-
数据结构学习笔记——查找算法
查找可大致分为线性查找、树形查找和散列查找三种。
一、查找的相关概念
(一)内查找和外查找
整个查找过程完全在内存中进行,则称为内查找;若在查找的过程中需要访问外存,则称为外查找,以下的查找算法都是内查找。
(二)静态查找和动态查找
查找某个特定元素是否在表中和它的相关属性称为
静态查找;若在查找过程中需要插入或删除查找表的元素,则为动态查找,另外,散列查找既适用于静态查找,也适用于动态查找,具体的查找算法分类如下表:分类 名称 备注 静态查找 顺序查找、折半查找(二分查找)、分块查找、散列查找 分块查找是由折半查找和顺序查找的一种改进方法 动态查找 二叉排序树、二叉平衡树、B树、B+树、散列查找 二叉平衡树、B树、B+树都是二叉排序树的改进方法 (三)平均查找长度
1、平均查找长度的定义
对于一个长度为n的查找表,Pi为查找第i个元素的概率,一般假设每个元素被查找到的概率相等,即等概率Pi=1/n,Ci为查找第i个元素所需的关键字对比次数,整个查找过程中进行关键字的比较次数的平均值称为平均查找长度(ASL),即ASL=P1C1+P1C2+……+PnCn。
2、平均查找长度的作用
平均查找长度(ASL)是衡量查找算法效率的最主要指标。二、线性查找
(一)顺序查找
1、查找思想
顺序查找是一种简单的查找算法,它从线性表的一端开始,依次检查所给定的关键字是否满足条件,若找到符合条件的元素,则查找成功,否则查找失败。算法中采用监视哨,即将数组r[]下标为0的位置空出来作为监视哨,数据元素从数组下标为1至n存放,然后从后向前,即顺序表的最后一个元素开始,依次进行比较。
#define MAXSIZE 100 typedef struct { int data; } SearchL; /*顺序查找*/ int SeqSearch(SearchL r[],int n,int k) { int i=n; r[0].data=k; //r[0]为监视哨 while(r[i].data!=k) i--; return i; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2、算法分析
(1)适用性:由于线性表有顺序存储和链式存储两种存储方式,顺序查找对这两种存储方式都适用,若对于顺序表,则通过数组的下标依次查找;对于链表,则通过指针依次查找,在链表中只能进行顺序查找。
(2)关键字比较次数:查找成功或不成功,关键字的比较次数始终是n+1次,当定位至第i个元素时,关键字的比较次数为n-i+1。由于这里采用监视哨(哨兵)的程序代码,若不采用监视哨,关键字的比较次数为n。
(3)平均查找长度:ASL成功=(n+1)/2,ASL不成功=n+1。
(4)时间复杂度:顺序查找的时间复杂度为O(n)。
(5)优缺点:顺序查找的优点是对元素的存储没有要求,可以顺序存储和链式存储,且对表内的有序性也没有要求;其缺点是当n较大时,ASL较大,导致效率低。3、有序表的顺序查找
若在查找前已知查找表是有序的,则在查找失败时可以不用比较接下来的比较操作,从而直接返回查找失败,进而降低顺序查找失败的平均查找长度ASL不成功。可以将有序表的顺序查找过程比喻成一棵二叉树,查找成功结点的查找长度为该所在层数,查找失败结点的查找长度为该结点的父节点所在层数。
在有序表的顺序查找中,查找成功的ASL与一般的表一样,而查找失败时,有序表的ASL=n/2+n/n+1,它的效率较好于一般的表的顺序查找。(二)二分查找(折半查找)
1、查找思想
二分(折半)查找要求线性表必须采用顺序存储结构,且表中元素按关键字有序排列,每次取中间元素进行比较,一直缩小范围继续进行查找,直到查找到相关元素为止,找到即查找成功;否则,查找失败。
