-
SPARKSQL3.0-Antlr4由浅入深&SparkSQL语法解析
一、前言
在开始剖析SparkSQL前,我们要先来了解一下Antlr4,这是因为spark-sql字符串解析工作是由Antlr4完成的,故需要先来了解Antlr4,如下:

本文会着重介绍一下几点:
1、Antlr是什么?
2、如何使用?
3、SparkSql中如何使用?
二、Antlr4是什么?
Antlr4(Another Tool for Language Recognition)是一款强大的语法分析器生成工具,可用于读取、处理、执行和翻译结构化的文本,用户可根据需要自定义语法规则来实现相应功能
那么我们为何要用antlr4呢?
假设我们要自己发明一种特殊语言【例如以自己命名的sql语言: MeSQL】,下面是MeSQL的一条sql语句:
me a,b,c to tableName- 1
相信市面上根本没有这种语言,我们自己编写的语言中肯定需要语法和关键字,并且关键字不仅仅只是 me \ to。肯定有很多关键字和不同语法组合成的语句;
针对这种自己发明的语法被称为:DSL领域特定语言
如果要我们要自己实现一套DSL领域特定语言,其过程会十分复杂,首先需要解析字符串,再形成语法树,再到节点处理等等步骤。
此时ANTLR就可以派上用场了,多说无益,接下来我们自己实现一个
三、使用
首先ANTLR是用Java编写的,因此你需要首先安装Java,下面将从实战的角度介绍如何使用
1、安装插件
首先需要在IDEA中安装antlr4插件,这个插件可以帮助我们提高工作效率,就像Maven的MavenHelper插件一样

2、新建Maven工程
新建一个Maven项目,并在pom.xml中引入antlr4依赖:
注意:如果你已经有一个SparkSql的项目,则无需引用,因sparkSQL中已经包含antlr的依赖
<dependencies> <dependency> <groupId>org.antlrgroupId> <artifactId>antlr4-runtimeartifactId> <version>4.8-1version> dependency> dependencies> <plugins> <plugin> <groupId>org.antlrgroupId> <artifactId>antlr4-maven-pluginartifactId> <version>4.8-1version> <executions> <execution> <goals> <goal>antlr4goal> goals> <phase>nonephase> execution> executions> <configuration> <outputDirectory>src/main/javaoutputDirectory> <visitor>truevisitor> configuration> plugin> plugins>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
3、新建antlr4语法文件
语法文件是以.g4结尾的文件,例如MeSql.g4,antlr4是通过读取.g4语法文件来生成语法解析的类
一个完整的.g4语法文件是要包含如下两种元素:
1、语法规则 - 即语法,例如java的方法要写返回值和入参,等固定的语法搭配
2、词法规则 - 即关键字规则,例如java的public, private等关键字词法
如下:
// 语法文件通常以 granmar 关键宇开头 这是一个名为 MeSql 的语法 它必须和文件名 MeSql.g4相匹配 grammar MeSql; // 定义一条名为 me 的语法规则,它匹配一对花括号[START, STOP为词法关键词]、逗号分隔的 value [另一条语法规则,在下面], 以及 * 匹配多个 value me : START value (',' value)* STOP ; // 定义一条value的语法规则,正是上面me语法中的value,该value的值应该是 INT 或者继续是 me [代表嵌套], | 符号代表或 value : me |INT ; // 以下所有词法符号都是根据正则表达式判断 // 定义一个INT的词法符号, 只能是正整数 INT : [0-9]+ ; // 定义一个START的词法符号, 只包含{ START : '{' ; // 定义一个STOP的词法符号, 只包含} STOP : '}' ; // 定义一个AND的词法符号, 只包含, AND : ',' ; // 定义一个WS的词法符号,后面跟正则表达式,意思是空白符号丢弃 WS : [\t\n\r]+ -> skip ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
4、运行antlr4插件测试
接下来我们要通过运行语法文件,将用户输入的字符串转化为语法树,过程如下:

首先选中me右键点击Test Rule me

此时会弹出Antlr Preview窗口,在左侧窗口中输入:
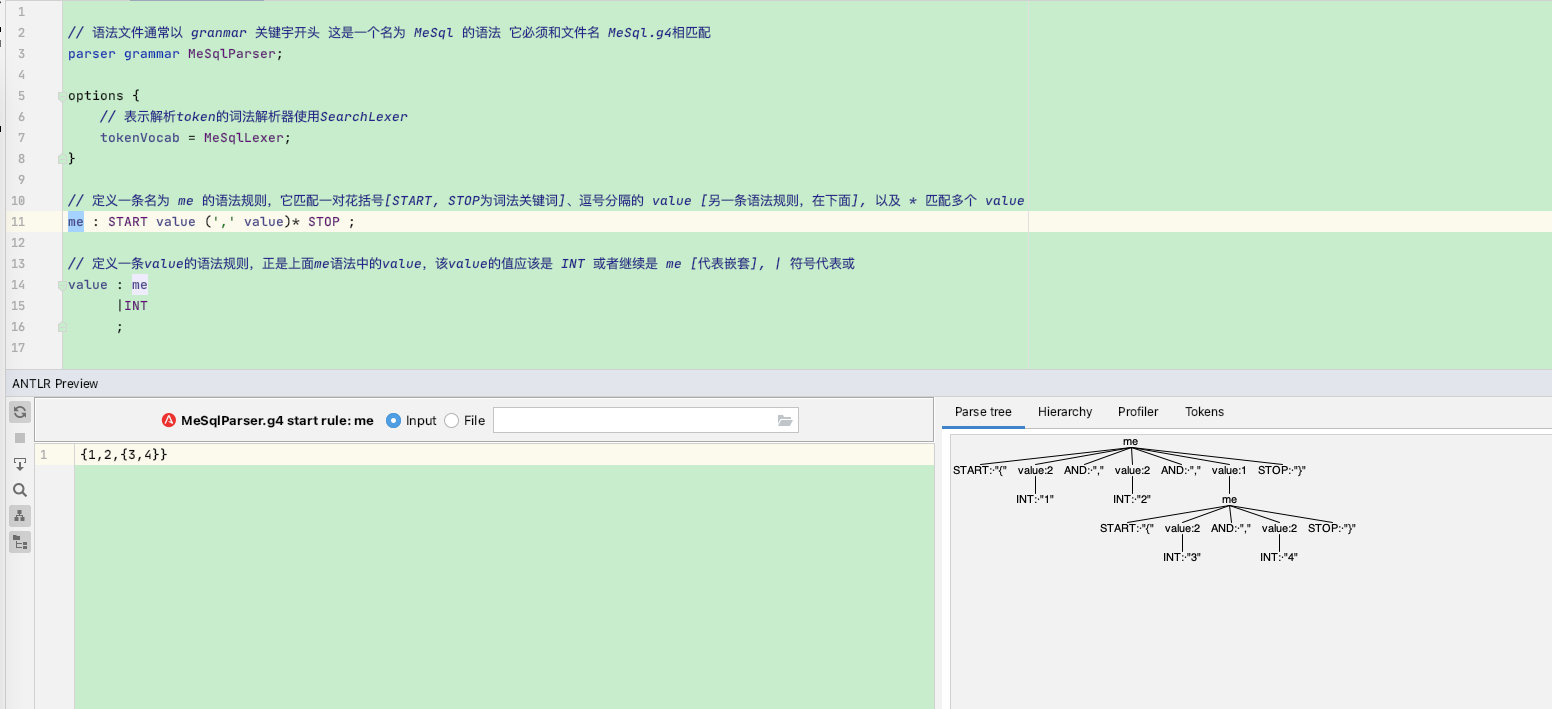
{3,4,{3,4}}- 1
此时右侧会展示插件解析好的语法树【也叫AST抽象语法树】

可以看到树中的根节点就是me,{ 转换成了START,数值3,4都转换成了value,并且指向INT词法
我们再将MeSql文法改一改:将INT改为[0-2],此时输入3,4 会解析失败

