-
Linux进程常见通信方式
为什么要进程要进行通信呢?
进程间可能存在特定的协同工作的场景,这个时候就需要一个进程把自己的数据交付给另一个进程,让其进行处理。
进程通信的本质
因为进程具有独立性,那么两个进程要互相通信,必须得先看到同一份资源(一段内存,内存可以以文件方式提供、也可能以队列的方式提供、也可能提供的就是原始的内存块)。进程通信的本质就是,由操作系统参与提供一份所有通信进程都能看到的资源。
通信的方式
1、管道
什么是管道
1、管道是Unix中最古老的进程间通信的形式。
2、我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”
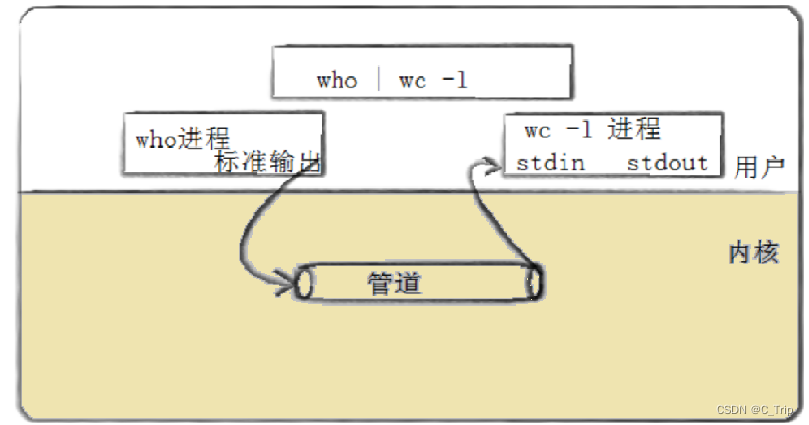
<1>匿名管道
#include
原型 int pipe(int fd[2]);
功能:创建一无名管道
参数 fd:文件描述符数组,其中fd[0]表示读端, fd[1]表示写端
返回值:成功返回0,失败返回错误代码#include
ssize_t read(int fd, void *buf, size_t count);
功能:从文件描述符中读取数据
参数:fd:文件描述符,buf:目标缓存区, count:期望读取的数据字节大小