#define MAXSIZE 100 typedef struct { int data; } SearchL; /*折半查找*/ int BinSearch(SearchL r[],int n,int k) { int low,high,mid; low=1; high=n; while(low<=high) { mid=(low+high)/2; if(k==r[mid].data) return mid; else if(k<r[mid].data) high=mid-1; //在中间元素的左半区间查找,即low至mid-1 else low=mid+1; //在中间元素的右半区间查找,即low至mid+1 } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
其基本步骤如下(设查找表有n个元素):
(1)初始查找范围,置初始变量范围,low=1,high=n;
(2)取中间元素,即mid=⌊(low+high)/2⌋(向下取整,取比它小的最大整数);
(3)将指定查找的关键字与中间元素进行比较,若相等,则表示查找成功,查找的元素即为mid指向的位置;若不相等,根据大于还是小于中间元素,选择中间元素的另一边元素继续进行比较:
①若查找关键字小于中间元素,low不变,high变为mid-1;
②若查找关键字大于中间元素,high不变,low变为mid+1。
(4)重复以上(2)、(3)步骤,直到查找成功或查找范围超出(low>high)为止。例如,以有序序列{-7,-2,0,1,3,4,5,9},采用折半查找元素0和6的过程。
1、查找元素0的过程(k=0):
(1)令low=1,high=8,所以mid=(1+8)/2=4;
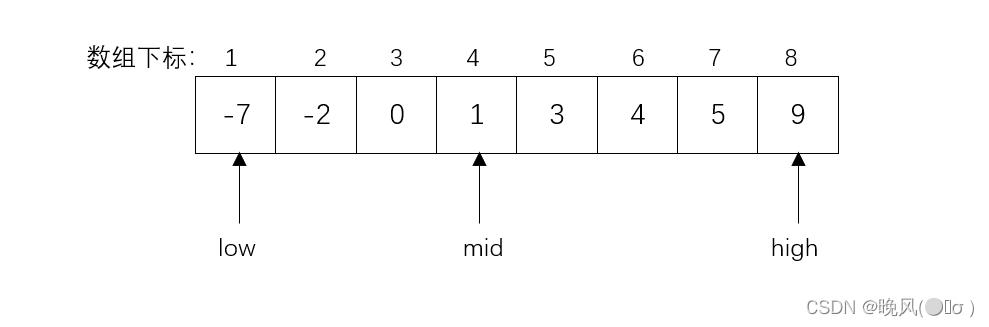
(2)此时mid=4,k=0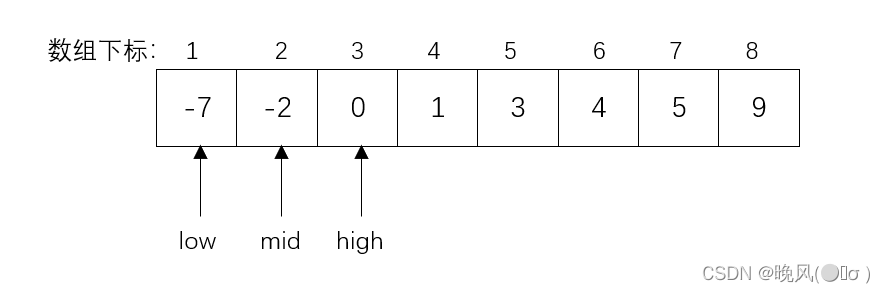
(4)此时mid=2,k=0>r[mid]=-2,查找关键字大于中间元素,high=3不变,low变为mid+1,即low=mid+1=2+1=3,mid=(low+high)/2=(3+3)/2=3。
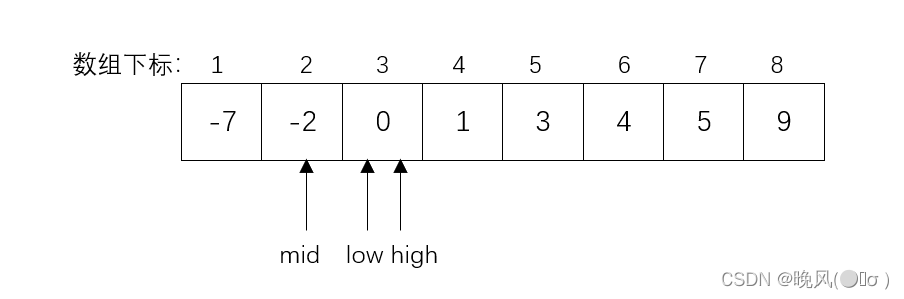
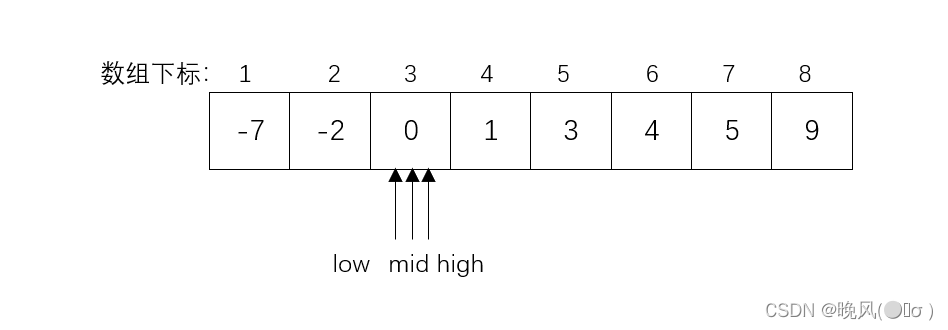
(5)此时k=r[mid]=0,查找成功。
2、查找元素6的过程(k=6):
(1)令low=1,high=8,所以mid=(1+8)/2=4;
(2)此时mid=4,k=6>r[mid]=1,查找关键字大于中间元素,high=8不变,low变为mid+1,,即low=mid+1=4+1=5,mid=(low+high)/2=(5+8)/2=6。
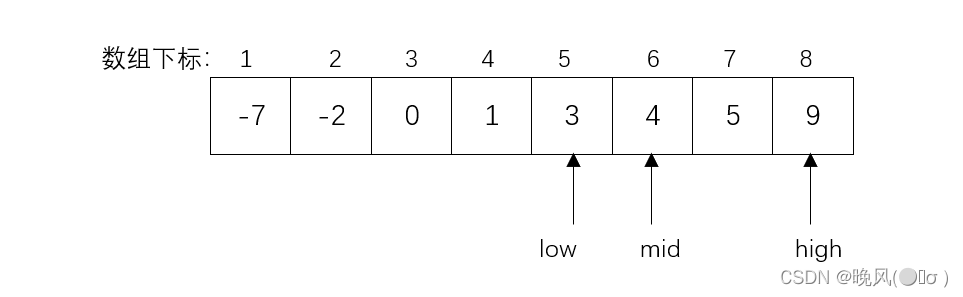
(3)此时mid=6,k=6>r[mid]=4,查找关键字大于中间元素,high=8不变,low变为mid+1,,即low=mid+1=6+1=7,mid=(low+high)/2=(7+8)/2=7。
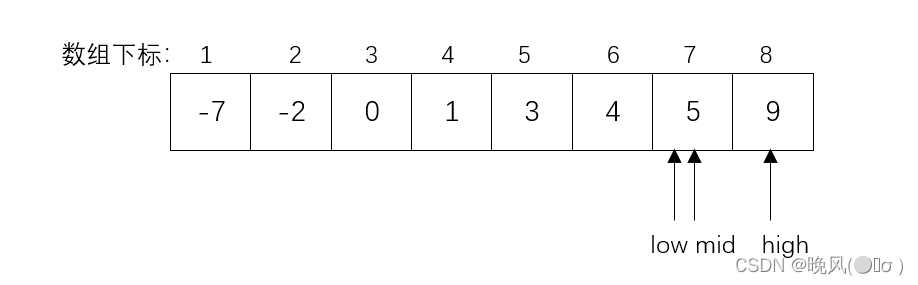
(4)此时mid=7,k=6>r[mid]=5,查找关键字大于中间元素,high=8不变,low变为mid+1,,即low=mid+1=7+1=8,mid=(low+high)/2=(8+8)/2=8。
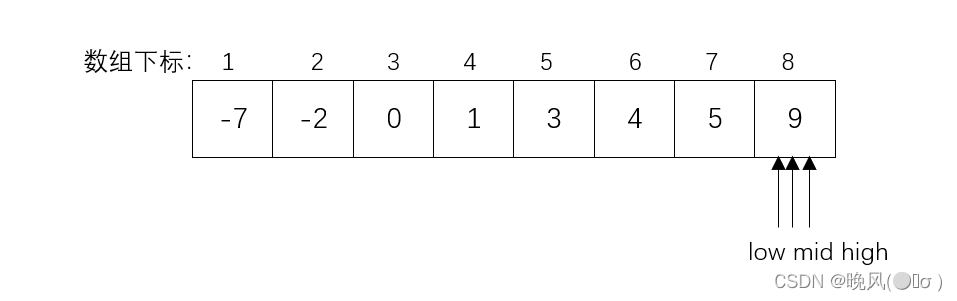
(5)此时mid=8,k=62、折半查找判定树
可以将折半查找通过一棵二叉树表示,且是一棵平衡二叉树,且它的中序遍历序列是递增的,将当前查找的中间元素mid为根结点,左子表和右子表分别作为根结点的左子树和右子树(
左<根<右):
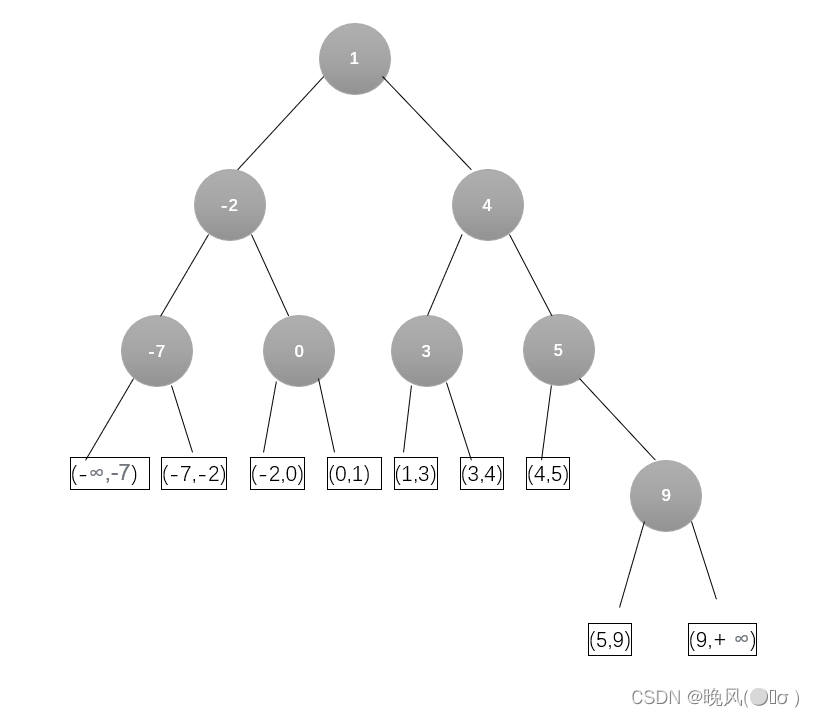
- 若有序表有n个元素,则对应的折半查找判定树中有
n个非叶子结点(圆的数量)和n+1个叶子结点(矩形的数量)。
3、算法分析
(1)适用性:折半查找只适用于有序的顺序表,它要求线性表具有随机存取,前提是查找表中必须是按关键字大小有序排列。
