-
面向OLAP的列式存储DBMS-10-[ClickHouse]的常用数组操作
参考ClickHouse 中的数据查询以及各种子句
ClickHouse 数组的相关操作函数,一网打尽在关系型数据库里面我们一般都不太喜欢用数组,但是在 ClickHouse 中数组会用的非常多,并且操作起来非常简单。ClickHouse 里面提供了非常多的函数,用好了的话,就相当于分布式的 pandas。

下面就先来看一下关于数组的一些函数,这里先介绍一部分,提前感受一下ClickHouse的强大。
docker start docker-clickhouse- 1
1 创建测试表
首先我们创建一张新表,并写入测试数据:
CREATE TABLE t2 ( dt Date, cash Array(UInt8) ) ENGINE = Memory(); -- 然后写入数据 INSERT INTO t2 VALUES ('2020-01-01', [10,10,10]), ('2020-01-02', [20,20,20]), ('2020-01-01', [10,10,10]), ('2020-01-02', [20,20]), ('2020-01-03', []), ('2020-01-03', [30,30,30]); -- 查询 SELECT * FROM t2; dt |cash | ----------+----------+ 2020-01-01|[10,10,10]| 2020-01-02|[20,20,20]| 2020-01-01|[10,10,10]| 2020-01-02|[20,20] | 2020-01-03|[] | 2020-01-03|[30,30,30]|- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2 常用数组操作
2.1 groupArray和groupUniqArray
这个函数已经出现过一次了,我们说它是把多行数据合并成一个数组,相当于是聚合函数的一种。
select dt,groupArray(cash) from t2 group by dt; dt |groupArray(cash) | ----------+-----------------------+ 2020-01-01|[[10,10,10],[10,10,10]]| 2020-01-02|[[20,20,20],[20,20]] | 2020-01-03|[[],[30,30,30]] |- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们看到 groupArray 就等同于类似 count、sum 这样的聚合函数,将同一组的数据组合成一个新的数组。由于本来的元素就是数组,所以这里就是数组嵌套数组。
除了groupArray之外,还有一个groupUniqArray,在组合的时候会对元素进行去重:
select dt,groupUniqArray(cash) from t2 group by dt; 我们看到 '2020-01-01' 这行数据被去重了。 dt |groupUniqArray(cash)| ----------+--------------------+ 2020-01-01|[[10,10,10]] | 2020-01-02|[[20,20],[20,20,20]]| 2020-01-03|[[],[30,30,30]] |- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2 arrayFlatten
SELECT dt, groupArray(cash), arrayFlatten(groupArray(cash)) FROM t2 GROUP BY dt; dt |groupArray(cash) |arrayFlatten(groupArray(cash))| ----------+-----------------------+------------------------------+ 2020-01-01|[[10,10,10],[10,10,10]]|[10,10,10,10,10,10] | 2020-01-02|[[20,20,20],[20,20]] |[20,20,20,20,20] | 2020-01-03|[[],[30,30,30]] |[30,30,30] |- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
相信该函数的作用显而易见的,就是将多个嵌套数组扁平化,另外这里的查询语句还可以美化一下:
-- 使用 WITH 子句,提前将 groupArray(cash) 起一个别名 WITH groupArray(cash) AS group_cash SELECT dt, group_cash, arrayFlatten(group_cash) FROM t2 GROUP BY dt; -- 或者这么做 SELECT dt, groupArray(cash) AS group_cash, arrayFlatten(group_cash) FROM t2 GROUP BY dt; -- 我们看到即使是在 SELECT 里面起的别名也是可以被使用的 -- 另外顺序也没有限制,比如下面的做法也是合法的 SELECT dt, arrayFlatten(group_cash), groupArray(cash) AS group_cash FROM t2 GROUP BY dt;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2.3 splitByChar
将字符串按照指定字符分割成数组。
SELECT splitByChar('^', 'komeiji^koishi'); splitByChar('^', 'komeiji^koishi')| ----------------------------------+ ['komeiji','koishi'] |- 1
- 2
- 3
- 4
- 5
2.4 arrayJoin
该函数和 ARRAY JOIN 子句的作用非常类似:
select * from t1; title|value | -----+-------+ food |[1,2,3]| fruit|[3,4] | meat |[] | select title,arrayJoin(value) from t1; title|arrayJoin(value)| -----+----------------+ food | 1| food | 2| food | 3| fruit| 3| fruit| 4|- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.5 arrayMap
对数组中的每一个元素都以相同的规则进行映射:
-- arrayMap(x -> x * 2, value)表示将value中的每一个元素都乘以2,然后返回一个新数组 -- 而mapV 就是变换过后的新数组,直接拿来用即可 SELECT title, arrayMap(x -> x * 2, value) AS mapV, v FROM t1 LEFT ARRAY JOIN mapV as v title|mapV |v| -----+-------+-+ food |[2,4,6]|2| food |[2,4,6]|4| food |[2,4,6]|6| fruit|[6,8] |6| fruit|[6,8] |8| meat |[] |0| -- 另外展开的字段也可以不止一个 SELECT title, arrayMap(x -> x * 2, value) AS mapV, v, value, v_1 FROM t1 LEFT ARRAY JOIN mapV as v, value AS v_1 title|mapV |v|value |v_1| -----+-------+-+-------+---+ food |[2,4,6]|2|[1,2,3]| 1| food |[2,4,6]|4|[1,2,3]| 2| food |[2,4,6]|6|[1,2,3]| 3| fruit|[6,8] |6|[3,4] | 3| fruit|[6,8] |8|[3,4] | 4| meat |[] |0|[] | 0|- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
3 数组的相关操作函数
在一般的关系型数据库,相信很多人都不怎么使用数组这个结构,如果真的需要数组,那么会选择将其变成数组格式的字符串进行存储。但在ClickHouse中,数组的使用频率是非常高的,因为它内置了大量和数组有关的函数。
