-
Hadoop高可用环境搭建-HDFSNameNode高可用搭建、Yarn高可用搭建
本文环境搭建的前提条件:JDK、Zookeeper、Hadoop完全分布式环境搭建完成。如果未满足条件且不会搭建,可以前往博主的主页搜索相关文章进行搭建。
目录
本文主节点hostname:master,从一:slave1,从二:slave2
一、HDFSNameNode高可用搭建
1、切换目录:cd /export/server/hadoop/etc/hadoop (/export/server是放hadoop的目录,这个如果和博主不一样需要换成自己的目录路径)
注释部分为HTML语法,如果复制粘贴记得删除
vi core-site.xml
- <property>
- <name>fs.defaultFSname>
- <value>hdfs://myclustervalue>
- property>
- <property>
- <name>ha.zookeeper.quorumname>
- <value>master:2181,slave1:2181,slave2:2181value>
- property>
- <property>
- <name>hadoop.tmp.dirname>
- <value>/export/server/hadoop-2.7.2/data/ha/tmpvalue>
- property>
vi hdfs-site.xml
- <property>
- <name>dfs.replicationname>
- <value>2value>
- property>
- <property>
- <name>dfs.nameservicesname>
- <value>myclustervalue>
- property>
- <property>
- <name>dfs.ha.namenodes.myclustername>
- <value>nn1,nn2value>
- property>
- <property>
- <name>dfs.namenode.rpc-address.mycluster.nn1name>
- <value>master:8020value>
- property>
- <property>
- <name>dfs.namenode.rpc-address.mycluster.nn2name>
- <value>slave1:8020value>
- property>
- <property>
- <name>dfs.namenode.http-address.mycluster.nn1name>
- <value>master:50070value>
- property>
- <property>
- <name>dfs.namenode.http-address.mycluster.nn2name>
- <value>slave1:50070value>
- property>
- <property>
- <name>dfs.namenode.shared.edits.dirname>
- <value>qjournal://master:8485;slave1:8485;slave2:8485/myclustervalue>
- property>
- <property>
- <name>dfs.ha.fencing.methodsname>
- <value>sshfencevalue>
- property>
- <property>
- <name>dfs.ha.fencing.ssh.private-key-filesname>
- <value>/root/.ssh/id_rsavalue>
- property>
- <property>
- <name>dfs.journalnode.edits.dirname>
- <value>/export/server/hadoop-2.7.2/data/ha/jnvalue>
- property>
- <property>
- <name>dfs.permissions.enablename>
- <value>falsevalue>
- property>
- <property>
- <name>dfs.client.failover.proxy.provider.myclustername>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
- property>
- <property>
- <name>dfs.ha.automatic-failover.enabledname>
- <value>truevalue>
- property>
vi slaves 将主从节点写上
master
slave1
slave2
1、分发文件给两个从节点:
scp -r /export/server/hadoop-2.7.2/etc/hadoop slave1:/$HADOOP_HOME/etc/
scp -r /export/server/hadoop-2.7.2/etc/hadoop slave2:/$HADOOP_HOME/etc/
将三个节点都刷新:source /etc/profile
2、将每个节点都启动ZooKeeper并查看状态:
启动:zkServer.sh start
查看:zkServer.sh status
3、主节点格式化ZooKeeper: hdfs zkfc -formatZK
4、每个节点启动journalnode服务: hadoop-daemon.sh start journalnode
5、格式化集群的一个NameNode节点(主节点):hdfs namenode -format
6、在主节点单独启动namenode进程: hadoop-daemon.sh start namenode
7、将格式化的namenode节点信息同步到备用的NameNode(nn2即node1节点),并启动namenode进程(从一节点):hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
8、在主节点启动所有的datanode进程: hadoop-daemons.sh start datanode
9、在主节点和从一节点上分别启动 ZooKeeperFailoverCotroller(主备切换控制器),是NameNode机器上一个独立的进程(进程名为zkfc):
hadoop-daemon.sh start zkfc
10、用jps查看(主节点、从一、从二分别为664)

