-
C++11、17、20的内存管理-指针、智能指针和内存池从基础到实战(上)
C++11、17、20的内存管理-指针、智能指针和内存池从基础到实战(上)
- 第一章 指针原理和快速入门
- 第二章 C++智能指针和函数参数与返回值
- 1、unique_ptr的指针和数组多种初始化方式分析
- 2、unique_ptr智能指针和数组的访问
- 3、unique_ptr重置和移动内存资源
- 4、unique_ptr释放所有权和自定义空间删除方法
- 5、图解shared_ptr共享智能指针原理分析
- 6、shared_ptr共享智能指针演示初始化和空间清理
- 7、shared_ptr共享指针定制删除函数和指向同一个对象
- 8、weak_ptr解决shared_ptr循环引用内存泄漏
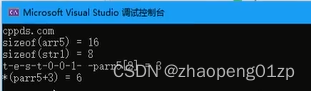
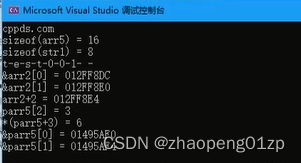
- 9、指针作为函数参数传递-使用模板传递数组
- 10、智能指针作为函数的参数和返回值unique_ptr
- 11、使用string作为函数参数内存的输入和输出
- 12、使用vector传递内存并接收函数返回的内存空间
第一章 指针原理和快速入门
1、第一个指针程序-详解指针代码




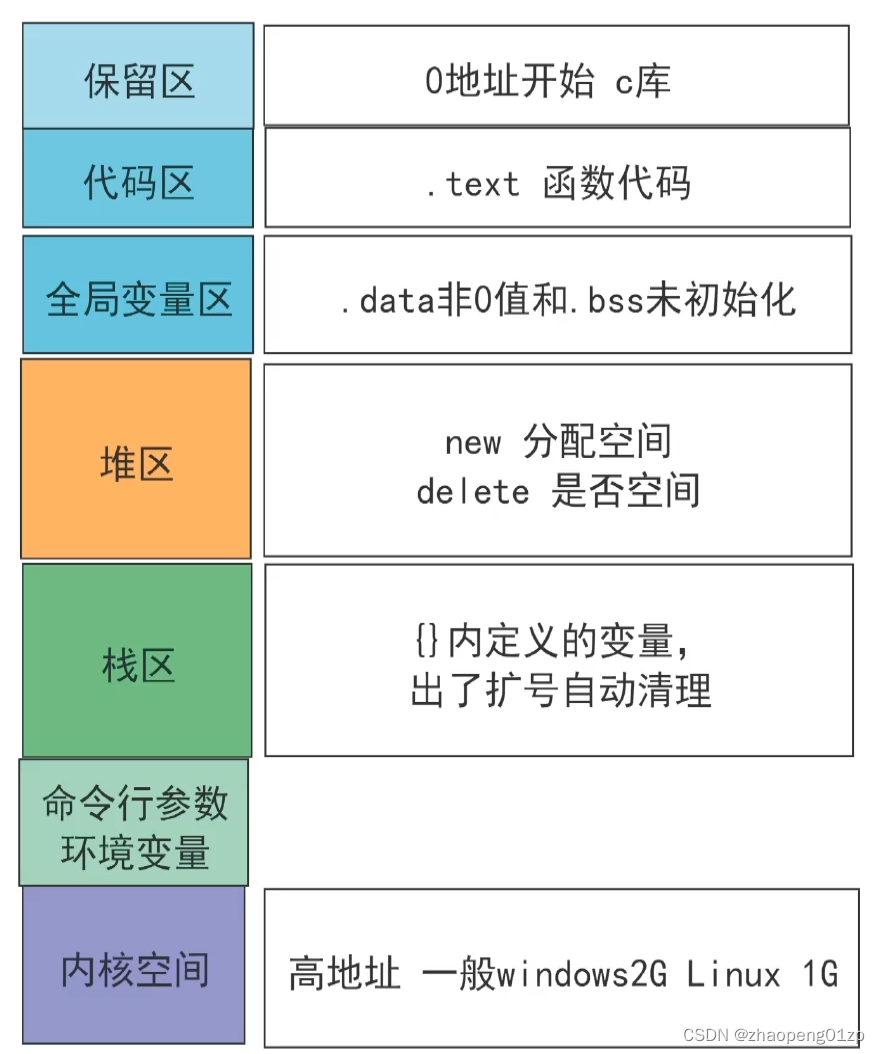
2、图示进程的内存空间划分分析代码区_堆栈_内核空间








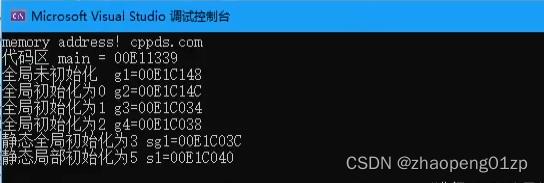

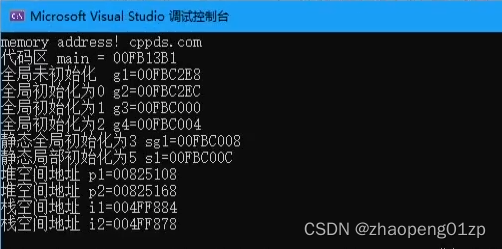

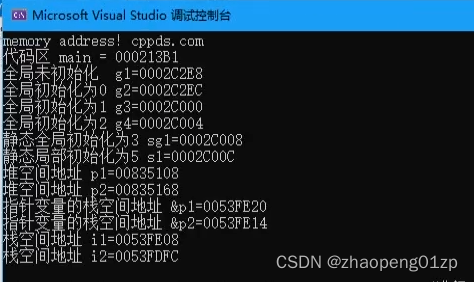
3、各种内存空间-堆_栈_全局地址代码演示
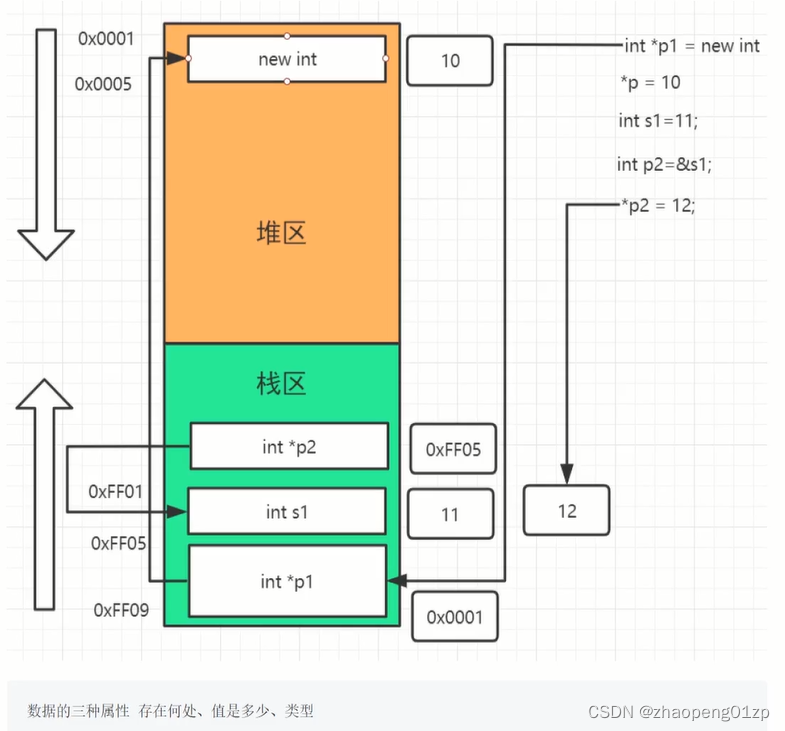
4、图解堆栈空间分配对应的指针代码
5、数组的堆栈空间初始化和c++11的for遍历


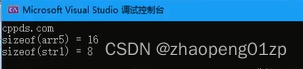
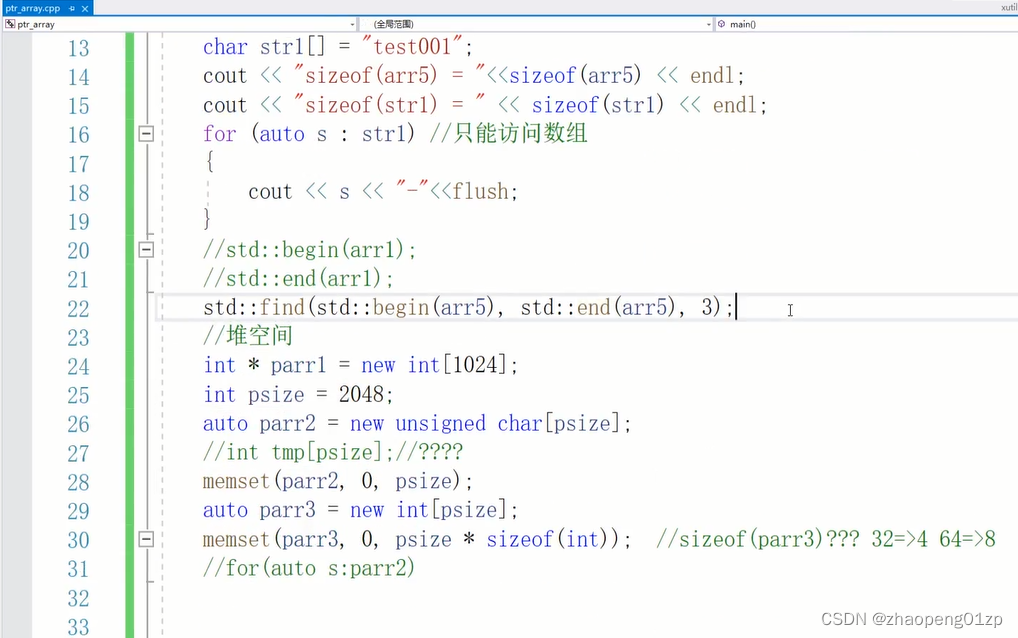







