-
建模杂谈系列178 APIFunc继续实践-NER01
说明
之前新部署的实体识别的接口服务还是有点小问题,主要是效率上的(不如之前的高),所以考虑再使用APIFunc重构一次。
说起来搭建上一版的实体接口服务时,也是对APIFunc的原型设计实验,再次看代码时,发现其中还是有很大的框架性问题。功能当然是ok,但是从产品设计上,这样的框架原型是无法拓展的,这才是Review代码和重构时比较产生的价值。
简单说来,原来的NER服务自重太大,载重过低。一辆大卡车,只运了一盒蛋糕的感觉。
当时想的是构造一个对象,把相关的东西都放在一起,共享变量空间,然后流程化执行。
ner.connection_test() ner.getting_data() ner.adjust_getting_data() ner.is_data_format_right() ner.processing(para_dict = {'keep_cols':['doc_id','task_for','rec_id','function_type' ,'ORG_result','PER_result','content_hash']}) ner.to_buffer(para_dict = {}) ner.to_oprlog(para_dict={}) ner.worker_log()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这样做看起来很对,但实际上是不对的。很多和逻辑核心无关的东西都揉在一起了,在调试的时候我们是看逻辑还是运行架构呢?
APIFunc在设计时,先规划好了数据的流,只有Worker是「待镶嵌」的组件。所以,当项目规划好了,实际上就已经在持续运行了,一系列获取数据写缓存啥的和Worker都没有关系。
Worker只从队列里取数,处理,然后放回另一个队列,最后写一条日志。
这种纯粹的(内存)IO和日志都有专门函数/服务来处理,相当于一个模板。最近正好平行的使用Kettle来完成类似的工作,所以发现这么做应该是对的。
在Kettle中,分为Job和Transformation,其中Job干的就是外面一堆杂事,把很多Transformation连起来。而Transformation则专注于一个个的处理过程。
把APIFunc和之前的设计版,以及成熟的产品对比,这才是一个新产品的正确方向。
内容
1 概述
总的说起来,我想APIFunc会比Kettle更强大一些。
差异点1:APIFunc自带的默认的数据库体系
Kettle其实只负责处理和联合调度,具体是哪些数据库或者文件进行IO是不管的。这样当然可以说是比较灵活,但是其实也会有很大的使用成本。也就说使用者不仅要关心处理逻辑,还要关心IO。
APIFunc则选用了一套高效的数据库体系,确保了数据的存储、流转和分发,以及元数据的存储。在IO端,你是可以用任何程序通过API的方式向系统发送和取出数据的。这样,IO几乎就等于API,只有一种方式。
Worker在接入APIFunc处理时,一般默认是在局域网内的,也是使用API(访问内存数据库)吞吐数据,效率很高,自带子任务分发。
如果说以上仅仅是运行/运维方面的便利性,那么元数据就是价值二次提炼的核心。
APIFunc认为数据不可能是一次处理好的,也不是一种方法能处理好的
通过元数据的分析和建模,我们可以让数据处理采用更复杂的多的方式进行细分和协同。搞过建模的应该都能理解。
差异点2:Col Base Processing
APIFunc的默认模式是只要对一行进行处理就可以了,这样编辑起来会很容易。而且很重要的是,可以跨行联动处理(也就是同时处理包含多列的行)。相比之下,Kettle的处理看起来是按列的(不能同时处理多列),但本质上是按列声明的按行处理方式。所以这种方式还不如APIFunc强大。
对于行处理来说,python在底层是要通过cyphon来进行并行调度的,所以按行编辑的时候要求所用的函数是cythonable的。大部分的函数,包括正则都是可以的。
那什么不可以呢?例如使用深度学习预测,或者是矩阵计算。
本质上,最高效的数值计算应该就是矩阵计算,这可以达到单核的最高峰。
API允许处理到某一步骤的时候切换按列执行,执行时会把一列或几列转换为矩阵执行。这点Kettle应该是没有的。在支持深度学习上,这点是必要的,比如这次就需要插入实体模型的处理。数据-> 张量 -> (显存) -> GPU/CPU -> 数据。
差异点3:接口或Python
Kettle的拓展方式是插件和Java, APIFunc的拓展方式是API和Python。
这些差异点都还是比较大的,总体上我认为APIFunc继续发展,最终可以让我在更短的时间编写更可靠的程序,易于运维长效执行。而且不仅仅是数据清洗,而是包含了数据分析、建模和决策以及自动优化的一个体系。
2 开始
话可以往远处说,事要从近处着手做
2.1 WMongo TryConnectionOnce ~ 1.5 Hours
