-
Linux网络--------http协议
URL—网址
首先,http协议是应用层协议, 是超文本传输协议。

urlencode : 转码
urldecode : 解码

将 ++ ---- > %2B%2B就是转码的过程
%2B%2B -----> ++ 就是解码的过程对http协议的宏观认识
我们知道:网络通信的本质是通过网络文件(fd)来盲读的
那如何保证:每次读取到的是一个完整的request , 并且读不到下一个request呢?首先: 空行 ------> 保证读完 hander, 然后 hander中有一个Content_Length来表明正文的字节大小
如果没有正文呢? ------ > 也就没有Content_Length
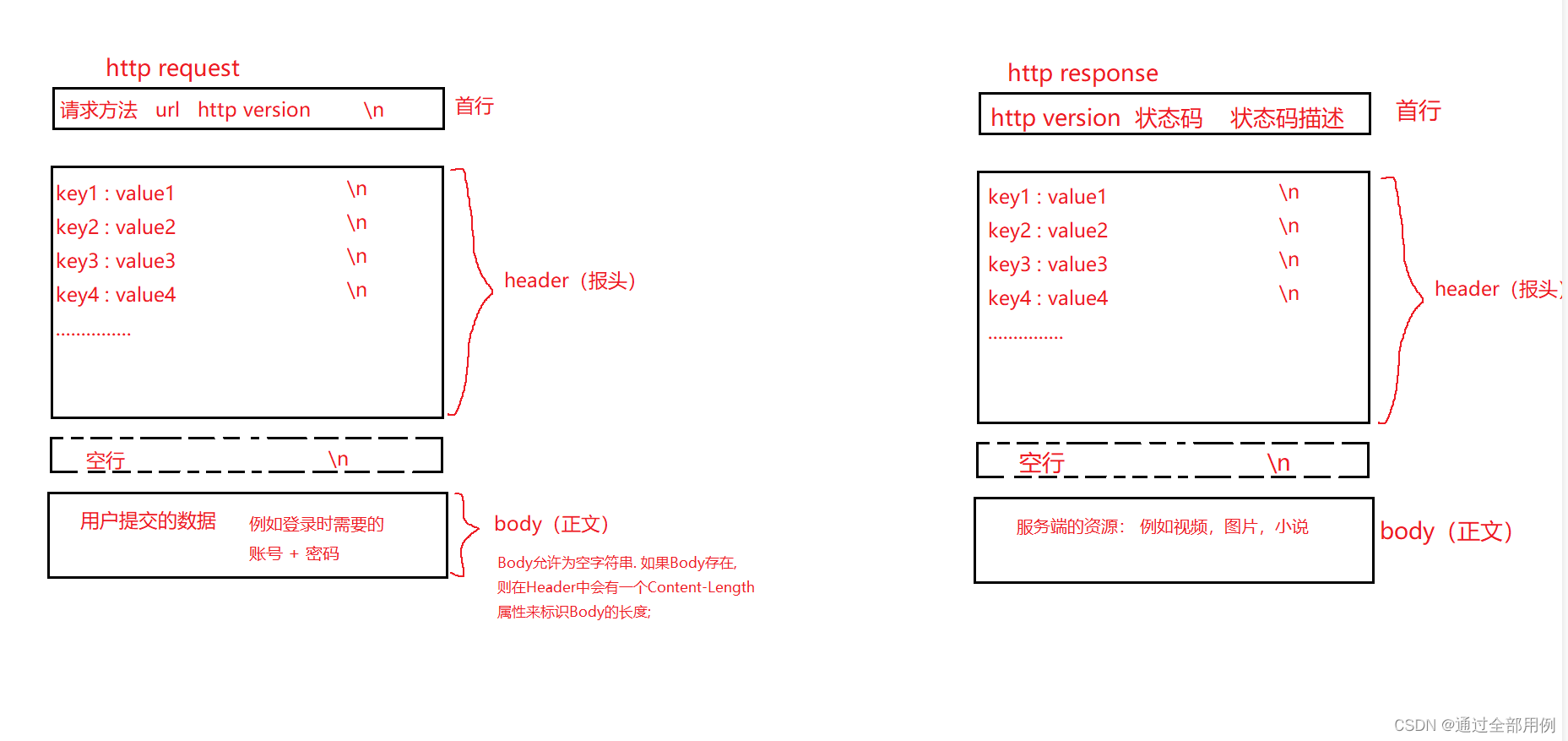
关于相关的报头属性:
Content-Type: 数据类型(text/html等)
Content-Length: Body的长度
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
User-Agent: 声明用户的操作系统和浏览器版本信息;
referer: 当前页面是从哪个页面跳转过来的;
location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;http协议的请求方法
了解主要的三个就行了。

关于HEAD方法: 只返回报头数据(header) 不会返回body(正文)部分。 没什么好说的
关于GET 和 POST方法
1,两者最主要的区别是 : 当需要提交参数的时候(输入账号 + 密码), GET方法是将参数信息放在了URL(网址中)
而POST方法是将其放入了body(正文)
2, 参数提交的位置不同,就会导致,POST方法比较私密, 不会显示参数信息了URL输入框中
3, 另外的话, URL是有大小限制的, body(正文)是无大小限制的。再度分析http协议,
如何处理呢? : 本质就是文本分析。
读取 首行 -------> 获得相关属性然后解析
读取 报头 -------> 获得相关属性然后解析
读取 正文--------> 获取相关属性然后解析http响应的状态码

3xx状态码的特殊含义:
1, 301 永久重定向
2, 302 or 307 临时重定向永久重定向: 当我们访问某一个网站的时候, 可能会让我们跳转到另一个网址
临时重定向: 当访问某种资源的时候, 提示登录,输入账号 + 密码 然后又跳转回来。最简单的http协议服务器
Sock.hpp ------> 提供各种接口 : socket() , bind(), connect(), accept(),
