-
Elasticsearch:Data streams(一)
数据流让你可以跨多个索引存储仅追加(append-only)的时间序列数据,同时为你提供一个用于请求的命名资源。 数据流非常适合日志、事件、指标和其他持续生成的数据。
你可以将索引和搜索请求直接提交到数据流。 流自动将请求路由到存储流数据的后备(backing indices)索引。 你可以使用索引生命周期管理 (ILM) 来自动管理这些后备索引。 例如,你可以使用 ILM 自动将较旧的支持索引移动到更便宜的硬件并删除不需要的索引。 随着数据的增长,ILM 可以帮助您降低成本和开销。
后备索引(backing indices)
数据流由一个或多个隐藏的(索引名字由 . 开始的)、自动生成的支持索引组成。
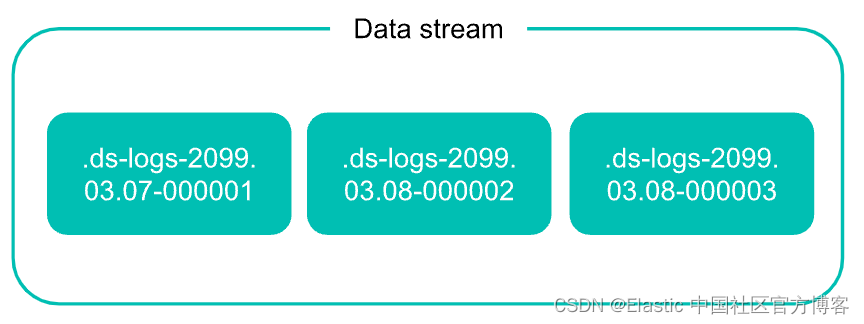
数据流需要匹配的索引模板。 该模板包含用于配置流的支持索引的映射和设置。
每个索引到数据流的文档都必须包含一个 @timestamp 字段,映射为 date 或 date_nanos 字段类型。 如果索引模板没有为 @timestamp 字段指定映射,Elasticsearch 将 @timestamp 映射为具有默认选项的日期字段。
同一个索引模板可以用于多个数据流。 你不能删除数据流正在使用的索引模板。
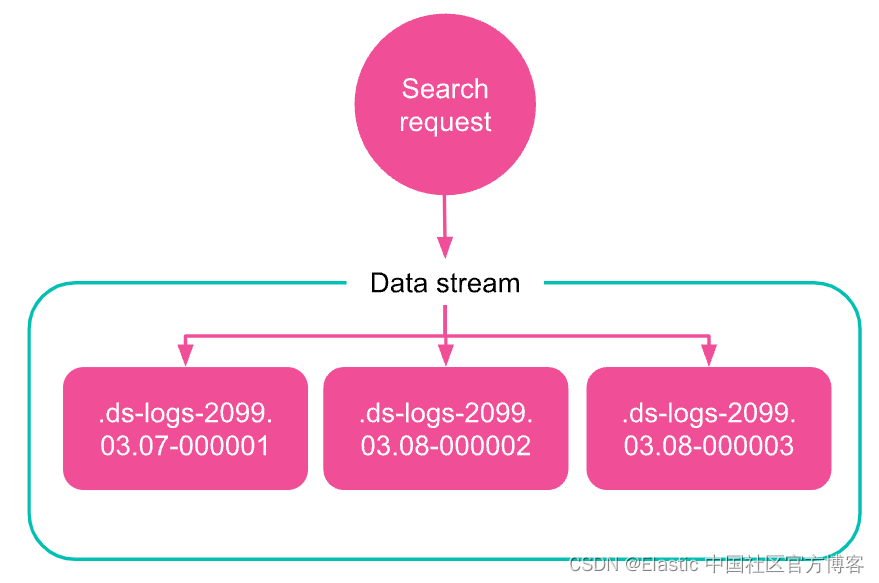
读请求
当你向数据流提交读取请求时,该流会将请求路由到其所有后备索引。
写索引
最近创建的后备索引是数据流的写入索引。 流仅将新文档添加到此索引。
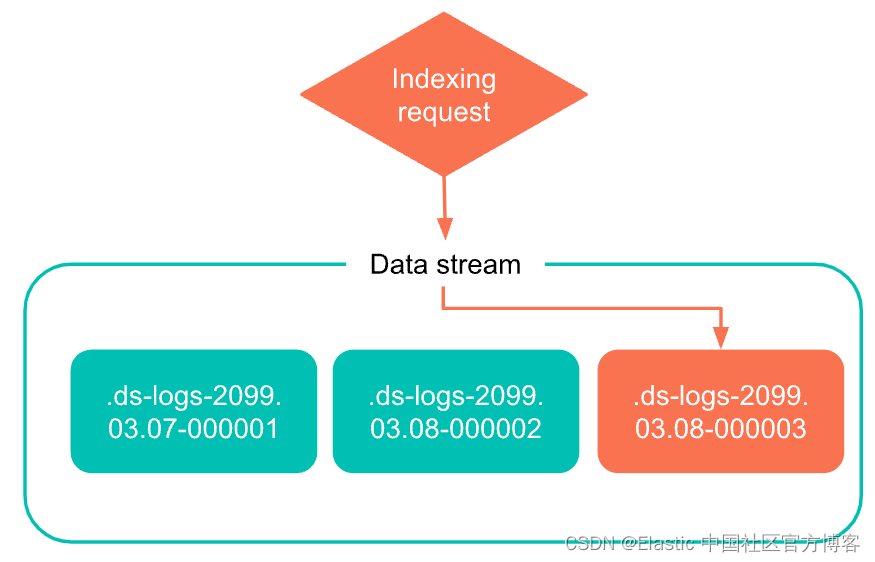
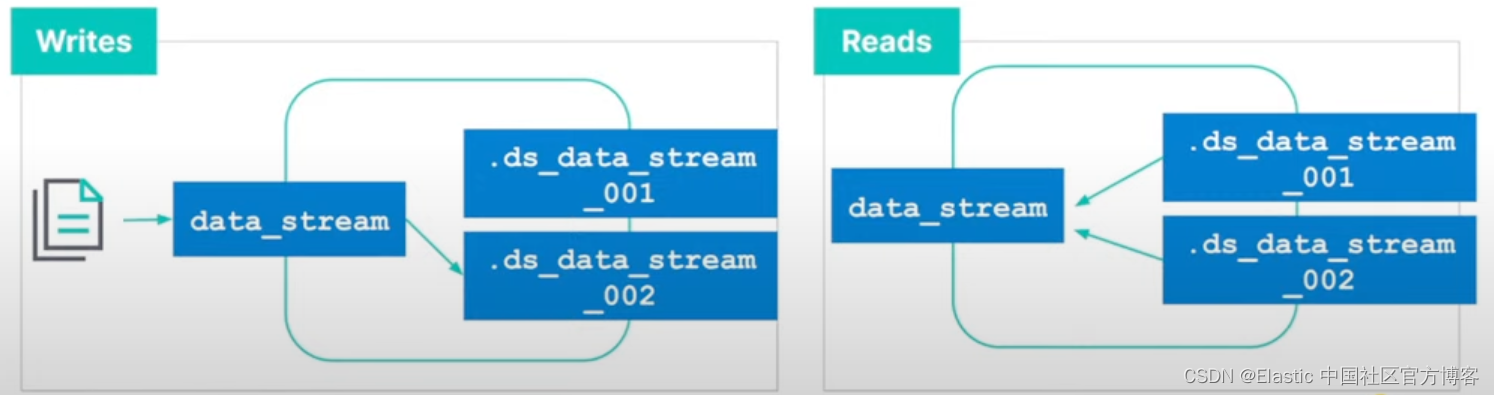
你不能将新文档添加到其他后备索引中,即使直接向索引发送请求也是如此。
你也不能对可能阻碍索引的写入索引执行如下的操作,例如:
Rollover
Rollover,也即滚动。滚动创建一个新的后备索引,成为流的新写入索引。
我们建议使用 ILM 在写入索引达到指定的年龄或大小时自动滚动数据流。 如果需要,你还可以手动滚动数据流。有关 rollover 的文章,你可以阅读 “Elasticsearch: rollover API”。
Generation
每个数据流都跟踪它的 generation:一个六位数的零填充整数,从 000001 开始充当流滚动的累积计数。
创建后备索引时,使用以下约定命名索引:
.ds-<data-stream>-<yyyy.MM.dd>-<generation>是后备索引的创建日期。 具有更高生成的后备索引包含更多最新数据。 例如,web-server-logs 数据流的代数为 34。该流的最新支持索引创建于 2099 年 3 月 7 日,名为 .ds-web-server-logs-2099.03.07-000034。 某些操作,例如 shrink 或 restore,可以更改后备索引的名称。 这些名称更改不会从其数据流中删除后备索引。
只追加(Apend-only)
数据流专为现有数据很少(如果有的话)更新的用例而设计。 你不能将现有文档的更新或删除请求直接发送到数据流。 相反,使用查询更新和查询 API 删除。有关如何更新或查询 API 删除文档,请参考我的另外一篇文章 “开始使用 Elasticsearch (1)”。
如果需要,你可以通过直接向文档的后备索引提交请求来更新或删除文档。
提示:如果你经常更新或删除现有时间序列数据,请使用带有写入索引的索引别名而不是数据流。 请参阅管理没有数据流的时间序列数据。
设置数据流
要设置数据流,请执行以下步骤:
- 创建索引生命周期策略
- 创建组件模板
- 创建索引模板
- 创建数据流
- 保护数据流
重要:如果你使用 Fleet 或 Elastic Agent,请跳过本教程。 Fleet 和 Elastic Agent 为你设置数据流。 请参阅 Fleet 的数据流文档。
在下面的介绍中,我将一一介绍。
创建索引生命周期策略
虽然是可选的,但我们建议使用 ILM 来自动管理数据流的支持索引。 ILM 需要索引生命周期策略。
我们可以参考文章 “Elasticsearch:使用 docker compose 来实现热温冷架构的 Elasticsearch 集群” 来搭建具有热,温及冷层架构的 Elasticsearch 集群。
