段技术,相对传统列存分块并行方案要在很大数据量时(否则并行会受到限制)才会发挥优势不同,这个技术可以使 SPL 列存在数据量不很大时也能获得良好的并行分段效果,充分发挥并行优势。
SPL 还提供了针对数据类型的优化机制,可以显著提升多维分析中的切片运算性能。比如将枚举型维度转换成整数,在查询时将切片条件转换成布尔值构成的对位序列,在比较时就可以直接从序列指定位置取出切片判断结果。还有将多个标签维度(取值是或否的维度,这种维度在多维分析中大量存在)存储在一个整数字段中的标签位维度技术(一个整数字段可以存储 16 个标签),不仅大幅减少存储量,在计算时还可以针对多个标签同时做按位计算从而大幅提升计算性能。
有了这些高效机制以后,我们就可以在 BI 分析中不再使用宽表,转而基于 SPL 存储和算法做实时关联,性能比宽表还更高(没有冗余数据读取量更小,更快)。
不过,只有这些还不够,SPL 原生语法还不适合BI前端直接访问,这就需要适合的语义转换技术,通过适合的方式将用户操作转换成 SPL 语法进行查询。
这就需要DQL了。
DQL:关联描述技术
DQL 是 SPL 之上的语义层构建工具,在这一层完成对于 SPL 数据关联关系的描述(建模)再为上层应用服务。即将 SPL 存储映射成 DQL 表,再基于表来描述数据关联关系。
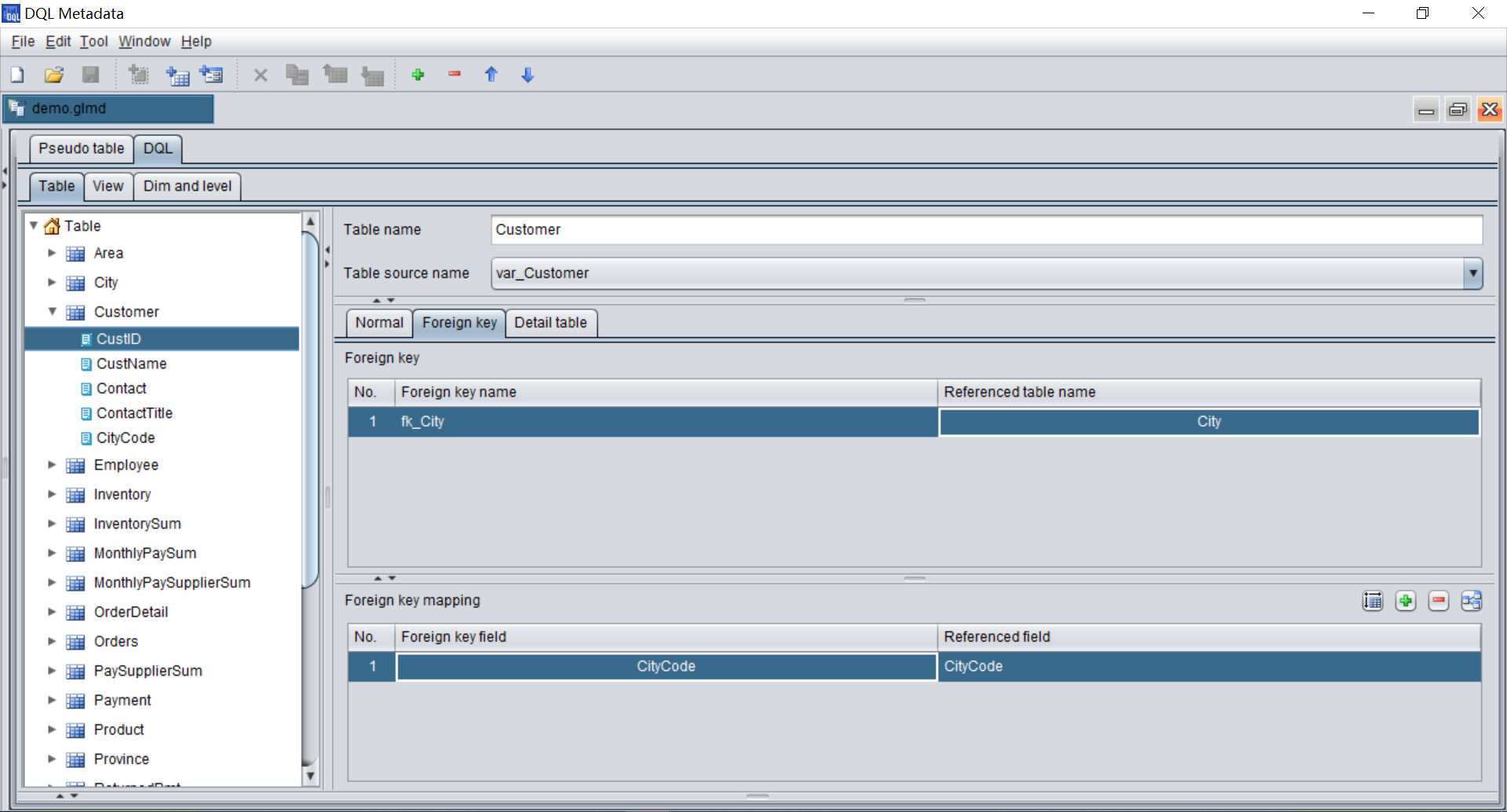
通过对数据表关系描述以后形成了一种以维度为中心的总线式结构(不同于 E-R 图中的网状结构),中间是维度,表与表之间不直接相关都通过维度过渡。

基于这种结构下的关联查询(DQL语句)会很好表达。比如要根据订单表(orders)、客户表(customer)、销售员表(employee)以及城市表(city)查询:本年度华东的销售人员,在全国各销售区的销售额。
用 SQL 写起来是这样的:
SELECT ct1.area,o.emp_id,sum(o.amount) somt FROM orders o JOIN customer c ON o.cus_id = c.cus_id JOIN city ct1 ON c.city_id = ct1.city_id JOIN employee e ON o.emp_id = e.emp_id JOIN city ct2 ON e.city_id = ct2.city_id WHERE ct2.area = 'east' AND year(o.order_date)= 2022 GROUP BY ct1.area, o.emp_id- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
