-
Hadoop运行模式
目录
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:Apache Hadoop
一、本地运行模式
官方Grep案例
1. 创建在hadoop-2.7.2文件下面创建一个input文件夹
mkdir input
2. 将Hadoop的xml配置文件复制到input
cp etc/hadoop/*.xml input
3. 执行share目录下的MapReduce程序
bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
4. 查看输出结果
cat output/*
二、完全分布式运行模式
1、编写集群分发脚本xsync
将三台服务器都放入hadoop和jdk
hadoop103删除文件 hadoop102通过rsync同步数据
(第一次拷贝推荐用scp,之后用sync)
- cd /opt/module/
- 将本地文件推发送给局域网服务器
- scp -r jdk1.8.0_212/ root@hadoop103:/opt/module/
- 输入yes
- 输入密码
- 拉取局域网的文件
- scp -r root@hadoop102:/opt/module/hadoop-3.1.3 ./
- 将102服务器的工具拷贝到104
- scp -r root@hadoop102:/opt/module/* root@hadoop104:/opt/module/
- rm -rf wcinput
- rsync -av hadoop-3.1.3/ root@hadoop103:/opt/module/hadoop-3.1.3/
创建脚本并执行,然后输入其他两个服务器的密码

- cd /usr/local/
- mkdir bin
- vim xsync
- #!/bin/bash
- #1 获取输入参数个数,如果没有参数,直接退出
- pcount=$#
- if((pcount==0)); then
- echo no args;
- exit;
- fi
- #2 获取文件名称
- p1=$1
- fname=`basename $p1`
- echo fname=$fname
- #3 获取上级目录到绝对路径
- pdir=`cd -P $(dirname $p1); pwd`
- echo pdir=$pdir
- #4 获取当前用户名称
- user=`whoami`
- #5 循环
- for((host=103; host<105; host++)); do
- echo ------------------- hadoop$host --------------
- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
- done
- xsync /usr/local/bin
配置环境变量
- 102服务器
- xsync /etc/profile.d/my_env.sh
- 103服务器、104服务器都执行
- source /etc/profile
2、SSH无密登录配置

① 进入用户目录,输入 ls -al查看隐藏目录,如果没有ssh文件 连接自己建立ssh文件
如果是root用户,输入 cd
ll -al可以看到.ssh文件
ssh localhost②跟103和104建立连接,实现免密登录
- cd .ssh/
- 按三下enter,建立自己的密钥
- ssh-keygen -t rsa
- ssh-copy-id hadoop102
- ssh-copy-id hadoop103
- ssh-copy-id hadoop104

输入ssh hadoop102实现无密码直接进入
进入103、104重新执行一下上述操作
3、集群配置
- vim core-site.xml
- <!-- 指定HDFS中NameNode的地址 -->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://hadoop102:8020</value>
- </property>
- <!-- 指定Hadoop运行时产生文件的存储目录 -->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/module/hadoop-3.1.3/data</value>
- </property>
- vi hdfs-site.xml
- <property>
- <name>dfs.namenode.http-address</name>
- <value>hadoop102:9870</value>
- </property>
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>hadoop104:9868</value>
- </property>
- vim yarn-site.xml
- <!-- Reducer获取数据的方式 -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <!-- 指定YARN的ResourceManager的地址 -->
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>hadoop103</value>
- </property>
- <property>
- <name>yarn.nodemanager.env-whitelist</name>
- <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
- </property>
- vim mapred-site.xml
- <!-- 指定MR运行在Yarn上 -->
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
给103、104分发文件
- cd /usr/local/bin
- xsync /opt/module/hadoop-3.1.3/
- 进入103
- cd /opt/module/hadoop-3.1.3/etc/hadoop/
- vim core-site.xml
4、群起集群并测试
给102配置workers,并分发给103,104
- cd /opt/module/hadoop-3.1.3/etc/hadoop/
- vim workers
- hadoop102
- hadoop103
- hadoop104
- xsync workers
将102初始化,如果文件夹里有 data和logs文件夹先删掉要不然启动失败
- cd /opt/module/hadoop-3.1.3/
- hdfs namenode -format
- cd data/dfs/name/current/
- vim VERSION
- namespaceID=8697062
- clusterID=CID-ab379c11-26c3-4584-b0f3-5e992ecb9628
- cTime=1669127949039
- storageType=NAME_NODE
- blockpoolID=BP-745685491-192.168.48.102-1669127949039
- layoutVersion=-64
编辑启动和停止文件,防止启动集群失败,并同步服务器
- vim sbin/start-dfs.sh
- vim sbin/stop-dfs.sh
- HDFS_DATANODE_USER=root
- HADOOP_SECURE_DN_USER=hdfs
- HDFS_NAMENODE_USER=root
- HDFS_SECONDARYNAMENODE_USER=root
- vim sbin/start-yarn.sh
- vim sbin/stop-yarn.sh
- YARN_RESOURCEMANAGER_USER=root
- HADOOP_SECURE_DN_USER=yarn
- YARN_NODEMANAGER_USER=root
- xsync start-dfs.sh
- xsync stop-dfs.sh
- xsync start-yarn.sh
- xsync stop-yarn.sh
最后启动集群
- 102,启动dfs
- sbin/start.dfs.sh
- 用jps查看结果


