-
[Linux](8)进程地址空间
验证地址空间
学C语言时我们应该见过这样的图:
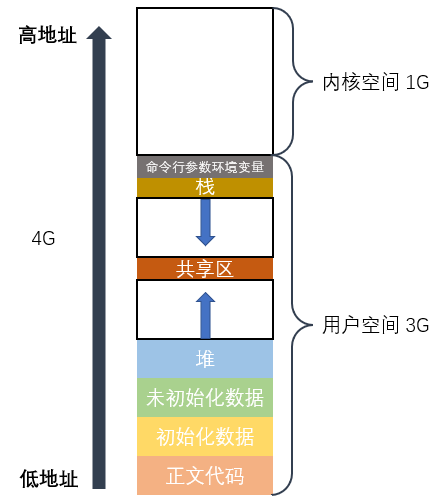
如何理解它呢?
根据这张图,在 Linux 下我们可以按由低到高的顺序,把各个分区的变量的地址打印出来:
#include#include int un_g_val; int g_val = 100; int main(int argc, char* argv[], char* env[]) { printf("code addr: %p\n", main); printf("init global addr: %p\n", &g_val); printf("uninit global addr: %p\n", &un_g_val); char* m1 = (char*)malloc(100); printf("heap addr: %p\n", m1); printf("stack addr: %p\n", &m1); for (int i = 0; i < argc; ++i) { printf("argv addr: %p\n", argv[i]); } for (int i = 0; env[i]; ++i) { printf("env addr: %p\n", env[i]); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
结果:
[CegghnnoR@VM-4-13-centos 2022_8_15]$ ./mytest code addr: 0x40057d init global addr: 0x60103c uninit global addr: 0x601044 heap addr: 0xd50010 stack addr: 0x7ffe2043a400 argv addr: 0x7ffe2043a76a env addr: 0x7ffe2043a773 env addr: 0x7ffe2043a789 env addr: 0x7ffe2043a7a1 #以下均为环境变量地址:略。。。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
👆地址确实是依次增大的。并且在堆和栈之间出现了一个非常大的断层。
堆区向上增长,栈区向下增长:
不断申请堆区空间
char* m1 = (char*)malloc(100); char* m2 = (char*)malloc(100); char* m3 = (char*)malloc(100); char* m4 = (char*)malloc(100); printf("heap addr1: %p\n", m1); printf("heap addr2: %p\n", m2); printf("heap addr3: %p\n", m3); printf("heap addr4: %p\n", m4); printf("stack addr1: %p\n", &m1); printf("stack addr2: %p\n", &m2); printf("stack addr3: %p\n", &m3); printf("stack addr4: %p\n", &m4);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
堆区空间的地址是逐渐增大的:
heap addr1: 0x215c010 heap addr2: 0x215c080 heap addr3: 0x215c0f0 heap addr4: 0x215c160- 1
- 2
- 3
- 4
栈区变量的地址是逐渐减小的:
stack addr1: 0x7ffeecce37a0 stack addr2: 0x7ffeecce3798 stack addr3: 0x7ffeecce3790 stack addr4: 0x7ffeecce3788- 1
- 2
- 3
- 4
堆栈相对而生,我们在C函数中定义的变量,通常在栈上保存,那么先定义的一定是地址比较高的。
函数内定义
static变量,本质是编译器会把该变量编译进全局数据区。static int a = 3; printf("static addr: %p\n", &a);- 1
- 2
static addr: 0x601040- 1
地址空间的存在
让父子进程分别打印全局变量的值和地址
#include#include #include #include int g_val = 100; int main() { pid_t id = fork(); if (id == 0) { //child while (1) { printf("我是子进程:%d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val); sleep(1); } } else { //parent while (1) { printf("我是父进程:%d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val); sleep(2); } } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
[CegghnnoR@VM-4-13-centos 2022_8_15]$ ./mytest 我是父进程:2840, ppid: 14100, g_val: 100, &g_val: 0x601054 我是子进程:2841, ppid: 2840, g_val: 100, &g_val: 0x601054- 1
- 2
- 3
父子进程打印的全局变量值和地址是一致的,由此可以得出:
当父子进程没有修改全局数据的时候,父子是共享该数据的。
下面对子进程部分进行修改,让它 5 秒后修改全局变量:
//child int flag = 0; while (1) { printf("我是子进程:%d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val); sleep(1); ++flag; if (flag == 5) { g_val = 200; printf("我是子进程,我已修改全局数据\n"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
#修改前同上。。。 我是子进程,我已修改全局数据 我是子进程:5081, ppid: 5080, g_val: 200, &g_val: 0x60105c 我是父进程:5080, ppid: 14100, g_val: 100, &g_val: 0x60105c- 1
- 2
- 3
- 4
现象:子进程的
g_val确实改成了200,父进程的没改,但是他们的地址却都一样。也就是说,父子进程读取的是同一个变量,但是在后续有修改的情况下,父子进程读取到的内容却不一样。
结论:我们在 C/C++ 中使用的地址,不是物理地址!