SELECT VERSION() ; 输出22.1.3.7 SELECT COUNT() FROM system.functions WHERE name LIKE '%array%'; 输出50,如下所示: arrayEnumerateUniqRanked | arrayJoin | arrayFilter | arrayDifference | arrayCumSumNonNegative | arrayCumSum | arraySort | arrayReverseSplit | arrayReverseFill | arrayFill | arrayLastIndex | arrayFirst | arrayProduct | arrayAvg | arrayMax | arrayMin | arrayAll | arrayExists | arrayMap | arrayZip | arraySlice | arrayAUC | arrayStringConcat | arrayElement | arrayCount | arrayLast | arrayDistinct | array | arrayReverseSort | arrayEnumerateDenseRanked| arraySplit | arrayCompact | arrayIntersect | arrayPushFront | arrayConcat | arrayWithConstant | arrayFlatten | arrayPopFront | arrayFirstIndex | arrayUniq | arrayEnumerateUniq | arrayEnumerateDense | arrayResize | arrayReduceInRanges | arrayReduce | arrayPopBack | arrayPushBack | arraySum | arrayReverse | arrayEnumerate |- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
当前的 ClickHouse 是 22.1.3.7版本,关于数组的函数有50个,通过这个50个函数,我们可以对数组进行各种骚操作。当然也有一些函数不是专门针对数组的,但是可以用在数组身上,我们就也放在一起说了,下面就来依次介绍相关函数的用法。
3.1 检测数组或字符串是否为空empty
--检测数组是否为空 SELECT empty([1,2]),empty([]); SELECT notEmpty([1,2]),notEmpty([]); --检测字符串是否为空 SELECT empty('test'),empty(''); SELECT notEmpty('test'),notEmpty(''); --返回字符串或数组长度 SELECT LENGTH([]),LENGTH([1,2]),LENGTH('test'),LENGTH('');- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.2 创建指定类型的空数组array
emptyArrayUInt8、emptyArrayUInt16、 emptyArrayUInt32、emptyArrayUInt64、 emptyArrayInt8、emptyArrayInt16、 emptyArrayInt32、emptyArrayInt64、 emptyArrayFloat32、emptyArrayFloat64、 emptyArrayDate、emptyArrayDateTime、emptyArrayString -- 数组元素的类型为 nothing,因为没有指定任何元素 SELECT [] v, toTypeName(v); /* ┌─v──┬─toTypeName(array())─┐ │ [] │ Array(Nothing) │ └────┴─────────────────────┘ */ -- 采用最小类型存储,因为 1 和 2 都在 UInt8 的范围内 SELECT [1, 2] v, toTypeName(v); /* ┌─v─────┬─toTypeName([1, 2])─┐ │ [1,2] │ Array(UInt8) │ └───────┴────────────────────┘ */ -- 但是我们可以创建指定类型的数组 SELECT emptyArrayDateTime() v, toTypeName(v); /* ┌─v──┬─toTypeName(emptyArrayDateTime())─┐ │ [] │ Array(DateTime) │ └────┴──────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
array:也是创建一个数组,和直接使用方括号类似。但是 array 函数要求必须至少传递一个常量,否则就不知道要创建哪种类型的数组。如果想创建指定类型的空数组,那么使用上面的emptyArray* 系列函数即可
不管是使用array创建,还是使用[]创建,里面的元素都必须具有相同的类型,或者能够兼容。SELECT array(1,2),[1,2]; -----------+------+ [1,2] |[1,2] |- 1
- 2
- 3
3.3 range
SELECT range(5); -----------+ [0,1,2,3,4]| SELECT range(3,6); -----------+ [3,4,5] | SELECT range(1,6,2); --------------+ [1,3,5] |- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.4 合并数组arrayConat
arrayConat:将多个数组进行合并,得到一个新的数组
-- SELECT 中起的别名可以被直接其它字段所使用 SELECT [1, 2] v1, [11] v2, [111, 222] v3, arrayConcat(v1, v2, v3); /* v1 |v2 |v3 |arrayConcat([1, 2], [11], [111, 222])| -----+----+---------+-------------------------------------+ [1,2]|[11]|[111,222]|[1,2,11,111,222] | */- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.5 查找指定索引的元素arrayElement
arrayElement:查找指定索引的元素,索引从1开始,也可以通过方括号直接取值;另外也支持负数索引,-1代表最后一个元素。
-- 索引从1开始,所以arr[1] 就表示第1个元素,也就是 32 with [32,24] as arr select arrayElement(arr,1),arr[2],arr[-1]; /* arrayElement(arr, 1)|arrayElement(arr, 2)|arrayElement(arr, -1)| --------------------+--------------------+---------------------+ 32| 24| 24| */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.6 判断数组里面是否包含某个元素has
has:判断数组里面是否包含某个元素,如果包含,返回 1;不包含,返回0
WITH [1, 2, Null] AS arr SELECT has(arr, 2), has(arr, 0), has(arr, Null); /* ┌─has(arr, 2)─┬─has(arr, 0)─┬─has(arr, NULL)─┐ │ 1 │ 0 │ 1 │ └─────────────┴─────────────┴────────────────┘ */ -- 嵌套数组也是可以的 with [[1, 2]] as arr SELECT has(arr, [1, 2]),has(arr,[1]); /* has(arr, [1, 2])|has(arr, [1])| ----------------+-------------+ 1| 0| */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.7 判断数组里面是否包含某个子数组hasAll
hasAll:判断数组里面是否包含某个子数组,如果包含,返回1;不包含,返回0。
注意:空数组是任意数组的子集;
注意:Null 会被看成是普通的值;
注意:数组中的元素顺序没有要求;