(2)平均查找长度:在折半判定树中,可看出其中叶子结点都为查找失败的情况,查找成功时查找长度为根结点到目的结点路径上的结点数,而查找失败时查找长度为根结点到对应失败结点的父结点路径上的结点数。在等概率条件下,ASL成功等于每层层数乘以每层非叶子结点数之和除以非叶子结点数(非叶子结点数为n),而ASL不成功等于叶子结点的父结点层数乘以每层叶子结点数之和除以叶子结点数(叶子结点数为n+1)。例如,上述的折半判定树中,在等概率条件下:
A S L 成功 = ( 1 × 1 + 2 × 2 + 3 × 4 + 4 × 1 ) 8 = 21 8 ASL_{成功}=\frac{(1\times1+2\times2+3\times4+4\times1 )}{8}=\frac{21}{8} ASL成功=8(1×1+2×2+3×4+4×1)=821
A S L 成功 = ( 3 × 7 + 4 × 2 ) 9 = 29 9 ASL_{成功}=\frac{(3\times7+4\times2 )}{9}=\frac{29}{9} ASL成功=9(3×7+4×2)=929
(3)比较次数:对于折半查找,查找成功和查找失败的最多比较次数相同,均为⌈log2(n+1)⌉,由于折半判定树不是一棵满二叉树,其各分支高度相差为0或1,且由于最多相差为1,所以查找失败的最少次数为⌈log2(n+1)⌉-1。已知一个长度为16的顺序表L,其元素按关键字有序排列,若采用折半查找法查找一个L中不存在的元素,则关键字的比较次数最多是__________,最少是__________。
查找成功和查找失败的最多比较次数相同,均为⌈log2(n+1)⌉=⌈log217⌉=5,查找失败的最少次数相差为1,即5-1=4。
(4)时间复杂度:在折半判定树中,比较次数最多不会超过树的高度h=⌈log2(n+1)⌉,即折半查找的时间复杂度为O(log2n)。
(5)优点:在平均情况下,折半查找比顺序查找的效率高。例如,设有序顺序表中的元素依次为017,094,154,170,275,503,509,512,553,612,677,765,897,908,试画出对其进行折半查找的判定树,若要查找元素275和684,求其比较次数,并计算折半查找成功的平均搜索长度和搜索不成功的平均搜索长度。
1、对017~908共14个元素进行编号,即有序表中的元素下标为r[1,14]。
2、low=1,high=14,所以mid=(low+high)/2=15/2=7,所以这棵判定树的根结点为下标mid=7的元素:
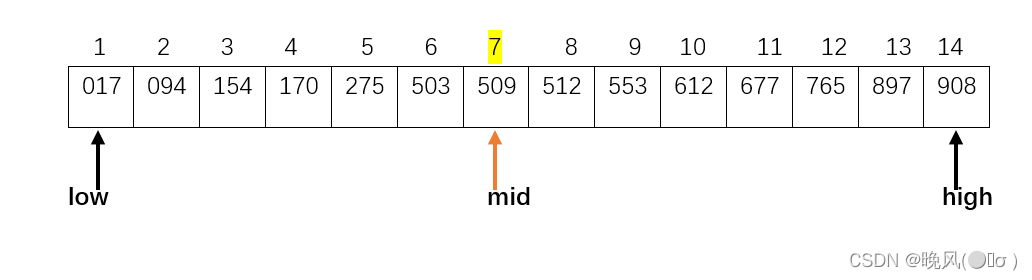
3、从mid左右子表开始进行查找。
(1)左子表查找:
①此时low=1不变,high变为mid-1,即high=mid-1=7-1=6,改变后的mid=(low+high)/2=7/2=3,所以根结点509的左子树为下标mid=3的元素,即r[3]=154;

继续左子树,low=1不变,high变为mid-1,即high=mid-1=3-1=2,改变后的mid=(low+high)/2=3/2=1,r[mid]=r[1]=017,所以结点154为017的父节点,017无左子树。

继续右子树,此时high=2不变,low变为mid+1,即low=mid+1=1+1=2,改变后的mid=(low+high)/2=4/2=2,r[mid]=r[2]=094,所以017的右子树为094。

②若在查找154后的下一步查找操作中,查找元素大于154,此时相当于查找154的右子树,此时high=6不变,low变为mid+1,即low=mid+1=3+1=4,改变后的mid=(low+high)/2=10/2=5,所以154的右子树为下标mid=5的元素,即r[5]=275;
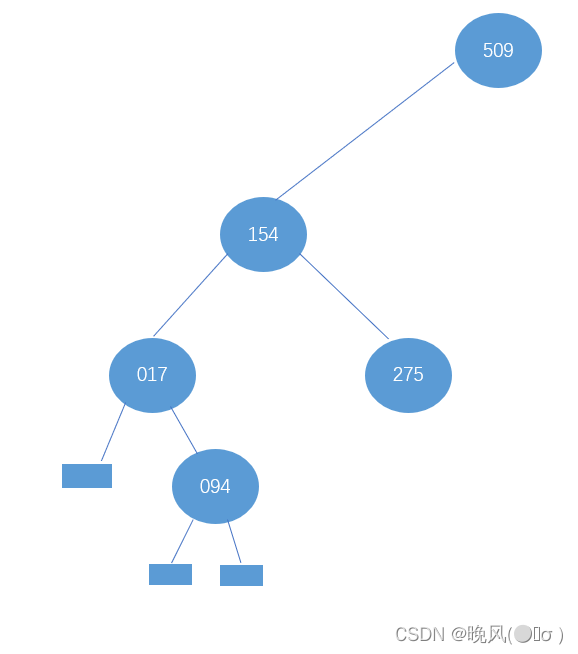
通过顺序表序列可知275的左右还有查找元素,继续操作:
继续查找275的左、右子树,依然是不同的方向,得到mid=4和mid=6,即r[4]=170和r[6]=503为275的左、右子树:
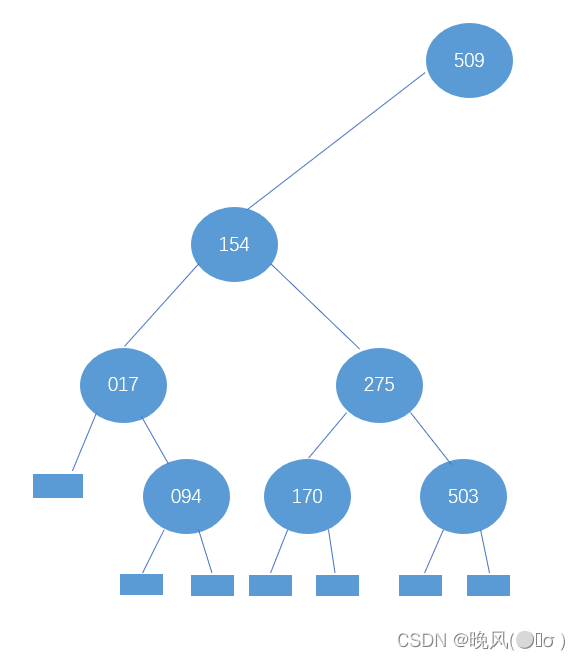
(2)右子表查找:
①此时high=14不变,low为mid+1,即low=mid+1=7+1=8,改变后的mid=(low+high)/2=22/2=11,所以根结点509的右子树为下标mid=11的元素,即r[11]=677;
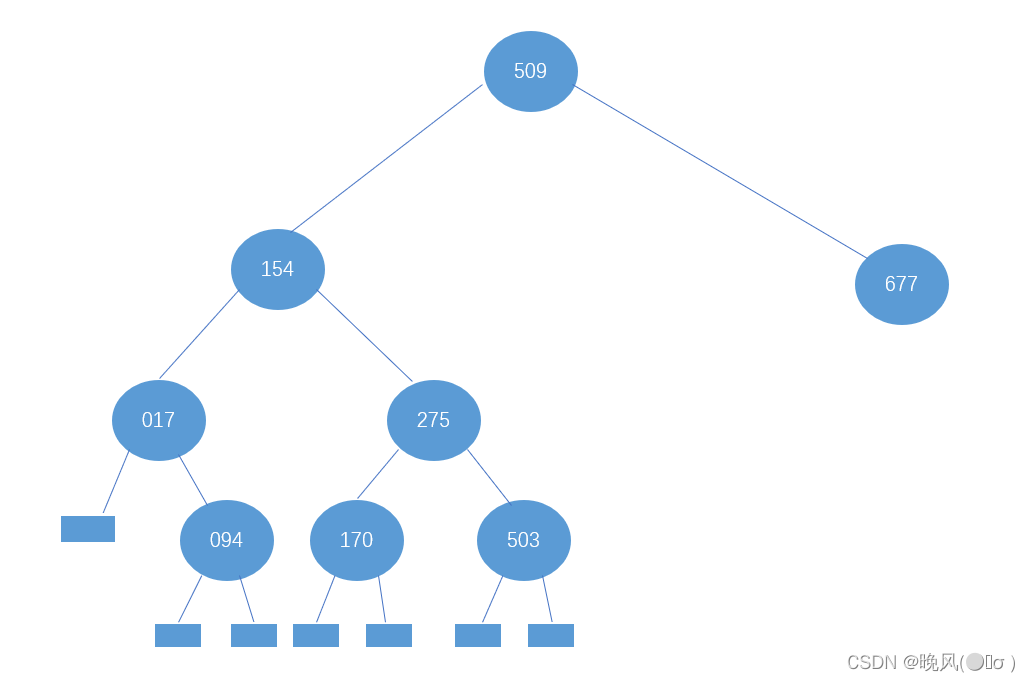
继续677的左子树,low=8不变,high变为mid-1,即high=mid-1=11-1=10,改变后的mid=(low+high)/2=18/2=9,r[mid]=r[9]=553,所以结点553为677的左子树。
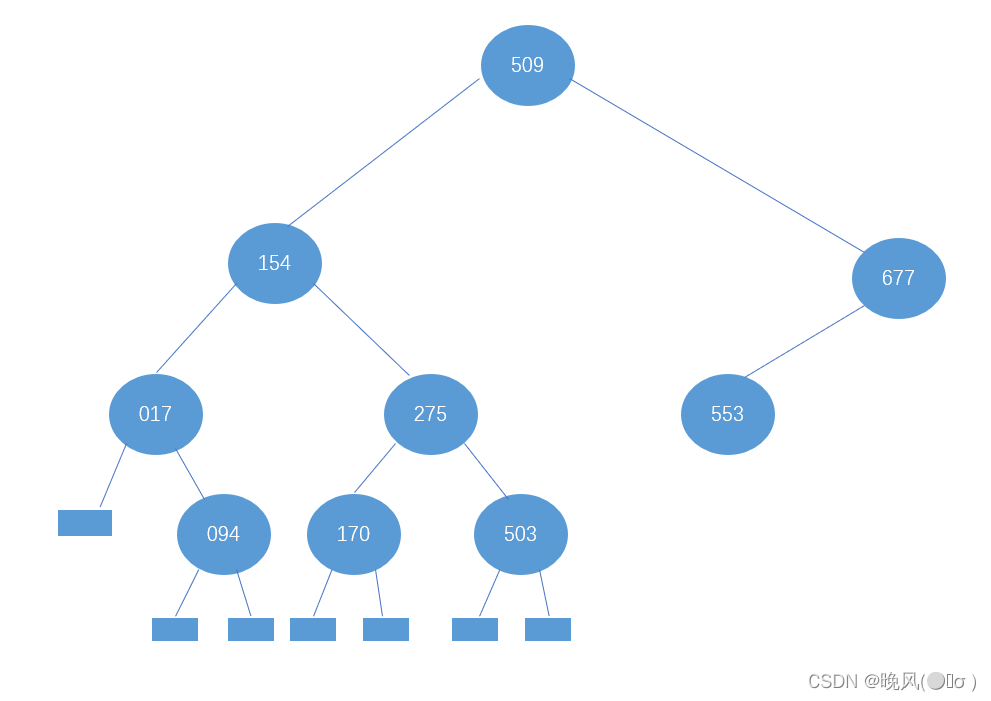
通过顺序表序列可知553的左右还有查找元素,继续操作:
继续553的左子树,low=8不变,high变为mid-1,即high=mid-1=10-1=9,改变后的mid=(low+high)/2=17/2=8,r[mid]=r[8]=512,所以结点512为553的左子树。
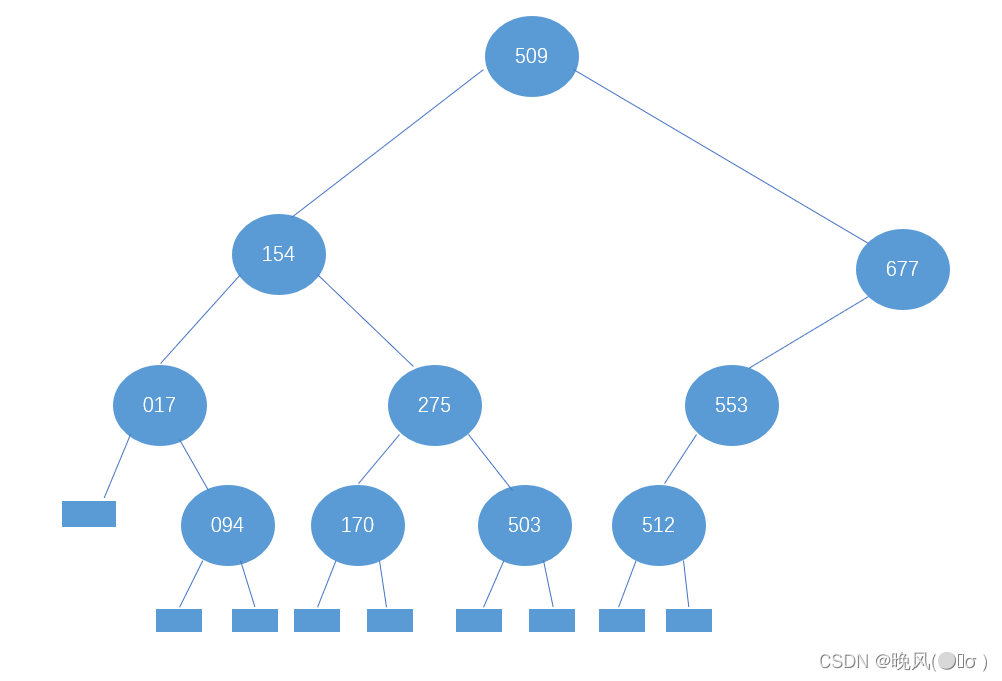
回到上一步,继续553的右子树,此时high=10不变,low变为mid+1,即low=mid+1=9+1=10,改变后的mid=(low+high)/2=20/2=10,r[mid]=r[10]=612,所以553的右子树为612。
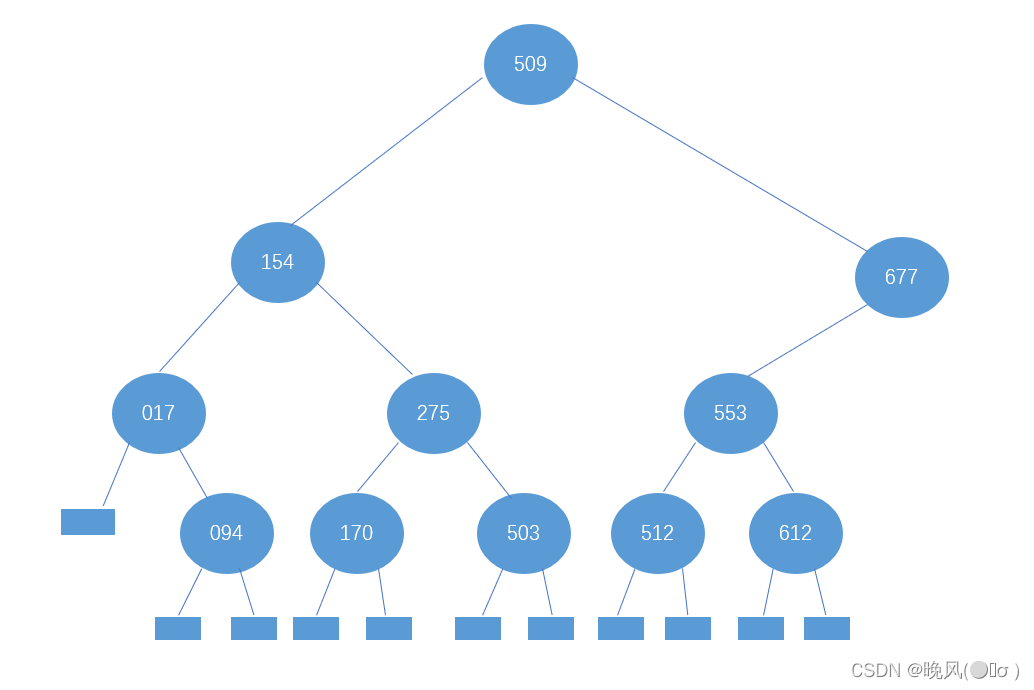
②若在查找677后的下一步查找操作中,查找元素大于677,此时相当于查找677的右子树,此时high=14不变,low变为mid+1,即low=mid+1=11+1=12,改变后的mid=(low+high)/2=26/2=13,所以677的右子树为下标mid=13的元素,即r[13]=897。
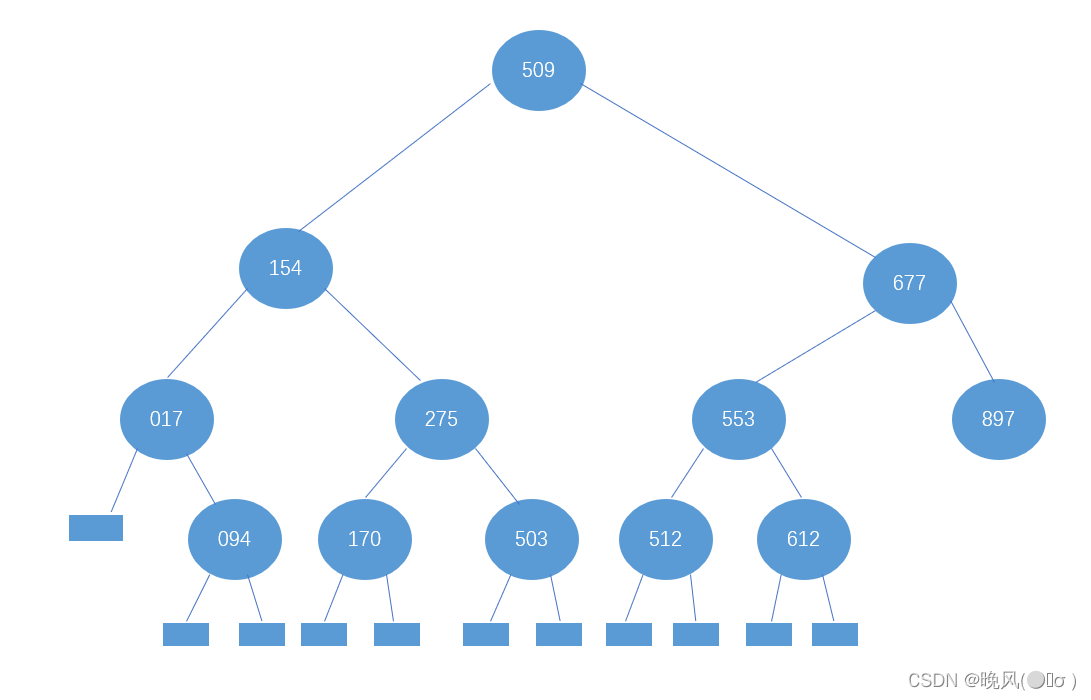
继续查找897的左、右子树,依然是不同的方向,low=12,high=mid-1=13-1=12,mid=(12+12)/2=12;high=14,low=mid+1=13+1=14,mid=(14+14)/2=14,可得到r[12]=765和r[14]=908为897的左、右子树。
至此,判定树建立完成:
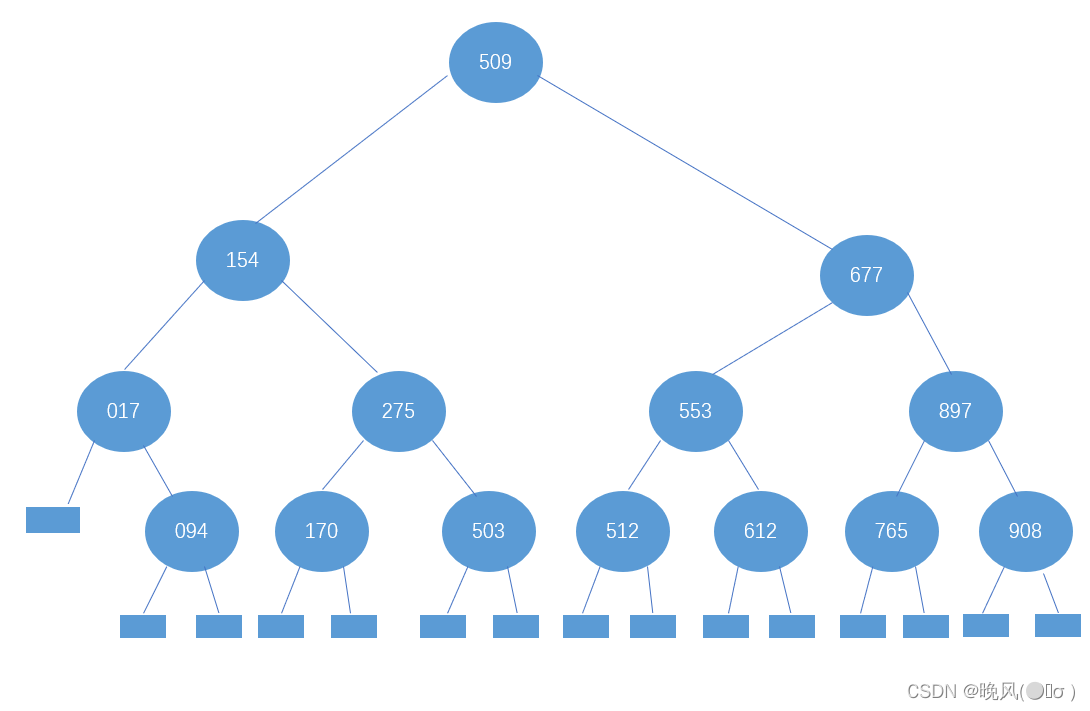
4、比较次数
由判定树可知,若要查找元素275,首先与509比较,比较次数为1次,275<509,所以与509的左子树154比较,比较次数为2次,由于275等于154的右子树,比较次数为3次,查找成功,所以查找元素275的总比较次数为3次;若要查找元素684,首先与509比较,比较次数为1次,684>509,所以与509的右子树677比较,比较次数为2次,由于684>677,所以与677的右子树897比较,比较次数为3次,684<897,所以与897的左子树765进行比较,比较次数为4次。
5、平均查找长度
ASL成功=(1×1+2×2+3×4+4×7)/14=45/14,
ASL不成功=(3×1+4×14)/15=59/15。(三)分块查找
1、查找思想
分块查找也称为索引顺序查找,它将查找表分为若干块,要求每个块内可以无序,但块间是必须有序的,即上一块的最大关键字大于或小于后一块中的最小或最大关键字值。
另外,还需建立一个索引表,索引表内是按关键字排列有序的,索引表中的一项对应线性表的一块,索引表内由关键字域和指针域组成,前者存放该块内的最大关键字,后者存放指向该块中第一个和最后一个元素的指针(数组下标值)。例如,关键字序列为{2,4,0,9,12,-6,5,7,1,8},其分块索引和索引表如下,分为了5个块和索引表:
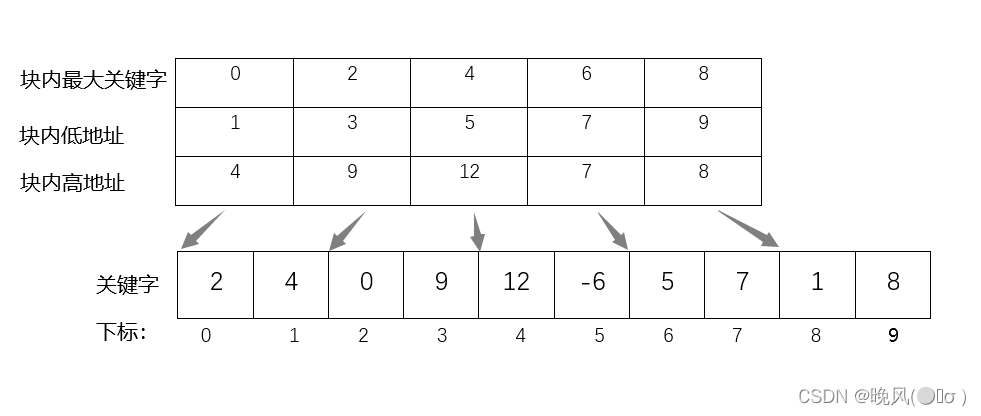
2、分析
(1)有序性:在分块查找中,块内无序,块间有序。
(2)适用性:分块查找适用于顺序存储结构和链式存储结构的线性表。
(2)平均查找长度:分块查找的平均查找长度等于索引查找和块内查找的平均查找长度之和,即ASL=ASL索引表+ASL子表。若查找表长度为n,被均匀地分为b块,且每块有s个记录,则在等概率的情况下,若对块内和索引表内都采用顺序查找的平均查找长度为:ASL=ASL索引表+ASL子表=(b+1)/2+(s+1)/2=(s2+2s+n)/2s,且每块有记录为s= √n;若对块内采用顺序查找,对索引表内采用折半查找,则平均查找长度为:ASL=ASL索引表+ASL子表=⌈log2(b+1)⌉+(s+1)/2;而对索引表和块内都采用折半查找时,查找效率最高,则平均查找长度为:ASL=ASL索引表+ASL子表=⌈log2(b+1)⌉+⌈log2(b+1)⌉=2⌈log2(b+1)⌉。为提高查找效率,对有65025个元素的有序顺序表建立索引顺序结构,在最好情况下查找到表中已有元素最多需要执行________次关键字的比较。
每个索引块的大小为 √65025=255,为每个块建立索引,索引表中索引项的个数为255,在对索引表和块内都采用折半查找时,查找效率最高,即ASL=ASL索引表+ASL子表=2⌈log2(b+1)⌉=2×8=16。
(3)时间复杂度:若n个元素被分为m块,则通过分块查找的时间复杂度为O(log2m+n/m)。
(4)优点:插入和删除的操作非常方便,不需要移动大量的元素。三、散列查找(哈希查找)
(一)散列的概念
将关键字按照其散列地址存储到散列表(哈希表)中的过程称为散列。
(二)哈希函数
通过在记录的存储位置和关键字之间建立一个确定的对应关系H,当查找给定值为k的记录时,通过该关系得到给定值k可能对应的位置H(k)进行判断,即称为散列查找(哈希查找),哈希查找的核心是哈希函数,它是将关键值映射到查找表中的对应地址的函数,元素的关键字与其存储地址是直接相关的。
(三)同义词与冲突
若哈希函数为H(k),若ki≠kj,但H(ki)=H(kj),则称发生了
冲突,且称ki与kj对H(k)是同义词,即两个不同的关键字可能被哈希函数散列到同一个地址的情况则称为冲突。一个好的哈希函数可以减小冲突,但不可能避免冲突,若一个哈希函数能够使每一个关键字散列到哈希表中任何一个的概率相同,则为均匀哈希函数,可以最大限度地减少冲突。(四)哈希函数的构造原则
(1)构造的哈希函数便于计算,能在较短时间内得到任一关键字对应的散列地址;
(2)哈希函数的定义域需包含所有要存储的关键字,值域的范围依赖于散列表的大小或地址范围;
(3)根据哈希函数计算出的地址应该能够等概率、均匀地分布于整个地址空间中,从而减小冲突的发生;(五)哈希函数的构造方法
不同的哈希函数具有不同的性能,在实际选择中,采用哪种哈希函数取决于关键字集合的情况,其目标都是为了尽量降低冲突的可能性。
1、直接定址法
(1)概念
直接定址法中直接利用关键字求得哈希地址,例如H(ki)=ki或H(ki)=a×ki+b,其中a、b为常数,在使用时,为了使哈希地址与存储空间相符合,可以调整a、b的值。
(2)分析
①直接定址法的特点是构造哈希函数简单,且对于不同的关键字,由于是直接通过关键字得到的,所以不会产生冲突。
②在实际问题中,很少遇到关键字集合中元素是连续的,所以若仍应用该方法的应用会导致所创建的哈希表空间浪费。2、除留余数法
(1)概念
设哈希表的表长为m,取一个小于或等于m的最大质数p(除1以及自身以外不可被整除),通过公式H(ki)=k%p,通过取余运算得到的余数作为哈希地址。
(2)分析
除留余数法所创建的哈希函数的好坏取决于p的选取,p的选取可以使每个关键字通过该哈希函数转换后等概率地映射到存储地址上的任一地址上,从而减少冲突的可能性,当p小于哈希表表长m的某个质数时,所得到的哈希函数较好。3、数字分析法
(1)概念