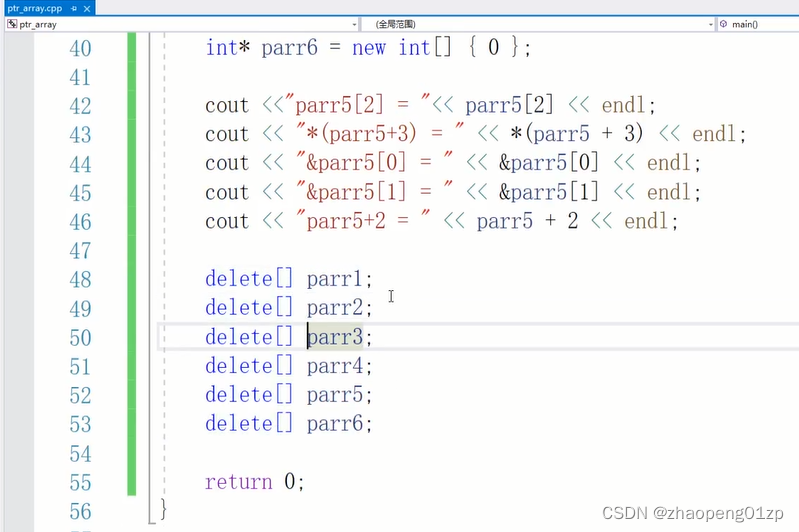
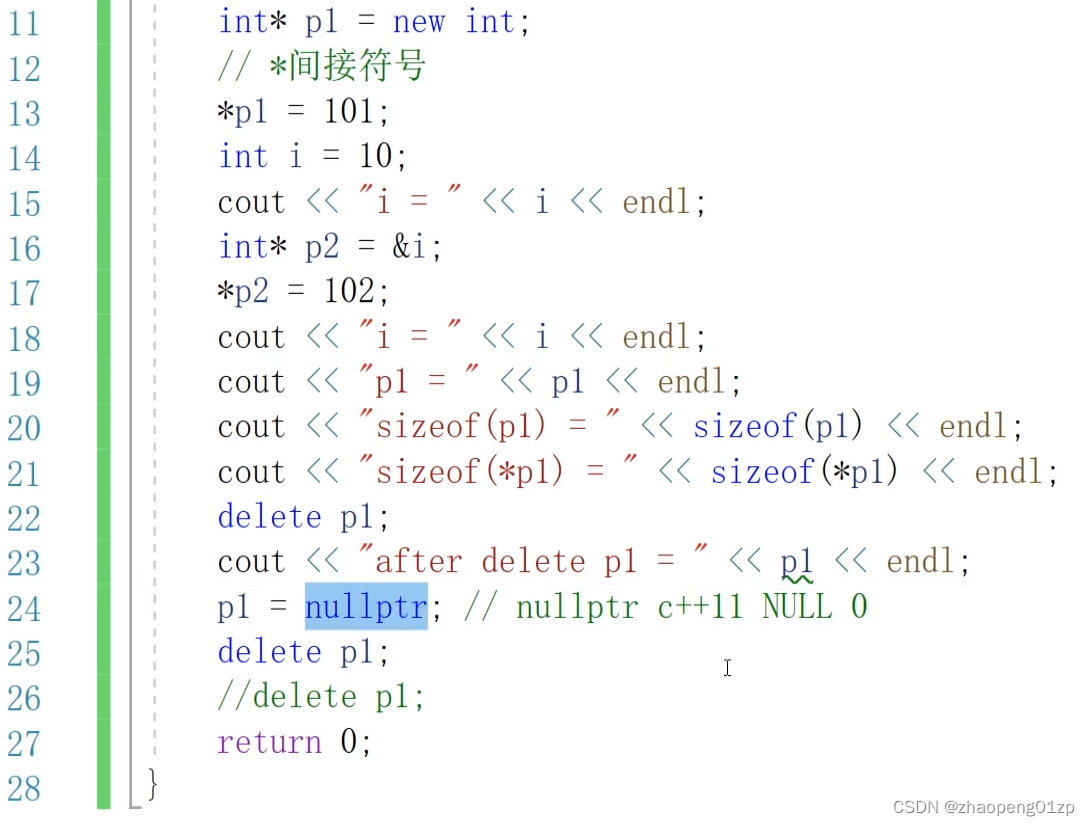
对于int或者char类型的堆空间,你不加这个方括号,delete也能够清理成功;
但是不加的话会有很大的误导性,而且你也不确定编译器是怎么理解的,你不能确定不同编译器的处理方式。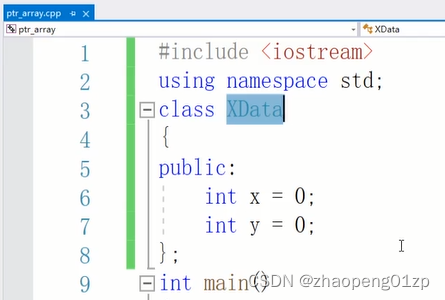

它有时候不会报错,但是这时候空间在来回传递的时候,有时候会导致系统对这种方式的理解是:我只删这一个对象XData的内存空间,而不是删整个的1024个XData的内存空间;其实最怕的就是上图这种不报错的情况了,会隐藏bug。

总之记得,只要是我们堆栈申请出的数组,你都不要省略这个符号来进行清理,而且清理过之后,我们要养成习惯,不管这些指针有没有效了,你只要清理掉之后,你全部要给这些指针改成nullptr,这样可以保证我们二次清理的时候程序不会当掉,而且我们去判断这块空间有没有被清理的时候,我们有这样的一个标识的方式,能知道这块空间是否被清理掉。

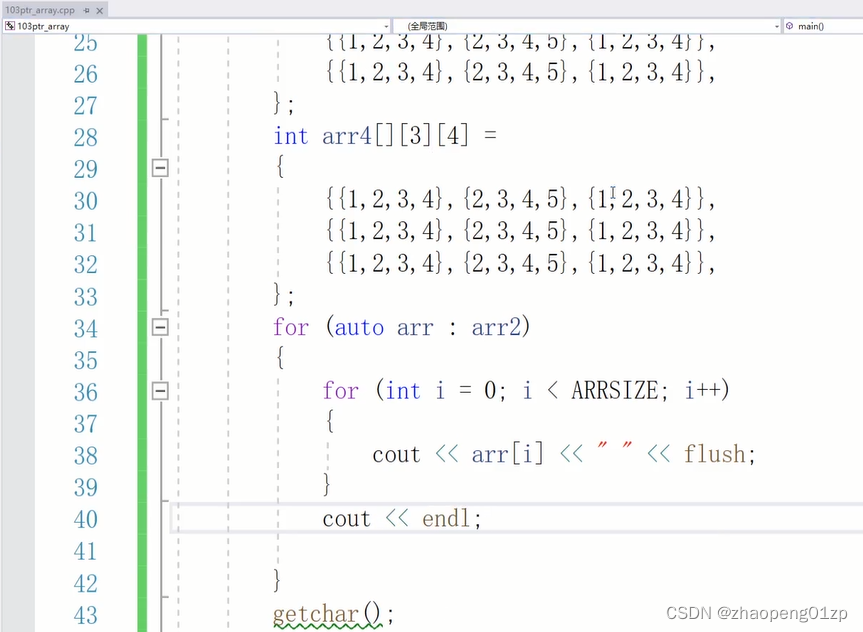
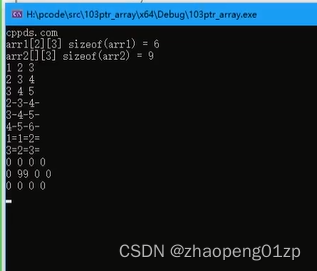
6、图解栈中二维数组的初始化和遍历
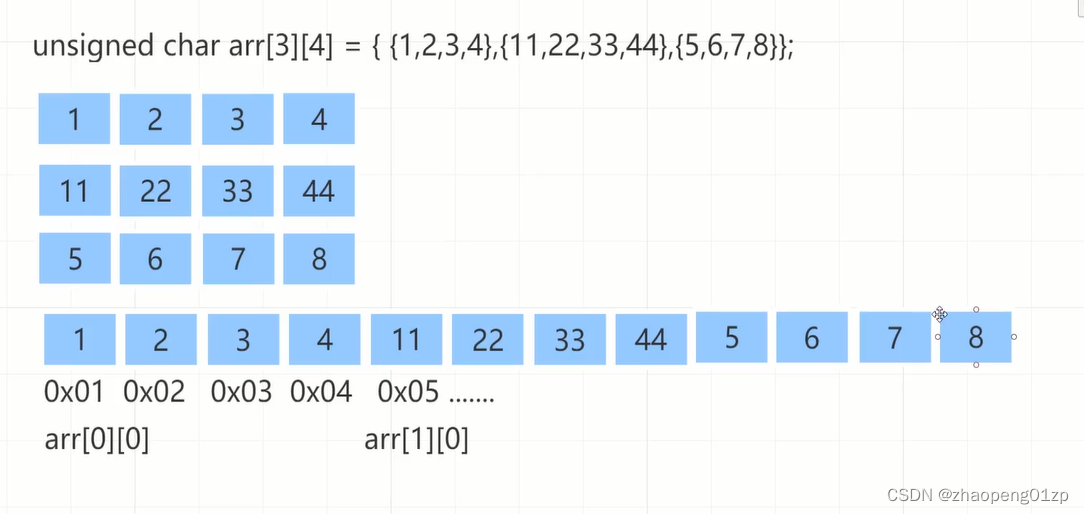



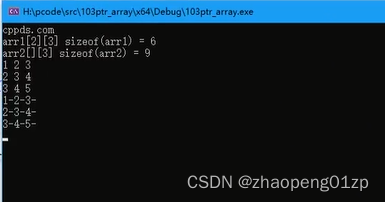
用来c++11的这个for循环来遍历二维数组,临时变量arr的类型在这类是unsigned char*,它其实拿到的是上图选中的arr2的3个一维数组其中一个的指针。


上图打印出来的是方框,这是因为我们的元素类型是unsigned char,所以输出成字符了,我们转换为int类型再来打印:


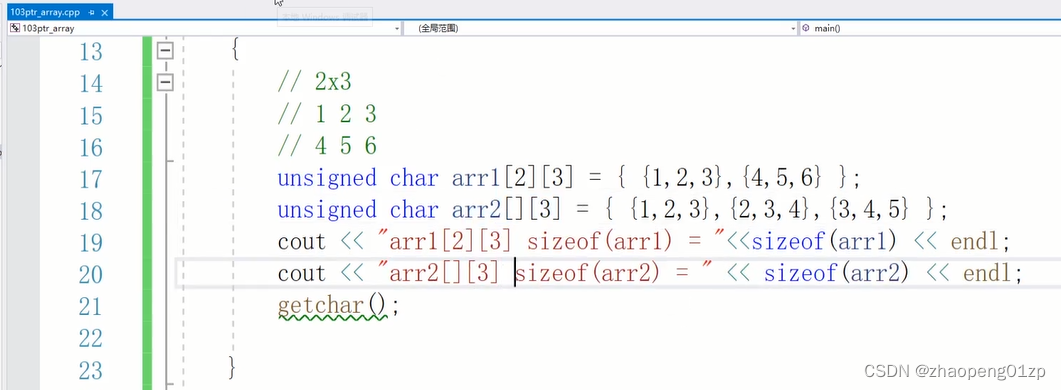
那怎么来计算二维数组的维度呢?我们可以理解二维数组的维度为宽和高:




7、图解堆中两种二维数组空间分配设置和清理



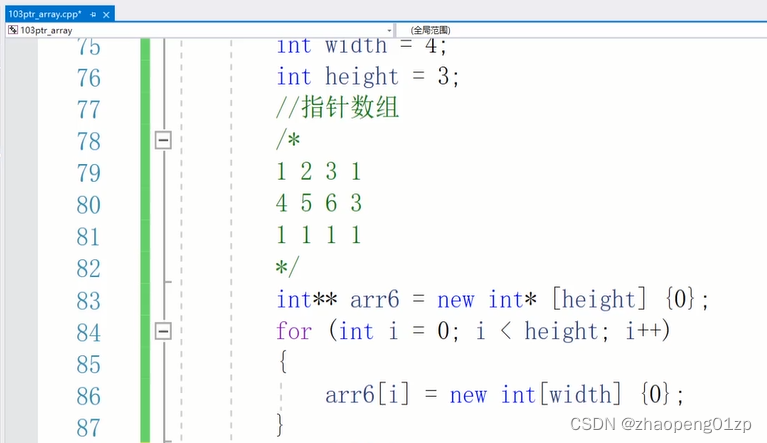
先是有了一个指针数组,指针数组存放的是一个个的指针,每个指针指向一块新的数组空间
new int[width]。


先要把指针数组指向的每一块空间删除掉,然后再来删除我们整个的空间。
8、void指针和c++11的指针类型转换


可以看到,static_cast是无法去掉常量类型的。

C语言的这种强制类型转换,它是不会去验证、检查这种const的,这种把const强制去掉的转换其实是非常危险的。
有些不能够转换的类型,它会提示:

可以看到这种不同类型的转换也是不成功的。

C语言风格的转换,我们不知道在这个转换过程中发生了什么,也就是说对于代码的清晰度来说,我不知道这里可能会产生问题;
所以说,我们要有一个明确的检查,来让我们知道该怎么去转换,也就是说代码层面要给它清楚。C++提供了直接把const给去掉的方式:

上面的把unsigned char*转换成int *在我们实际工作中也有这种类型重新定义的使用需求:

reinterpret_cast开头的re就告诉了我们,重新定义了这个类型空间的使用。
9、常量指针与指针常量
常量指针与指针常量是说,它指向的是一个常量,还是说它本身是一个常量;
也就是说,它指向的值是否能修改,还有它的指向(也就是它的值)是否能修改。
const在前,也就是说,const int表示类型,星号表示指针;
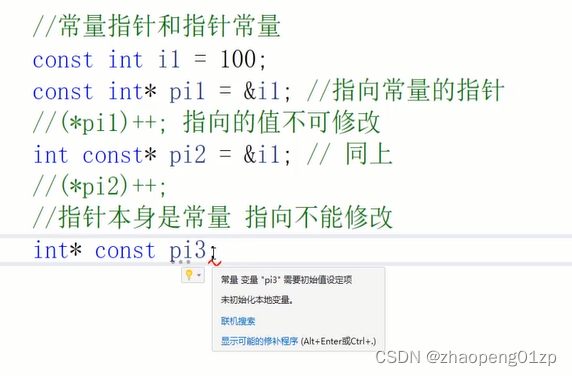
我们更关注的是const在星号的哪一边,const在星号的哪一边比较关键;
上图星号前面的是指向的内容,指向的内容是一个int类型的,后面加一个const表示你这个指针变量不可修改,因为它不能修改,所以它必须有一个初始化值。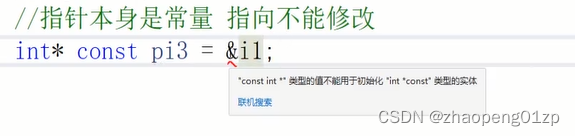
也就是说它在整个过程当中它是不可以修改的;
指向是不能修改的,但是它指向的值是可以修改的。
指针符号的左侧表示它指向的类型;
const在指针符号的右侧,表示指针变量本身的属性。10、示例指针操作二维数组对opencv灰度图做反色


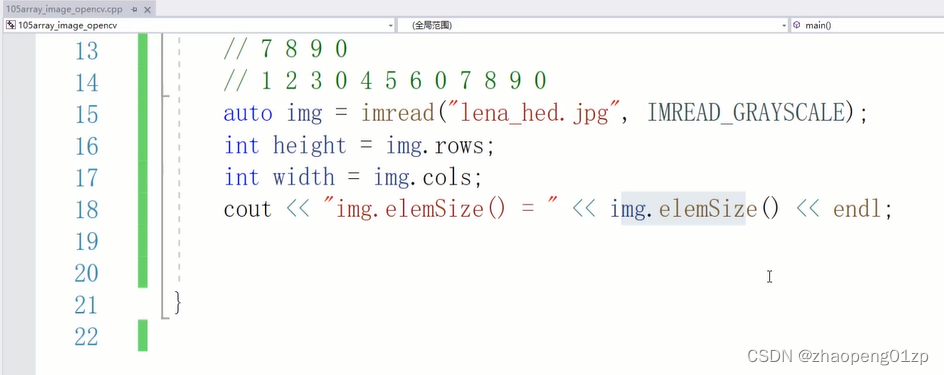

从上图可以看到一个字节表示一个像素。

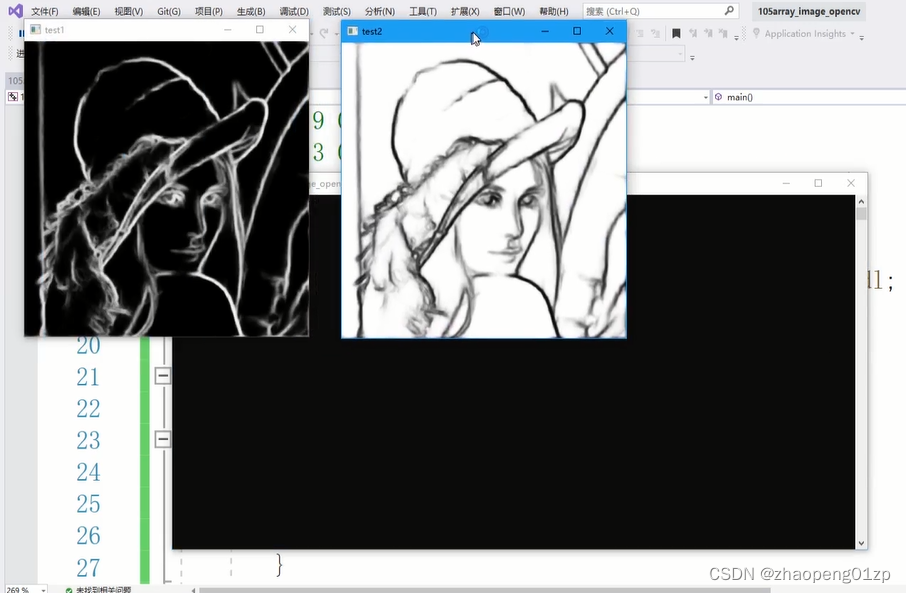
接下来我们要把灰度图变成白色的。

第二章 C++智能指针和函数参数与返回值
1、unique_ptr的指针和数组多种初始化方式分析

RAII总的来说,就是我们的资源在初始化的时候就获取,然后我们在出了作用域的时候把它清理掉;
在初始化的时候创建好内存,我们用栈当中的变量,用栈当中它释放的这种特性,我们在对象的析构函数当中来释放我们的资源;
在构造函数当中申请资源,然后在析构函数当中释放资源,这样的话我们就不需要手动的释放了,因为只要出了它的作用域就能够自动释放,减少了我们内存泄漏的风险。所以它是这么一个策略,它会生成一个栈中的对象,在这个对象当中存储指针。






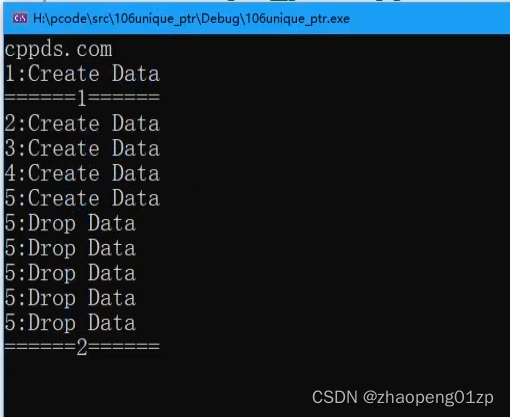
编号写的有问题,编号是静态类型的,成总数了,修改代码:

2、unique_ptr智能指针和数组的访问



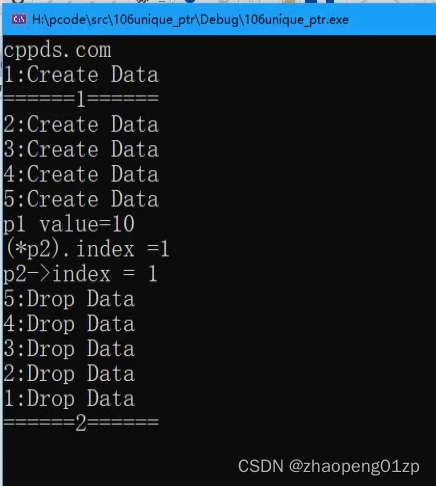



我们通过unique_ptr的源码可以看到,通过这种方式使得它操作我们的智能指针,跟操作一个普通的指针的方式是一致的。
如果说我们要真正的直接访问它所指向空间的地址呢,那我们怎么访问呢?

我们还有一个访问方式,就是unique_ptr提供的get成员函数,get返回的就是d1指针指向的内部空间的地址;
但是这边为什么用点呢?
点的话表示unique_ptr这个类的对象成员的访问,用箭头访问的时候是内部成员,因为这个箭头做了重定向(重载),所以访问智能指针本身内部函数成员的话是用点的方式,访问它指向的空间是用箭头来访问。
也就是说get成员函数返回的也是我们的指针地址。





3、unique_ptr重置和移动内存资源


这时候,我们如果想让p6指向另外一块空间,该怎么办呢?