返回值:如果成功,则返回读取的字节数(0表示文件结束),读取出错返回-1ssize_t write(int fd, const void *buf, size_t count);
功能:向文件描述符中写入数据
参数:fd:文件描述符,buf:目标缓存区, count要写入的数据字节大小
返回值:如果成功,则返回写入的字节数(0表示什么都没有写入)。如果出错,返回-1读写规则
1、如果所有管道写端对应的文件描述符被关闭,则read返回0
2、如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出
3、当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
4、当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。代码
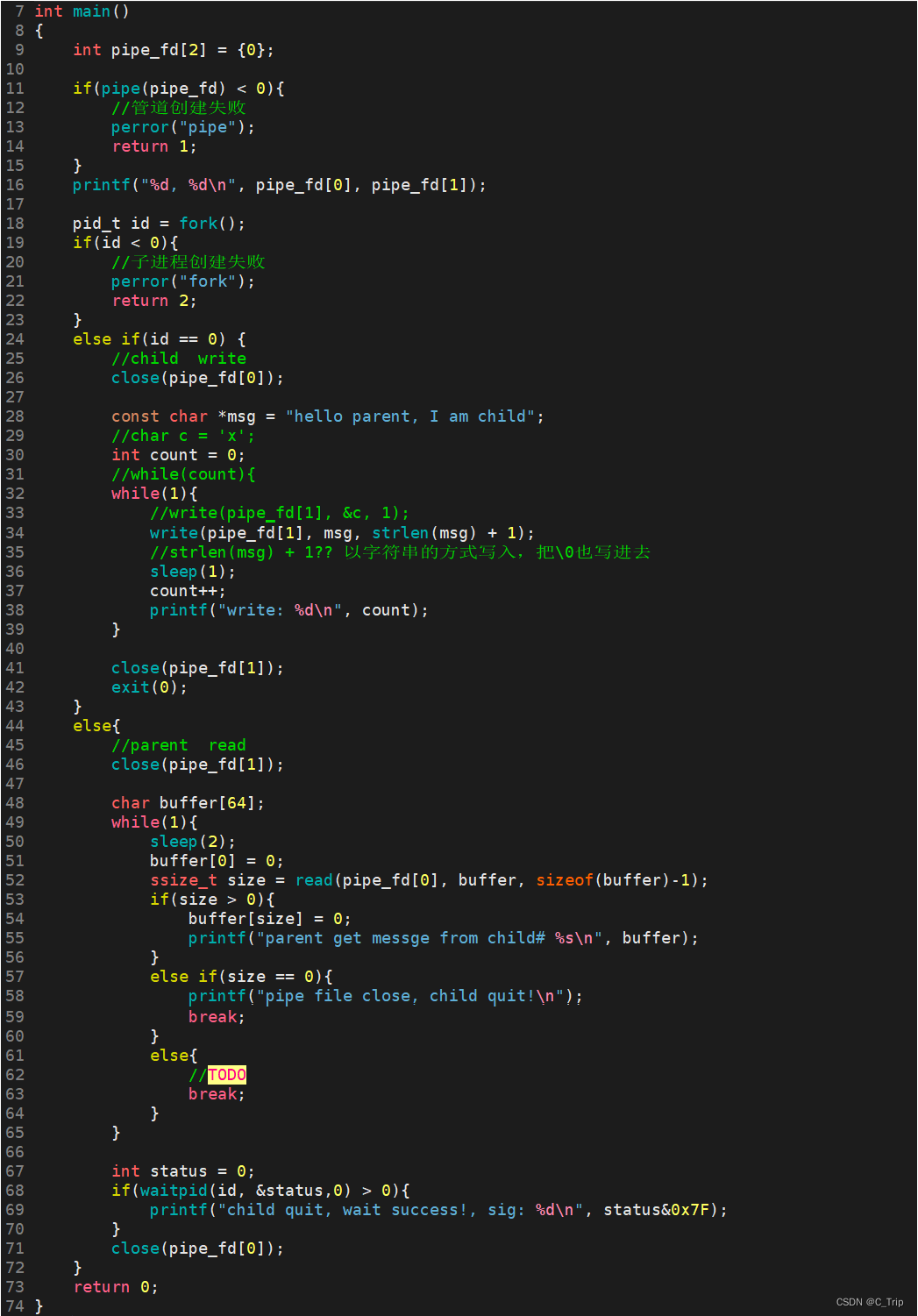
运行结果:
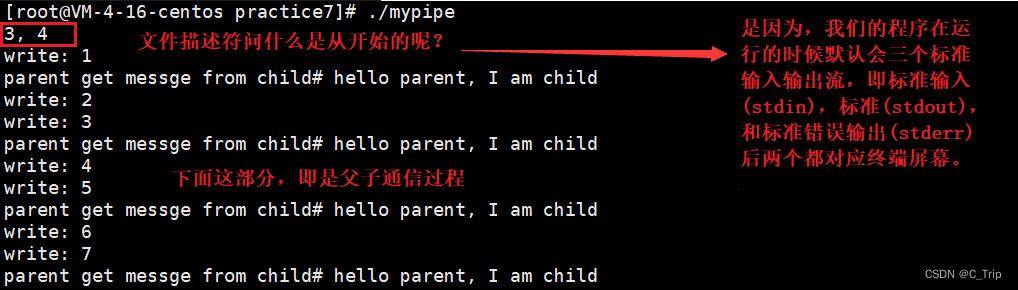
通过上面的3, 4我们可以注意到为啥不是3,5或3,6呢?其实文件描述符的本质就是个数组,因此是有顺序的。
Linux下管道大小
我们可以把上面代码中的29行放开,每次只写一个字符进去,50行读的时间延迟执行就会发现,管道是有大小的,大小为64KB。如下图运行结果:
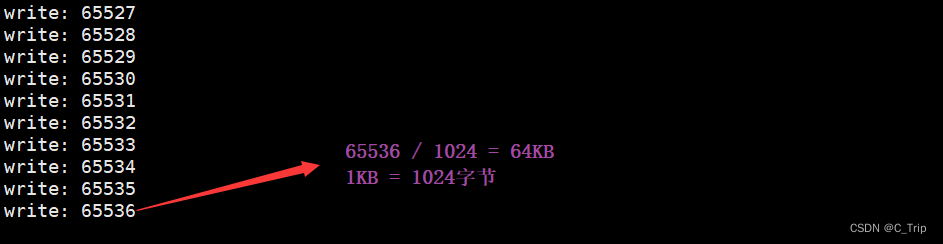
上面读写规则中的第三四条也就是因为这个原因。站在文件描述符角度理解管道

站在内核角度理解管道
看待管道,就如同看待文件一样!管道的使用和文件一致,迎合了“Linux一切皆文件思想”。
匿名管道特点
1、只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信;通常,一个管道由一个进程创建,然后该进程调用fork,此后父、子进程之间就可应用该管道。
2、管道提供流式服务(面向字节流的)
3、一般而言,进程退出,管道释放,所以管道的生命周期随进程
4、一般而言,内核会对管道操作进行同步与互斥(自带同步互斥)
5、管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道通信中的四种情况
1.读端不读或读的慢,写端(写满后)要等待读端
2.读端关闭,写端收到SIGPIPE信号直接终止
3.写端不写或写的慢,读端要等写端
4.写端关闭,读端要读完pipe内部的数据然后在读,会读到0表示读到文件结尾。<2> 命名管道
为了解决匿名管道只能父子通信,引入了命名管道。
命名管道创建
命令行创建
mkfifo filename
通过程序创建
相关函数:int mkfifo(const char *filename,mode_t mode)
