-
Pandas 数据中的loc与iloc含义以及操作
本节学习并记录pandas 的DataFrame类型的数据是怎么对列或者行进行操作的
1、df.loc: 语法格式是df.loc[<行表达式>, <列表达式>],如果列不传将返回所有的行,loc操作通过索引和列的条件筛选出数据。
2、df.iloc: 语法格式是df.iloc[<行表达式>, <列表达式>],格式可以使用数字索引(行和列的0~n索引)进行筛选数据,意味着iloc[]的表达式只支持数据切片的形式
一、首先定义一组数据,或者读取csv文件,Excel表格json数据,这里使用读取csv文件进行来当基础数据操作,这里读取前100行,只显示前5行
- import pandas as pd
- data_path = './neo4j_all_metric.csv'
- df = pd.read_csv(data_path, nrows=100)
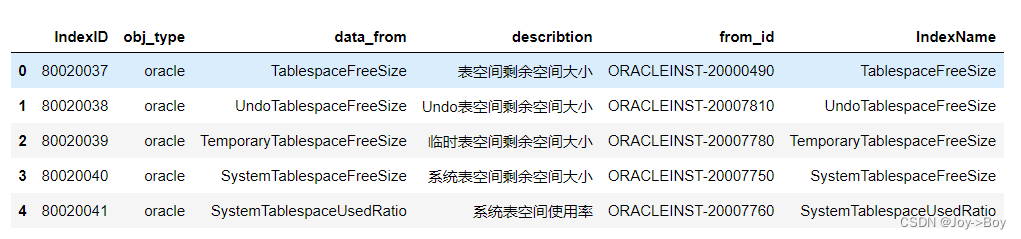
二、.loc的基本操作
1、单个索引,如果是字符串,需要加上引号
- # 选取索引为0的行
- df.loc[0]
- # 选取索引为10的行
- df.loc[10]
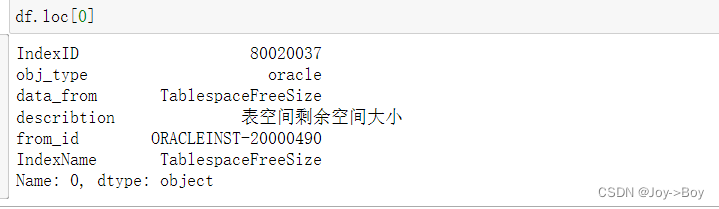
2、以列表组成的索引,例如[1, 3 , 5, 7, 9],显示出该列表对应行数的所有列的数据
- # 此时索引是一个列表, 可以选择第 1,3,5,7,9行
- df.loc[[1, 3, 5, 7, 9]]

3、带标签的切片,如Python的列表操作,包括起始已停止。
- # 显示的是5-10行的所有列的内容
- df.loc[5:10]
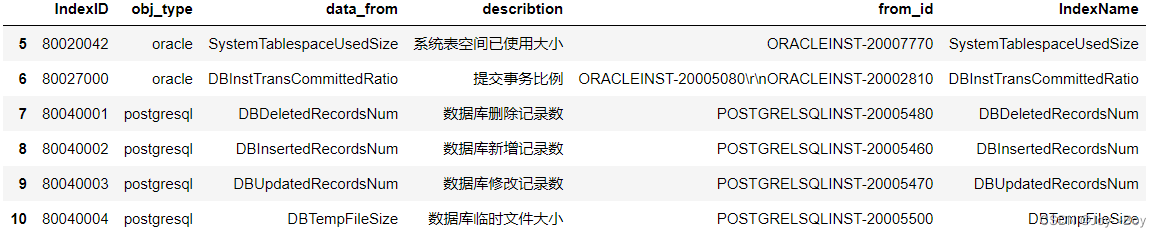
4、如果行表达式与类表达式都存在。如df.loc[n:m, cn:cm]
- # 5-10行,并且是obj_type-from_id,所有的数据
- df.loc[5:10, 'obj_type':'from_id']
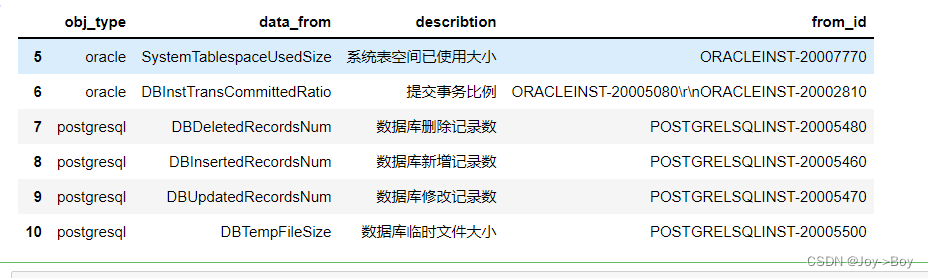
- # 5-10行,并且是obj_type与from_id,所有的数据
- df.loc[5:10, ['obj_type','from_id']]
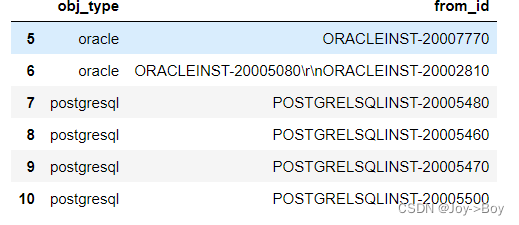
- # 5与10行,并且是obj_type与from_id,所有的数据
- df.loc[[5,10], ['obj_type','from_id']]