先解决掉这个问题,这样在部署的时候就可以做到位置无关了。
返回:新WMongo实例(目标实例)或者False
-
参数:
- 1 mongo_agent_host 格式为 http://xxx.xxx.xxx.xxx:12345/
-
1 首先只要求wmongo具有连接mymeta的能力
-
2 优先使用自己主机上的MongoAgent代理
- 最特殊的主机是:本地主机和目标主机
- 还有就是其他算网内主机(LAN or WAN)
-
3 逻辑上先访问mymeta,获取到元数据后开始使用指定的代理服务器发起连接探查。如果没有连接,那么就新建一次,并返回当前一个全新的WMongo实例。如果中间有任何问题都会返回False。
在使用的时候从依赖文件中引入WMongo,然后在一个入口程序里完成目标连接的初始化,其他各程序引用即可。
2.2 Step1Worker
2.2.1 从实例开始
APIFunc实例化时要提供样例数据。
一开始没有太在意,在做的时候很自然就这么定义了,这样依赖,无形间约束了使用者:想要开发APIFunc,先给几条示例数据。
这样既可以让开发者有一个清晰的起点,不迷茫;另外带来的好处是以后debug的时候,也是要给数据的,这个口子就接的很好。
tem_listofdict =[{'ner_doc_id': 1, 'content': 'sssssss'}, {'ner_doc_id': 2, 'content': 'xxxxxxx'}, {'ner_doc_id': 3, 'content': 'aaaaaaa'}] af = APIFunc('ner_parse', listofdict= tem_listofdict, key_id='ner_doc_id')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2.2 图准备好了吗
对于任何的APIFunc开发,首先是要把图给画出来。有了图就有了排序,然后顺着做就行了。
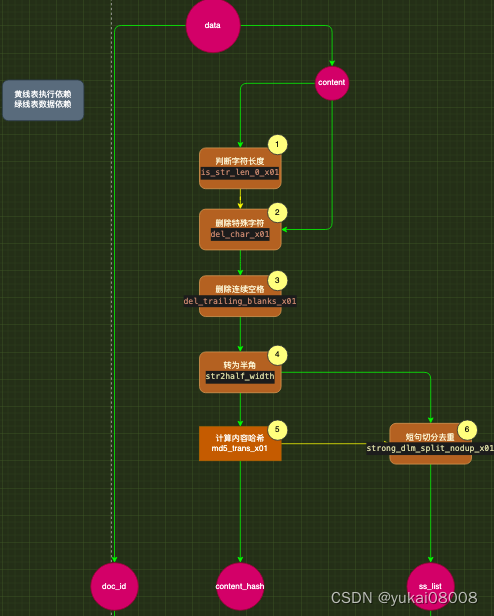
2.2.3 规则链/规则函数的开发
写到这里正好稍微梳理一下层级结构
几个概念如下
名称 解释 GS,GraphSession 一个Project对应一个GS CS,ChainSession 一个端到端的逻辑链,分为一字型和Y型两种 RuleF, Rule Function 规则函数 RootF, Root Function 根函数 他们之前的关系如下
- 1 GS: 由一系列具有拓扑排序的CS组成
- 2 CS: 由一系列具有拓扑排序的RuleF组成
- 3 CS: 具有结构,如果是一字型就不限长度;如果是Y型则只有两层。
- 4 CS: 其中的RuleF可以依赖超出本CS,但是不超出GS的其他RuleF
- 5 RuleF: 是RootF的偏函数,RuleF在一个GS中名称是唯一的
- 6 RootF: 是对基础函数(普通无状态的python函数)的一个封装,多了规则部分的表达
从复用角度上看:
- 1 GS: 是最大的复制单元
- 2 CS: 是最小的工作单位
- 3 CS: 如果网页端好了的话,选中一个CS,会将对应的RuleF按拓扑排序展示在页面上
- 4 RuleF: 有些应用只是改改配置,在页面上改变对应的依赖和参数就可以(意味着有一个当前GS下的C.RuleF联合下拉框)
- 5 RuleF: 可以对根函数进行变体,但这样哈希就会变,不能再被继承和复制(除非也发布为新的根函数)
数据表
数据表只有两层
L1
分为GS、CS和RootFunc三个表
L1.GS
字段名 解释 project 项目名称 in_sample 输入的示例,一般是一个字典 out_sample 输出的实例,一般是一个字典 L2.GS_Details
字段名 解释 project 项目名称 tord 拓扑排序(cs的) csname cs名称 varname 变量名,变量进入体系后将会以 x_001之类的方式命名 exe_csname 将cs名和varname加起来的名称,主要用于执行时的识别 L1.CS
字段名 解释 csname cs名称 in_sample 输入的示例,一般是一个字典 out_sample 输出的实例,一般是一个字典 L2.CS_Details
字段名 解释 csname cs名称 tord 拓扑排序(RuleF的) root_func 根函数名称 L1.RootFunc
字段名 解释 name rootfunc名称 func 函数体 rule 规则判定逻辑 1,0,-1 关于字段的拓展,约定末尾为x,y,z;x->y->z是逐层递进的关系
- 1 因为「瀑布图」的原因,每个分支要有x才能区分不同变量
- 2 因为某个变量可能是一个字典,如果采用同样的函数要加上y区分
- 3 如果某个变量是字典,并且里面多个变量采用了多次的同样函数,那就要加上z。