功能:创建一个特殊文件
参数:filename: 文件名,mode: 权限模式
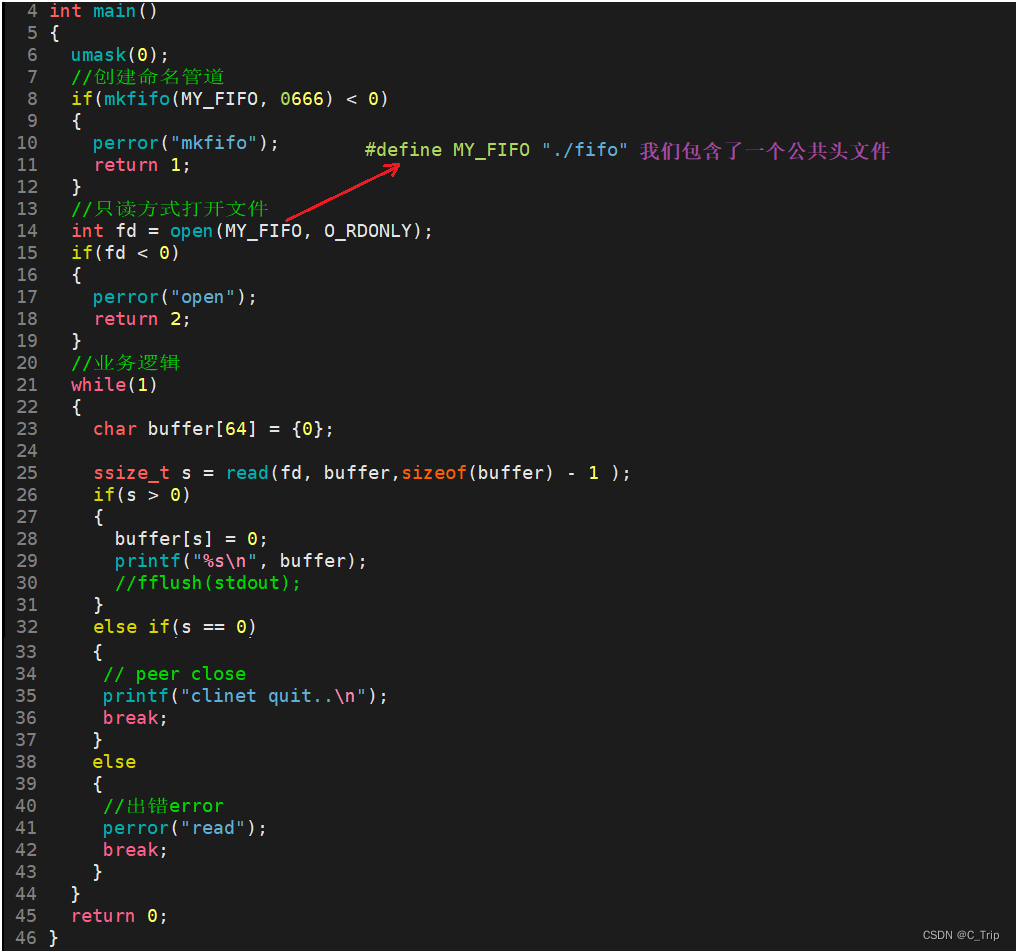
返回值:成功返回0,失败返回-1用命名管道实现server&client通信
server
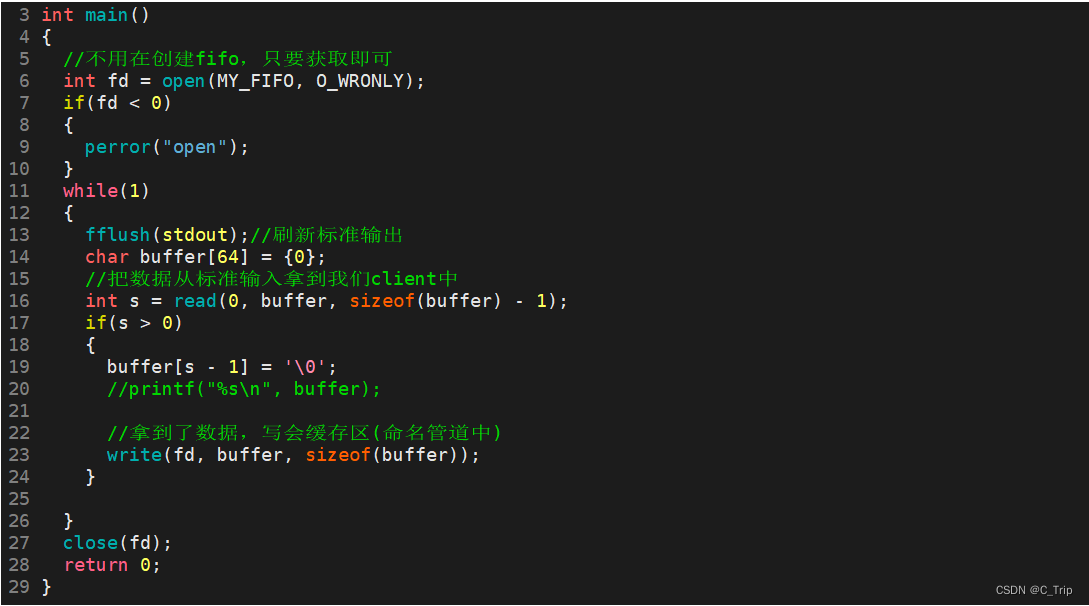
client
运行结果:

命名管道和匿名管道的区别
1、匿名管道由pipe函数创建并打开。
2、命名管道由mkfifo函数创建,打开用open
3、FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在它们创建与打开的方式不同,一但这些工作完成之后,它们具有相同的语义。2、共享内存
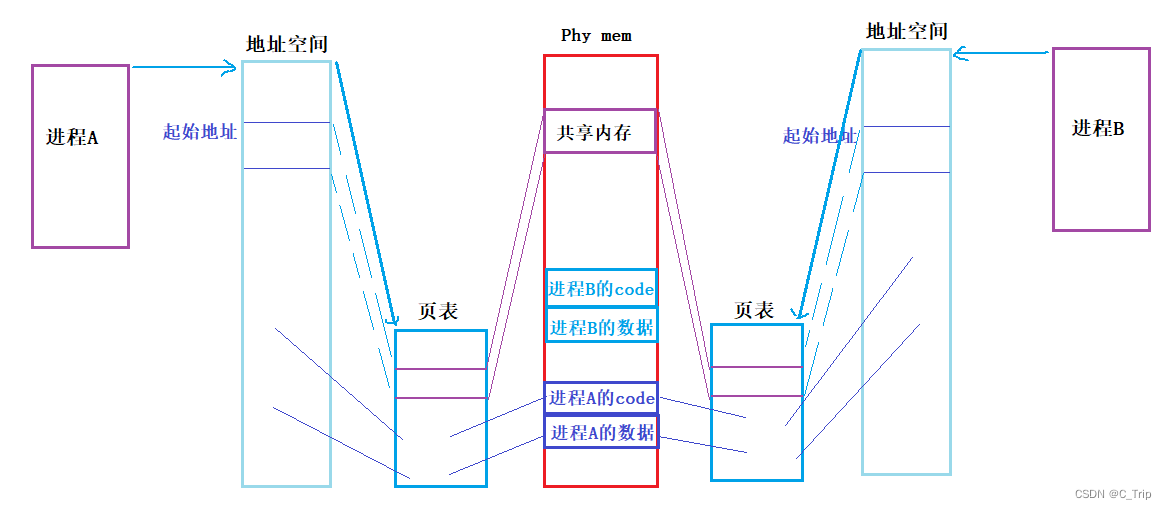
原理
1、通过调用库函数shmget,在内存中创建一块内存空间。
2、通过调用库函数shmat,让进程 “挂接” 到这块共享内存上。
如图:
相关函数功能:用来创建共享内存
原型 int shmget(key_t key, size_t size, int shmflg);
参数:
key:这个共享内存段名字
size:共享内存大小
shmflg:由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是一样的