对于知道关键字集合,且每个关键字的位数比哈希表的地址码位数多时,可以从关键字中选出分布较为均匀的若干位,从而构成哈希地址。
(2)分析
只适用于已知关键字集合,若更换关键字,则需重新构造哈希函数。4、平方取中法
(1)概念
根据哈希表的长度和关键字的位数,取关键字的平方得到的值中间几位作为哈希地址,由于一个数的平方后的中间几位数与该数的每一位都有关,所以这样得到的哈希地址的随机性大,且所得到的哈希地址分布较均匀。
(2)分析
适合于关键字集合未知的情况。5、折叠法
(1)概念
将关键字按相等的位数分段(最后一段的位数可以不等),然后取所有段的叠加之和作为哈希地址,叠加的方法有两种:一是移位叠加,将每一段的最低位对齐后相加;二是分界叠加,按照分界线对齐后叠加。
(2)分析
对于关键字位数多、分布均匀,而哈希地址范围有限的情况下,采用折叠法合适。(六)处理冲突
1、开放定址法
若出现冲突,以哈希地址p=H(ki)为基准,产生另一个哈希地址p1,若仍然冲突,再以哈希地址p=H(ki)为基准产生另一个哈希地址,直到不冲突的哈希地址为止,然后将相应的元素存放其中。
(1)线性探测法
若哈希表的表长为m,di=0,1,2,……,m-1为增量序列,当冲突发生时,根据以下公式解决冲突:

H=(H(ki)+di)%m,顺序查看表中的下一个单元,每次往后探测相邻的下一个单元是否为空,直至找到一个空闲单元或查遍全表。线性探测法可能使第i个哈希地址的同义词存入第i+1个哈希地址中,这样导致本应存入第i+1个哈希地址的元素争夺第i+2个哈希地址的元素的地址,……,从而造成大量元素中相邻散列地址上聚集的情况,大大降低查找效率,这里的聚集原因是同义词之间或非同义词之间发生冲突。
例如,对一组关键字{5,31,18,24,27,15,2,3,16,4}构造哈希表,已知哈希表表长为13,地址范围为0~12,设哈希函数为:H(k)=ki%13,通过线性探测法解决冲突,建立相应的哈希表,并求出在等概率情况下,查找成功和查找失败的平均查找长度。
①首先将关键字值代入到哈希函数中求得哈希地址:
H(5)=5%13=5,发生冲突次数为0;散列地址 0 1 2 3 4 5 6 7 8 9 10 11 12 关键字 5 冲突次数 0 由于H(31)=31%13=5,出现冲突,进行处理,m=13,增量序列di=1,所以H31=(H(ki)+di)%m=(H(31)+d1)%13=(5+1)%13=6,发生冲突次数为1;
散列地址 0 1 2 3 4 5 6 7 8 9 10 11 12 关键字 5 31 冲突次数 0 1 由于H(18)=18%13=5,出现冲突,进行处理,m=13,增量序列di=1,所以H31=(H(ki)+di)%m=(H(18)+d1)%13=(5+1)%13=6,仍冲突,继续进行处理,H31=(H(ki)+di)%m=(H(18)+d2)%13=(5+2)%13=7,发生冲突次数为2;
散列地址 0 1 2 3 4 5 6 7 8 9 10 11 12 关键字 5 31 18 冲突次数 0 1 2 H(24)=24%13=11,发生冲突次数为0;
散列地址 0 1 2 3 4 5 6 7 8 9 10 11 12 关键字 5 31 18 24 冲突次数 0 1 2 0 H(27)=27%13=1,发生冲突次数为0;
散列地址 0 1 2 3 4 5 6 7 8 9 10 11 12 关键字 27 5 31 18 24 冲突次数 0 0 1 2 0 H(15)=15%13=2,发生冲突次数为0;
散列地址 0 1 2 3 4 5 6 7 8 9 10 11 12 关键字 27 15 5 31 18 24 冲突次数 0 0 0 1 2 0 由于H(2)=2%13=2,出现冲突,进行处理,m=13,增量序列di=1,所以H2=(H(ki)+di)%m=(H(2)+d1)%13=(2+1)%13=3,发生冲突次数为1;