注意:1.0 和 1 被视为相等。hasAll([], []):返回1。 hasAll([1, Null], [Null]):返回1。 hasAll([1.0, 2.0, 3.0], [2.0, 3.0, 1.0]):返回1,因为元素顺序无影响,并且 1.0和1被视为相等 hasAll(['a', 'b'], ['a']):返回 1 hasAll(['a', 'b'], ['c']):返回 0 hasAll([[1, 2], [3, 4]], [[1, 2], [3, 4]]):返回 1,嵌套数组也是可以的 在 has 函数里面也有嵌套数组,但是维度不同。比如 has(a, b):如果 a 是维度为 N 的数组,那么 b 必须是维度为 N - 1 的数组;而 hasAll 则要求 a 和 b 的维度必须相同。 WITH [[1, 2], [11, 22]] AS arr, [[1, 2], [11, 22]] AS subset SELECT hasAll(arr, subset) /* ┌─hasAll(arr, subset)─┐ │ 1 │ └─────────────────────┘ */ -- 我们说 SELECT 里面别名可以给其它字段使用,因此下面这种做法也是合法的 WITH [[1, 2], [11, 22]] AS arr, arr AS subset SELECT hasAll(arr, subset) /* ┌─hasAll(arr, subset)─┐ │ 1 │ └─────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.8 判断两个数组里面是否有相同的元素hasAny
hasAny:判断两个数组里面是否有相同的元素,只要有1个相同的元素,返回 1;否则,返回0。
SELECT hasAny([1.0, 2.0], [1]), hasAny([Null], [1, Null]) /* ┌─hasAny([1., 2.], [1])─┬─hasAny([NULL], [1, NULL])─┐ │ 1 │ 1 │ └───────────────────────┴───────────────────────────┘ */ SELECT hasAny([[1, 2], [3, 4]], [[3, 4]]) /* ┌─hasAny([[1, 2], [3, 4]], [[3, 4]])─┐ │ 1 │ └────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.9 hasSubstr
hasSubstr:和 hasAll 类似,但是顺序有要求,hasAll(arr, subset) 要求的是 subset 中的元素在 arr 中都出现即可;但是 hasSubstr 函数则不仅要求 subset 中的元素在 arr 中都出现,并且还要以相同的顺序。举个栗子: hasSubstr([1, 2, 3], [2, 3]):返回 1 hasSubstr([1, 2, 3], [3, 2]):返回 0 hasSubstr([[1, 2], [2, 1], [3, 2]], [[3, 2]]):返回 1 -- 两个数组的维度必须相同 SELECT hasSubstr([1, 2, 3], [3, 2]), hasSubstr([1, 2, 3], [2, 3]); /* ┌─hasSubstr([1, 2, 3], [3, 2])─┬─hasSubstr([1, 2, 3], [2, 3])─┐ │ 0 │ 1 │ └──────────────────────────────┴──────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.10 indexOf
indexOf:查找某个元素第一次在数组中出现的位置,索引从 1 开始;如果不存在,则返回 0 WITH [1, 2, 3, Null, 99] AS arr SELECT indexOf(arr, 100), indexOf(arr, 99), indexOf(arr, Null); /* ┌─indexOf(arr, 100)─┬─indexOf(arr, 99)─┬─indexOf(arr, NULL)─┐ │ 0 │ 5 │ 4 │ └───────────────────┴──────────────────┴────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.11 arrayCount
arrayCount:查找一个数组中非 0 元素的个数,该数组类的元素类型必须是 UInt8,并且不能包含 Null 值。因为一旦包含 Null,那么类型就不是 UInt8 了,而是 Nullable(UInt8)
SELECT arrayCount([1, 2, 3]), arrayCount([1, 2, 3, 4, 0]); /* ┌─arrayCount([1, 2, 3])─┬─arrayCount([1, 2, 3, 4, 0])─┐ │ 3 │ 4 │ └───────────────────────┴─────────────────────────────┘ */ 此外 arrayCount 还有一种用法,就是接收一个函数和一个数组: WITH [1, 2, 3, 4, 0] AS arr SELECT arrayCount(arr), arrayCount(x -> cast(x + 1 AS UInt8), arr) /* ┌─arrayCount(arr)─┬─arrayCount(lambda(tuple(x), CAST(plus(x, 1), 'UInt8')), arr)─┐ │ 4 │ 5 │ └─────────────────┴──────────────────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
ClickHouse 中的函数类似于 C++ 中的 lambda 表达式,x -> x + 1 相当于将 arr 中的每一个元素都加上 1,但结果得到整型是 UInt16,所以需要使用 cast 转成 UInt8,否则报错。另外,加上 1 之后就没有为 0 的元素了,所以返回的结果是 5。
3.12 countEqual返回某元素在数组中出现的次数
with [1,1,1,2,Null,Null] as arr select countEqual(arr,1),countEqual(arr,Null); /* countEqual(arr, 1)|countEqual(arr, NULL)| ------------------+---------------------+ 3| 2| */- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.13 arrayEnumerate
arrayEnumerate:等价于先计算出数组的长度,假设为 N,然后返回 range(1, N + 1)
with range(1,5) as arr1, [2,2,2,2] as arr2 select arr1,arrayEnumerate(arr2); /* arr1 |arrayEnumerate(arr2)| ---------+--------------------+ [1,2,3,4]|[1,2,3,4] | */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.14 arrayEnumerateUniq
arrayEnumerateUniq:从数组的第一个元素开始,每重复一次就加 1。
with ['a', 'a', 'c', 'b', 'c', 'a', 'b', 'b'] as arr SELECT arrayEnumerateUniq(arr); /* arrayEnumerateUniq(arr)| -----------------------+ [1,2,1,1,2,3,2,3] | */- 1
- 2
- 3
- 4
- 5
- 6
- 7
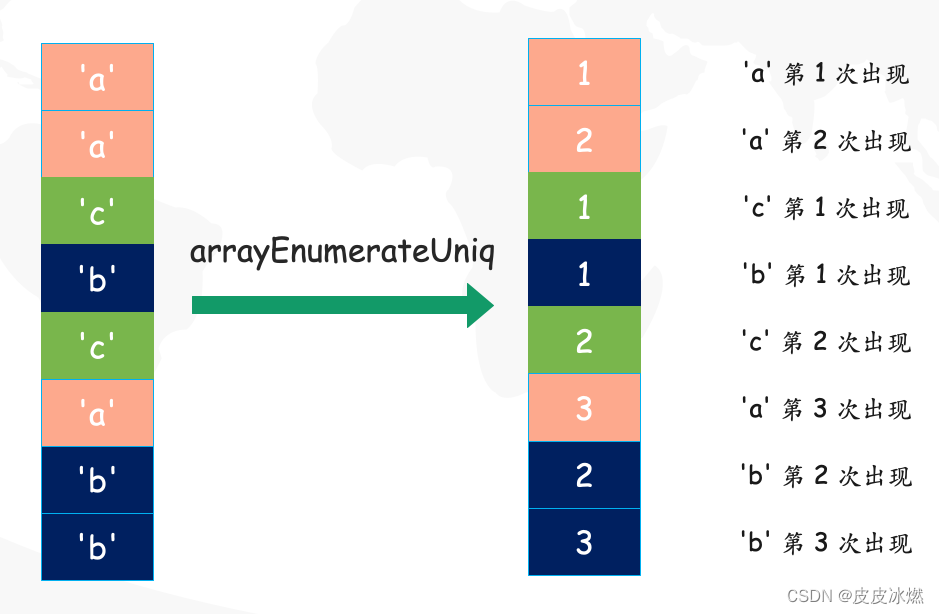
arrayEnumerateUniq 还可以接收多个数组,这些数据具有相同的长度。
此时会将多个数组作为一个整体来进行判断,因此这些数组都必须有相同的长度。SELECT arrayEnumerateUniq(['a','a','b','a'], [1,1,5,1]); 等价于 select arrayEnumerateUniq([('a',1), ('a',1), ('b',5), ('a',1)]); /* arrayEnumerateUniq(['a', 'a', 'b', 'a'], [1, 1, 5, 1])| ------------------------------------------------------+ [1,2,1,3] | */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.15 arrayPopBack移除数组中的最后一个元素