三、.iloc的基本操作
1、切片的方式
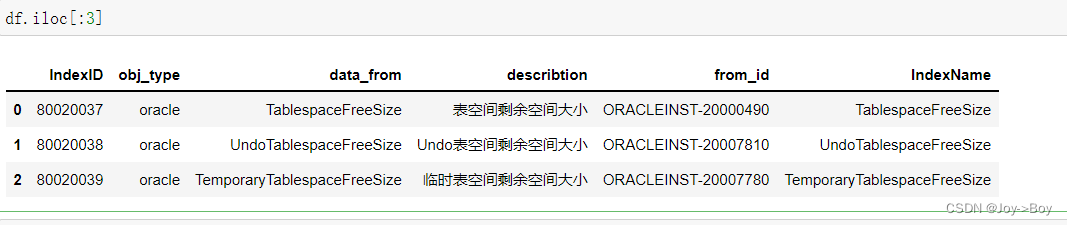
- # 前三行
- df.iloc[:3]
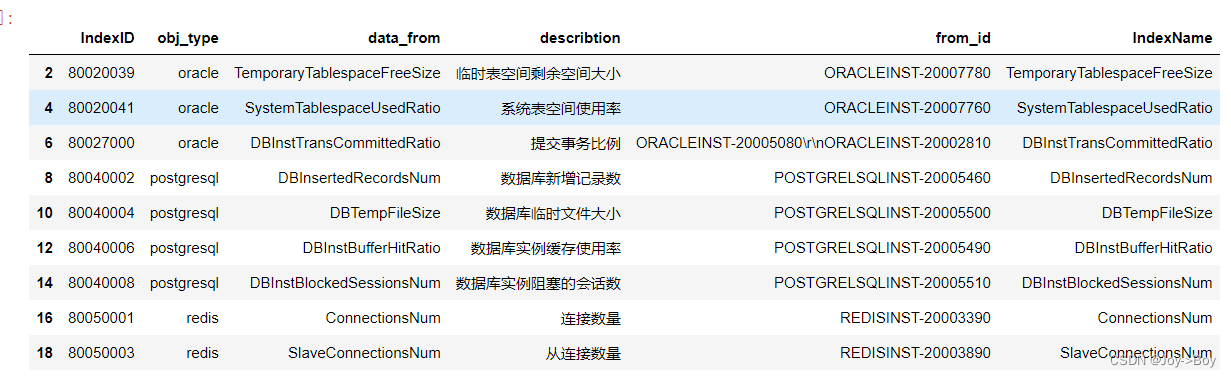
- # 2-20,步长是2,2可以取到,20取不到
- df.iloc[2:20:2]
- # 表达式含义,前三行的, 1,2列==前两列
- df.iloc[:3, [0, 1]]

-
相关阅读:
利用Linux中的iptables进行网络代理配置
如何解决pc端屏幕显示缩放比例125%,150%对页面布局的影响
MyBatis关联关系映射详解
Oracle两个日期都存在返回最小/最大的,如果只存在一个就返回存在的日期
安装Mycat-web
SpringBoot 全局请求拦截
快速在线安装MySQL
夏季,糖友需要注意些什么
图解系统(五)——文件系统02
2023-11-08 LeetCode每日一题(最长平衡子字符串)
- 原文地址:https://blog.csdn.net/qq_42336581/article/details/128033912