散列地址 0 1 2 3 4 5 6 7 8 9 10 11 12 关键字 27 15 2 5 31 18 24 冲突次数 0 0 1 0 1 2 0 由于H(3)=3%13=3,出现冲突,进行处理,m=13,增量序列di=1,所以H3=(H(ki)+di)%m=(H(3)+d1)%13=(3+1)%13=4,发生冲突次数为1;
散列地址 0 1 2 3 4 5 6 7 8 9 10 11 12 关键字 27 15 2 3 5 31 18 24 冲突次数 0 0 1 1 0 1 2 0 由于H(16)=3%13=3,出现冲突,进行处理,m=13,增量序列di=1,所以H3=(H(ki)+di)%m=(H(16)+d1)%13=(3+1)%13=4,仍发生冲突,继续处理,H3=(H(ki)+di)%m=(H(16)+d2)%13=(3+2)%13=5,仍发生冲突,继续处理,H3=(H(ki)+di)%m=(H(16)+d3)%13=(3+3)%13=6,仍发生冲突,继续处理,H3=(H(ki)+di)%m=(H(16)+d4)%13=(3+4)%13=7,仍发生冲突,继续处理,H3=(H(ki)+di)%m=(H(16)+d5)%13=(3+5)%13=8,
不发生冲突结束,发生冲突次数为5;散列地址 0 1 2 3 4 5 6 7 8 9 10 11 12 关键字 27 15 2 3 5 31 18 16 24 冲突次数 0 0 1 1 0 1 2 5 0 由于H(4)=4%13=4,出现冲突,进行处理,……,同样也冲突5次。
最终,得到的哈希表如下:散列地址 0 1 2 3 4 5 6 7 8 9 10 11 12 关键字 27 15 2 3 5 31 18 16 4 24 冲突次数 0 0 1 1 0 1 2 5 5 0 ②求在等概率情况下,查找成功和查找失败的平均查找长度:
A S L 成功 = ( 1 + 1 + 2 + 2 + 1 + 2 + 3 + 6 + 6 + 1 ) 10 = 25 10 = 5 2 ASL_{成功}=\frac{(1+1+2+2+1+2+3+6+6+1)}{10}=\frac{25}{10} =\frac{5}{2} ASL成功=10(1+1+2+2+1+2+3+6+6+1)=1025=25
A S L 失败 = ( 1 + 10 + 9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1 + 2 + 1 ) 13 = 59 13 ASL_{失败}=\frac{(1+10+9+8+7+6+5+4+3+2+1+2+1)}{13}=\frac{59}{13} ASL失败=13(1+10+9+8+7+6+5+4+3+2+1+2+1)=1359(2)平方探测法
对于公式H=(H(ki)+di)%m,若取增量序列di=0,12,-12,22,-22,……,k2,-k2时,该方法称为平方探测法,也称为二次探测法,其中要求k≤m/2,且哈希表长度m必须是某个4k+3的质数。
(3)双散列法
双散列法是采用两个哈希函数,对于公式H=(H(ki)+di)%m,若取增量序列di=H2(i),该方法称为双散列法。当通过第一个哈希函数得到的哈希地址发生冲突时,利用第二个哈希函数计算该关键字的增量序列di),若设冲突次数为i,则公式为H=(H(ki)+i×H2(i))%m。
(4)伪随机序列法
对于公式H=(H(ki)+di)%m,若取增量序列di为伪随机数序列时,该方法称为伪随机序列法。
2、链地址法
链地址法是为了避免同义词发生冲突,且能避免聚集情况,将所有的同义词存储在一个单链表中,哈希地址为i的同义词单链表的头指针存放在哈希表的第i个单元中,并由其哈希地址唯一标识该单链表。另外,查找、插入、删除操作都在单链表中进行。
例如,对一组关键字{16,46,32,50,70,26,42,36,24,49,64},已知哈希表长度为7,哈希函数为:H=ki%7,通过利用链地址法来解决冲突,并建立相应的哈希表,并求出在等概率情况下,查找成功和查找失败的平均查找长度。