未来进行自动调优时,是以GS为整体目标,分为结构和参数两部分。可能会以md5_md5的方式表达一个搜索的参数空间。
依赖分为程序依赖和数据依赖,后者一定包含了某个程序依赖(正常运行),甚至也可以进一步声明为运行为某个特殊规则结果的依赖。
这里,规则其实是对
del_char规则的数据有依赖(而del_char这条规则只对前面的规则有运行依赖,真正的数据是来自原始文件的)del_trailing_blanks['subline_dict'] ={'del_char':None} del_trailing_blanks['main_dict'] = {'key_id':gs_id, 'depend_cols':['del_char.data'], 'input_cols': ['some_str']}- 1
- 2
- 3
- 4
以上的表都还没有做,可以看成是设计示意表。
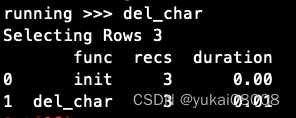
定义好一条规则,调试的方式如下(相当于运行一个最短的会话,只有一个函数):

这是规则结果,主要是可以看到运行时间。我发现这个对于开发很有帮助,这样不仅知道逻辑的效果,还知道程序的效率。
规则函数模板在生产状态时,会用try把主逻辑函数包起来,但是在调试时就不方便。所以约定函数具有一个参数(is_debug),这个参数为True时不走try逻辑。
第一条链:

封装。这样的链之后是要存表的,用的时候就可以直接复用。# 定义一个链 StandardCleanChar_session = ['is_str_len_0','del_char','del_trailing_blanks','str2half_width']- 1
- 2
运行
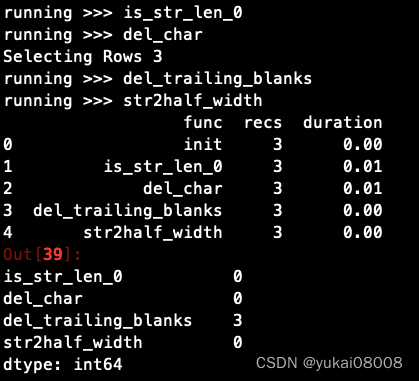
Col_Base因为这种方法用的比例比较低,而且通常都是类似矩阵计算的场景下才使用的,我稍微梳理一下,免的以后自己忘了。
默认情况均是指row_base情况。
- 1 修饰器的头部声明**@af.route(‘/ner_predict’, is_force=True,
is_col_base = True)**,声明is_col_base = True默认是False - 2 函数的参数ner_predict(
input_listofdict = None, para_dict = None), 声明输入为input_listofdict,默认是input_dict,注意传入函数的实际上是input_seriesofdict - 3 返回的是一个有固定字段要求的DataFrame。
下面的是检测入字段集合是否符合需求,返回的字段数和正常处理时返回的字段数是相同的。
need_cols = ['model_data'] sample_input_dict = input_listofdict[0] input_cols = list(sample_input_dict.keys()) if not (set(need_cols) <= set(input_cols)): res_df = pd.DataFrame() res_df['status'] = [False]* len(input_listofdict) res_df['rule_result'] = None res_df['msg'] = 'InputSetError' res_df['data'] = None res_df['name']='ner_predict' return res_df- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
字段说明
字段 解释 status 表示运行的状态,一般就是全True/False rule_result 1/0/None msg 运行中提示的错误 data 结果数据,通常可以用col2s来将多列的数据以字典形式压到一列里 name 规则名称 总体来说,当使用Col-Base模式时,函数将默认处理一列数据。此时程序内部不再有try…except,而是由使用者来确保整个程序的可靠运行。
在引用主键id时,depend_cols和input_cols都要使用主键名称,不能给主键映射重命名。
Col-Base方法要保证输出的行数等于输入的行数,且不要乱序。主程序会自动进行合适的匹配,不用担心匹配不到对应的记录。
当然可以在运行前加上一些前置检查/筛选来辅助这个步骤,但总体上,这个步骤必须是可以自己保证可靠的。
内存/显存耗用
在这次测试开发中,我使用一万条数据作为输入,然后在使用深度学习模型预测时采取了不同的批次测试。从CPU和GPU的体系比较来看,GPU下内存的耗费大约是CPU的3~4倍,同样的还有显存耗用,大约是内存的1.5倍。我不太清楚内部的转换发生了什么,但我想可以理解为空间换时间。
- 1 因为要使用显卡,就要将数据和模型从内存搬到显存
- 2 最终要输出,所以又要将显存的结果转到内存