#include#include #include #include #include //struct sockaddr_in #include using namespace std; class Sock { public: //创建套接字, 本质是创建网络文件 static int Socket() { int sock = socket(AF_INET, SOCK_STREAM, 0); if(sock < 0) { cout << "sock error" << endl; exit(1); } return sock; } //服务端需要绑定, 客户端不需要绑定,由OS自动绑定 static void Bind(int sock, uint16_t port) { struct sockaddr_in local; local.sin_family = AF_INET; //ipv4协议 local.sin_port = htons(port); local.sin_addr.s_addr = INADDR_ANY; //链接服务器上的任意一台主机 if(bind(sock, (struct sockaddr*)&local, sizeof(local)) < 0) { cout << "bind error" << endl; exit(2); } } //服务端需要监听----监听状态 static void Listen(int sock) { if(listen(sock, 5) < 0) { cout << "listen error" << endl; exit(3); } } //服务端需要接受,新的fd实际上提供服务的文件,旧的sock是用来监听的----> "饭馆的拉客少年" static int Accept(int sock) { struct sockaddr_in peer; socklen_t len = sizeof(peer); int fd = accept(sock, (struct sockaddr*)&peer, &len); //peer是输出型参数,返回的是客户端相关属性 if(fd < 0) { cout << "accept error" << endl; exit(4); } return fd; } //客户端需要链接的是服务端 需要 ip + port static void Connect(int sock, string ip, uint16_t port) { struct sockaddr_in local; local.sin_family = AF_INET; local.sin_port = htons(port); local.sin_addr.s_addr = inet_addr(ip.c_str()); if(connect(sock, (struct sockaddr*)&local, sizeof(local)) < 0) { cout << "connect error" << endl; exit(5); } cout << "connect success" << endl; } }; - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
http.cpp -----> 接受请求 后 并且返回 一个响应
