-
【微服务治理之监控APM】系统监控架构概述
APM 简介
APM 通常认为是 Application Performance Management 的简写,它主要有三个方面的内容,分别是
- Logs(日志)、
- Traces(链路追踪)
- Metrics(报表统计)。
以后大家接触任何一个 APM 系统的时候,都可以从这三个方面去分析它到底是什么样的一个系统。Metrics可以用于服务告警,Tracing 和 Logging 用于调试发现问题。监控、追踪和日志是可观测性(observability)的基石
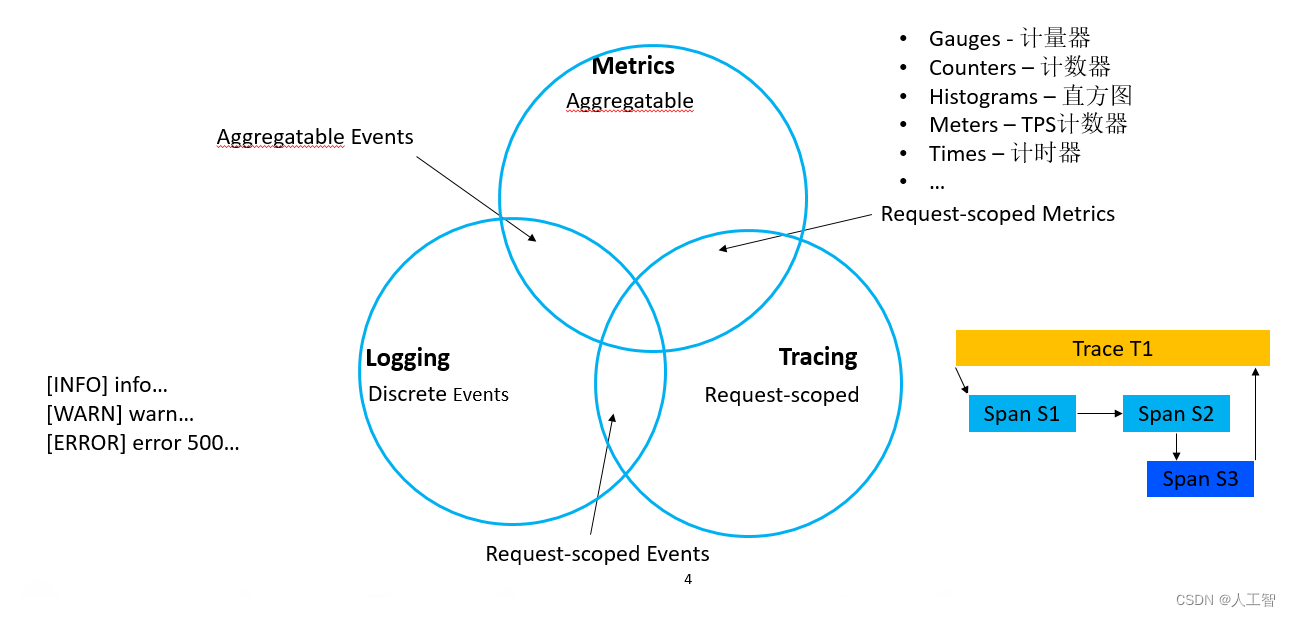
有些场景中,APM 特指上面三个中的 Metrics,我们这里不去讨论这个概念。这节我们先对这 3 个方面进行介绍,同时介绍一下这 3 个领域里面一些常用的工具。
1、Metrics
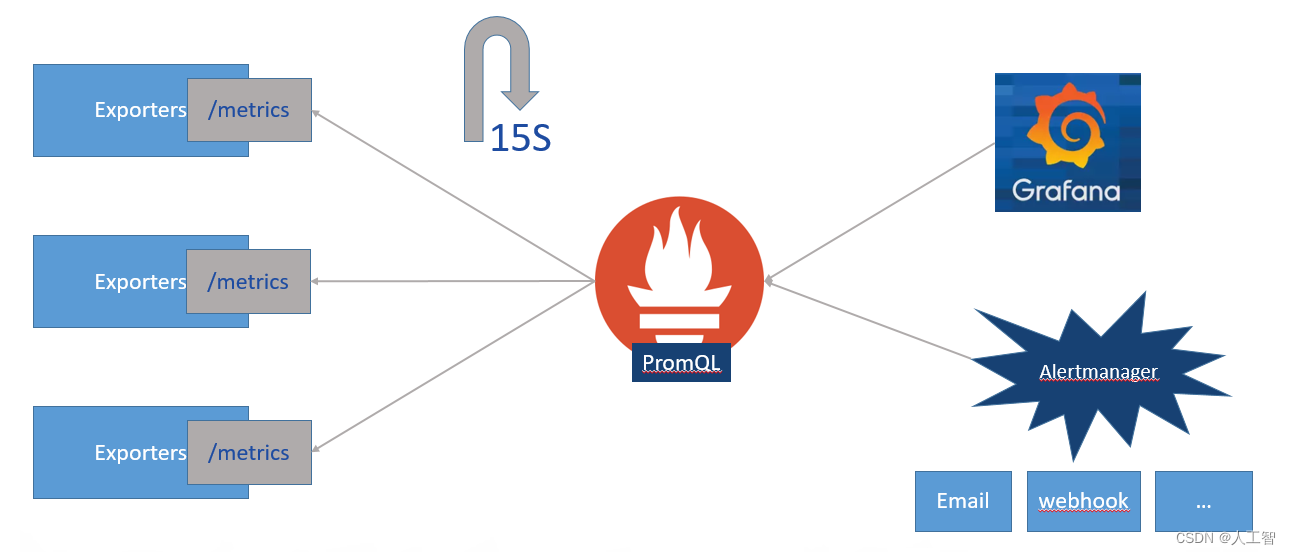
Prometheus:收集度量标准
告警管理器:根据指标查询向各种提供者发送警报
Grafana:把prometheus收集到的数据,变成可视化豪华仪表板
还有一个方案是使用美团开源监控系统CAT,提供了比较全面的实时监控告警服务。
优势:监控功能强大,基本上可以覆盖各种监控场景
劣势:接入成本较高、对业务代码侵入较大1、Logs ,就是对个应用中打印的 log 进行收集和提供查询能力。
- Logs 的典型实现是 ELK (ElasticSearch、Logstash、Kibana),三个项目都是由 Elastic 开源,其中最核心的就是 ES 的储存和查询的性能得到了大家的认可,经受了非常多公司的业务考验。Logstash 负责收集日志,然后解析并存储到 ES。通常有两种比较主流的日志采集方式,一种是通过一个客户端程序 FileBeat,收集每个应用打印到本地磁盘的日志,发送给 Logstash;另一种则是每个应用不需要将日志存储到磁盘,而是直接发送到 Kafka 集群中,由 Logstash 来消费。
Kibana 是一个非常好用的工具,用于对 ES 的数据进行可视化,简单来说,它就是 ES 的客户端。
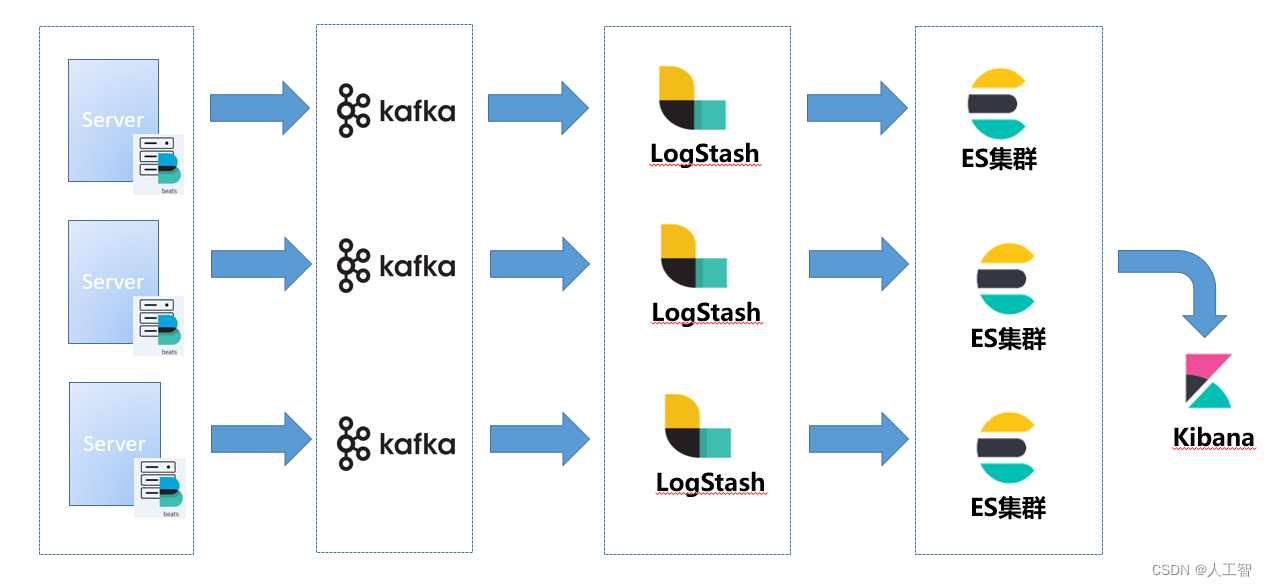