显然它是可以被嵌套的:
注意:对空数组使用 arrayPopBack 不会报错,得到的还是空数组。with [1,2,3] as arr select arrayPopBack(arr),arrayPopBack(arrayPopBack(arr)); /* arrayPopBack(arr)|arrayPopBack(arrayPopBack(arr))| -----------------+-------------------------------+ [1,2] |[1] | */- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.16 arrayPopFront移除数组中的第一个元素
也可以被嵌套,并且对空数组使用也不会报错,还是得到空数组。
with [1,2,3] as arr select arrayPopFront(arr),arrayPopFront(arrayPopFront(arr)); /* arrayPopFront(arr)|arrayPopFront(arrayPopFront(arr))| ------------------+---------------------------------+ [2,3] |[3] | */- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.17 arrayPushBack从数组的尾部塞进一个元素
添加的时候记得类型要匹配,如果添加了 Null,那么数组会变成 Nullable。
select arrayPushBack([1,2],3); /* arrayPushBack([1, 2], 3)| ------------------------+ [1,2,3] | */- 1
- 2
- 3
- 4
- 5
- 6
3.18 arrayPushFront从数组的头部塞进一个元素
SELECT arrayPushFront(['a', 'b', 'c'], 'd'); /* ┌─arrayPushFront(['a', 'b', 'c'], 'd')─┐ │ ['d','a','b','c'] │ └──────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
添加的时候记得类型要匹配,如果添加了 Null,那么数组会变成 Nullable。
3.19 arrayResize改变数组的长度
如果指定的长度比原来的长度大,那么会用零值从尾部进行填充。
如果指定的长度比原来的长度小,那么会从尾部进行截断。SELECT arrayResize(range(4),7), arrayResize(range(4),2); /* ┌─arrayResize(range(4), 7)─┬─arrayResize(range(4), 2)─┐ │ [0,1,2,3,0,0,0] │ [0,1] │ └──────────────────────────┴──────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
在填充的时候,也可以使用指定的值进行填充:
注意Null会被补成0。SELECT arrayResize(range(4), 7, 66), arrayResize(range(4), 7, Null); /* arrayResize(range(4), 7, 66)|arrayResize(range(4), 7, NULL)| ----------------------------+------------------------------+ [0,1,2,3,66,66,66] |[0,1,2,3,0,0,0] | */- 1
- 2
- 3
- 4
- 5
- 6
3.20 arraySlice返回数组的一个片段
arraySlice(arr, M):返回从索引为 M 开始以及之后的所有元素。
arraySlice(arr, M, N):从索引为 M 的元素开始,总共返回 N 个元素。SELECT arraySlice(range(1,10),3), arraySlice(range(1,10),3,4); /* ┌─arraySlice(range(1, 10), 3)─┬─arraySlice(range(1, 10), 3, 4)─┐ │ [3,4,5,6,7,8,9] │ [3,4,5,6] │ └─────────────────────────────┴────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
3.21 arraySort对数据进行排序然后返回
SELECT arraySort([2,3,1]), arraySort(['abc','ab','c']); /* ┌─arraySort([2, 3, 1])─┬─arraySort(['abc', 'ab', 'c'])─┐ │ [1,2,3] │ ['ab','abc','c'] │ └──────────────────────┴───────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
字符串会按照字典序排序返回,整型、浮点型、日期都会按照大小返回。问题来了,如果我们希望按照字符串的长度排序该怎么办呢?所以 arraySort 还支持传递一个自定义函数:
-- 按照数组中元素的长度进行排序 SELECT arraySort(x -> length(x),['abc','ab','c']); /* ┌─arraySort(lambda(tuple(x), length(x)), ['abc', 'ab', 'c'])─┐ │ ['c','ab','abc'] │ └────────────────────────────────────────────────────────────┘ */ -- 按照正负号排序,小于0的排在大于0的左边 SELECT arraySort(x -> (x>0), [-3,1,3,-1,-2,2]); /* arraySort(lambda(tuple(x), greater(x, 0)), [-3, 1, 3, -1, -2, 2])| -----------------------------------------------------------------+ [-3,-1,-2,1,3,2] | */ -- 按照绝对值进行排序 SELECT arraySort(x -> (abs(x)), [-3,1,3,-1,-2,2]); /* arraySort(lambda(tuple(x), abs(x)), [-3, 1, 3, -1, -2, 2])| ----------------------------------------------------------+ [1,-1,-2,2,-3,3] | */ -- 先按照正负号排序,小于0的排在大于0的左边,然后各自再按照绝对值进行排序 SELECT arraySort(x -> (x > 0, abs(x)), [-3, 1, 2, -1, -2, 3]); /* ┌─arraySort(lambda(tuple(x), tuple(greater(x, 0), abs(x))), [-3, 1, 2, -1, -2, 3])─┐ │ [-1,-2,-3,1,2,3] │ └──────────────────────────────────────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
这 ClickHouse 也太强大了吧,这简直不像是在写 SQL 了,都有点像写 Python 代码了,所以 ClickHouse 这么火不是没有原因的。
另外当出现空值或 NaN 的话,它们的顺序如下:
-inf 普通数值 inf NaN Null- 1
所以 arraySort 如果接收一个参数,那么该参数必须是一个数组,然后 ClickHouse 按照默认的规则进行排序;如果接收两个参数,那么第一个参数是匿名函数,第二个参数是数组,此时 ClickHouse 会按照我们定义的函数来给数组排序;但其实 arraySort 还可以接收三个参数,第一个参数依旧是函数,然后第二个参数和第三个参数都是数组,此时会用数组给数组排序:
-- 因为有两个数组,所以匿名函数要有两个参数,x表示第一个数组、y表示第二个数组 -- 首先不管排序规则是什么,最终输出的都是第一个数组 -- x, y -> y 就表示按照第二个数组来给第一个数组进行排序输出 SELECT arraySort(x, y -> y, [1, 2, 3], [22, 11, 33]); /* ┌─arraySort(lambda(tuple(x, y), y), [1, 2, 3], [22, 11, 33])─┐ │ [2,1,3] │ └────────────────────────────────────────────────────────────┘ */ -- 同理 x, y -> x 返回的还是 [1, 2, 3]、 x, y -> -x 返回的是 [3, 2, 1] -- 只不过此时第二个数组就用不上了- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.22 arrayReverseSort对数据进行逆序排序然后返回
该函数你可以认为它是先按照 arraySort 排序,然后将结果再反过来,举个栗子:
SELECT arraySort(x -> -x, [1, 2, 3]) sort, arrayReverseSort(x -> -x, [1, 2, 3]) reverse_sort; /* ┌─sort────┬─reverse_sort─┐ │ [3,2,1] │ [1,2,3] │ └─────────┴──────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
指定了匿名函数,按照相反数进行排序,因为 -3 < -2 < -1,所示 arraySort 排序之后就是 [3, 2, 1],然后 arrayReverseSort 则是在其基础上直接返回,所以得到的还是 [1, 2, 3]。
至于其它用法和 arraySort 都是一样的,可以看做是在 arraySort 的基础上做了一次反转。不过有一点需要注意,那就是 Null 值和 NaN:
arraySort:-inf 普通数值 inf NaN Null arrayReverseSort:inf 普通数值 -inf NaN Null- 1
- 2
即使是 arrayReverseSort,NaN 和 Null 依然排在最后面。
3.23 arrayUniq返回数组中不同元素的数量
SELECT arrayUniq([1, 2, 3, 1, 4]); /* ┌─arrayUniq([1, 2, 3, 1, 4])─┐ │ 4 │ └────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
也可以传递多个长度相同的数组,会依次取出所有数组中相同位置的元素,然后拼成元组,并计算这些不重复的元组的数量,举个栗子:
-- 相当于判断 arrayUniq( [('a', 1, 3), ('a', 1, 3), ('b', 2, 3)] ) SELECT arrayUniq(['a', 'a', 'b'], [1, 1, 2], [3, 3, 3]); /* ┌─arrayUniq(['a', 'a', 'b'], [1, 1, 2], [3, 3, 3])─┐ │ 2 │ └──────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.24 arrayJoin将数组展开成多行
SELECT arrayJoin(range(1,3)); /* arrayJoin(range(1, 3))| ----------------------+ 1| 2| */ -- ||表示字符串拼接,当arrayJoin展开成多行的时候,会自动和其它字段组合 with range(1,3) as arr SELECT arrayJoin(arr) AS v, 'A00' || cast(v AS String); /* v|concat('A00', CAST(arrayJoin(arr), 'String'))| -+---------------------------------------------+ 1|A001 | 2|A002 | */ -- 如果出现了多个arrayJoin ,那么会做笛卡尔积: SELECT arrayJoin([1, 2]), arrayJoin([11, 22]); /* arrayJoin([1, 2])|arrayJoin([11, 22])| -----------------+-------------------+ 1| 11| 1| 22| 2| 11| 2| 22| */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
3.25 groupArray将多行数据合并成数组
提到了arrJoin,那么就必须提一下groupArray,这算是一个聚合函数,它和 arrayJoin作用相反,将多行数据合并成数组。
SELECT number FROM numbers(3); /* number| ------+ 0| 1| 2| */ SELECT groupArray(number) FROM numbers(3); /* groupArray(number)| ------------------+ [0,1,2] | */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.26 groupUniqArray将多行数据去重合并成数组
除了groupArray,还有一个groupUniqArray,从名字上看显然多了一个去重的功能。
-- SELECT arrayJoin([1, 1, 2, 2, 3]) 会自动展开成多行 -- 当然我们也可以将它作为一张表 SELECT v FROM (SELECT arrayJoin([1, 1, 2, 2, 3]) v); /* ┌─v─┐ │ 1 │ │ 1 │ │ 2 │ │ 2 │ │ 3 │ └───┘ */ -- 通过 groupArray 再变成原来的数组 SELECT groupArray(v) FROM (SELECT arrayJoin([1, 1, 2, 2, 3]) v); /* ┌─groupArray(v)─┐ │ [1,1,2,2,3] │ └───────────────┘ */ -- 如果使用 groupUniqArray 的话 SELECT groupUniqArray(v) FROM (SELECT arrayJoin([1, 1, 2, 2, 3]) v); /* ┌─groupUniqArray(v)─┐ │ [2,1,3] │ └───────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
3.27 arrayDifference数组每相邻两个元素的差值
-- 第一个元素固定为0,第二个元素为3-1,第三个元素为4-3,以此类推 -- 相邻元素相减 SELECT arrayDifference([1, 3, 4, 7, 10]) /* ┌─arrayDifference([1, 3, 4, 7, 10])─┐ │ [0,2,1,3,3] │ └───────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.28 arrayDistinct对数组中的元素进行去重
SELECT arrayDistinct([1, 1, 1, 2, 2, 3]); /* ┌─arrayDistinct([1, 1, 1, 2, 2, 3])─┐ │ [1,2,3] │ └───────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
3.29 arrayEnumerateDense
arrayEnumerateDense:返回一个和原数组大小相等的数组,并指示每个元素在原数组中首次出现的位置(索引都是从 1 开始)
-- 22 首次出现在索引为 1 的位置、1 首次出现在索引为 2 的位置 -- 13 首次出现在索引为 4 的位置,因此结果为 [1, 2, 1, 3, 2, 3] SELECT arrayEnumerateDense([22, 1, 22, 13, 1, 13]); /* ┌─arrayEnumerateDense([22, 1, 22, 13, 1, 13])─┐ │ [1,2,1,3,2,3] │ └─────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.30 arrayIntersect接收多个数组并取它们的交集
