-
深度可分离卷积神经网络与卷积神经网络
在学习语义分割过程中,接触到了深度可分离卷积神经网络,其是对卷积神经网络在运算速度上的改进,具体差别如下:
一些轻量级的网络,如mobilenet中,会有深度可分离卷积depthwise separable convolution,由depthwise(DW)和pointwise(PW)两个部分结合起来,用来提取特征feature map
相比常规的卷积操作,其参数数量和运算成本比较低
常规卷积操作
对于一张5×5像素、三通道(shape为5×5×3),经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4,最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3
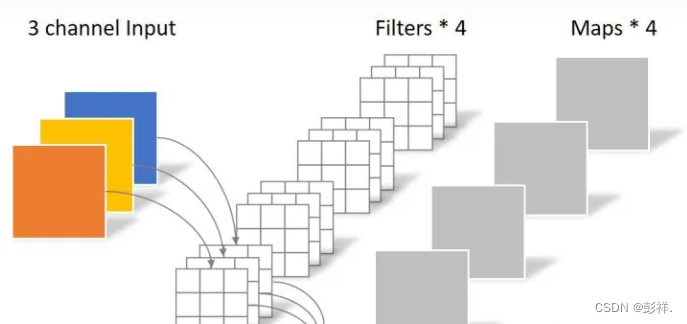
卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:N_std = 4 × 3 × 3 × 3 = 108
深度可分离卷积
逐通道卷积
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
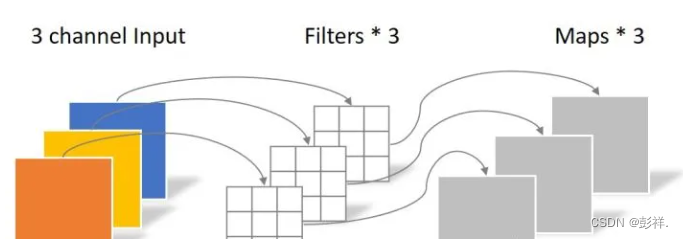
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:N_depthwise = 3 × 3 × 3 = 27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map
逐点卷积
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map
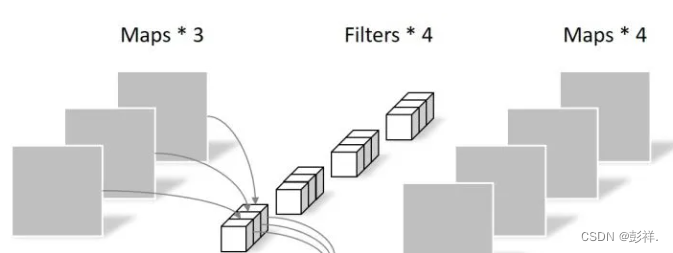
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同参数对比
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
不足:
accuracy可能会下降,如果是按层数来算的话,因为每个depthconv没有跨通道的信息,即使之后通过pointconv去弥补,pointconv又缺乏空间上的关联信息,理论上会差一些。
当然了,效果还是看具体数据集和任务,没法一概而论。不过参数和计算量的节省也带来了好处,要说理论上,FC啥都能干,但是参数太多实际上根本训练不出那么好的效果。网络的深度对于网络的能力来说提升是比较大的,把节省下来的参数和计算量放到深度上,效果可能就会更好了。 -
相关阅读:
Python基础之SQLite数据库
【Go语言从入门到实战】基础篇
【每日一题】除法求值
1992-2021年省市县经过矫正的夜间灯光数据(GNLD、VIIRS)
C语言实现线索化二叉树(先序、中序、后序)
Vue学习之--------脚手架的分析、Ref属性、Props配置(2022/7/28)
java计算机毕业设计项目材料管理系统源码+系统+数据库+lw文档+mybatis+运行部署
JavaSE——抽象类和接口详解
基于Dockerfile创建镜像
web网站学习 apache (一)
- 原文地址:https://blog.csdn.net/pengxiang1998/article/details/127941414