要在 Kibana 中创建索引生命周期策略,请打开主菜单并转到 Stack Management > Index Lifecycle Policies。 单击 Create policy。你可以阅读文章 “Elastic:Data stream 在索引生命周期管理中的应用” 以了解更多。





在上面我们配置了 hot phase,warm phase 及 Delete phase。Delete phase 需要在 warm phase 里选择删除才可以出现。需要注意的一点是数据的年龄是根据 rollover 发生的时间来定的。
点击 Save policy 按钮。这样我们就创建一个叫做 my-lifecycle-policy 的索引生命周期策略。我们可以使用如下的命令来查看:
GET _ilm/policy/my-lifecycle-policy- {
- "my-lifecycle-policy": {
- "version": 1,
- "modified_date": "2022-11-17T06:27:16.429Z",
- "policy": {
- "phases": {
- "warm": {
- "min_age": "0d",
- "actions": {
- "allocate": {
- "number_of_replicas": 0,
- "include": {},
- "exclude": {},
- "require": {}
- },
- "forcemerge": {
- "max_num_segments": 1
- },
- "set_priority": {
- "priority": 50
- },
- "shrink": {
- "number_of_shards": 1
- }
- }
- },
- "hot": {
- "min_age": "0ms",
- "actions": {
- "rollover": {
- "max_primary_shard_size": "50gb",
- "max_age": "30d",
- "max_docs": 5,
- "max_primary_shard_docs": 5
- },
- "set_priority": {
- "priority": 204
- }
- }
- },
- "delete": {
- "min_age": "3m",
- "actions": {
- "delete": {
- "delete_searchable_snapshot": true
- }
- }
- }
- }
- },
- "in_use_by": {
- "indices": [],
- "data_streams": [],
- "composable_templates": []
- }
- }
从上面的定义中我们可以看出来, 当 hot 节点里的索引满足如下的任何一个条件:
- Primary shard 的大小超过 50G
- 文档的年龄超过 30 天
- 文档数超过 5 个
- Primary shard 文档数超过 5 个
Rollover 都会发生。Elasticsearch 会自动按照一定的时间间隔来检查 rollover 是否发生。这个时间是由参数 indices.lifecycle.poll_interval 来决定的。我们可以在地址找到这个参数的设置。在默认的情况下,这个参数是10分钟的时间。在实验的环境中,为了能够尽快地看到 rollover 事件的发生,我们可以修改这个参数:
- PUT _cluster/settings
- {
- "transient": {
- "indices.lifecycle.poll_interval": "10s"
- }
- }
上面表明 Elasticsearch 每隔10秒钟进行查询,并执行 ILM policy。
你还可以使用创建生命周期策略 API。
- PUT _ilm/policy/my-another-lifecycle-policy
- {
- "policy": {
- "phases": {
- "hot": {
- "actions": {
- "rollover": {
- "max_primary_shard_size": "50gb"
- }
- }
- },
- "warm": {
- "min_age": "30d",