输入http://hadoop102:9870/dfshealth.html#tab-overview
 http://hadoop102:9870/dfshealth.html#tab-overview
http://hadoop102:9870/dfshealth.html#tab-overview
进入103,输入 sbin/start-yarn.sh 和jps

进入 104,输入jps

输入 地址启动成功
http://http:/hadoop03:8088/cluster
http://http:/hadoop03:8088/cluster
1、集群测试,hdfs上传文件到集群
hadoop fs -mkdir /wcinput
①上传小文件到文件夹发现文件夹下多了一个文件并且可以预览
hadoop fs -put wcinput/word.txt /wcinput
②上传大文件到集群
hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /

查看上传的文件位置
- cd data/dfs/data/current/BP-1360615751-192.168.48.102-1669300615773/current/finalized/subdir0/subdir0/
- vim blk_1073741825


将上传的jdk还原到压缩包并解压
- cat blk_1073741826 >> tmp.tar.gz
- cat blk_1073741827 >> tmp.tar.gz
- tar -zxvf tmp.tar.gz

并且可以看到103,104都有此文件夹


执行 wordcout程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput

集群异常处理
问题
将102、103、104的data删除
发现文件下载失败
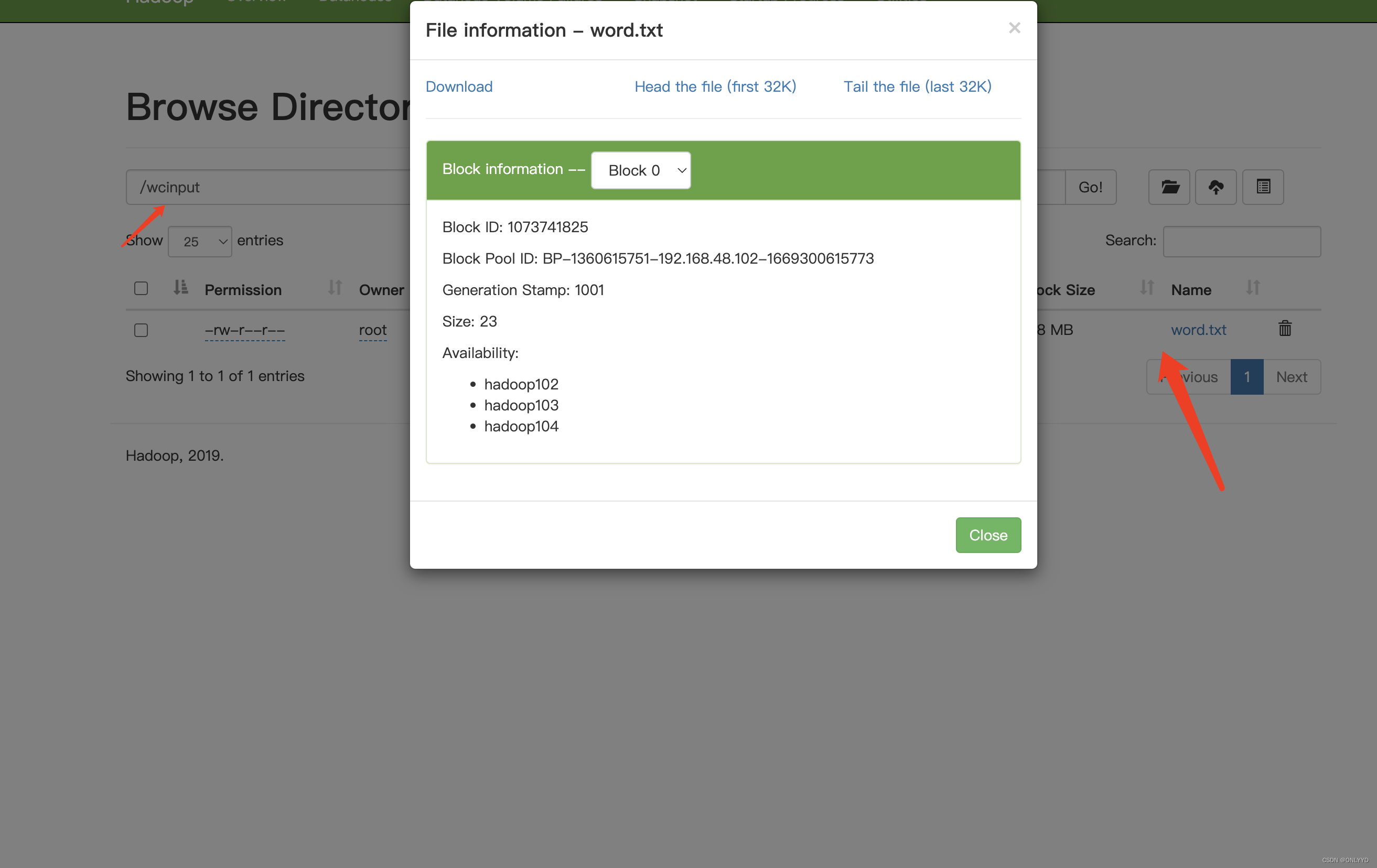
解决方案
- 将服务器的data和log都删掉
- rm -rf data/ logs/
- 格式化
- hdfs namenode -format
- 启动hdfs
- sbin/start-dfs.sh
配置历史服务器
- cd /opt/module/hadoop-3.1.3/etc/hadoop/
- vim mapred-site.xml
- <!-- 历史服务器端地址 -->(内部通讯端口)
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>hadoop102:10020</value>
- </property>
- <!-- 历史服务器web端地址 -->(访问地址)
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>hadoop102:19888</value>
- </property>
- xsync mapred-site.xml
- cd /opt/module/hadoop-3.1.3/
- bin/mapred --daemon start historyserver
- jps

