-
Kafka 插件并创建 Kafka Producer 发送
相关说明
- 启动测试前清空所有数据。
- 每次测试先把所有数据写入 Kafka,再加载 Kafka 插件同步数据到 DolphinDB 中。目的是将同步数据的压力全部集中到 Kafka 插件。
- 以 Kafka 插件从收到第一批数据到收到最后一批数据的时间差作为同步数据的总耗时。
测试流程
- 加载 Kafka 插件并创建 Kafka Producer 发送数据到 Kafka 中(以发送 100 万条数据为例)
DolphinDB GUI 连接 DolphinDB 执行以下脚本,本例中插件的安装路径为
/DolphinDB/server/plugins/kafka,用户需要根据自己实际环境进行修改:- // 加载插件
- try{
- loadPlugin("/DolphinDB/server/plugins/kafka/PluginKafka.txt")
- loadPlugin("/DolphinDB/server/plugins/kafka/PluginEncoderDecoder.txt")
- } catch(ex){print(ex)}
- // 创建 Producer
- producerCfg = dict(STRING, ANY);
- producerCfg["metadata.broker.list"] = "192.193.168.5:8992";
- producer = kafka::producer(producerCfg);
- kafka::producerFlush(producer);
- //向kafka传100万数据
- tbl = table("R5L1B3T1N03D01" as deviceId, "2022-02-22 13:55:47.377" as timestamps, "voltage" as deviceType , 1.5 as value )
- // 创建 Consume
- consumerCfg = dict(STRING, ANY)
- consumerCfg["group.id"] = "test10"
- consumerCfg["metadata.broker.list"] = "192.193.168.5:8992";
- for(i in 1..1000000) {
- aclMsg = select *, string(now()) as pluginSendTime from tbl;
- for(i in aclMsg) {
- kafka::produce(producer, "test3", "1", i, true);
- }
- }
- consumer = kafka::consumer(consumerCfg)
- topics=["test10"];
- kafka::subscribe(consumer, topics);
- for(i in 1..1000000) {
- aclMsg = select *, string(now()) as pluginSendTime from tbl;
- for(i in aclMsg) {
- kafka::produce(producer, "test10", "1", i, true);
- }
- }
- 订阅 Kafka 中数据进行消费
- // 创建存储解析完数据的表
- colDefName = ["deviceId","timestamps","deviceType","value", "pluginSendTime", "pluginReceived"]
- colDefType = [SYMBOL,TIMESTAMP,SYMBOL,DOUBLE,TIMESTAMP,TIMESTAMP]
- dest = table(1:0, colDefName, colDefType);
- share dest as `streamZd
- // 解析函数
- def temporalHandle(mutable dictVar, mutable dest){
- try{
- t = dictVar
- t.replaceColumn!(`timestamps, temporalParse(dictVar[`timestamps],"yyyy-MM-dd HH:mm:ss.SSS"))
- t.replaceColumn!(`pluginSendTime, timestamp(dictVar[`pluginSendTime]))
- t.update!(`received, now());
- dest.append!(t);
- }catch(ex){
- print("kafka errors : " + ex)
- }
- }
- // 创建 decoder
- name = colDefName[0:5];
- type = colDefType[0:5];
- type[1] = STRING;
- type[4] = STRING;
- decoder = EncoderDecoder::jsonDecoder(name, type, temporalHandle{, dest}, 15, 100000, 0.5)
- // 创建subjob函数
- kafka::createSubJob(consumer, , decoder, `DecoderKafka)
此时我们观察共享流表的数据量,当达到 100 万条时说明消费完成,测试结束。
5. Kerberos 认证
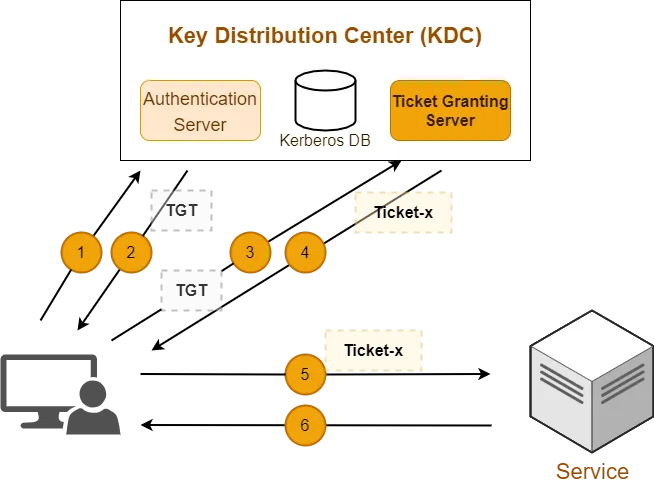
5.1 什么是 Kerberos ?