- "actions": {
- "shrink": {
- "number_of_shards": 1
- },
- "forcemerge": {
- "max_num_segments": 1
- }
- }
- },
- "cold": {
- "min_age": "60d",
- "actions": {
- "searchable_snapshot": {
- "snapshot_repository": "found-snapshots"
- }
- }
- },
- "frozen": {
- "min_age": "90d",
- "actions": {
- "searchable_snapshot": {
- "snapshot_repository": "found-snapshots"
- }
- }
- },
- "delete": {
- "min_age": "735d",
- "actions": {
- "delete": {}
- }
- }
- }
- }
- }
在上面的 rollover 中,我们定义了当 primary shard 的大小超过 50G 的时候,rollover 会发生。我们甚至可以增加其它的一些条件比如:
- "rollover" : {
- "max_size" : "50gb",
- "max_age" : "30d",
- "max_docs" : 5
- }
当它满足如下的任何一个条件:
- 索引的大小大于 50G
- 文档的数量大于 5
- 索引的时间跨度超过 30 天
rollover 就会自动发生。
创建组件模板
数据流需要匹配的索引模板。 在大多数情况下,你使用一个或多个组件模板来编写此索引模板。 你通常使用单独的组件模板进行映射和索引设置。 这使你可以在多个索引模板中重用组件模板。
创建组件模板时,包括:
- @timestamp 字段的 date 或 date_nanos 映射。 如果你不指定映射,Elasticsearch 会将 @timestamp 映射为具有默认选项的日期字段。
- index.lifecycle.name 在索引设置(settings)中的生命周期策略。
提示:映射字段时使用 Elastic Common Schema (ECS)。 ECS 字段默认与多个 Elastic Stack 功能集成。
如果你不确定如何映射你的字段,请使用运行时字段(runtime fields)在搜索时从非结构化内容中提取字段。 例如,你可以将日志消息索引到通配符(wildcard)字段,然后在搜索期间从该字段中提取 IP 地址和其他数据。
要在 Kibana 中创建组件模板,请打开主菜单并转到 Stack Management > Index Management。 在 Index Templates 视图中,单击 Create component template。

如果你想了解详细如何操作,请阅读我的另外一篇文章 “Elasticsearch:可组合的 Index templates - 7.8 版本之后”。
你还可以使用创建组件模板 API。
- # Creates a component template for mappings
- PUT _component_template/my-mappings
- {
- "template": {
- "mappings": {
- "properties": {
- "@timestamp": {
- "type": "date",
- "format": "date_optional_time||epoch_millis"
- },
- "message": {
- "type": "wildcard"
- }
- }
- }
- },
- "_meta": {
- "description": "Mappings for @timestamp and message fields",
- "my-custom-meta-field": "More arbitrary metadata"
- }
- }
- # Creates a component template for index settings
- PUT _component_template/my-settings
- {
- "template": {
- "settings": {