- 3 中间收益的是进入显存后,使用GPU加速计算
目前来看,对比是很明显的。GPU(3060Ti)在未满载的情况下,速度是16核CPU的10倍速。GPU如果更合理的加负载(例如将批次任务再缩小,允许4~5个Worker同时跑),那么速度应该会更可观。
但是使用CPU有一个优点,就是内存控制的很好。
我观察了CPU 容器运行(
docker stats CONTAINER)的过程,内存最高的峰值也不超过1.5G,这样在低配的服务器上也可以运行。大致的速度是 1.5~1.7/U*秒, 所以一台服务器使用一个核,一天能处理13万 ~ 14.7万文档。行编辑时主逻辑的赋值
每条规则大概率会存在规则上的差异,但无论如何,都要围绕着给消息对象的三个属性赋值。 正常执行时
rule_result会赋值0,1。错误时的赋值(except),没有逻辑,直接赋值。但是参考逻辑正常时应该怎么给。
msg.status = False msg.rule_result = None msg.data = None- 1
- 2
- 3
链的实现
以下是整个处理流的链,链可以:
- 1 将一些常用的“连招”复用起来,比如
StandardCleanChar_session可以用在很多文本的处理上 - 2 将工作进行分解、分摊。有些项目相关的独特链需要单独开发的,就可以剥离出来。因为APIFunc的每个会话都是可以使用一些样例数据初始化的,所以即使逻辑上有依赖关系,在开发的时候也可以并行。
- 3 链分为两种,Y型和I型。这次的实现也正好有一个Y型链
NerPredictFork_session。约定Y型链只有两层(理论上应该把NerPredict_session也并在一起)
这个是测试态,将链分开来写的方法。执行时把这些列表加一起,运行一条语句就行。
# 定义一个链(常用、复用) StandardCleanChar_session = ['is_str_len_0','del_char','del_trailing_blanks','str2half_width'] TemSplit_session = ['md5_trans_a_str','strong_dlm_split_nodup'] NerPredict_session = ['ner_predict'] NerPredictFork_session = ['person_len','company_len'] PER_session = ['sub_entity_del_1'] ORG_session = ['del_trailing_word','sub_entity_del_y02','non_org_entity_filter'] # =============== 【调试一条链】 StandardCleanChar_list = StandardCleanChar_session StandardCleanChar_dict = {} for k in StandardCleanChar_list: StandardCleanChar_dict[k] = chain_funcname_dict[k] af.run_chain(chain_funcname_list=StandardCleanChar_list,chain_funcname_dict=StandardCleanChar_dict) af.g['ruleresult_frame'][ [x for x in af.g['ruleresult_frame'].columns if x !=gs_id]].sum() # -- TemSplit_list = TemSplit_session TemSplit_dict = {} for k in TemSplit_list: TemSplit_dict[k] = chain_funcname_dict[k] af.run_chain(chain_funcname_list=TemSplit_list,chain_funcname_dict=TemSplit_dict) af.g['ruleresult_frame'][ [x for x in af.g['ruleresult_frame'].columns if x !=gs_id]].sum() # -- NerPredict_list = NerPredict_session NerPredict_dict = {} for k in NerPredict_list: NerPredict_dict[k] = chain_funcname_dict[k] af.run_chain(chain_funcname_list=NerPredict_list,chain_funcname_dict=NerPredict_dict) af.g['ruleresult_frame'][ [x for x in af.g['ruleresult_frame'].columns if x !