Kerberos 是一种基于加密 Ticket 的身份认证协议,支持双向认证且性能较高。主要有三个组成部分:Kdc, Client 和 Service。
生产环境的 Kafka 一般需要开启 Kerberos 认证,为 Kafka 提供权限管理,提高安全性。
5.2 前置条件
- Java 8+
- kerberos:包括 Kdc 和 Client
- keytab 证书
5.3 认证相关配置说明
环境相关配置说明
以下是 Kerberos 认证涉及的关键配置信息,具体配置文件的路径根据实际情况调整
- 安装 kdc
yum install -y krb5-server krb5-libs krb5-workstation krb5-devel krb5-auth-dialog2. 配置 /etc/krb5.conf
- [realms]
- HADOOP.COM = {
- kdc = cnserver9:88
- admin_server = cnserver9:749
- default_domain = HADOOP.COM
- }
3. 配置 /var/kerberos/krb5kdc/kadm5.acl
*/admin@HADOOP.COM *4. 创建生成 kdc 数据库文件
sudo kdb5_util create -r HADOOP.COM –s5. 启动 kerberos 服务
- sudo systemctl start krb5kdc
- sudo systemctl status krb5kdc
6. 安装 kerberos 客户端
yum install -y krb5-devel krb5-workstation krb5-client7. 启动 kerberos 客户端
sudo kadmin.local -q "addprinc hadoop/admin"DolphinDB Kafka Plugin 配置说明
- 关键配置参数说明
- security.protocol:指定通信协议
- sasl.kerberos.service.name:指定 service 名称
- sasl.mechanism:SASL 机制,包括 GSSAPI, PLAIN, SCRAM-SHA-256, SCRAM-SHA-512, OAUTHBEARER
- sasl.kerberos.keytab:keytab 文件的路径
- sasl.kerberos.principal:指定 principal
- 具体代码实现
- // 加载插件
- try{loadPlugin("/path/to/DolphinDBPlugin/kafka/bin/linux/PluginKafka.txt")} catch(ex){print(ex)}
- // 生产者配置
- producerCfg = dict(STRING, ANY);
- producerCfg["bootstrap.servers"] = "cnserver9:9992";
- producerCfg["security.protocol"] = "SASL_PLAINTEXT";
- producerCfg["sasl.kerberos.service.name"] = "kafka";
- producerCfg["sasl.mechanism"] = "GSSAPI";
- producerCfg["sasl.kerberos.keytab"] = "/home/test/hadoop.keytab";
- producerCfg["sasl.kerberos.principal"] = "kafka/cnserver9@HADOOP.COM";
- producer = kafka::producer(producerCfg);
- // 消费者配置
- consumerCfg = dict(STRING, ANY)
- consumerCfg["group.id"] = "test"
- consumerCfg["bootstrap.servers"] = "cnserver9:9992";
- consumerCfg["security.protocol"] = "SASL_PLAINTEXT";
- consumerCfg["sasl.kerberos.service.name"] = "kafka";
- consumerCfg["sasl.mechanism"] = "GSSAPI";
- consumerCfg["sasl.kerberos.keytab"] = "/home/test/hadoop.keytab";
- consumerCfg["sasl.kerberos.principal"] = "kafka/cnserver9@HADOOP.COM";
- consumer = kafka::consumer(consumerCfg)
注意:适配 Kerberos 认证只需修改 Kafka 插件有关生产者和消费者的配置即可,其余脚本无需改动。
6. 其他说明
本教程展示了 DolphinDB Kafka Plugin 中常用的接口函数,完整的函数支持请参考官网文档:DolphinDB Kafka 插件官方教程
使用过程中如果遇到任何问题,欢迎大家在项目仓库反馈
- Github 仓库:DolphinDB Kafka Plugin
- Gitee 仓库:DolphinDB Kafka Plugin
-
相关阅读:
Android Compose 权限请求
腾讯java研发岗二面:如何保证 redis 的高并发和高可用?
使用EasyPoi导出word并转换为pdf
C++学习笔记(四): 类、头文件、对象
C++类详解
Keras深度学习入门篇
大话STL第二期——机械先驱—vector
传统语音增强——最小方均(LMS)自适应滤波算法
计算机视觉与深度学习实战,Python工具,深度学习的视觉场景识别
程序员面试—反问示例
- 原文地址:https://blog.csdn.net/feidododekefu/article/details/127921026
