-
进程的虚拟地址空间
每个程序运行起来后,都拥有一个自己的虚拟地址空间(注意是虚拟的,不是实际存在的),这个虚拟地址空间的大小由计算机的硬件平台
关于虚拟的概念,当时IBM给出了一种说法很形象生动:
它存在,你能看得见,它是物理的
它存在,你看不见,它是透明的
它不存在,你却看得见,它是虚拟的
它不存在,你也看不见,它被删除了!决定,具体地说是由CPU位数决定的。硬件决定了地址空间的最大理论上限,即硬件的寻址空间大小,比如32位的硬件平台决定了虚拟地址空间的地址为0到2^32 - 1,即0x00000000~0xFFFFFFFF,也就是我们常说的4GB虚拟空间大小,也就是它只有4GB的寻址能力。
现在让我们来看一下x86体系下32位Linux环境中进程虚拟地址空间:
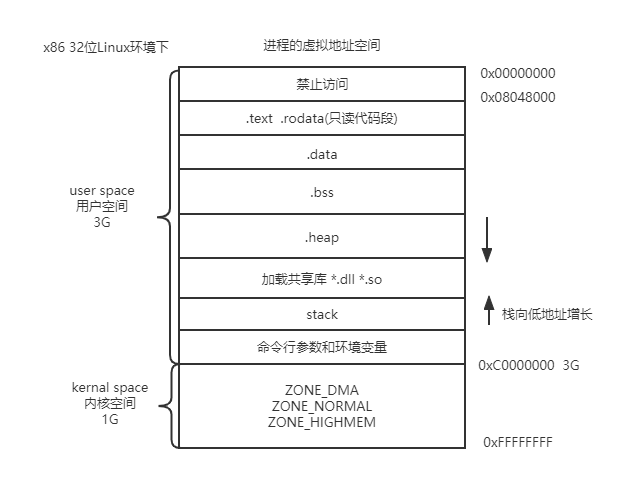
了解了地址空间,我们就能对程序有更深入的理解。
这里介绍一下每一节中存放的内容:.text:已编译程序的机器代码 .rodata:只读数据,比如printf语句中的格式串和开关语句的跳转表 .data:已初始化的全局和静态变量。注意局部变量在运行时被保存在栈中,既不出现在.data节中,也不出现在.bss节中 .bss:未初始化的全局和静态变量,以及所有被初始化为0的全局或静态变量。这个节不占据实际的空间,它仅仅是一个占位符。 区分已初始化和未初始化变量是为了空间效率,未初始化变量不需要占据任何实际的磁盘空间。运行时,在内存中分配这些变量,初始值为0- 1
- 2
- 3
- 4
- 5
一种记住.data和.bss节之间区别的简单方法是把“bss”看成是“更好地节省空间(Better Save Space)的缩写”(.bss中的值都为0)
举个例子:
int gdata1 = 10; int gdata2 = 0; int gdata3; static int gdata4 = 11; static int gdata5 = 0; static int gdata6; int main() { int a = 12; int b = 0; int c; static int e = 13; static int f = 0; static int g; cout << c << g << endl; //c不为零,g为零 system("pause"); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
根据上面的规则,各个变量存放在哪块内存呢?
gdata1和gdata4初始化且不为0,存放在.data段 gdata2、gdata3、gdata5、gdata6未初始化或初始化为0,存放在.bss段 a,b,c不会产生符号,编译成指令,指令存放在.text段 mov dword ptr[a], 0ch e初始化了,且不为0,存放在.data段 f和g初始化为0,或未初始化,存放在.bss段 注意一点,虽然a变量是局部变量,存放在栈上, 但有一点需要明确a = 12编译后生成指令,存放在.text段,只是在运行时,在栈上开辟空间- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
知道了每节存放的内容,或许就能更好的理解程序
比如,为什么有时会发生栈溢出(stack overflow)?
栈向低地址增长,栈空间是有限的,当递归函数递归太深就会爆栈(关于函数调用是如何开辟栈空间的之后再谈)为什么程序常常会出现”段错误(segment fault)“或”非法操作,该内存地址不能read/write“的错误信息?
这往往是因为指针指向一个不允许读或写的内存地址,而程序却试图利用指针来读写该地址的时候,就会出现这个错误。在Linux或Windows的内存布局中,有些地址是始终不能读写的,例如0地址。还有这样的程序为什么报错?
char *p = "hello, world"; *p = 'a';- 1
- 2
因为”hello, world“作为字符串常量存放在只读数据段中,修改只读数据段当然不可以。
等等,当我们之后遇到此类问题时,都可以想想它在内存中是怎么存储的,从而明白为什么出错。
一些小点:
1.栈通常只有数兆字节的大小,而堆一般比栈大很多可以有几十至数百兆字节的容量。程序使用malloc或new分配内存时得到的内存都来自堆里。
2.Windows在默认情况下会将高地址的2GB空间分配给内核(也可配置为1GB),而Linux默认情况下将高地址的1GB空间分配给内核。思考,数据什么时候可以放在栈上,什么时候又需要放在堆上呢?