=gs_id]].sum() # -- NerPredictFork_list = NerPredictFork_session NerPredictFork_dict = {} for k in NerPredictFork_list: NerPredictFork_dict[k] = chain_funcname_dict[k] af.run_chain(chain_funcname_list=NerPredictFork_list,chain_funcname_dict=NerPredictFork_dict) af.g['ruleresult_frame'][ [x for x in af.g['ruleresult_frame'].columns if x !=gs_id]].sum() # -- PER_list = PER_session PER_dict = {} for k in PER_list: PER_dict[k] = chain_funcname_dict[k] af.run_chain(chain_funcname_list=PER_list,chain_funcname_dict=PER_dict) af.g['ruleresult_frame'][ [x for x in af.g['ruleresult_frame'].columns if x !=gs_id]].sum() # -- ORG_list = ORG_session ORG_dict = {} for k in ORG_list: ORG_dict[k] = chain_funcname_dict[k] af.run_chain(chain_funcname_list=ORG_list,chain_funcname_dict=ORG_dict) af.g['ruleresult_frame'][ [x for x in af.g['ruleresult_frame'].columns if x !=gs_id]].sum()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
还有一个merge输出的session,就不写了。
3 部署
本次仍然可以使用最简单的单步结构
单个APIFunc的集成能力是非常可观的,本次使用单步结构一半是出于巩固和强化设计,另一半则是真的没有必要用更多步。可以想象,未来有两种模式:
- 1 使用单步结构将大部分的任务处理掉,然后在上面再搭单步结构将底层的单步结合起来
- 2 适当的使用多步结构
至少目前我觉得大部分的(>80%)的需求可以用单步解决,所以现在还是专注在提升单步结构的熟练度上。
3.1 项目初始化
init_projects.py现在可以更细致的将项目需要的表进行细分,现在可以使用自动连接方法了,感觉很方便
w = WMongo('w') target_server = 'm7.24059' cur_w = w.TryConnectionOnceAndForever(server_name =target_server)- 1
- 2
- 3
这样就获得了本机访问目标数据服务的工具(
cur_w)工作表
以Step开头的表
工作表的目的是容纳每个步骤的IO,以及步骤间的元数据。
这样就创建了对应表的一系列默认的索引。要特别注意的是,对于gs_id创建的是主键索引,如果插入重复数据会直接报错误。
gs_id = 'ner_doc_id' project_name ='ner' cur_w.ensure_mongo_index(tier1 =project_name, tier2 ='step1_input', key_index=gs_id) cur_w.ensure_mongo_index(tier1 =project_name, tier2 ='step2_output',key_index=gs_id,index_list = ['content_hash']) cur_w.ensure_mongo_index(tier1 =project_name, tier2 ='step1_step2_ruleresult',key_index=gs_id) {'data': {'ner_doc_id': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_is_enable_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_create_time_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_update_time_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_ch001_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