如果p6不释放的话,会造成什么现象呢?
这个p6智能指针出了作用域之后它要释放,p7也要释放,那就会造成空间释放两次,所以说它是支持移动构造的;
除了支持移动构造外,它也支持移动赋值:

这时候,p7原有的空间会被释放掉,p8会释放所有权,释放所有权是什么意思呢,就是说p8出了作用域不会再释放它指向的这块空间了,这块空间交给了我们p7来释放。
整个的过程就是我们在重新设定了这一个资源的指向。
我们看上图,那如果我们想让它指向一块新的空间,那怎么办?
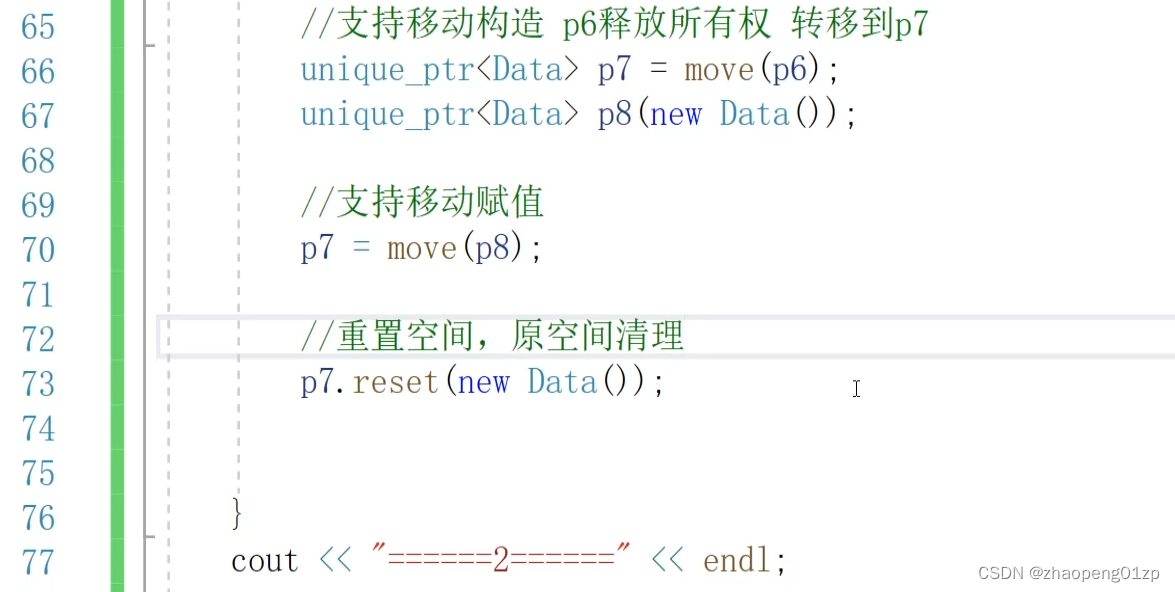
整个这一段代码的目的,就是重新使用p7这一个智能指针,为什么要重新使用这一个智能指针呢?
这个智能指针可能就是我们一个类的成员,或者就是我们前后业务逻辑一直要用的这一个变量,那为了使它重新指向另外一个空间,所以说我们对它进行重置。4、unique_ptr释放所有权和自定义空间删除方法

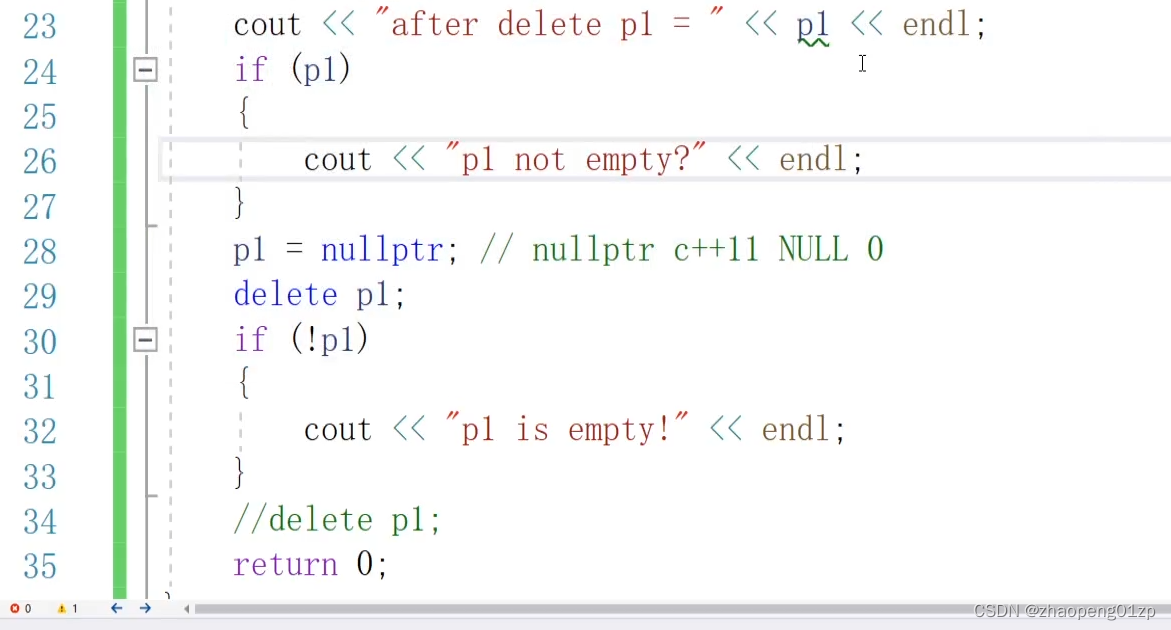
我们可以看到它支持一个nullptr的赋值,也就是说可以传nullptr值,其他值都不可以传;所以说你这时候你把它赋成nullptr之后,它里面的空间就已经被释放掉了:


我们可以看到,在你把p7设成nullptr的时候,就调用了析构函数,所以这是我们主动释放空间资源的一种方法。


释放所有权这是一个很危险的操作,我们将所有权释放了之后,从上图可以看到p9指向的这块空间没有释放掉,就导致内存泄漏了;
release函数返回的是我们Data指针,也就是说这时候需要我们自己清理了,也就是说这块空间就交由你手动来清理:

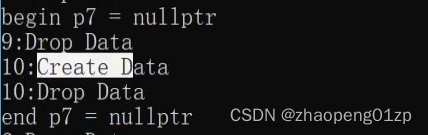
释放所有权,在你有这种需求的时候,一般在我们互相传递参数的时候,会用到这样一个方法。
我们只是传了一个指针进来,交给智能指针,但是具体这个指针它的清理,它默认的方法是内部调用delete,但我们有一些特定的资源(编码数据包、解码数据帧之类的),它们的清理是有固定的方法的,这时候我们把指针传进去了,我们希望它的智能指针出了作用域了时候,自动调用它的方法,那这时候我们要怎么处理呢?
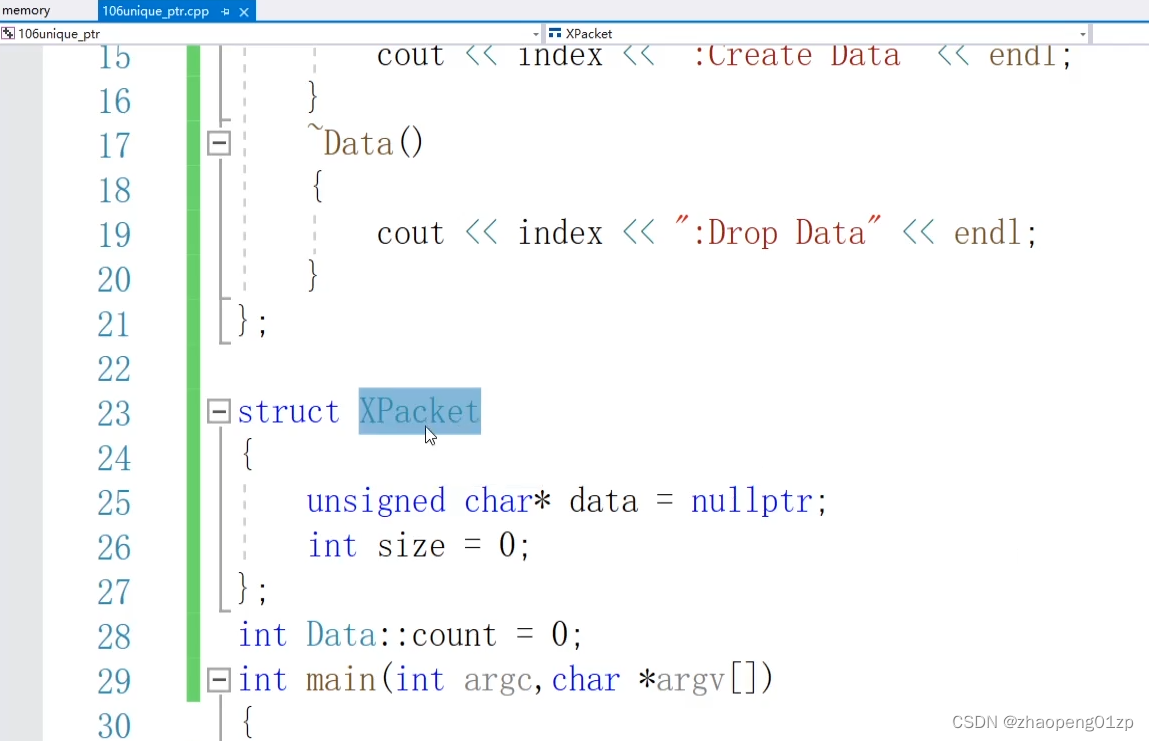
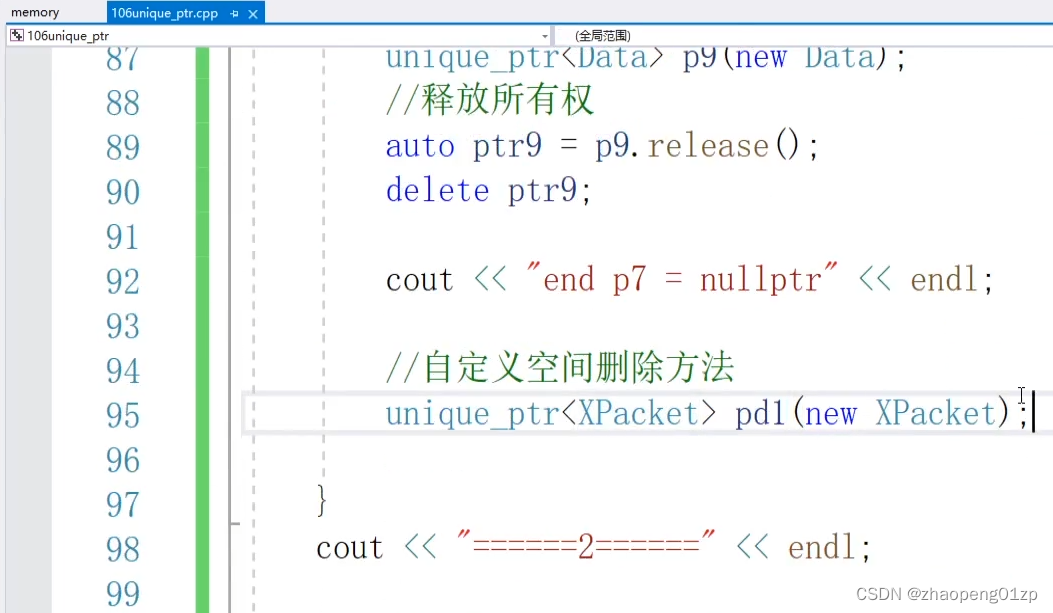
比方说传递了一个C语言类型的指针,比方说XPacket结构体里面包含有一个空间,而且它没有析构函数,这个XPacket是外部提供的,我们不好对它进行重构,那这时候我们怎么处理?
也就是说由外部提供的,我们希望它有一个特定的空间删除方法,那这时候我们在模板函数的参数中增加一个类,在这个类当中我们指定它的清理方法:

那我们怎么让智能指针pd1出了作用域的时候去调用这个自定义的空间删除方法呢?