#include "Sock.hpp" #include#include #include void* handlerHttp(void* argc) { int sock = *(int*)argc; delete (int*)argc; pthread_detach(pthread_self()); char buff[10240]; memset(buff, 0, sizeof(buff)); ssize_t s = recv(sock, buff, sizeof(buff) - 1, 0); if(s > 0) { buff[s] = 0; cout << buff << endl; string response = "http/1.0 200 ok \n"; response += "Content-Type: text/plain\n"; //text/plain 就是普通文本 response += '\n'; // 报头和正文的分界线 response += "Do you eat breakfast good morning good ningt"; send(sock, response.c_str(), response.size(), 0); } close(sock); return nullptr; } void Usage(const char* proc) { cout << "Usage:" << endl; cout << "./http" << " proc" << endl; } // ./http port int main(int argc, char* argv[]) { if(argc != 2) { Usage(argv[0]); return 1; } //创建套接字, 本质是创建文件 int sock = Sock::Socket(); //绑定 Sock::Bind(sock, atoi(argv[1])); //监听状态 Sock::Listen(sock); //接受状态 while(1) { int fd= Sock::Accept(sock); if(fd > 0) { int* pram = new int(fd); pthread_t td; pthread_create(&td, nullptr, handlerHttp, pram); } } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
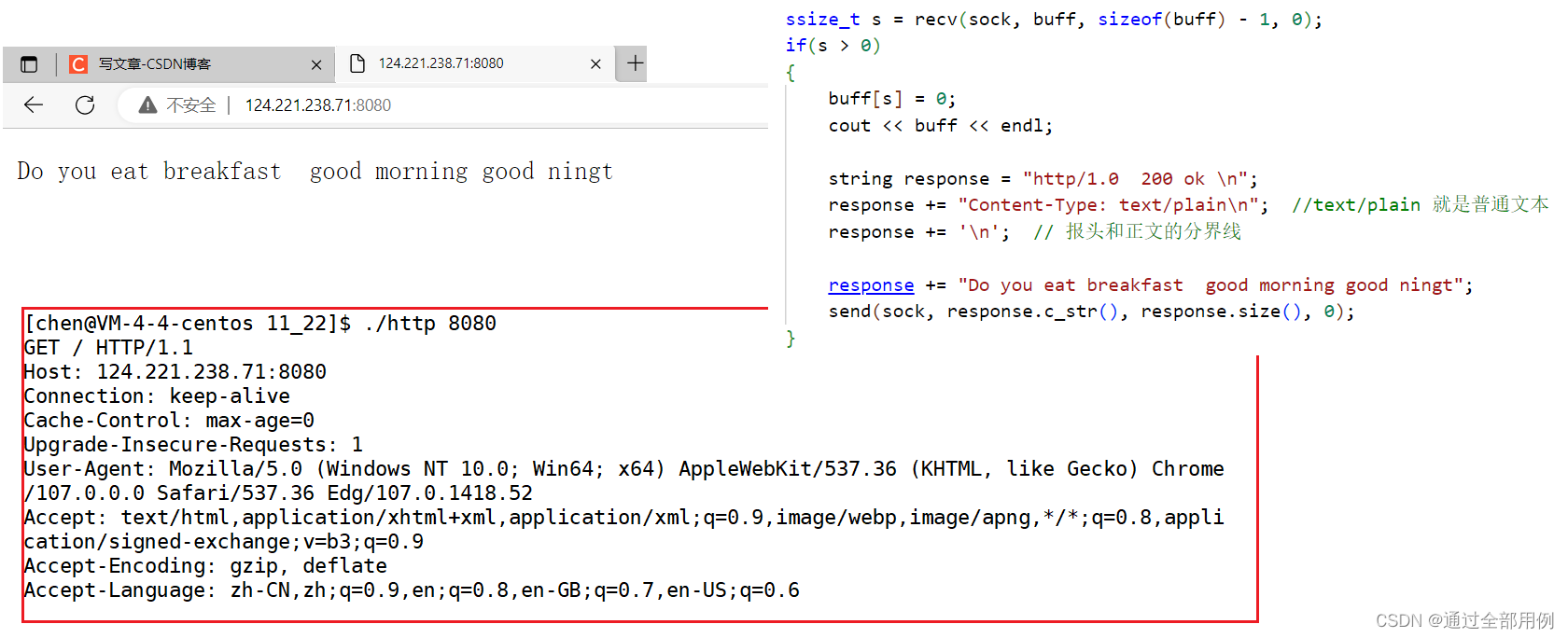
关于http协议的一些概念性知识
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD (但是http1.1也是支持的)
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT下面三个都是应用层协议
SMTP:简单邮件协议
FTP:文件传输协议
TELNET:Internet远程登录服务的标准协议UDP:用户数据报协议 (这是传输层协议)
http状态码中,(2xx )表示访问成功,( 4xx)表示坏请求,(5xx )表示服务不可用。
坏请求 : 客户端的错
服务不可用: 服务端的错HTTP协议,是TCP/IP协议栈中应用层的协议
Cookie数据是在HTTP协议头部字段中传输
HTTP协议在目前1.1版本中支持了长连接管理,也就是支持在一定时间内保持TCP连接建立,用于发送/接收多次请求**(keep-alive)**