_ch001_cnt_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'ner_doc_id': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'content_hash_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_is_enable_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_create_time_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_update_time_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_ch001_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_ch001_cnt_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'ner_doc_id': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_is_enable_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_create_time_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_update_time_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_ch001_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True} {'data': {'_ch001_cnt_1': 'Not Existed and Created'}, 'msg': 'ok', 'status': True}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
日志表
为两类型(Sniffer、Worker)创建三种角色的日志表(monitor, sniffer , worker), 实际上应该还有stats,这个以后再说。
cur_w.set_a_index(tier1 =project_name, tier2='log_monitor', idx_var ='_create_time') cur_w.set_a_index(tier1 =project_name, tier2='log_sniffer', idx_var ='_create_time') cur_w.set_a_index(tier1 =project_name, tier2='log_worker', idx_var ='_create_time')- 1
- 2
- 3
- 4
统计表
这个暂缺
监控表
暂缺,仅凭日志就足够暂时很多信息了。
队列
默认是存在Redis服务的,在初始化时也要同步的确认消费组
# ======================= Redis ========================= # 渠道工作流的工作组 | 确保需要分发的stream建立消费组 work_in_stream = '%s.step1_work' % project_name work_out_stream = '%s.step2_work' % project_name group_name = 'group1' lq.ensure_group(work_in_stream,group_name, start_point ='0') lq.ensure_group(work_out_stream,group_name ,start_point ='0')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.2 三个推动流
这三个流是保证数据从缓存池到输出的流动, 推动流和Worker共同构成了一个Job
这里还需要先确保 RedisAgent(24021)服务的存在,这样操作Redis Stream就会很简单。
推动流是以app开头命名的,序号不代表顺序,只是一个编号。
app01_PullToStep1Mongo.py app02_PushStep1WorkerStream.py app03_PullToStep2Mongo.py- 1
- 2
- 3
所有的app将归口到
app.py,里面会将所有需要运行的app都串行的运行起来,提供一个串行的运行逻辑。当然本质上这些app全部是可以并行的,甚至可以fork。归口到app里的目的是提供一个基础的运行样例,过一段时间(~ 1Mon),我的前端组件将提供更透明的控制,那个才是一个常态的运行机制。