- "index.lifecycle.name": "my-lifecycle-policy"
- }
- },
- "_meta": {
- "description": "Settings for ILM",
- "my-custom-meta-field": "More arbitrary metadata"
- }
- }
在上面,创建了 settings 及 mappings 的组件模板。当然,我们甚至可以创建自己的 alias 组件模板。
创建索引模板
使用你的组件模板创建索引模板。 指定:
- 与数据流名称匹配的一个或多个索引模式。 我们建议使用我们的数据流命名方案。
- 该模板启用了数据流。
- 任何包含你的映射和索引设置的组件模板。
- 优先级(priority)高于 200 以避免与内置模板发生冲突。 请参阅避免索引模式冲突。
要在 Kibana 中创建索引模板,请打开主菜单并转到 Stack Management > Index Management。 在 Index Templates 视图中,单击 Create Template。

你还可以使用创建索引模板 API。 包含 data_stream 对象以启用数据流。
- PUT _index_template/my-index-template
- {
- "index_patterns": ["my-data-stream*"],
- "data_stream": { },
- "composed_of": [ "my-mappings", "my-settings" ],
- "priority": 500,
- "_meta": {
- "description": "Template for my time series data",
- "my-custom-meta-field": "More arbitrary metadata"
- }
- }
如果我们想知道最终的 index template 是什么样子的,你可以阅读我的另外一篇文章 “Elasticsearch:Simulate index API”。
POST /_index_template/_simulate_index/my-data-stream1由于上面的 my-data-stream1 名字符合在上面的 my-index-template 中定义的 index pattern,所以它将模拟出来这个索引所将要具有的配置,尽管上面的命令不生成任何实质的索引。上面的命令返回的结果为:
- {
- "template": {
- "settings": {
- "index": {
- "lifecycle": {
- "name": "my-lifecycle-policy"
- },
- "routing": {
- "allocation": {
- "include": {
- "_tier_preference": "data_hot"
- }
- }
- }
- }
- },
- "mappings": {
- "properties": {
- "@timestamp": {
- "type": "date",
- "format": "date_optional_time||epoch_millis"
- },
- "message": {
- "type": "wildcard"
- }
- }
- },
- "aliases": {}
- },
- "overlapping": []
- }
创建数据流
索引请求将文档添加到数据流中。 这些请求必须使用 op_type create。 文档必须包含一个@timestamp 字段。
要自动创建数据流,请提交以流名称为目标的索引请求。 此名称必须与你的索引模板的索引模式之一相匹配。
- PUT my-data-stream/_bulk
- { "create":{ } }
- { "@timestamp": "2099-05-06T16:21:15.000Z", "message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736" }
- { "create":{ } }
- { "@timestamp": "2099-05-06T16:25:42.000Z", "message": "192.0.2.255 - - [06/May/2099:16:25:42 +0000] \"GET /favicon.ico HTTP/1.0\" 200 3638" }