5、文件分层
在实际使用中,我们的语法文件中会包含非常多的语法和词法,为了更好的解耦,通常是有两个文件:
1、语法文件
2、词法文件
语法文件中通过关键字指向词法文件,例如在spark中,也是将语法文件分成了两个,如下:
https://github.com/apache/spark/tree/master/sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser
所以我们将上面示例更改成如下两个文件:
MeSqlLexer词法文件:
// 语法文件通常以 granmar 关键宇开头 这是一个名为 MeSql 的语法 它必须和文件名 MeSql.g4相匹配 lexer grammar MeSqlLexer; // 以下所有词法符号都是根据正则表达式判断 // 定义一个INT的词法符号, 只能是正整数 INT : [0-9]+ ; // 定义一个START的词法符号, 只包含{ START : '{' ; // 定义一个STOP的词法符号, 只包含} STOP : '}' ; // 定义一个AND的词法符号, 只包含, AND : ',' ; // 定义一个WS的词法符号,后面跟正则表达式,意思是空白符号丢弃 WS : [\t\n\r]+ -> skip ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
MeSqlParser语法文件:
// 语法文件通常以 granmar 关键宇开头 这是一个名为 MeSql 的语法 它必须和文件名 MeSql.g4相匹配 parser grammar MeSqlParser; options { // 表示解析token的词法解析器使用SearchLexer tokenVocab = MeSqlLexer; } // 定义一条名为 me 的语法规则,它匹配一对花括号[START, STOP为词法关键词]、逗号分隔的 value [另一条语法规则,在下面], 以及 * 匹配多个 value me : START value (',' value)* STOP ; // 定义一条value的语法规则,正是上面me语法中的value,该value的值应该是 INT 或者继续是 me [代表嵌套], | 符号代表或 value : me |INT ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
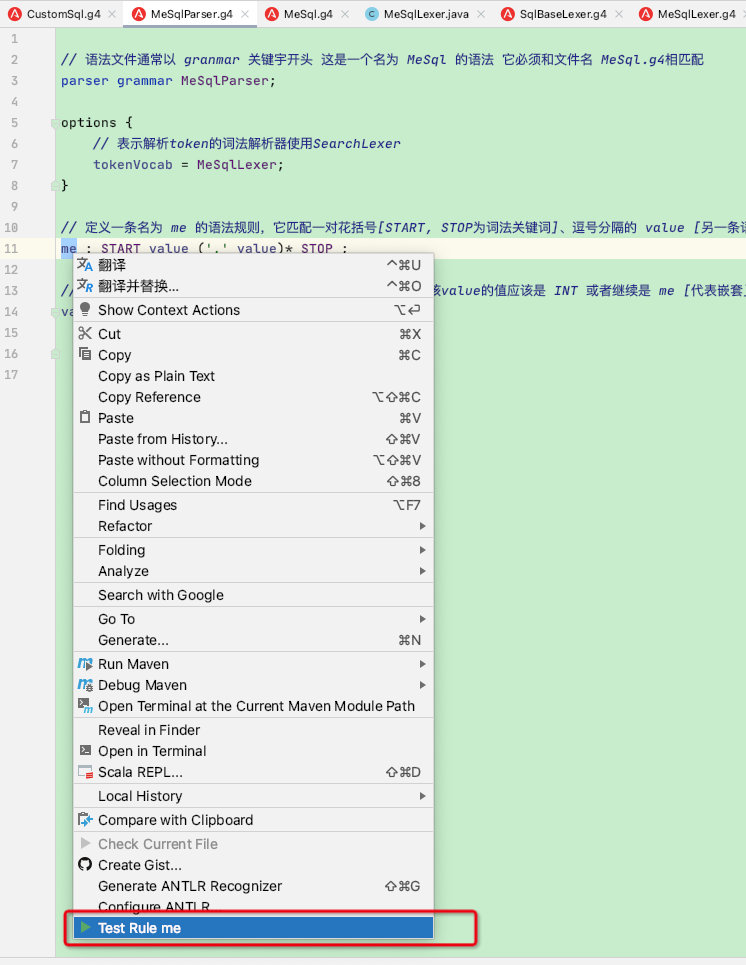
在MeSqlParser语法文件中选中me 右键执行:
检验成功:
6、编译语法文件生成java语法解析类
验证完语法文件是正确的,接下来就要用antlr4的工具将语法文件编译成java解析类,最终落地到代码层面
首先配置生成java类的路径,右键MeSqlParser -> Configure
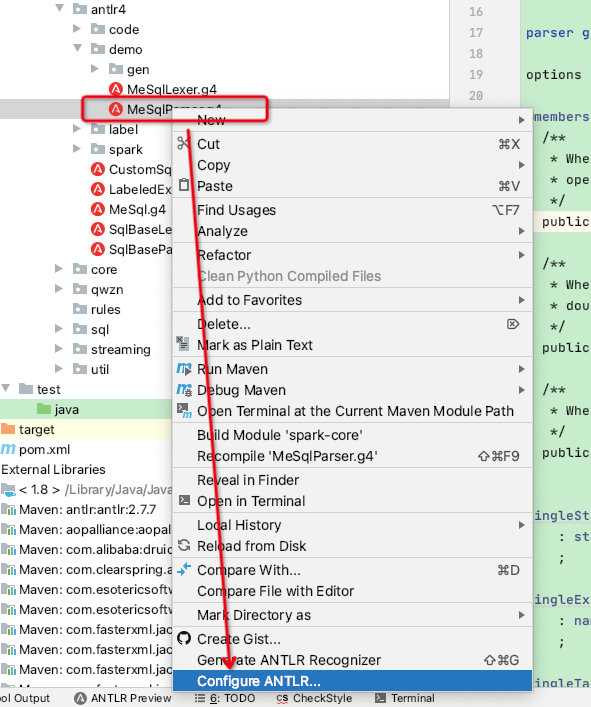