它其实是虚拟地址,也叫线性地址,逻辑地址
虚拟地址可以通过页表映射到物理地址。
概念
每一个进程在启动的时候,都会让操作系统为其创建一个地址空间,该地址空间就是进程地址空间。
同样的,操作系统也要管理这些进程地址空间,所以它其实是内核的一个数据结构
struct mm_struct为了维护进程的独立性,进程地址空间让每个进程都认为自己是独占系统中的所有资源的。
所谓进程地址空间,其实就是OS通过软件的方式,给进程提供一份软件视角,认为自己会独占系统的所有资源(主要是内存资源)。
在内核里的具体实现是,
task_struct(PCB)内有指针指向mm_struct(进程地址空间),mm_struct内有指针指向一个链表,链表的每一个结点有start和end表示一块分区,还有一个指针,指向页表。
❓程序是如何变成进程的?
-
代码被编译出来,还没有被加载进内存的时候,程序内部就已经有地址和分区了。
readelf -S [可执行程序]显示的就是程序内部的各种区域。 -
这种地址是一种相对地址,当加载到内存里的时候,利用它在内存里的第一个位置和相对位置偏移量就可以转化成虚拟地址,并建立页表。
❓为什么父子进程全局变量的地址一样,读取到的内容却不一样?
-
在没有修改的时候,确实是共享同一块空间。当有进程要修改全局变量时,操作系统会重新开辟一段空间,并替换页表中的物理地址,使原来的虚拟地址映射到一个新的物理地址。
-
也就是说,页表只有物理地址改了,虚拟地址不变,所以我们看到的地址是一样的,但实际上两个进程通过各自的页表映射到了不同的物理空间,读取的值也就不一样了。
-
操作系统给修改的一方重新开辟空间,并把原来的数据拷贝到新的空间的行为叫做写时拷贝。
❓
pid_t id = fortk()中,同一个id变量,为什么会有不同的值?pid_t id是属于父进程栈空间中定义的变量,fork 内部会创建一个进程,程序运行到 return 前就已经有两个进程了,所以 return 会被执行两次,而 return 的本质,就是通过寄存器将返回值写入到接受返回值的变量中。当 id = fork() 的时候,谁先返回,谁就发生写时拷贝。最后大家的虚拟地址是一样的,但是对应的物理地址不一样,也就有了不同的值。
❓为什么要有虚拟地址空间?
- 保护内存。内存是硬件,本身并没有分区,虚拟地址空间则是在程序和硬件之间添加了一层软硬件层,对非法的访问可以直接拦截。
- 管理内存。通过地址空间,进行功能模块的解耦。
- 让进程或程序可以以统一的视角看待内存。维护进程独立性。
-
相关阅读:
[激光原理与应用-35]:《光电检测技术-2》- 光学测量基础 - 认识光源
什么是Redis?
Linux基础——服务
2024华为OD机试真题-机场航班调度-C++(C卷D卷)
Git 使用
Spark On Yarn基本原理及部署
十一:以理论结合实践方式梳理前端 React 框架 ———框架架构
理解一下C#的异步编程方式
Databend 集群部署 | 新手篇(2)
Kotlin高仿微信-第26篇-朋友圈-选择图片、小视频对话框
- 原文地址:https://blog.csdn.net/CegghnnoR/article/details/126356252