HTTP协议是无状态的协议,在最初设计的时候HTTP协议是一种简单的请求-响应协议,即一次建立连接中,完成一次请求一次响应后,通信结束关闭连接,所以是无状态的。也就是说:假设发起3次请求,每次请求都没任何关系。GET请求提交参数是放在URL中的, 有长度限制 。 http标准协议规定:URL无长度限制, 但是呢客户端的浏览器和服务器会因为URL超出长度而出现请求失败的情况, 所以默认为有长度限制。
POST请求提交参数是放在body(正文中), 无长度限制。POST请求不会被缓存 ----> 对数据长度无限制(body) -------> 无法从浏览器中找到
GET请求可以缓存,可以从浏览记录中找到 ------->数据长度有限制(URL)对与PUT方法而言:-------一定会有资源
PUT方法请求服务器去把请求里的实体存储在请求URI(Request-URI)标识下。
如果请求URI(Request-URI)指定的的资源已经在源服务器上存在,那么此请求里的实体应该被当作是源服务器关于此URI所指定资源实体的最新修改版本。
如果请求URI(Request-URI)指定的资源不存在,并且此URI被用户代理定义为一个新资源,那么源服务器就应该根据请求里的实体创建一个此URI所标识下的资源。如果一个新的资源被创建了。HEAD请求是没有响应体的,仅传输状态行和标题部分 (首行 + header)
DELETE方法用来删除指定的资源,它会删除URI给出的目标资源的所有当前内容
PUT方法用于将数据发送到服务器以创建或更新资源,它可以用上传的内容替换目标资源中的所有当前内容403:禁止访问,服务器拒绝接收到请求但拒绝提供服务,原因较多,比如权限不足,IP被拉入黑名单…
4xx:客户端的错503: 表示服务器端暂时无法处理请求 -----> 服务端的错误 ----->5xx
cookie和session —本质就是“会话保持功能”
我们知道:http协议是一种无状态协议。 发送一次请求,建立链接—>传输数据----->关闭链接。每一次的请求都没有关系。
也就是说,如果浏览某些网站可能要输入账号+密码, 意味着只要网页跳转的时候就要再次进行输入。
可实际经验告诉我们:不需要多次输入账号 + 密码 ---------->原因就是cookie和session什么是cookie呢?
1, 站在客户端浏览器的角度: cookie就是一个文件,用来保存用户的私密信息(例如账号 + 密码)
2, 在http协议的角度 : 只要客户端的浏览器中存在cookie信息, 每次发送请求的时候, 都会在请求中携带上cookie信息。(这也是为什么我们每次都只用第一次输入密码 + 账号的原因)。cookie的可以记录用户的ID,记录用户的密码,记录用户浏览过的商品记录。但是无法记录用户的浏览器设置(浏览器设置属于浏览器,而并不属于某次请求的信息)

cookie的基础属性
domain:可以访问该Cookie的域名。path:Cookie的使用路径。
httponly:如果cookie中设置了HttpOnly属性,那么通过js脚本将无法读取到cookie信息,这样能有效的防止XSS攻击,窃取cookie内容,这样就增加了cookie的安全性,但不是绝对防止了攻击。