①首先将关键字值代入到哈希函数中求得哈希地址:
H(16)=16%7=2
H(46)=46%7=4
H(32)=32%7=4
H(50)=50%7=1
H(70)=70%7=0
H(26)=26%7=5
H(42)=42%7=0
H(36)=36%7=1
H(24)=24%7=1
H(49)=49%7=0
H(64)=64%7=1
②可得到的哈希表如下:
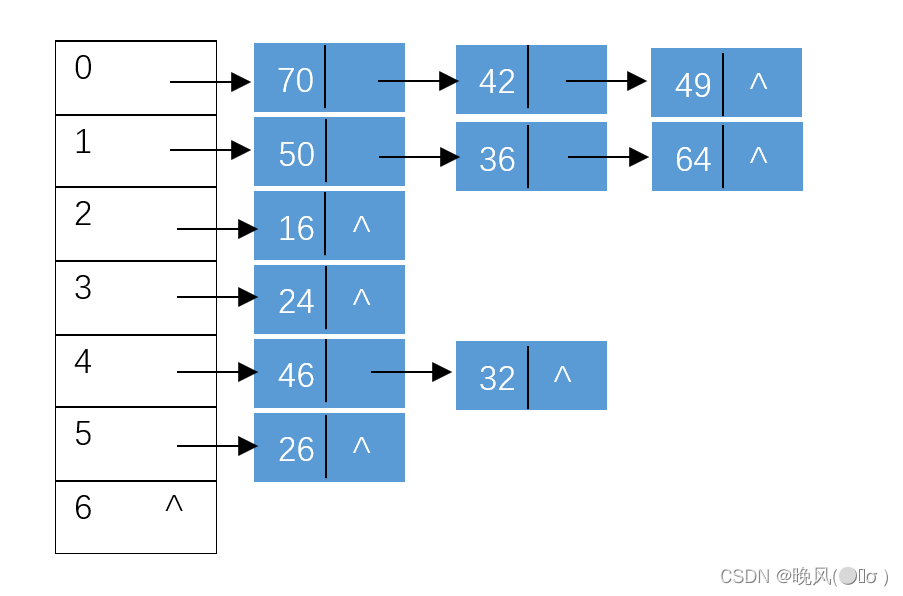
③求平均查找长度ASL:
A S L 成功 = ( 1 × 6 + 2 × 3 + 3 × 2 ) 11 = 18 11 ASL_{成功}=\frac{(1\times6+2\times3+3\times2)}{11}=\frac{18}{11} ASL成功=11(1×6+2×3+3×2)=1118
A S L 失败 = ( 3 + 3 + 1 + 1 + 2 + 1 ) 7 = 11 7 ASL_{失败}=\frac{(3+3+1+1+2+1)}{7}=\frac{11}{7} ASL失败=7(3+3+1+1+2+1)=711(七)哈希查找的性能分析
哈希表的查找效率取决于哈希函数、处理冲突的方法和装填因子α,其中装填因子α是一个表的装满程度,它等于表中记录数/哈希表长度,哈希表的平均查找长度依赖于装填因子α,而不直接依赖记录数或哈希表长度,当α越大,表示装填的记录越满,发生冲突的可能性越大,反之可能性越小。
对一组关键字序列{1,9,12,11,25,35,17,29}创建一个哈希表,装填因子α为1/2,试确定表长m,采用除留余数法构造哈希函数,并采用链地址法处理冲突,并求出在等概率情况下,查找成功和查找失败的平均查找长度。
①已知装填因子α=1/2,关键字个数n=8,m为哈希表表长,α=n/m,求得m=16。
②除留余数法构造哈希函数H(key)=key%p,取一个小于或等于m的最大质数p(除1以及自身以外不可被整除),p必须不大于表长,且尽可能使哈希地址散布地均匀,从而减少冲突,所以p取13,故哈希函数为H(key)=key%13。
③将关键字值代入到哈希函数中求得哈希地址:
H(1)=1%13=1
H(9)=9%13=9
H(12)=12%13=12
H(11)=11%13=11
H(25)=25%13=12
H(35)=35%13=9
H(17)=17%13=4
H(29)=29%13=3
④可得到的哈希表如下:
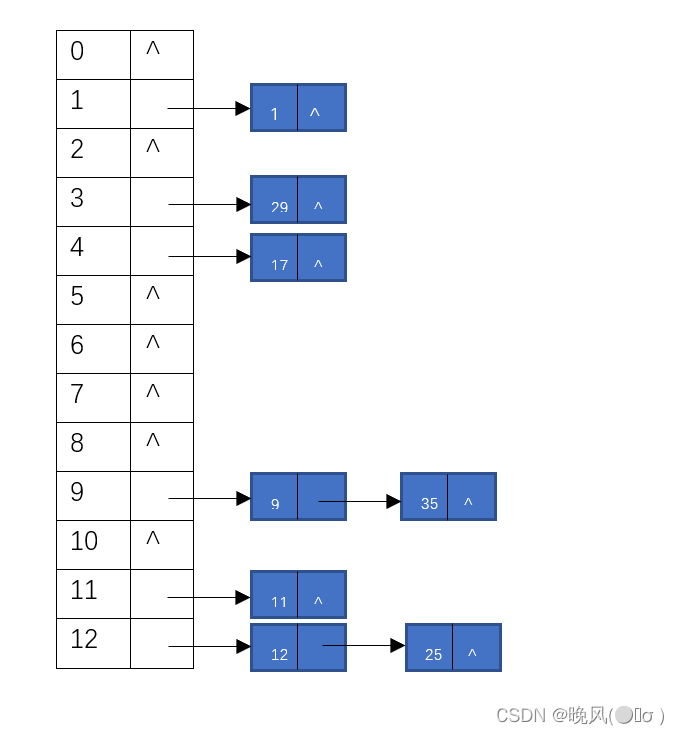
⑤求平均查找长度ASL:
A S L 成功 = ( 1 × 6 + 2 × 2 ) 8 = 10 8 = 5 4 ASL_{成功}=\frac{(1\times6+2\times2)}{8}=\frac{10}{8} =\frac{5}{4} ASL成功=8(1×6+2×2)=810=45
A S L 失败 = ( 1 + 1 + 1 + 2 + 1 + 2 ) 13 = 8 13 ASL_{失败}=\frac{(1+1+1+2+1+2)}{13}=\frac{8}{13} ASL失败=13(1+1+1+2+1+2)=138 -
相关阅读:
[项目管理-4]:软硬件项目管理 - 人月神话:项目时间管理(时间)- 概述
MAX485芯片介绍(MAX485ESA+T,半双工RS422和RS485串口收发传输芯片,2.5Mbps传输速率。5V逻辑电平)
canvas实现图片标注,绘制区域
手机和电脑通过TCP传输(一)
译码器的电路
Vite:轻量级的前端构建工具
Javaweb 自定义 Servlet 实现按照访问路径转发
Anaconda安装+Tensorflow2.0安装配置+Pycharm安装+GCN调试(Window 10)
Java基础-IO流(字节流)
CentOS7日志文件及journalctl日志查看
- 原文地址:https://blog.csdn.net/qq_43085848/article/details/127992636