SELECT arrayIntersect([1, 2], [2, 3], [3, 4]), arrayIntersect([1, 2], [2, 3], [2, 4]); /* ┌─arrayIntersect([1, 2], [2, 3], [3, 4])─┬─arrayIntersect([1, 2], [2, 3], [2, 4])─┐ │ [] │ [2] │ └────────────────────────────────────────┴────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
3.31 arrayReduce将一个聚合函数作用在数组上
SELECT arrayReduce('max',[1,23,6]), arrayReduce('sum',[1,23,6]); /* ┌─arrayReduce('max', [1, 23, 6])─┬─arrayReduce('sum', [1, 23, 6])─┐ │ 23 │ 30 │ └────────────────────────────────┴────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
可能有人觉得直接用聚合函数不就好了,答案是不行的,因为这些聚合函数针对的都是多行结果集,而不是数组。
-- 相当于只有一行数据,所以返回其本身 -- 如果是 sum 就直接报错了, 因为数组之间不能进行加法运算 SELECT max([11, 33, 22]); /* ┌─max([11, 33, 22])─┐ │ [11,33,22] │ └───────────────────┘ */ -- 如果想返回 33,我们应该将这个数组给展开,变成多行 SELECT max(arrayJoin([11, 33, 22])); /* ┌─max(arrayJoin([11, 33, 22]))─┐ │ 33 │ └──────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
所以聚合函数针对的是多行,而不是数组,如果想用聚合函数,那么应该将数组给展开。或者使用这里的 arrayReduce,相当于将两步合在一起了。当然我们也可以不用 arrayReduce,因为 ClickHouse 为了数组专门提供了相应的操作,比如求数组中最大的元素可以使用更强大的 arrayMax,后面说。
3.32 arrayReduceInRanges
对给定范围内的数组元素应用聚合函数
-- 会对数组中索引为 1 开始向后的 5 个元素进行 sum,结果为 15 -- 会对数组中索引为 2 开始向后的 4 个元素进行 sum,结果为 14 -- 会对数组中索引为 1 开始向后的 3 个元素进行 sum,结果为 6 SELECT arrayReduceInRanges( 'sum', [(1, 5), (2, 4), (1, 3)], [1, 2, 3, 4, 5] ) /* ┌─arrayReduceInRanges('sum', array((1, 5), (2, 4), (1, 3)), [1, 2, 3, 4, 5])─┐ │ [15,14,6] │ └────────────────────────────────────────────────────────────────────────────┘ */ -- 以上等价于 WITH [1, 2, 3, 4, 5] AS arr SELECT [arrayReduce('sum', arraySlice(arr, 1, 5)), arrayReduce('sum', arraySlice(arr, 2, 4)), arrayReduce('sum', arraySlice(arr, 1, 3))] AS v /* ┌─v─────────┐ │ [15,14,6] │ └───────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
3.33 arrayReverse对数组进行逆序
我们之前还介绍了一个 arrayReverseSort,它在逆序之前会先排序,而这里的 arrayReverse 只是单纯的逆序
-- arrayReverse 和 reverse 作用相同 SELECT arrayReverse([22, 33, 11]), reverse([22, 33, 11]); /* ┌─arrayReverse([22, 33, 11])─┬─reverse([22, 33, 11])─┐ │ [11,33,22] │ [11,33,22] │ └────────────────────────────┴───────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.34 arrayFlatten将数组扁平化
-- arrayFlatten 也可以使用 flatten 代替 SELECT arrayFlatten([[1, 2, 3], [11, 22, 33]]); /* ┌─arrayFlatten([[1, 2, 3], [11, 22, 33]])─┐ │ [1,2,3,11,22,33] │ └─────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们之前还介绍了一个 arrayConcat,可以对比一下两者的区别
SELECT arrayConcat ([1, 2, 3], [11, 22, 33]); /* ┌─arrayConcat([1, 2, 3], [11, 22, 33])─┐ │ [1,2,3,11,22,33] │ └──────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
3.35 arrayCompact从数组中删除连续重复的元素
SELECT arrayCompact([2, 2, 1, 1, 1, 3, 3, Null, Null]); /* ┌─arrayCompact([2, 2, 1, 1, 1, 3, 3, NULL, NULL])─┐ │ [2,1,3,NULL] │ └─────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
我们看到作用类似于之前介绍的 arrayDistinct,但两者还是有区别的。
SELECT arrayDistinct([2, 2, 1, 1, 1, 3, 3, NULL, NULL]) /* ┌─arrayDistinct([2, 2, 1, 1, 1, 3, 3, NULL, NULL])─┐ │ [2,1,3] │ └──────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
我们发现 arrayDistinct 不包含 Null 值。
3.36 arrayZip类似于Python中的zip
SELECT arrayZip(['a', 'b', 'c'], [1, 2, 3], ['x', 'y', 'z']); /* ┌─arrayZip(['a', 'b', 'c'], [1, 2, 3], ['x', 'y', 'z'])─┐ │ [('a',1,'x'),('b',2,'y'),('c',3,'z')] │ └───────────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
3.37 arrayMap对数组每个元素作用相同的函数
arrayMap:对数组中每一个元素都作用相同的函数,根据函数的返回值创建一个新的数组,非常常用的一个功能。