栈是程序运行的基础,函数调用的过程中,通过移动栈指针开辟足够的空间,用来存放函数使用到的局部变量,以及函数中使用到的通用寄存器的副本(以便在函数调用结束后,通过副本可以恢复到函数调用之前)。编译器编译并优化代码时,一个函数就是一个最小的编译单元,所以在编译阶段,编译器就得知道要存放哪些局部变量和寄存器,以便预留空间。所以编译期可以确定大小的”放在“(预留,运行时开辟)栈上,对于无法确定大小或大小可以改变的数据,最好放在堆上。除了动态大小的需要放在堆上,动态生命周期的内存也需要分配到堆上。因为栈上的内存在函数调用结束后,会被回收(实则是改变栈指针,数据并不会被清空),对于栈上内存的生命周期是不受开发人员控制的,局限在当前调用栈中。而堆上开辟的内存需要显式释放,因此堆上的内存就有更加灵活的生命周期,可以在不同的调用栈之间共享数据。总结下来,栈上的数据是静态的,大小固定,生命周期固定,而堆上的数据是动态的,大小不固定,生命周期不固定。以上便是进程的虚拟地址空间的介绍,这里只关注了几个常用的节,关于这部分知识点很多,之后继续总结。
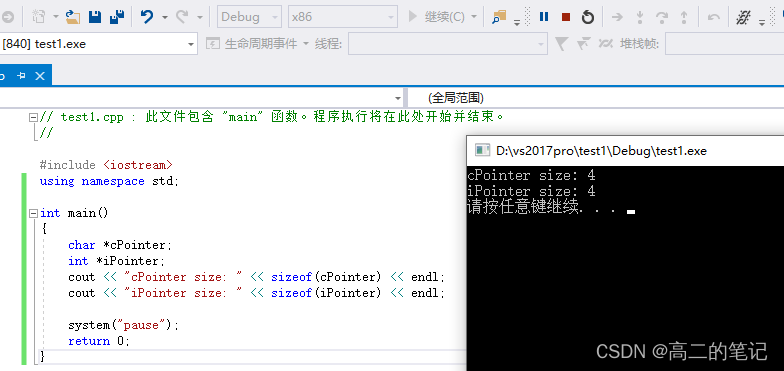
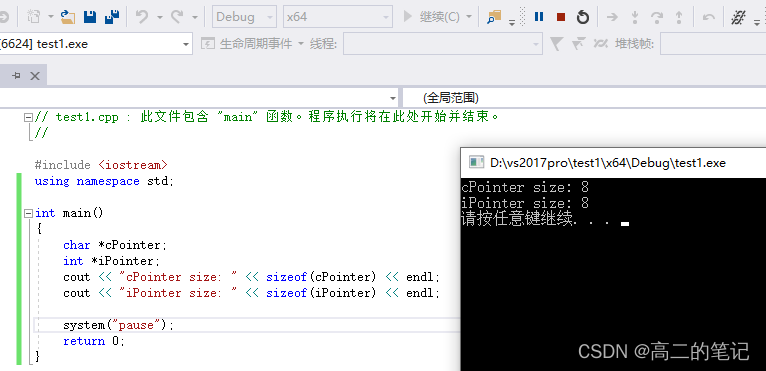
正文结束,这里通过一个小例子来测试指针在不同平台下、不同类型下的大小:
一般来说,C语言指针大小的位数与虚拟空间的位数相同,如32位平台下的指针为4字节,64位平台下的指针为8字节。这里有一个经典的面试题,就是问指针大小,比如32位操作系统下,int *p和char *p,p的大小是多大? 都是4字节,因为p是指针类型,p存放的是内存地址,与类型无关。- 1
- 2
32位环境下:
64位环境下:
参考资料:
[1] 龚奕利,贺莲译.深入理解计算机系统[M].北京:机械工业出版社,2016.
[2] 俞甲子,石凡,潘爱民著.程序员的自我修养:链接、装载与库[M].北京:电子工业出版社,2009.4 -
相关阅读:
Day13--自定义组件-封装自定义属性和click事件
通讯录实现之进阶版将通讯录数据保存在文件中(完整代码)
算法-分数
GoLong的学习之路(三)语法之运算符
[Linux](8)进程地址空间
全国各个省份市区县明细数据
leetcode:887. 鸡蛋掉落【经典dp定义】
R-CNN 详解
RADIUS 如何提高 WiFi 无线网络安全性?
秒懂Groovy【仅限于Java开发者】
- 原文地址:https://blog.csdn.net/gaoyuelon/article/details/127815765