- hadoop fs -mkdir /input
- hadoop fs -put wcinput/word.txt /input
- hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output

配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
- cd /opt/module/hadoop-3.1.3/etc/hadoop/
- vim yarn-site.xml
- <!-- 开启日志聚集功能 -->
- <property>
- <name>yarn.log-aggregation-enable</name>
- <value>true</value>
- </property>
- <!-- 设置日志聚集服务器地址 -->
- <property>
- <name>yarn.log.server.url</name>
- <value>http://hadoop102:19888/jobhistory/logs</value>
- </property>
- <!-- 设置日志保留时间为7天 -->
- <property>
- <name>yarn.log-aggregation.retain-seconds</name>
- <value>604800</value>
- </property>
- ##102关闭HistoryManager
- mapred --daemon stop historyserver
- ##103关闭NodeManager
- sbin/stop-yarn.sh
- ##103启动NodeManager
- sbin/start-yarn.sh
- ##102启动HistoryManager


集群启动/停止方式总结
1)各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
2)各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
(2)启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
编写Hadoop集群常用脚本
启动和停止所有集群脚本
- cd /usr/local/
- vim myhadoop.sh
- #!/bin/bash
- if [ $# -lt 1 ]
- then
- echo "No Args Input..."
- exit ;
- fi
- case $1 in
- "start")
- echo " =================== 启动 hadoop集群 ==================="
- echo " --------------- 启动 hdfs ---------------"
- ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
- echo " --------------- 启动 yarn ---------------"
- ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
- echo " --------------- 启动 historyserver ---------------"
- ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
- ;;
- "stop")
- echo " =================== 关闭 hadoop集群 ==================="
- echo " --------------- 关闭 historyserver ---------------"
- ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
- echo " --------------- 关闭 yarn ---------------"
- ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
- echo " --------------- 关闭 hdfs ---------------"
- ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
- ;;
- *)
- echo "Input Args Error..."
- ;;
- esac
- chmod +x myhadoop.sh
- 停止集群
- ./myhadoop.sh stop

./myhadoop.sh start
查看集群脚本
- vim jpsall
- #!/bin/bash
- for host in hadoop102 hadoop103 hadoop104
- do
- echo =============== $host ===============
- ssh $host jps
- done
- chmod 777 jpsall
- jpsall
-
相关阅读:
优化代码 —— 减少 if - else
CVE-2016-3088漏洞复现
TFT-LCD屏幕显示ASCII字符和字符串
第二章 算法
Leetcode 剑指 Offer II 048. 二叉树的序列化与反序列化
specCPU 2006 备忘
mysql多表查询
介绍java中Pair和Map的区别
原生JavaScript实现video视频控制栏
通过itextpdf向PDF文件最后一页添加图片
- 原文地址:https://blog.csdn.net/ONLYYD/article/details/127949713