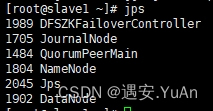

以上HDFSNameNode高可用搭建环境便搭建完成了
测试主备切换:
查看节点状态:hdfs haadmin -getServiceState nn1
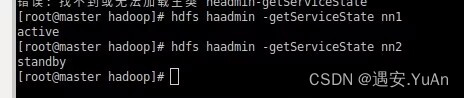
方式一、命令切换节点状态 到 hadoop 目录下执行:
1、将 NN2 切换为 Standby 备用节点 bin/hdfs haadmin -transitionToStandby --forcemanual nn2 2、将 NN1 切换为 Active 备用节点 bin/hdfs haadmin -transitionToActive --forcemanual nn1
方式二、利用ZKFC自动故障转移
1、关闭 主节点 ANN 的 NameNode 节点
kill -9 进程号
等待一会,ZKFC 检测出 主节点 NameNode 失联后,就会进行启动备用节点为主节点
查看 master 的节点状态,此时备用节点 已经切换为主节点 ANN
2、再将主节点关闭的 NameNode 节点启动
单独启动NameNode节点命令
hadoop-daemon.sh start namenode
查看 slave1 的节点状态,此时节点状态已经切换为备用节点
二、 Yarn高可用搭建
1、cd /export/server/hadoop-2.7.2/etc/hadoop/
在主节点修改yarn-site.xml:
vi yarn-site.xml
- <property>
- <name>yarn.nodemanager.aux-servicesname>
- <value>mapreduce_shufflevalue>
- property>
- <property>
- <name>yarn.resourcemanager.ha.enabledname>
- <value>truevalue>
- property>
- <property>
- <name>yarn.resourcemanager.cluster-idname>
- <value>rmClustervalue>
- property>
- <property>
- <name>yarn.resourcemanager.ha.rm-idsname>
- <value>rm1,rm2value>
- property>
- <property>
- <name>yarn.resourcemanager.hostname.rm1name>
- <value>mastervalue>
- property>
- <property>
- <name>yarn.resourcemanager.hostname.rm2name>
- <value>slave1value>
- property>
- <property>
- <name>yarn.resourcemanager.zk-addressname>
- <value>master:2181,slave1:2181,slave2:2181value>
- property>
- <property>
- <name>yarn.resourcemanager.recovery.enabledname>
- <value>truevalue>
- property>
- <property>
- <name>yarn.resourcemanager.store.classname>
- <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
- property>
1、在主节点将文件分发给两个从节点:
scp -r yarn-site.xml slave1:/export/server/hadoop-2.7.2/etc/hadoop/
scp -r yarn-site.xml slave2:/export/server/hadoop-2.7.2/etc/hadoop/
2、将三个节点都启动ZooKeeper
zkServer.sh start
3、在主节点和从一节点启动ZKFC
hadoop-daemon.sh start zkfc
5、在主节点启动集群start-all.sh
6、在从一节点启动resourcemanager
yarn-daemon.sh start resourcemanager
7、用jps查看(主节点、从一、从二分别为885)

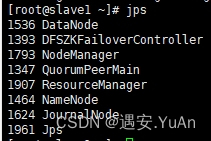
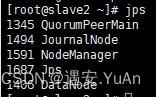
查看节点状态:yarn rmadmin -getServiceState rm1
-
相关阅读:
VC++将资源文件编译进程序并在运行时释放到文件
JavaScript权威指南第七版 第二章笔记:词法结构
Firefox修改缓存目录的方法
LeetCode 每日一题——1710. 卡车上的最大单元数
【R言R语】算法工程师入职一年半的总结与感悟
深入理解服务器进程管理与优化
shiro学习笔记——shiro拦截器与url匹配规则
nginx请求的11个阶段
深入理解Istio流量管理的熔断配置
xray证书安装及使用
- 原文地址:https://blog.csdn.net/qq_62731133/article/details/127981418