SELECT arrayMap(x -> (x, 1), ['a', 'b', 'c']); /* ┌─arrayMap(lambda(tuple(x), tuple(x, 1)), ['a', 'b', 'c'])─┐ │ [('a',1),('b',1),('c',1)] │ └──────────────────────────────────────────────────────────┘ */ SELECT arrayMap(x -> x * 2, [1, 2, 3]) v1, sum(arrayJoin(v1)) v2, arrayReduce('sum', v1) v3; /* ┌─v1──────┬─v2─┬─v3─┐ │ [2,4,6] │ 12 │ 12 │ └─────────┴────┴────┘ */ 当然也可以作用嵌套数组: SELECT arrayMap(x -> arrayReduce('sum', x), [[1, 2, 3], [11, 22, 33], [33, 44, 55]]); /* ┌─arrayMap(lambda(tuple(x), arrayReduce('sum', x)), [[1, 2, 3], [11, 22, 33], [33, 44, 55]])─┐ │ [6,66,132] │ └────────────────────────────────────────────────────────────────────────────────────────────┘ */ SELECT arrayMap(x -> arrayReduce('max', x), [[1, 2, 3], [11, 22, 33], [33, 44, 55]]); /* ┌─arrayMap(lambda(tuple(x), arrayReduce('max', x)), [[1, 2, 3], [11, 22, 33], [33, 44, 55]])─┐ │ [3,33,55] │ └────────────────────────────────────────────────────────────────────────────────────────────┘ */ SELECT arrayMap(x -> arrayReduce('min', x), [[1, 2, 3], [11, 22, 33], [33, 44, 55]]); /* ┌─arrayMap(lambda(tuple(x), arrayReduce('max', x)), [[1, 2, 3], [11, 22, 33], [33, 44, 55]])─┐ │ [1,11,33] │ └────────────────────────────────────────────────────────────────────────────────────────────┘ */ 也可以作用多个数组,这些数组的长度必须相等。此外,有多个数组,函数就要有多少个参数: -- 得到的是 [1 + 11 + 33, 2 + 22 + 44, 3 + 33 + 55] -- 如果是 arrayMap(x -> arrayReduce('sum', x), [[1, 2, 3], [11, 22, 33], [33, 44, 55]]) -- 那么得到的是 [1 + 2 + 3, 11 + 22 + 33, 33 + 44 + 55] SELECT arrayMap(x, y, z -> arrayReduce('sum', [x, y, z]), [1, 2, 3], [11, 22, 33], [33, 44, 55]) AS v; /* ┌─v──────────┐ │ [45,68,91] │ └────────────┘ */ SELECT arrayMap(x, y, z -> (x + y, z), [1, 2, 3], [11, 22, 33], [33, 44, 55]) AS v; /* ┌─v─────────────────────────┐ │ [(12,33),(24,44),(36,55)] │ └───────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
3.38 arrayFilter对数组中每个元素作用相同的函数
arrayFilter:对数组中每一个元素都作用相同的函数,如果函数返回值为真(非 0),则该元素保留,否则不保留。
SELECT arrayFilter(x -> x > 5, [1, 4, 5, 7, 10]); /* ┌─arrayFilter(lambda(tuple(x), greater(x, 5)), [1, 4, 5, 7, 10])─┐ │ [7,10] │ └────────────────────────────────────────────────────────────────┘ */ SELECT arrayFilter(x -> length(x) > 1, ['a', 'aa', 'aaa']); /* ┌─arrayFilter(lambda(tuple(x), greater(length(x), 1)), ['a', 'aa', 'aaa'])─┐ │ ['aa','aaa'] │ └──────────────────────────────────────────────────────────────────────────┘ */ SELECT arrayFilter(x -> x LIKE 'sa%', ['satori', 'koishi']); /* ┌─arrayFilter(lambda(tuple(x), like(x, 'sa%')), ['satori', 'koishi'])─┐ │ ['satori'] │ └─────────────────────────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3.39 arrayFill对数组中每个元素作用相同的函数
arrayFill:对数组中每一个元素都作用相同的函数,如果函数返回值为真,则该元素保留,否则被替换为前一个元素。
-- 2 会被替换成 4,1 会被替换成 5 SELECT arrayFill(x -> x >= 3, [3, 4, 2, 5, 1]); /* ┌─arrayFill(lambda(tuple(x), greaterOrEquals(x, 3)), [3, 4, 2, 5, 1])─┐ │ [3,4,4,5,5] │ └─────────────────────────────────────────────────────────────────────┘ */ -- 第一个元素永远不会被替换,2、3、4、5 都不满足条件,因此都要换成前一个元素 -- 换 2 的时候,2 已经变成了 1,所以 3 的前面是 1,于是 3 也会变成 1 -- 4 和 5 也是同理,因此最终所有值都会变成 1 SELECT arrayFill(x -> x >= 6, [1, 2, 3, 4, 5]); /* ┌─arrayFill(lambda(tuple(x), greaterOrEquals(x, 6)), [1, 2, 3, 4, 5])─┐ │ [1,1,1,1,1] │ └─────────────────────────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.40 arrayReverseFill对数组每个元素作用相同的函数
arrayReverseFill:对数组中每一个元素都作用相同的函数,如果函数返回值为真,则该元素保留,否则被替换为后一个元素。注意:此时数组是从后往前扫描的
-- 2 会被替换成 5,1 还是 1,最后一个元素不会被替换 SELECT arrayReverseFill(x -> x >= 3, [3, 4, 2, 5, 1]); /* ┌─arrayReverseFill(lambda(tuple(x), greaterOrEquals(x, 3)), [3, 4, 2, 5, 1])─┐ │ [3,4,5,5,1] │ └────────────────────────────────────────────────────────────────────────────┘ */ -- 因为数组从后往前扫描,所以 4 变成 5、3 也会变成 5,所有值都会变成 5 SELECT arrayReverseFill(x -> x >= 6, [1, 2, 3, 4, 5]); /* ┌─arrayReverseFill(lambda(tuple(x), greaterOrEquals(x, 6)), [1, 2, 3, 4, 5])─┐ │ [5,5,5,5,5] │ └────────────────────────────────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.41 arrayMin返回数组中最小的元素
arrayMin:返回数组中最小的元素
WITH [11, 22, 8, 33] AS arr SELECT arrayMin(arr) v1, min(arrayJoin(arr)) v2, arrayReduce('min', arr) v3; /* ┌─v1─┬─v2─┬─v3─┐ │ 8 │ 8 │ 8 │ └────┴────┴────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
arrayMin 里面还可以传递一个匿名函数:
SELECT arrayMin(x -> -x, [11, 22, 8, 33]) /* ┌─arrayMin(lambda(tuple(x), negate(x)), [11, 22, 8, 33])─┐ │ -33 │ └────────────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