编译报错。

可以看到它会去调用上图这个函数,因为我们没有去重载PacketDelete对应的操作符,也就是说它待会会调用它的括号操作符来进行重载,所以我们在删除的时候需要定义一个:
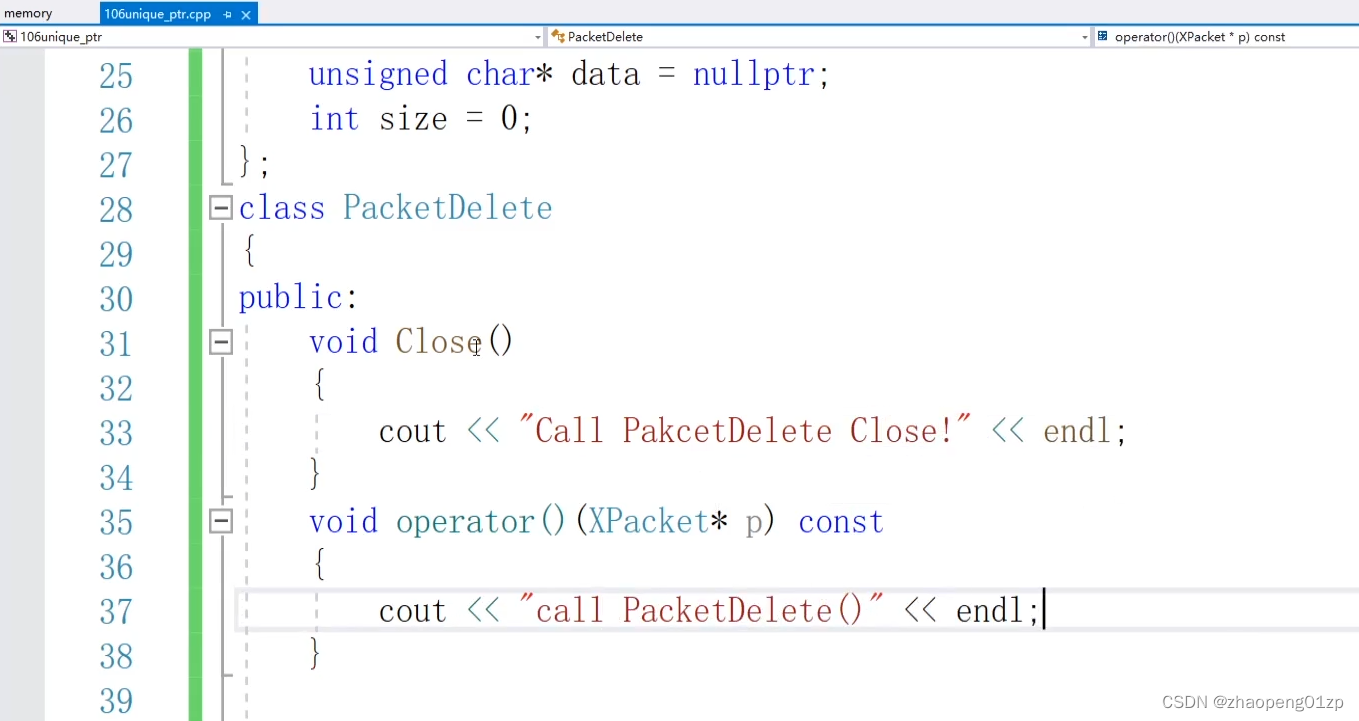
括号操作符重载里面它会把对应的要删除的类型XPacket指针传进来。


就可以调外部的清理函数接口来进行处理,空间资源得到了释放。
那我们刚刚添加的Close函数是什么意思呢?
也就是在特定场合下,如果说我们满足了某一个条件,就像上面的Release函数我们去主动调用它去释放的时候,我们希望做一些处理的时候,调用原先释放的函数它有哪些特定的处理方法的时候。
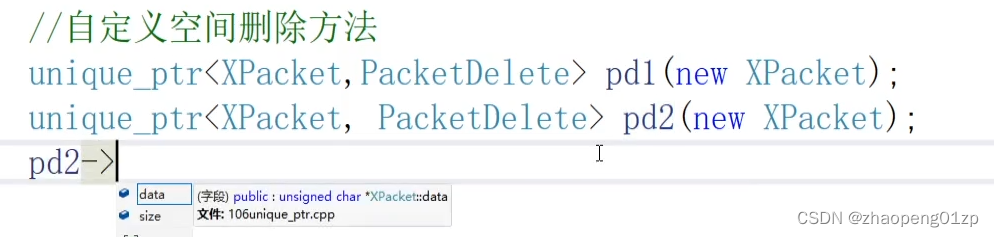
这是一个模板函数,我们传了一个PacketDelete类型过去,它其实是内部会生成一个对象,那我们怎么拿到这个对象呢:
如果说是用箭头操作符,其实是它指向的XPacket对象;用点操作符,是拿unique_ptr它本身的函数:


通过get_deleter接口拿到的就是PacketDelete对象,这时候我们是可以调用它里面的方法的(例如Close),当然如果我们不调用它的方法,我们也可以对它直接清理,把这个对象当做函数来调用,因为我们重载了这对小括号(函数调用操作符):
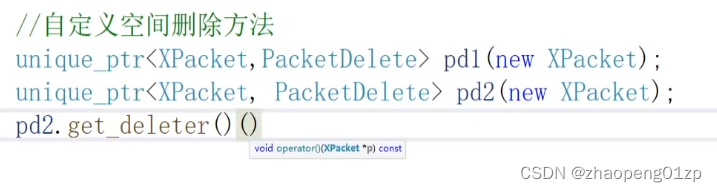
如果说我们手动调用,get是拿到这个XPacket的指针,这样我们就是对它进行释放了:
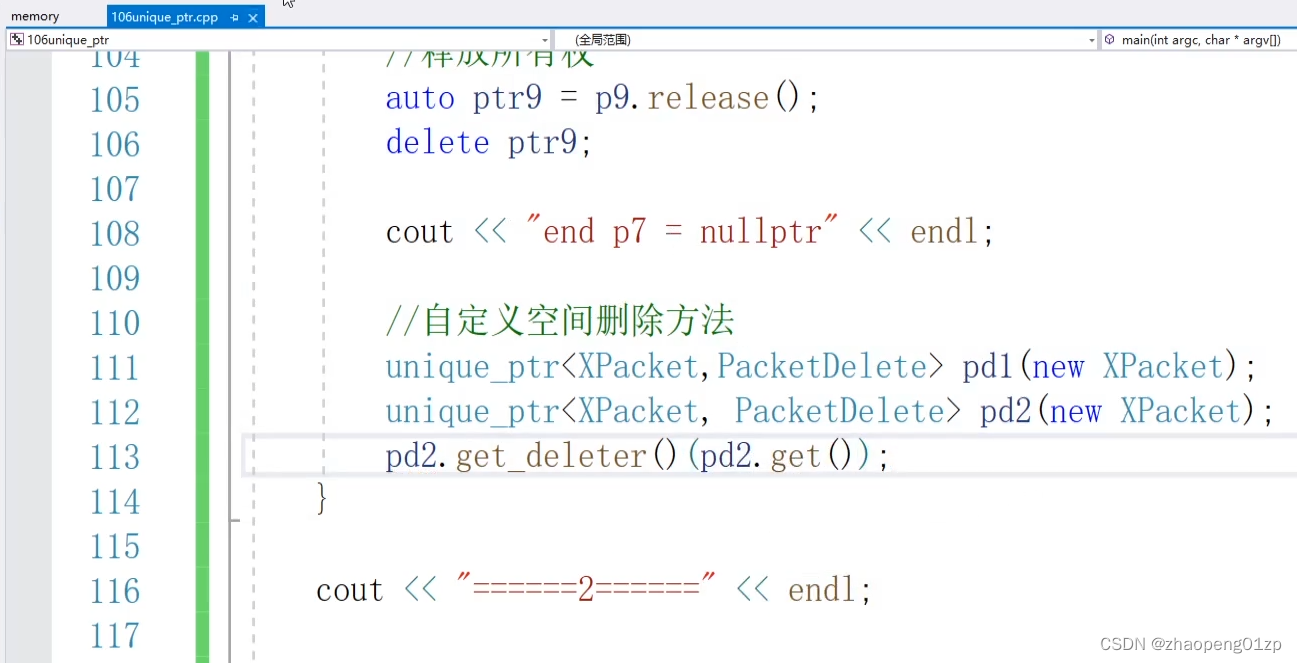
但是这样释放会有问题:

我们主动调用了get_deleter并且把空间释放了,但是当pd2出了作用域之后,其实它并不知道它的空间已经被释放了,所以它会二次释放导致了这个错误,那我们的做法就是释放这块空间所有权:



我们在前面加有一个Close函数,如果说我们在业务逻辑当中有一定的业务,就是要把这个空间先要做一个预处理分割开来,同样也是可以直接调用的:

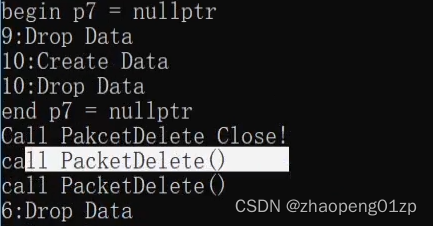
我们先调用了Close,然后再调用了清理,这样的话我们是把整个智能指针空间的清理过程完全定制化来做了。
5、图解shared_ptr共享智能指针原理分析