多个表关联要 JOIN 多次,同一个地区表要反复关联两次才能查到销售员和客户的所在区域,对于这种情况 BI 前端表达起来会很吃力,如果将关联开放出来,用户又很难理解。
那么 DQL 是怎么处理的呢?
DQL 写法:
SELECT cus_id.city_id.area,emp_id,sum(amount) somt FROM orders WHERE emp_id.city_id.area == "east" AND year(order_date)== 2022 BY cus_id.city_id.area,emp_id- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
DQL 不需要 JOIN 多个表,只基于 orders 单表查询就可以了,外键指向表的字段当成属性直接使用,有多少层都可以引用下去,很好表达。像查询客户所在地区通过 cus_id.city_id.area 一直写下去就可以了,这样就消除了关联,将多表关联查询转化成单表查询。
更进一步,我们再基于 DQL 开发 BI 前端界面就很容易,比如可以做成这样:

用树结构分多级表达多层维表关联,这样的多维分析页面不仅容易开发,普通业务用户使用时也很容易理解,这就是 DQL 的效力。
总结一下,宽表的目的是为了解决 BI 查询性能和前端工程实现问题,而宽表会带来数据冗余和灵活性差等问题。通过 SPL 的实时关联技术与高效存储可以解决性能问题,而且性能比宽表更高,同时不存在数据冗余,存储空间也更小(压缩);DQL 构建的语义层解决了多维分析前端工程的实现问题,让实时关联成为可能,,灵活性更高(不再局限于宽表的按需建模),界面也更容易实现,应用范围更广。
SPL+DQL 继承(超越)宽表的优点同时改善其缺点,这才是 BI 该有的样子。
SPL 资料
-
相关阅读:
OpenGL进阶(二)之像素缓冲PixelBuffer
Three.js之绘制中文文字并跟随物体
MFC -- Date Time Picker 控件使用
鸿蒙Harmony应用开发—ArkTS声明式开发(通用属性:外描边设置)
十二,HDR环境贴图卷积
花好月圆│以代码寄相思,绘嫦娥之奔月
什么是ArchiMate?有优缺点和运用场景?
风力等级划分
3线硬件SPI+DMA驱动 HX8347 TFT屏-快速显示文字
信息系统项目管理师-进度管理论文提纲
- 原文地址:https://blog.csdn.net/weixin_53072519/article/details/127923785