我们回过头来分析 Logs 系统,Logs 系统的数据来自于应用中打印的日志,它的特点是数据量可能很大,取决于应用开发者怎么打日志,Logs 系统需要存储全量数据,通常都要支持至少 1 周的储存。
每条日志包含 ip、thread、class、timestamp、traceId、message 等信息,它涉及到的技术点非常容易理解,就是日志的存储和查询。
使用也非常简单,排查问题时,通常先通过关键字搜到一条日志,然后通过它的 traceId 来搜索整个链路的日志。
题外话,Elastic 其实除了 Logs 以外,也提供了 Metrics 和 Traces 的解决方案,不过目前国内用户主要是使用它的 Logs 功能。
2、 Traces 系统,它用于记录整个调用链路。
前面介绍的 Logs 系统使用的是开发者打印的日志,所以它是最贴近业务的。而 Traces 系统就离业务更远一些了,它关注的是一个请求进来以后,经过了哪些应用、哪些方法,分别在各个节点耗费了多少时间,在哪个地方抛出的异常等,用来快速定位问题。
经过多年的发展,Traces 系统虽然在服务端的设计很多样,但是客户端的设计慢慢地趋于统一,所以有了 OpenTracing 项目,我们可以简单理解为它是一个规范,它定义了一套 API,把客户端的模型固化下来。
微服务架构普及,分布式追踪系统大量涌现,但API互不兼容,难以整合和切换,因此OpenTracing提出了统一的平台无关、厂商无关的API,不同的分布式追踪系统去实现。这种作用与“JDBC”类似。
OpenTracing是一个轻量级的标准化层,位于“应用程序/类库”和“日志/追踪程序”之间。
应用程序/类库层示例:开发者在开发应用代码想要加入追踪数据、ORM类库想要加入ORM和SQL的关系、HTTP负载均衡器使用OpenTracing标准来设置请求、跨进程的任务(gRPC等)使用OpenTracing的标准格式注入追踪数据。所有这些,都只需要对接OpenTracing API,而无需关心后面的追踪、监控、日志等如何采集和实现。
当前比较主流的 Traces 系统中**,Jaeger、SkyWalking** 是使用这个规范的,而 Zipkin、Pinpoint 没有使用该规范。SkyWalking 在国内应该比较多公司使用,是一个比较优秀的由国人发起的开源项目,已进入 Apache 基金会。