secure:该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS,SSL等,在网络上传输数据之前先将数据加密。默认为false。
expires:指定了cookie的生存期,默认情况下cookie是暂时存在的,他们存储的值只在浏览器会话期间存在,当用户退出浏览器后这些值也会丢失,如果想让cookie存在一段时间,就要为expires属性设置为未来的一个过期日期。现在已经被max-age属性所取代,max-age用秒来设置cookie的生存期
另外的话,cookie是有一定缺陷的:
比如有大小限制,通常不能超过4k,以及cookie不断的传递客户端的隐私信息,存在一定的安全隐患(比如认为篡改)。sesssion
核心思路:将用户的私密信息保存在服务端。
Set_cookie ----->服务端向用户端的浏览器设置一个cookie
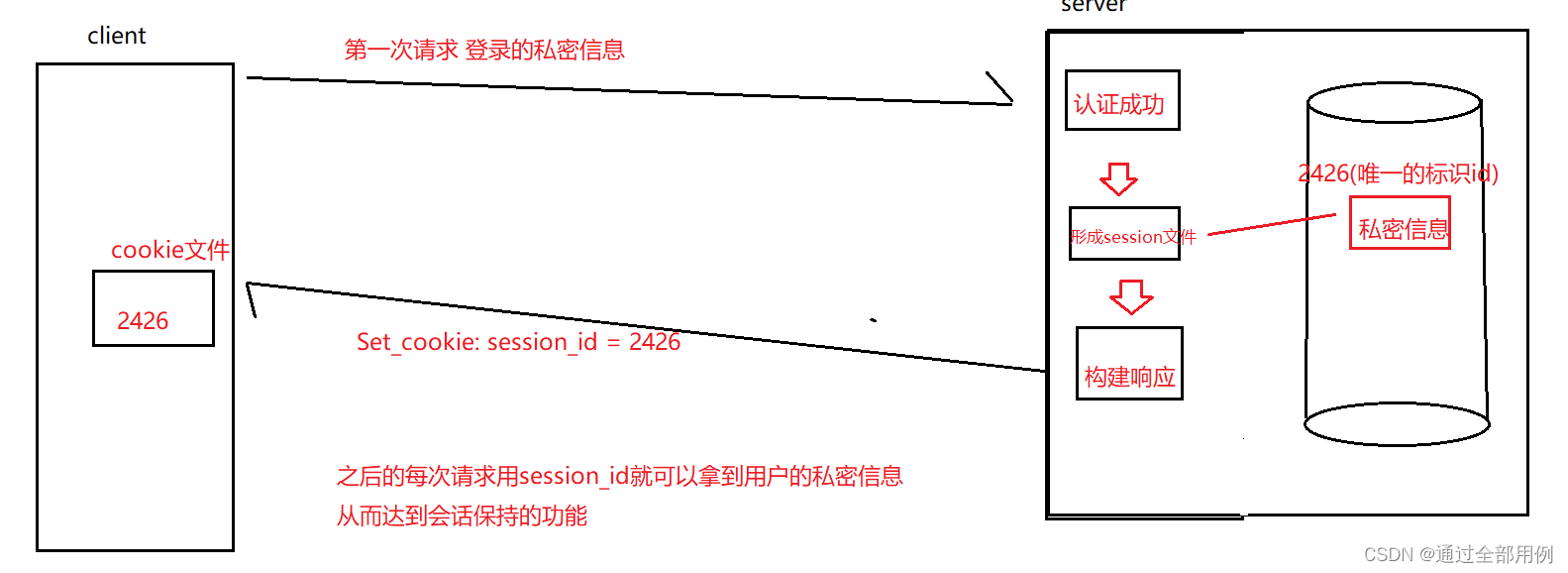
cookie和session的对比:
cookie如果没有指定失效时间,默认是在结束当前会话的时候失效。
session的默认有效时间是30分钟cookie只能存放字符串
session可以存放任意类型。cookie存在于客户端, 只能用户自己拥有。
session存在于服务端, 可被多个服务器共享。session不一定完全依赖于cookie, 可以将session_id附着于网址实现。
https协议
https = http + TLS/SSL(http的数据加密解密层, 都位于应用层)。
https 和 http协议的对比
http协议是超文本传输协议, 是明文传输的,默认端口是80
https协议是超文本安全传输协议, 是密文传输的, 默认端口是443那https是如何做到安全的呢????
铺垫概念知识1:
加密的方式 :
对称加密 , 密钥X(只有一个)
非对称加密, 有一对密钥, 公钥和私钥。
用公钥加密, 只能用私钥解密
用私钥加密, 只能用公钥解密。公钥往往是开放的,全世界都知道的, 密钥是只有自己拥有的。
另外的话, 不用把密钥想的多么复杂, 就是加密和解密算法。
非对称加密, 非常的浪费资源, 对称加密,不浪费资源。铺垫概念知识2:
如何防止文本信息被纂改呢?

客户端和服务端在进行沟通的时候, 分两部分 ; 密钥协商阶段 + 通信阶段。
而对于非法的中间商, 他可以获取任意交互阶段的数据。
对于安全的定义是 : 不是不让中间方获取数据, 而是得到数据后完全无法处理,以至于拿不到相关信息。下图所示: 中间人在交互的任意阶段就算拿到了数据, 都会因为没有相应的密钥而无法处理数据从而拿不到相关信息。

-
相关阅读:
和腾讯工作十几年的资深测试工程师讨论今年校招标准。
任意文件的上传和下载
2021 CSP J2入门组 CSP-S2提高组 第2轮 视频与题解
统计目录下的文件数量
redis下载与安装(Linux环境下)
JVM相关知识
【文件传输】查找等相关命令
如何自己开传奇单机架设超详细图文教程
mencpy和strcpy的区别?
STL-容器适配器详解
- 原文地址:https://blog.csdn.net/CL2426/article/details/128008253