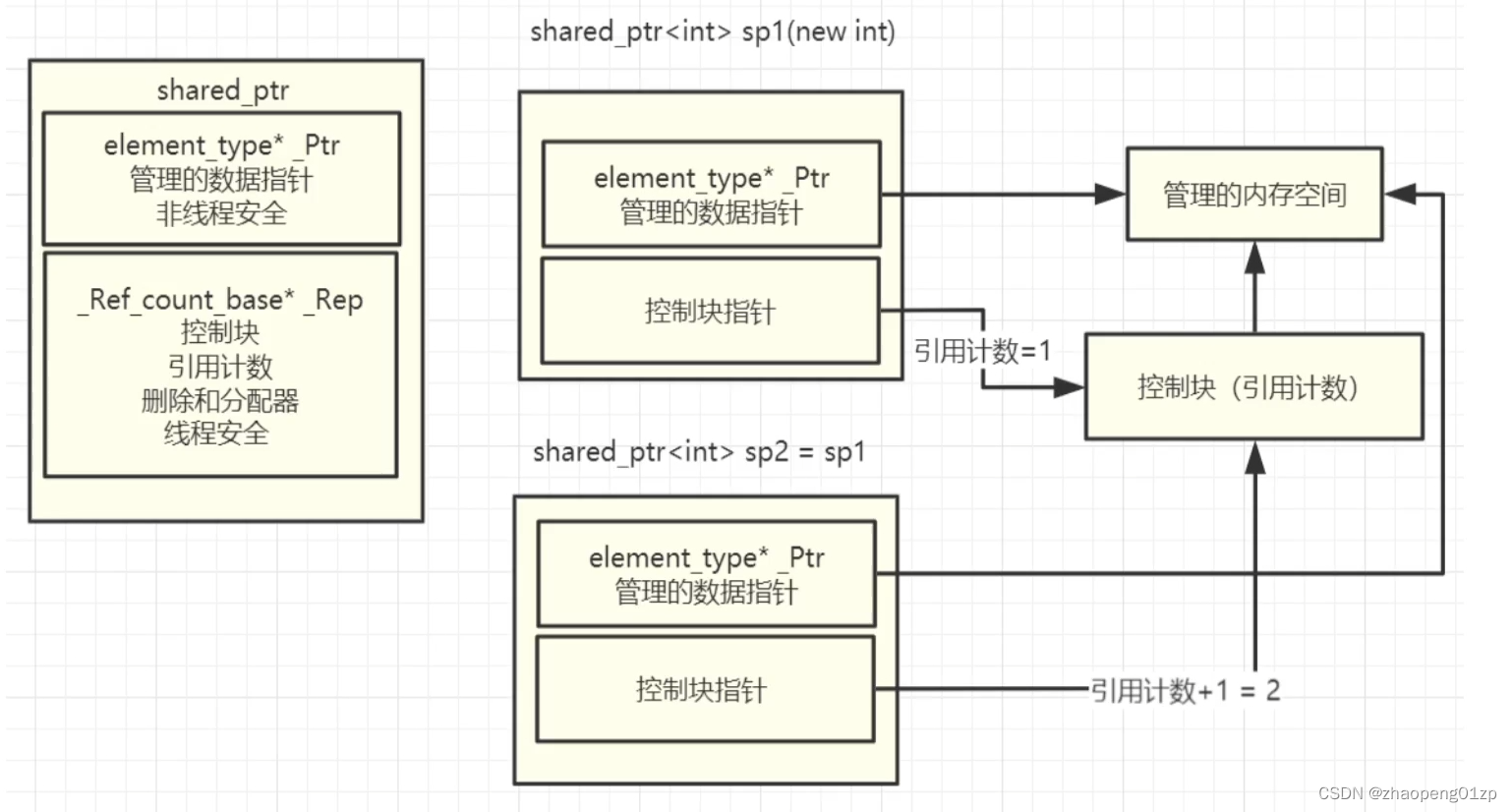
6、shared_ptr共享智能指针演示初始化和空间清理




这时候我们来对引用计数部分进行监听:




如果我们让sp4指向sp5的话,sp3的引用计数是否会改变呢?


因为sp4指向了一块新的空间,它会把原来指向空间的引用计数给清理掉。


当引用计数为0的时候,我们来看看:
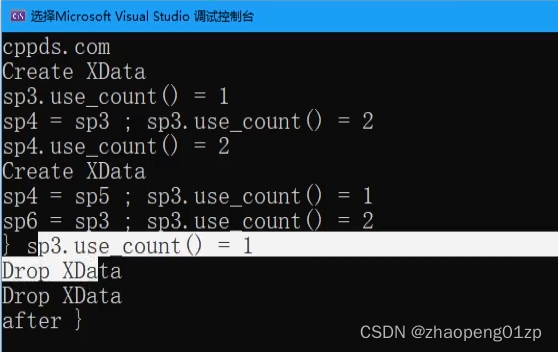
如果说我们要进行手动释放呢?


7、shared_ptr共享指针定制删除函数和指向同一个对象
定制删除函数和前面的unique_ptr的有了一些区别,它不是支持一个类的方式,而是只能通过函数指针的方式来进行实现,当然它也支持Lanbda表达式;这里我们先用一个纯粹的函数指针来做;
我们先准备好一个删除函数接口,待会把它传进来,函数的话可以使全局函数或者静态函数,暂时不能是成员函数:


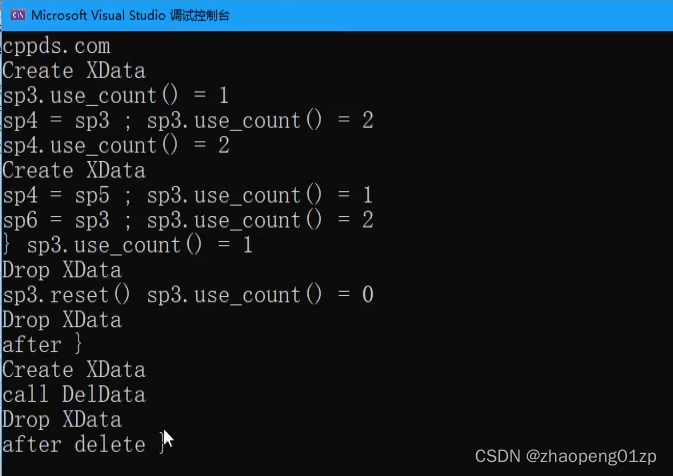
这个时候如果说我们不调用delete的话,相当于这块空间就不会被释放了:


其实我们可以用Lambda表达式作为临时函数来做,因为一般删除的都比较简单,正常情况下智能指针管理的某一块空间,我们删除的时候说白了就是调用一个第三方接口就可以了,其实就几行代码,这时候我们就可以用Lambda表达式来设定:


(注意上图中的DelData函数里面注释了delete p,所以少了一次释放XData)。
这样我们就指定了它的空间清理方法,这是工程上经常用到的。
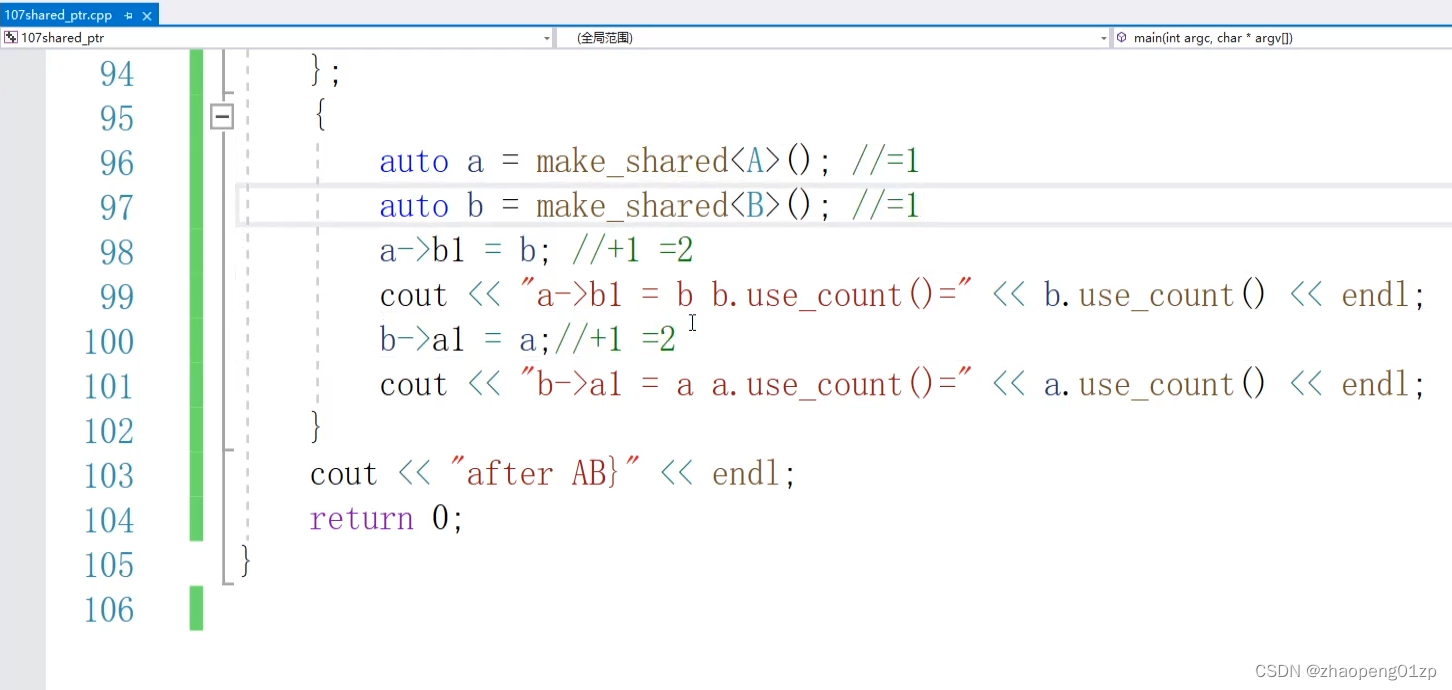
share_ptr智能指针指向同一个对象的不同成员