3.3 一个Worker
Worker是处理的核心,有点像Transformation, 但是强大太多…
其中worker开头的主要是进行调度的,核心的逻辑是在去掉前缀的文件中,这个文件就是使用APIFunc搭建的逻辑处理。
worker01_Step1Worker.py Step1Worker.py- 1
- 2
3.4 一个调度器
基于APScheduler可以进行调度
sche.py- 1
这里面封装了对app.py和 worker.py的逻辑,确保整个流持续流动。这里有一部分应该通过前端解决,有一步需要做一些动态加速的控制。目前先以固定的时间将(5秒)持续调度。
3.5 三个监控
Monitor通过持续的检查队列和数据库信息来获得任务的执行情况
monitor01_StreamFlow.py 检查各个流的消息数 monitor02_DB_Recs.py 检查step1 ~ step2两个Mongo表的数据数量 monitor03_Step1TasksClaimed.py 检查step1 表中未认领数据的情况- 1
- 2
- 3
类似地,三个监控也归口到
monitor.py执行。3.6 小结
程序部分
逻辑功能 数量 app 3 worker 1 sche 1 monitor 3 数据存储与流通
组件 数量 streams 3+2 (3 个是内部的stream, 另外两个是系统的input和output) mongo.collection 3
其他一些notes,具体的代码就不放了:
- 1 funcs.py 还是一个关键点,不能随便开放。一方面是限制只放必要的函数(并且函数使用版本控制),另一方面进行so加密,虽然这样也不能完全阻拦信息泄露,但是增加了难度和成本。
- 2 configs.py 里面放一些配置信息,例如
redis_agent_host目前没有自动化匹配,所以就还是手动配置。
快速搭建改进
到目前为止,在APIFunc上正式部署的项目这个应该算是第三个项目了,从前端交互式表格得到的一些体验,APIFunc的这种简单结构应该有可以快速搭建(20分钟内)。
标准APIFunc DataBase结构图
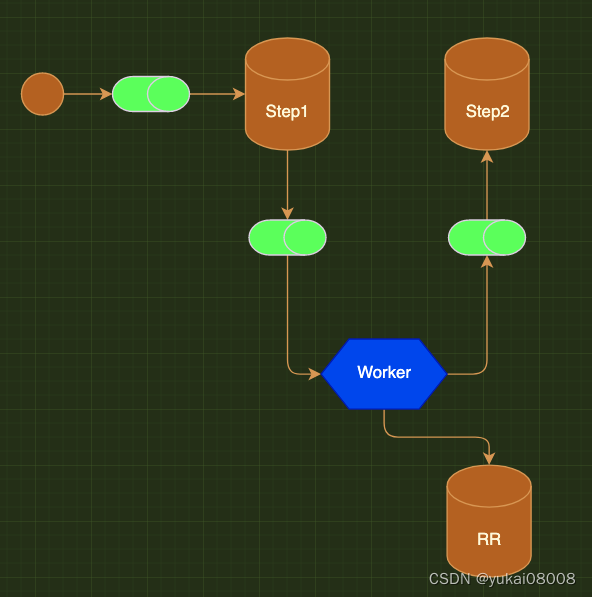
需要做的东西复杂度甚至都差不多:
- 1 分配一个Mongo服务,确保运行机存在一个Redis服务 - 人工
- 2 在meta.servers 确保目标主机的信息配置完毕 - 人工
- 3 明确项目的名称,以及数据主键名称 - 人工
- 4 运行
init_project.py将需要的数据库、表和队列都设置好。 - 脚本 - 5 app和monitor部分照搬(做好参数化 在configs.py里定义)- 脚本
可以这么想象,做好一个模板文件,新的项目只会修改configs.py和具体的Worker逻辑,不同的项目启动时只修改两个文件的映射。
更具体一点,先做一个模板项目,将重要的文件健米,然后投射到某个容器里,再将这个容器打包发布为镜像。然后新的项目只需要配置、Worker逻辑(基于APIFunc),哦,另外还有IO的处理函数。
这样将IO和Worker个性化,整个体系的运行还有监督都是制式的。
Worker一般需要1~2天, IO一般在一天内,所以一个完整的APIFunc项目周期一般为3天,放宽一点,就是一周。
4 总结
APIFunc 绝对是可用的,在不修改内核逻辑的情况下,我打算将所有我的内部项目全部使用APIFunc转换。
- 1 优化了算网主机与目标主机的自动连接方式
- 2 通过和kettle比对,更深的了解了APIFunc的特性和未来发展方向
- 3 明确了APIFunc的GS、CS、RootF和RuleF的概念,以及大致的表结构。这样交互表格就会以这种结构来增强APIFunc应用。
- 4 再次完成了一次Col-Base应用测试。开发方式、功能,还有性能。
- 5 再次实现了一次APIFunc项目的构建,优化了构建方式
- 6 在将服务优化的过程中,实际上还看到了很多问题点(< 3%),这些问题点相对是比较隐蔽的,通过规则元数据只需要少量样本就能发现问题。是清晰可优化的,只不过暂时没有时间,所以先这样吧。但是有信心对这些问题进行精准调优。这也是工具的灵活性特点。
-
相关阅读:
线程篇(JAVA)
R语言 批量导入数据
JavaScript基础语法的简单了解
毕业设计-深度学习身份证号码检测识别-python-opencv
FFplay文档解读-50-多媒体过滤器四
Pythonmock基本使用
ubuntu实现定时重启
花生壳配置TCP服务器
java毕业设计——基于java+JSP+J2EE的户籍管理系统设计与实现——户籍管理系统
ES6中实现继承
- 原文地址:https://blog.csdn.net/yukai08008/article/details/127918699