返回值:成功返回一个非负整数,即该共享内存段的标识码;失败返回-1shmflg中的
IPC_CREAT:to create a new segment,单独使用或flg为0,创建共享,内存若已存在则返回共享内存
IPC_EXCL : 单独使用没有价值
IPC_CREAT | IPC_EXCL 失败返回-1,若我成功则得到一定是最新共享内存功能:生成key秘钥
原型:key_t ftok(const char *pathname, int proj_id);
参数:
pathname:路径名, proj_id是子序号,它是一个8bit的整数。即范围是0~255。
返回值:如果成功,将返回生成的key_t值。失败时返回-1功能:将共享内存段连接到进程地址空间 (attach)
原型 void *shmat(int shmid, const void *shmaddr, int shmflg);
参数 shmid: 共享内存标识 shmaddr:指定连接的地址
shmflg:它的两个可能取值是SHM_RND和SHM_RDONLY
返回值:成功返回一个指针,指向共享内存第一个节;失败返回-1功能:将共享内存段与当前进程脱离 (detach)
原型 int shmdt(const void *shmaddr);
参数 shmaddr:由shmat所返回的指针
返回值:成功返回0;失败返回-1
注意:将共享内存段与当前进程脱离不等于删除共享内存段功能:用于控制共享内存
原型 int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数:
shmid:由shmget返回的共享内存标识码
cmd:将要采取的动作(有三个可取值)
buf:指向一个保存着共享内存的模式状态和访问权限的数据结构
返回值:成功返回0;失败返回-1
共享内存总结
- 共享内存不提供任何同步或者互斥机制,需要程序员自行保证数据安全
- 共享内存是所有进程间通信最快的
- shmget中第二个参数size一般为4096字节的整数倍(共享内存在中申请的基本单位是页,内存页4kb)如果申请4097->内核给4096 byte*2,实际查看是4097但系统按两页申请。
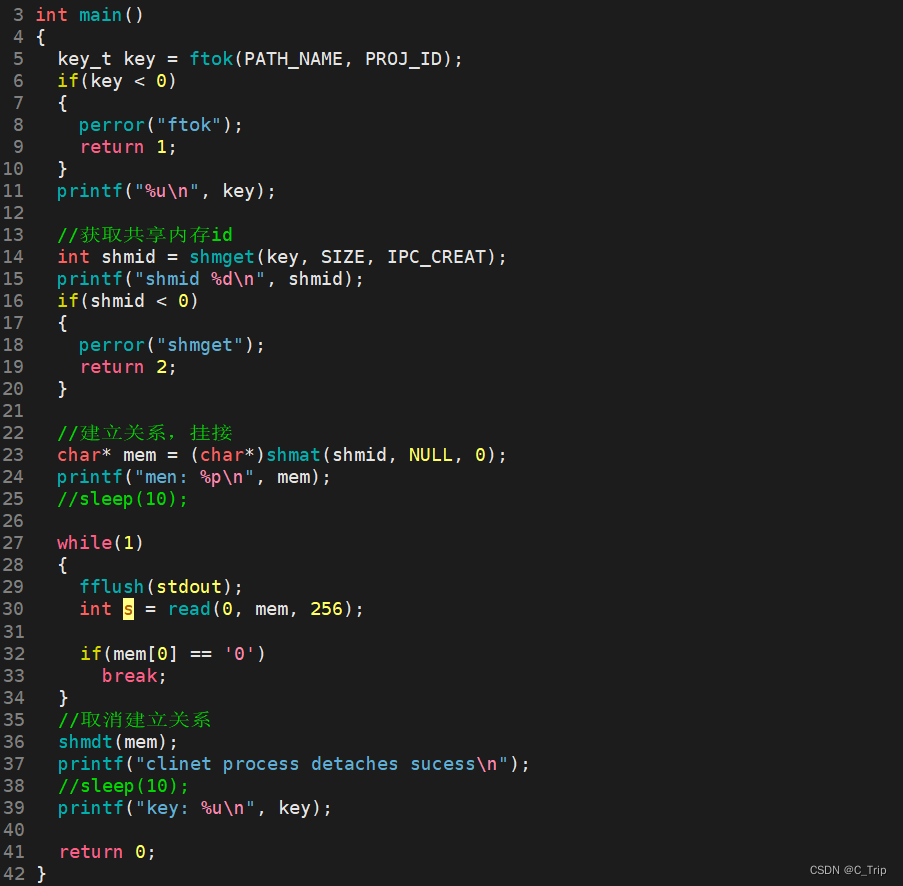
用享内存实现server&client通信
server端
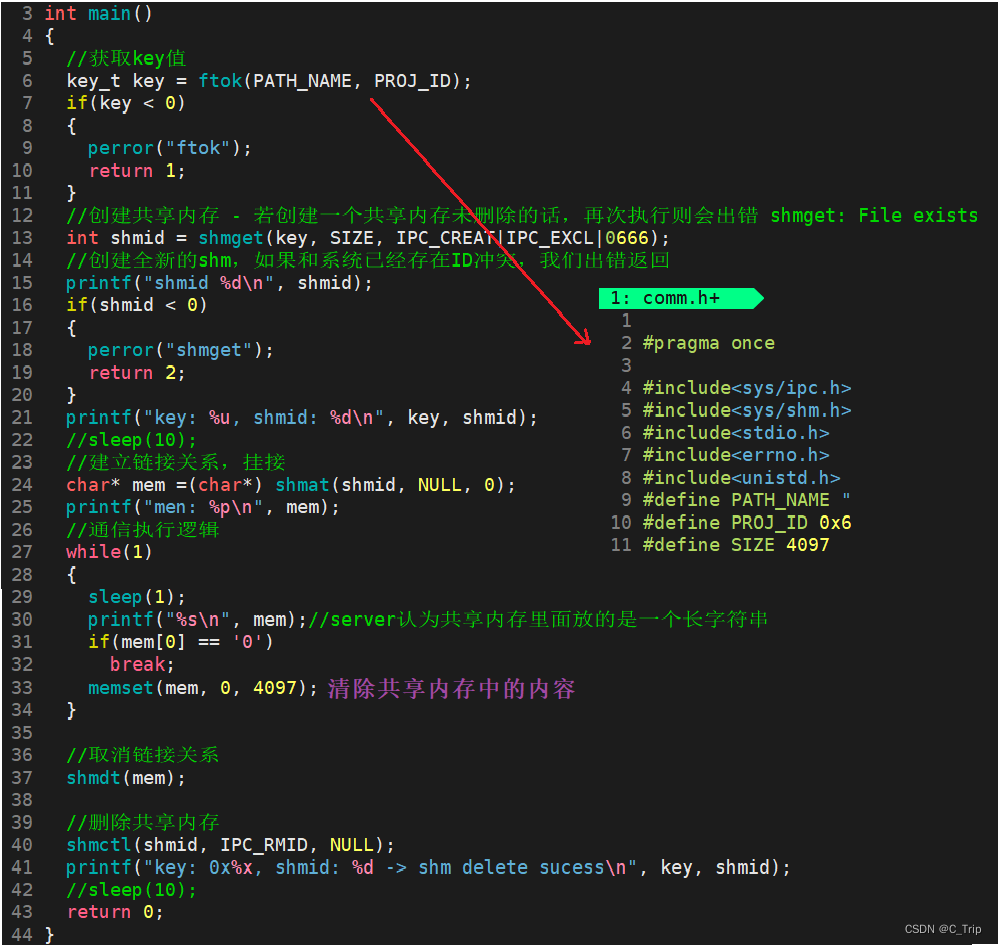
client端
运行结果:

3、信号量
什么是信号量
管道,共享内存、消息队列都是以传输数据为目的的。
信号量不是以传输数据为目的的,他是通共享资源的方式来达到多个线程的同步和互斥的目的的。学习信号量我们要知道的几个概念