会按照调用匿名函数的返回值进行判断,选择最小的元素,这里 33 在调用之后返回 -33,显然是最小值。但是这里有一个需要注意的地方,就是它返回的也是匿名函数的返回值。个人觉得应该返回 33 才对,应为我们指定函数只是希望 ClickHouse 能够按照我们指定的规则进行排序,而值还是原来的值,但 ClickHouse 这里设计有点莫测高深了。如果我们以字符串为例,那么会看的更加明显:
SELECT arrayMin(x -> length(x), ['ab', 'abc', 'a']) v; /* ┌─v─┐ │ 1 │ └───┘ */- 1
- 2
- 3
- 4
- 5
- 6
我们看到居然返回了一个 1,我们的本意是想选择长度最短的字符串,但是返回的是最短字符串的长度,也就是返回的不是 ‘a’,而是 length(‘a’)。
3.42 arrayMax返回数组中最大的元素
WITH [11, 22, 8, 33] AS arr SELECT arrayMax(arr) v1, max(arrayJoin(arr)) v2, arrayReduce('max', arr) v3; /* ┌─v1─┬─v2─┬─v3─┐ │ 33 │ 33 │ 33 │ └────┴────┴────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
也可以加上一个匿名函数,作用和 arrayMin 完全一样,并且返回的也是函数调用之后的结果。
3.43 arraySum对数组求总和
WITH range(1, 101) AS arr SELECT arraySum(arr), arrayReduce('sum', arr), sum(arrayJoin(arr)); /* ┌─arraySum(arr)─┬─arrayReduce('sum', arr)─┬─sum(arrayJoin(arr))─┐ │ 5050 │ 5050 │ 5050 │ └───────────────┴─────────────────────────┴─────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
同样可以加一个匿名函数:
WITH range(1, 101) AS arr SELECT arraySum(x -> x * 2, arr); /* ┌─arraySum(lambda(tuple(x), multiply(x, 2)), arr)─┐ │ 10100 │ └─────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
3.44 arrayProduct对数组求总乘积
SELECT arrayProduct([1, 2, 3, 4, 5]); /* ┌─arrayProduct([1, 2, 3, 4, 5])─┐ │ 120 │ └───────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
同样可以加一个匿名函数:
SELECT arrayProduct(x -> x + 1, [1, 2, 3, 4, 5]); /* ┌─arrayProduct(lambda(tuple(x), plus(x, 1)), [1, 2, 3, 4, 5])─┐ │ 720 │ └─────────────────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
3.45 arrayAvg对数组取平均值
WITH range(1, 101) AS arr SELECT arrayAvg(arr), arrayReduce('avg', arr), avg(arrayJoin(arr)); /* ┌─arrayAvg(arr)─┬─arrayReduce('avg', arr)─┬─avg(arrayJoin(arr))─┐ │ 50.5 │ 50.5 │ 50.5 │ └───────────────┴─────────────────────────┴─────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
同样可以加一个匿名函数:
WITH range(1, 101) AS arr SELECT arrayAvg(x -> x * 2, arr); /* ┌─arrayAvg(lambda(tuple(x), multiply(x, 2)), arr)─┐ │ 101 │ └─────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.46 arrayCumSum对数组进行累和
-- 第一个元素不变 SELECT arrayCumSum([1, 2, 3, 4, 5]); /* ┌─arrayCumSum([1, 2, 3, 4, 5])─┐ │ [1,3,6,10,15] │ └──────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
同样可以加一个匿名函数:
-- 第一个元素不变 SELECT arrayCumSum(x -> x * 2, [1, 2, 3, 4, 5]), arrayCumSum([2, 4, 6, 8, 10]); /* ┌─arrayCumSum(lambda(tuple(x), multiply(x, 2)), [1, 2, 3, 4, 5])─┬─arrayCumSum([2, 4, 6, 8, 10])─┐ │ [2,6,12,20,30] │ [2,6,12,20,30] │ └────────────────────────────────────────────────────────────────┴───────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
4 小结
以上就是关于 ClickHouse 数组的一些函数操作,可以说是非常强大了,不光是功能强大,用起来也很舒服,仿佛有种在写 Python 代码的感觉。当然以上并不是关于数组的全部操作(绝大部分),但说实话已经够用了,即使你当前的需求,某一个函数不能解决,那么也能多个函数组合来解决。比如我们想要计算两个数组中相同位置的元素的差,那么就可以这么做:
-- 一个函数即可解决 SELECT arrayMap(x, y -> x - y, [1, 2, 3], [3, 2, 1]); /* ┌─arrayMap(lambda(tuple(x, y), minus(x, y)), [1, 2, 3], [3, 2, 1])─┐ │ [-2,0,2] │ └──────────────────────────────────────────────────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
再比如,计算数组中每个元素减去上一个元素的值,由于第一个元素上面没有值,那么设为空:
-- 我们只需要选择 arr 的前 N - 1 个元素,然后再在头部插入一个 Null,[Null, 11, 22, 33, 44, 55] -- 最后让 arr 和它的对应元素依次相减即可 WITH [11, 22, 33, 44, 55, 66] AS arr SELECT arrayMap( x, y -> x - y, arr, arrayPushFront(arraySlice(arr, 1, length(arr) - 1), Null) ) v; /* ┌─v─────────────────────┐ │ [NULL,11,11,11,11,11] │ └───────────────────────┘ */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
显然即使是复杂的需求,也可以通过多个函数组合完成,怎么样,是不是有点酷呢?ClickHouse 内建了很多的函数,这些函数给我们一种仿佛在用编程语言写代码的感觉。
-
相关阅读:
ROS2系列知识(6):Action服务概念
基于JavaWeb的宿舍管理系统设计与实现
ANIMALS FULL PACK (总共三十个动物)
selenium安装配置及基本使用
100天精通Python(爬虫篇)——第47天:selenium自动化操作浏览器
Scapy样例三则
[halcon案例2] 足球场的提取和射影变换
力扣373.查找和最小的K对数字
基于JAVA疫情防控网站计算机毕业设计源码+系统+数据库+lw文档+部署
驱动器类产品的接口EMC拓扑方案
- 原文地址:https://blog.csdn.net/qq_20466211/article/details/127829334