另一个比较好的开源 Traces 系统是由韩国人开源的 Pinpoint,它的打点数据非常丰富。国内用skywalking比较好,有成熟的社区,可以加群和创始人沟通。
 Skywalking目前想要做成跟踪、监控、日志一体的解决方案(Tracing, Metrics and Logging all-in-one solution)。
Skywalking目前想要做成跟踪、监控、日志一体的解决方案(Tracing, Metrics and Logging all-in-one solution)。
数据收集:Tracing依赖探针(Agent),Metrics依赖Prometheus或者新版的Open Telemetry,日志通过ES或者Fluentd。
数据传输:通过kafka、Grpc、HTTP传输到Skywalking Reveiver
数据解析和分析:OAP系统进行数据解析和分析。
数据存储:后端接口支持多种存储实现,例如ES。
UI模块:通过GraphQL进行查询,然后通过VUE搭建的前端进行展示。
告警:可以对接多种告警,最新版已经支持钉钉。参考:
1、https://developer.aliyun.com/article/971591?spm=a2c6h.14164896.0.0.5b90c520Bz1nGI
2、https://developer.aliyun.com/article/1053064
3、https://blog.51cto.com/mingongge/3313415 -
相关阅读:
2.linux的组管理和权限管理
ios面试准备 - 网络篇
1.8-07:矩阵归零消减序列和
经典的风控授信流程与增信策略
网页颜色搭配表及颜色搭配技巧
接口自动化测试之预期结果的处理
(未解决)执行git rebase提示:Current branch xxx is up to date.
JCMsuite应用:光子晶体谐振腔光子晶体谐振腔
Pytoch随笔(光速入门篇)
全排列:让我看到未来所有的可能 -> 跨越CV小白的回溯算法
- 原文地址:https://blog.csdn.net/qq_35789269/article/details/127941093