1、信号量的本质:是一个计数器,类似 int count;衡量临界资源中资源数目的。
2、什么是临界资源:凡是能够被多个执行流同时能够访问的资源就是临界资源,如管道,共享
内存,消息队列等都是临界资源。
3、什么是临界区:进程代码有很多,其中用来访问临界资源的代码,就叫做临界区。
4、什么是原子性:一件事要么不做,要做就做完,没有中间态,就叫做原子性。
5、什么是互斥:在任意时刻只允许一个执行流进入临界资源,执行它自己的临界区。
6、什么是同步:让访问临界资源的过程在安全的前提下,有一定顺序性。信号量的代码我们在后面的生产消费者模型中讲解。
-
相关阅读:
Mobile App自动化测试技术及实现
Jenkins测试报告样式优化
浅谈电动汽车智能充电桩及运营管理云解决方案
个人如何申请发明专利,需要的资料有哪些
尚医通【预约挂号系统】总结
SpringBoot之WebSocket服务搭建
Android Kotlin Retrofit 与Flow。两个Flow用LiveData来进行分解
为.NET打开新大门:OpenVINO.NET开源项目全新发布
Vim编辑器使用入门
ndk开发之native层访问java层
- 原文地址:https://blog.csdn.net/C_Trip/article/details/127880009