这样我们就可以做到把某一个成员的资源管理和整个对象的资源管理统一进行配置,也就是当所有的资源都不在使用的时候才去把它的空间进行清理。
我们看到use_count等于3,因为它本身有一次引用,后面又引用了两个成员。8、weak_ptr解决shared_ptr循环引用内存泄漏
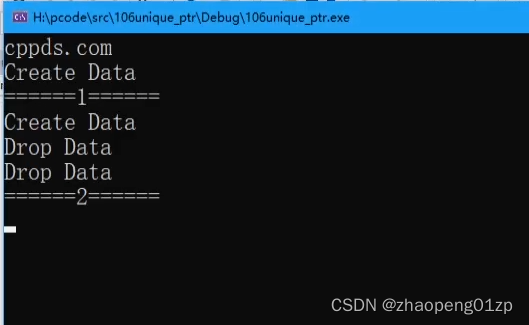
一旦产生了循环引用,就会造成我们的资源永远释放不掉,我们先看一下这个现象,看它是什么原理产生的,然后我们再来去看使用的解决方案。

循环引用,重点就是在A当中包含了B的共享智能指针,B当中包含了A的共享智能指针。
你前置声明之后,你就可以用B的指针,但是你不能直接用B生成对象,所以说这样一个前置声明的特性使得我们智能指针的价值会变大,因为你只是普通指针的话,你没有类型检测、空间资源的申请,用智能指针的话,既能满足我们不需要知道它的具体类型,又能管理这块空间,所以我们不需要知道它的类型,只需要做一个前置声明就行了。


这时候都没有问题;
那么怎么产生的循环引用问题呢?
在面向对象当中如果没设计好的话,很容易产生这种交叉引用问题的。

-
a出作用域
因为a是在栈中的变量,在出了a的作用域后就会调用a的析构,当析构的时候a的引用计数就会减1,a.use_count=2-1=1;
这时候我问一下,当a出了作用域之后,它里面有一个指针成员,是不是也会跟着调用析构函数释放它所指向的对象呢?
请问当a出了作用域之后,b.use_count=2-1=1么?你想一下b的引用计数会减1么?
因为a的引用计数现在等于1,a的资源不释放,只是把a的引用计数减1,当a的资源不释放,那a.b1也不会释放,所以b.use_count还是等于2;
因为b1是A对象的成员,成员空间的释放是跟着本身对象释放之后,先释放成员,再释放对象自己,而这里对象它自己都没有释放,它的成员b1也不会释放,所以不会调用B的析构,因为shared_ptr析构函数的做法是在shared_ptr这个对象的析构当中把引用计数减1,所以B的引用计数也不会减1,所以这时候b的use_count是等于2的;
那b出作用域能解决这个问题么? -
b出作用域

这就造成这两个对象出了作用域之后,这两个对象都没有释放,这样就产生了循环引用的问题,导致了这个内存泄漏,永远不会释放。
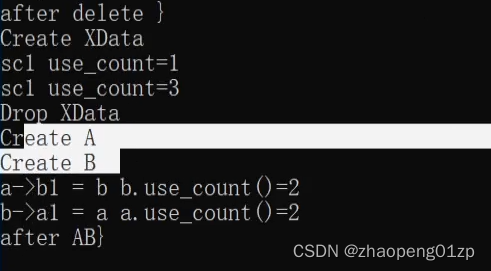
我们从上图可以看到,在Create A和Create B之后,这两个对象没有被释放。
解决循环引用的问题
weak_ptr,弱引用智能指针,它里面就是用来存放shared_ptr的,也就是由它来指向shared_ptr,它之所以称作弱引用,也就是说它的引用不会让shared_ptr的引用计数加1,这样是不是就解决了循环引用的问题呢;
但是,如果它让引用计数不加1,带来的问题是,那干嘛用它来引用呢,这时候我要去用的时候我怎么去确保它指向同一块空间没有加1,那它释放掉了呢,那怎么办呢?
所以说在弱引用的时候,我们还需要知道我们所引用的这块空间有没有被释放掉,而且还要确保能访问它,所以在这里它提供了两个函数。

lock会拿到弱引用所指向的shared_ptr,拿到它之后会复制一份shared_ptr,这时候引用计数会加1,你复制之后当你出了你的作用域之后,你会把它减1,也就是说你会生成一个临时的lock对象,当你使用完之后当然会减1了。

这里的Do函数先不写,我们先看看问题有没有得到解决,再来看它怎么使用:


因为
a->b2 = b;这一步是弱引用,不会把b的引用计数加1,退出的时候B就Drop了,这样就没有循环引用问题了,所以A也Drop了;
虽然没有了循环引用的问题,但是带来了我们使用的问题,那如何使用呢/

我们可以看到lock之后拿到的是一个shared_ptr。


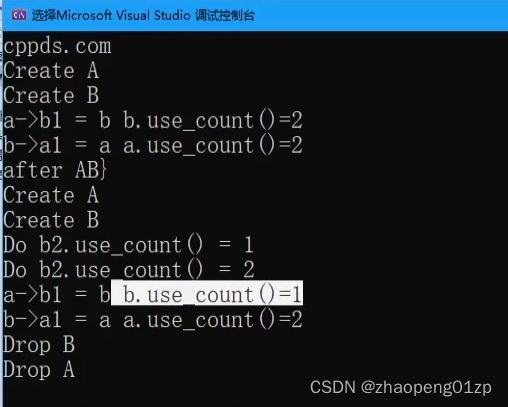
在出了Do函数的作用域之后,b的use_count又等于1,在等整个的a被清理掉之后,b2所指向的b的引用计数也跟着递减了,b的引用计数为0,b也就被清理掉了。
9、指针作为函数参数传递-使用模板传递数组
函数传递输入指针参数的3种形式
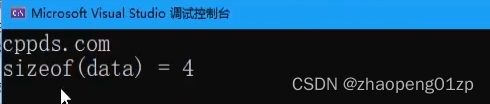
我们可以看到你其实拿到的是一个指针的大小。
我们把函数的参数改成数组的形式:

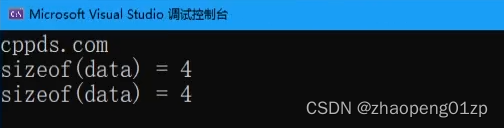
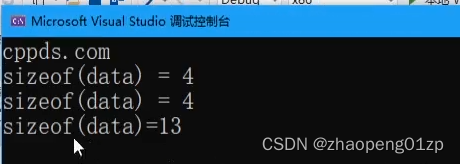
可以看到还是4,也就是说数组在经过传递参数之后,数组会转成指针;
如果说我就想把数组传过去怎么办?我就想在函数中知道传过来的这个数组的大小该怎么办呢?
只有一种方案,就是通过模板的方式,也就是说泛型编程可以做到这一点;
泛型编程它其实还是在编译阶段获取的,它根据你这个直接生成一套代码。
函数传递的指针输出参数
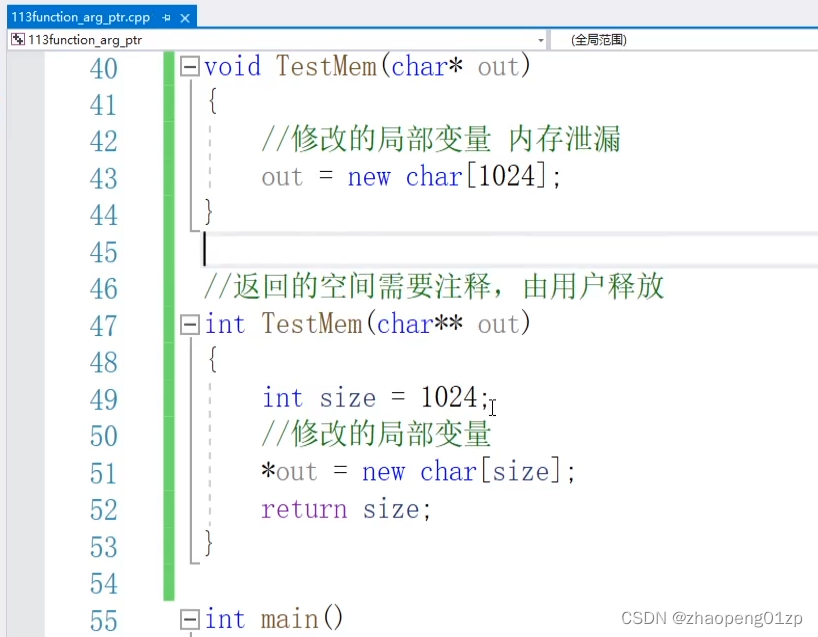

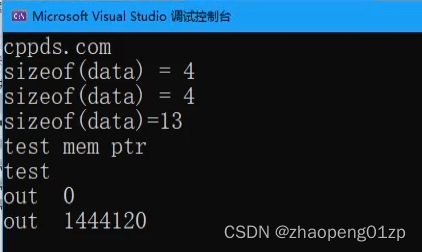
记得写注释告诉函数的调用者,释放在函数中申请的堆空间:




10、智能指针作为函数的参数和返回值unique_ptr
这里我们展示的是unique_ptr,因为shared_ptr相对来说更简单一点,而且shared_ptr的应用场景要谨慎一点,unique_ptr相对来说它的应用场景更多一点。
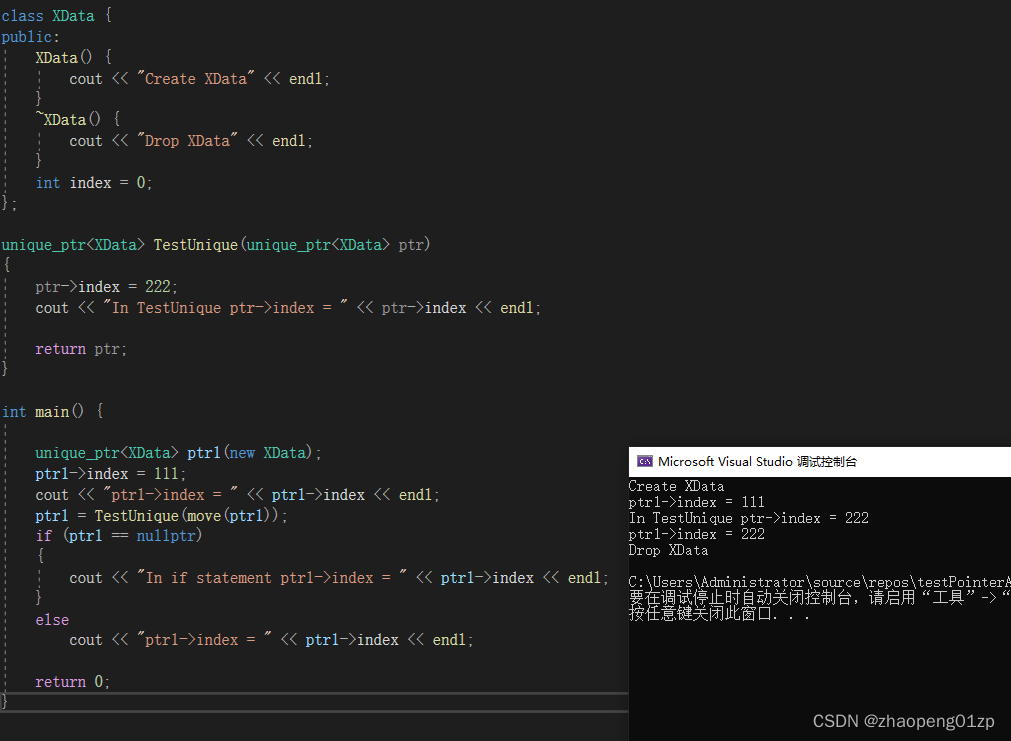
我们写一个函数,它使用智能指针作为参数,也使用智能指针做为返回值来进行传递:



因为unique_ptr它不能够拷贝构造,它只能用移动语义,但是移动到参数之后,这个ptr1其实应该是变成空的了;

所以我们一旦移动进去之后,就是把这个主动权交给到我们的函数内部,而且移动的好处就是我们也不用去管XData空间的申请释放问题了。

我们用一堆大括号把这段测试代码括起来,确保这个智能指针出它的作用域。




我们发现这个智能指针它竟然能从函数中传出来,按道理来说,函数的返回值会重新生成一块空间,是要做复制的,但是这里实际上并没有,它直接返回了;
这里是因为编译器实时做了优化。通过这个例子,我们知道了智能指针是可以直接返回的。
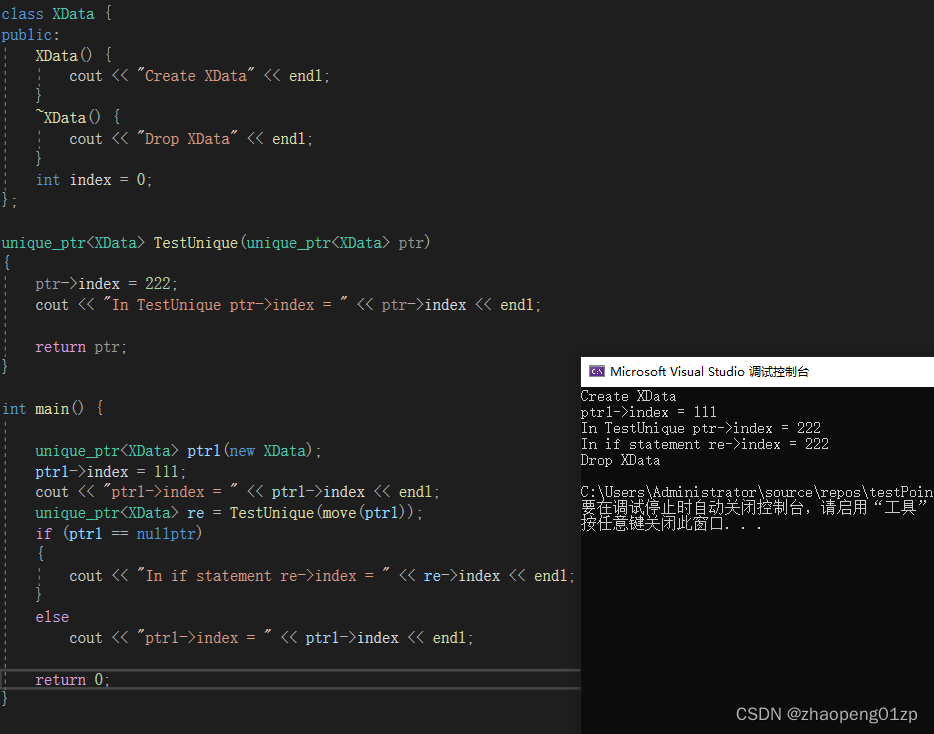
从上图我们知道了,ptr1被move后就成空的了。
11、使用string作为函数参数内存的输入和输出
我们为什么要用string作为参数来传递内存,或者是我们在函数当中的内存通过string传递出来,为什么不用智能指针,或者直接的普通指针来做呢?
因为看到很多的开源库,它的内存的传递、包括内部的实现,都是用string来做的;
用string来做有几个好处:- 它天生就包含了大小;
也就是说,我们在传递内存进去或者出来的时候,其实我们都需要知道这个内存的大小,一般怎么做呢,我们定义一个结构体,里面包含data和size,这是我们自己去定义;
如果我们是在堆当中申请的内存,如果是以指针的方式出去的话,我们需要考虑它什么时候释放,当然了如果是智能指针也能解决这个问题,智能指针的话解决不了的就是对应的内存大小没法知道,所以这时候我们就考虑到用string来做;因为看到的好几个大项目在用它做,所以说它基本是可行的,这项技术能够用在工程当中。
传参就分为两种了,一种是内存的输入,还有一种是内存的输出。


我们就可以通过data()来访问这块内存,比方说我们给这块空间设置值为字符A:




string传参的时候


我们来验证一下这块空间是否被复制了,因为复制是有开销的:

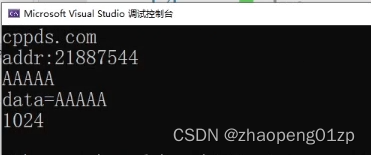
这个data其实是指向我们用string分配的内存空间,我们在TestString函数中也打印一下地址:

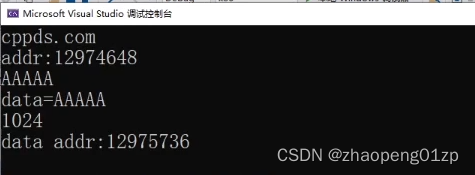
从上图我们可以看到,它其实不是同一块空间,也就是说当我们通过参数传递的时候,这个string它其实是复制了一份,这我们肯定是要避免的,因为我们用指针的目的,其实就是希望用它的同一块空间。
我们可以用引用的方式:


只要把参数设置成引用就没有问题了,我们这块内存空间进入到函数之后不会被复制一份,还是指向原空间。
当我们的空间是在函数内部申请的,我们用string来输出这块内存空间:


对于这里的string来说,它的data是在堆中分配的空间(out_data.resize)。

而通过返回值的方式返回一个string,这种方式有很多问题,所以在string处理内存上面我们就不考虑返回值了,只考虑string作为输入或输出参数。
但是string在这边做内存存储的时候,它其实还有一个问题,就是如果说我们想里面存放固定的类型,比方说存放的是一组对象,那我们怎么操作;
你可能会说,一组对象的话,我们也可以用这个string来存啊,你反正是char*么,如果我们想去操作这组对象呢,这组对象也是在堆中分配的,那我们这时候怎么去处理,这就要用到下一种内存方式,可以用vector来存放内存。12、使用vector传递内存并接收函数返回的内存空间
我们来演示用vector来传递内存和获取内存,也就是说从函数内部把内存传出来,基本等同于string,string可以做的事情它基本也类似,包括这个空间的申请,但是有一些区别:
vector的size()获取的就不是字节数了,它获取的是类型的数量,你要把它转换成字节数的话,你还需要自己去乘以类型的大小,才能得到实际的字节数;
vector跟string还有一个区别就是,vector可以作为返回值,string的返回值会复制一份,而vector返回值使用的是move,move的话就把它移出来了,就不会去做一份复制,我们既然做内存存储,我们肯定不希望它复制,因为复制的话带来的开销是非常大的,所以我们可以用vector传内存的时候return出来,它不会复制。
我们vector里面就存放XData类型的内容。




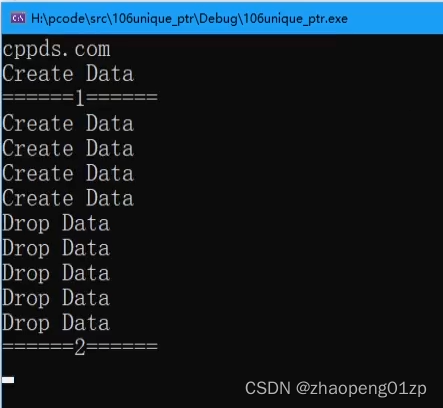
上图这么多Copy是因为我们在做pushback的时候重新给它扩容了。
我们给这段测试代码加上大括号,让它出作用域:

返回的vector中有1024个XData的话太多了,我们修改为3,然后编译运行:
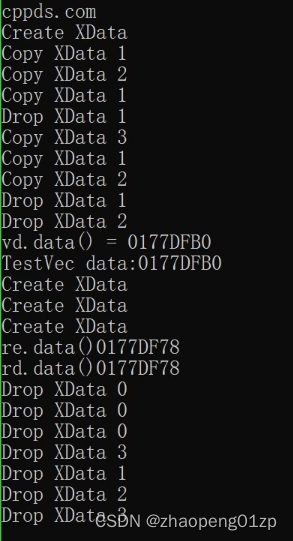
可以看到从函数内部返回的vector,它们的地址一样,它们是同一块空间,在申请空间的过程当中(resize)它其实是做了构造,生成了3个XData对象。

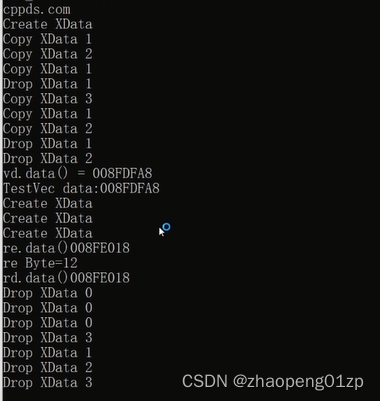
按照正常来说,在函数VecTest中定义的re,应该在函数退出之后就出了re的作用域,re就应该会释放掉了,但是我们看到,在函数退出之后它并没有释放,因为它是在
return re的时候做了一个move操作;
如果在函数中你换成string、返回string的话,它会复制一份返回出去,函数中的string是释放的。最佳方案还是我们把内存传进函数中,在我的内存上做处理。
你实际项目当中,可以用vector或者是string来存放,当然你可以直接用vector或者vector直接存二进制数据就可以了,再根据你的项目情况,而且实际是可以投入到工程项目当中的,当然前提是你先理解了vector和string的复制情况,它什么时候会复制、什么时候会释放。
-
相关阅读:
Linux系统信息收集
R语言—因子
创维E900V22C、E900V22D_线刷固件和卡刷固件及教程
Prometheus监控的搭建(ansible安装——超详细)
如何在Firefox中配置HTTP?
一文读懂野指针
使用Docker部署Java应用:从入门到实践
第2章 进程管理
《Python机器学习与可视化分析实战》简介
【Git】什么是Git以及码云代码托管服务
- 原文地址:https://blog.csdn.net/zhaopeng01zp/article/details/126674324