- POST my-data-stream/_doc
- {
- "@timestamp": "2099-05-06T16:21:15.000Z",
- "message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"
- }
你还可以使用创建数据流 API 手动创建流。 流的名称仍必须与模板的索引模式之一相匹配。
PUT _data_stream/my-data-stream保护数据流
使用索引权限来控制对数据流的访问。 授予对数据流的权限会授予对其后备索引的相同权限。
有关示例,请参阅数据流权限。比如,一个用户被授予对 my-data-stream 的读取权限。
- {
- "names" : [ "my-data-stream" ],
- "privileges" : [ "read" ]
- }
例如,my-data-stream 包含两个后备索引:.ds-my-data-stream-2099.03.07-000001 和 .ds-my-data-stream-2099.03.08-000002。因为用户被自动授予对流的后备索引的相同权限,所以用户可以直接从 .ds-my-data-stream-2099.03.08-000002 检索文档:
GET .ds-my-data-stream-2099.03.08-000002/_doc/2稍后 my-data-stream 滚动。 这将创建一个新的支持索引:.ds-my-data-stream-2099.03.09-000003。 因为用户仍然拥有my-data-stream 的读取权限,所以用户可以直接从.ds-my-data-stream-2099.03.09-000003中获取文档:
GET .ds-my-data-stream-2099.03.09-000003/_doc/2我们可以在创建 role 时,指定索引的权限:

将索引别名转换为数据流
在 Elasticsearch 7.9 之前,你通常会使用带有写入索引的索引别名来管理时间序列数据。你可以阅读文章 “Elasticsearch:Index 生命周期管理入门” 以了解更多。 数据流取代了此功能,需要更少的维护,并自动与数据层集成。
要将具有写入索引的索引别名转换为具有相同名称的数据流,请使用迁移到数据流 API。 在转换期间,别名的索引成为流的隐藏后备索引。 别名的写索引成为流的写索引。 该流仍然需要启用数据流的匹配索引模板。
POST _data_stream/_migrate/my-time-series-data获取有关数据流的信息
要获取有关 Kibana 中数据流的信息,请打开主菜单并转到 Stack Management > Index Management。 在 Data Streams 视图中,单击数据流的名称。

你还可以使用获取数据流 API。
GET _data_stream/my-data-stream删除数据流
要在 Kibana 中删除数据流及其后备索引,请打开主菜单并转到 Stack Management > Index Management。 在 Data Streams 视图中,单击垃圾桶图标。 仅当您拥有数据流的 delete_index 安全权限时才会显示该图标。

你还可以使用删除数据流 API。
DELETE _data_stream/my-data-stream在我接下来的文章 “Elasticsearch:Data streams(二)” 里,我会详细来描述如和使用一个 data stream。
-
相关阅读:
springboot配置es集群两种方式
Spring Boot进阶(94):从入门到精通:Spring Boot和Prometheus监控系统的完美结合
Java编程技巧-定义集合常量、定义数组常量的最佳方式
3. ansible playbook剧本
K8S 实用工具之三 - 图形化 UI Lens
linux安装redis
6 个意想不到的 JavaScript 问题
基于蝠鲼觅食优化的BP神经网络(分类应用) - 附代码
项目实战——匹配系统(中)
redis学习笔记
- 原文地址:https://blog.csdn.net/UbuntuTouch/article/details/127879494