生成java文件:


7、使用解析类
虽然我们在IDEA的antlr4插件中可以看到语句转换成AST语法树:
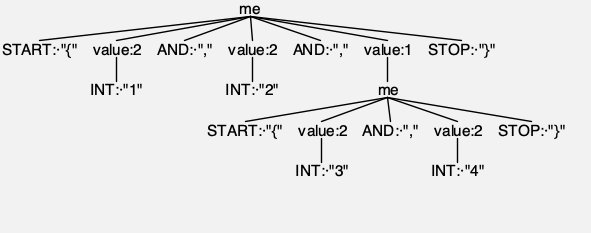
但这是antlr插件帮我们生成的,在实际使用中我们需要将语法树转换成真正的类,类似下图:me类中包含各个子类,同时包含自己

生成的java类便是Antlr4所提供的核心功能,将AST语法树转化成类的表达方式,接下来我们试一下
新建一个Test类复制如下代码:
import org.antlr.v4.runtime.ANTLRInputStream; import org.antlr.v4.runtime.CommonTokenStream; import org.antlr.v4.runtime.tree.ParseTree; public class Test { public static void main(String[] args) { ANTLRInputStream input = new ANTLRInputStream("{1,2,{3,4}"); //词法解析器,处理input MeSqlLexer lexer = new MeSqlLexer(input); //词法符号的缓冲器,存储词法分析器生成的词法符号 CommonTokenStream tokens = new CommonTokenStream(lexer); //语法分析器,处理词法符号缓冲区的内容 MeSqlParser parser = new MeSqlParser(tokens); ParseTree tree = parser.me(); System.out.println(tree.toStringTree(parser)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
我们在输出一行打一个断点,debug模式运行下,如下:
可以看出在ParseTree中包含着children集合,在集合中抱着各个节点,每个节点又可以向下展开,从而形成类形式的语法树!

8、自定义处理规则
在上一步中Antlr4帮我们将{1,2,{3,4}}字符串转化成了语法树,接下来我们需要自定义处理逻辑,从而让语法书按照我们设定的规则进行处理
比如我们现在的规则是需要将{}中的所有数值相加求和,最后得到总和,那么该如何自定义呢?
Antlr4给我们提供了两种遍历树的方式:
1、监听器–antlr4内部控制遍历语法树规则
2、访问者—用户可以手动控制遍历语法树规则
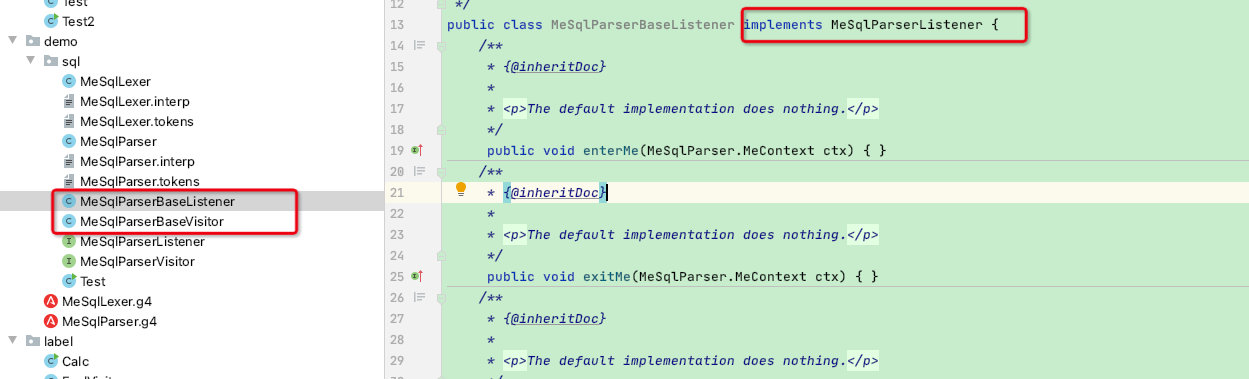
这两种方式在此示例中的体现是两个接口【antlr4帮我们生成的】:

我们只需要在两种接口中选择实现一种接口即可,不过antlr4已经帮我们生成了两个实现类:所以我们只需要直接补充接口函数即可
8.1、监听器模式
监听器模式的特点是用户无需关心语法树的递归,统一由antlr提供的ParseTreeWalker类进行递归即可。
我们先自行实现ParseTreeListener接口,在其中填充自己的逻辑代码(通常是调用程序的其他部分),从而构建出我们自己的语言类应用程序。
MeSqlParserBaseListener:通过map将各个节点分开,最后进行汇总累加
import java.util.HashMap; import java.util.Map; import org.antlr.v4.runtime.ParserRuleContext; import org.antlr.v4.runtime.tree.ErrorNode; import org.antlr.v4.runtime.tree.TerminalNode; public class MeSqlParserBaseListener implements MeSqlParserListener { Map<String, Integer> map = new HashMap<>(); public void enterMe(MeSqlParser.MeContext ctx) { if (!map.containsKey(ctx.getText())) { map.put(ctx.getText(), 0); } } public void exitMe(MeSqlParser.MeContext ctx) { if (ctx.parent == null) { int sum = map.values().stream().mapToInt(i -> i).sum(); System.out.println(" result = " + sum); } } public void enterValue(MeSqlParser.ValueContext ctx) { if (ctx.INT() != null && map.containsKey(ctx.parent.getText())) { map.put(ctx.parent.getText(), map.get(ctx.parent.getText()) + Integer.parseInt(ctx.INT().getText())); } } public void exitValue(MeSqlParser.ValueContext ctx) { } public void enterEveryRule(ParserRuleContext ctx) { } public void exitEveryRule(ParserRuleContext ctx) { } public void visitTerminal(TerminalNode node) { } public void visitErrorNode(ErrorNode node) { } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
主程序:
import org.antlr.v4.runtime.ANTLRInputStream; import org.antlr.v4.runtime.CommonTokenStream; import org.antlr.v4.runtime.tree.ParseTree; import org.antlr.v4.runtime.tree.ParseTreeWalker; public class Test { public static void main(String[] args) { ANTLRInputStream input = new ANTLRInputStream("{1,2,{3,4}}"); //词法解析器,处理input MeSqlLexer lexer = new MeSqlLexer(input); //词法符号的缓冲器,存储词法分析器生成的词法符号 CommonTokenStream tokens = new CommonTokenStream(lexer); //语法分析器,处理词法符号缓冲区的内容 MeSqlParser parser = new MeSqlParser(tokens); ParseTree tree = parser.me(); // ParseTreeWalker类将实现的MeSqlParserBaseListener监听器放入 new ParseTreeWalker().walk(new MeSqlParserBaseListener(), tree); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
这里说一下执行流程:
在MeSqlParserBaseListener类中,语法中的每条规则都有对应的enter方法和exit方法。
例如,当遍历器访问到me规则对应的节点时,它就会调用enterMe()方法,然后将对应的AST语法树节点 MeContext的实例当作参数传递给它。在遍历器访问了me节点的全部子节点之后,它会调用exitMe();
如果执行到叶子节点,它会调用enterValue()方法,将对应的语法树节点 ValueContext的实例当作参数传递给它,执行完成后执行exitValue()方法。
下图用标识了 ParseTreeWalker对AST语法树进行深度优先遍历的过程:

上面的程序结果是通过最后一次exitMe函数来将map中存储的各个节点的总和累加得出,如下:

至此监听器程序结束。
8.2、访问者模式
访问者模式的特点是需要用户自己手动控制语法树节点的调用,优点是灵活,sparksql也是使用这一模式来实现sql语法解析
在MeSqlParserBaseVisitor中,语法里的每条规则对应接口中的一个visit方法
MeSqlParserBaseVisitor2:
import java.util.List; // 用户自己控制语法树节点遍历,十分灵活 public class MeSqlParserBaseVisitor2 extends MeSqlParserBaseVisitor<Integer> { // 循环me节点的所有子节点,调用visitValue函数 @Override public Integer visitMe(MeSqlParser.MeContext ctx) { final List<MeSqlParser.ValueContext> value = ctx.value(); return value.stream().mapToInt(this::visitValue).sum(); } // visitValue函数中判断如果是me节点则调用visitMe,否则返回INT值 @Override public Integer visitValue(MeSqlParser.ValueContext ctx) { if (ctx.me() != null) { return visitMe(ctx.me()); } if (ctx.INT() != null) { return Integer.parseInt(ctx.INT().getText()); } return 0; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
主函数:
import org.antlr.v4.runtime.ANTLRInputStream; import org.antlr.v4.runtime.CommonTokenStream; public class TestVisitor { public static void main(String[] args) { ANTLRInputStream input = new ANTLRInputStream("{1,2,{3,4}}"); //词法解析器,处理input MeSqlLexer lexer = new MeSqlLexer(input); //词法符号的缓冲器,存储词法分析器生成的词法符号 CommonTokenStream tokens = new CommonTokenStream(lexer); //语法分析器,处理词法符号缓冲区的内容 MeSqlParser parser = new MeSqlParser(tokens); // 创建自定义访问器 MeSqlParserBaseVisitor2 visitor = new MeSqlParserBaseVisitor2(); // 将parser语法树头节点放入 Integer sum = visitor.visitMe(parser.me()); System.out.println(sum); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
结果:通过debug,可以看到结果符合预期:
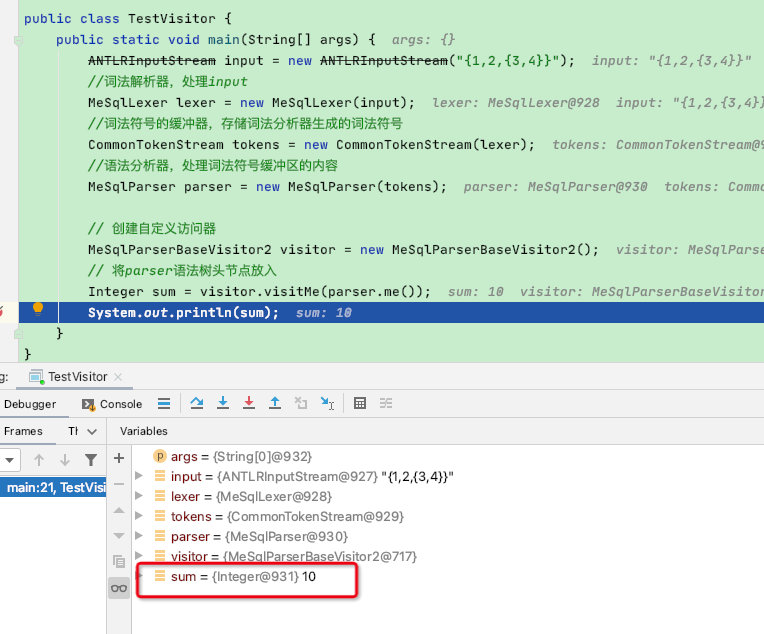
至此访问者模式结束。
9、使用总结
至此我们用两种方式实现了一个简单的DSL语言,回过头来再看一下开篇定义:
ANTLR是一款强大的语法分析器生成工具,可用于读取、处理、执行和翻译结构化的文本,用户可根据需要自定义语法规则来实现相应功能
是不是感觉清晰了很多
四、SparkSql中如何使用
在sparksql源码中是有语法文件的,如下:
https://github.com/apache/spark/tree/master/sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser
接下来我们将这两个文件复制到IDEA中,打开SqlBaseParser.g4,右键执行Test Rule

然后我们随便输入一条sql,查看右侧语法树:可以看到右侧生成了庞大的语法树,这就是SparkSQL的语法树

接下来我们可以根据语法文件来生成相关配置类:

然后我们试着做一个好玩的,新建一个类来自定义访问器:
MyVisitor
/** * 自定义SparkSQL */ public class MyVisitor extends SqlBaseParserBaseVisitor<String> { @Override public String visitSingleStatement(SqlBaseParser.SingleStatementContext ctx) { System.out.println(" ...MyVisitor... "); // 打印 return visitChildren(ctx); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
主函数:
import org.antlr.v4.runtime.ANTLRInputStream; import org.antlr.v4.runtime.CommonTokenStream; public class TestSpark { public static void main(String[] args) { String query = "SELECT * FROM STUDENT WHERE ID > 10;"; SqlBaseLexer lexer = new SqlBaseLexer(new ANTLRInputStream(query.toUpperCase())); SqlBaseParser parser = new SqlBaseParser(new CommonTokenStream(lexer)); // 创建自定义访问器 MyVisitor visitor = new MyVisitor(); // 将parser语法树头节点放入 visitor.visitSingleStatement(parser.singleStatement()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
此时运行会打印…MyVisitor…,由此我们自定义实现了一个sparksql处理的demo
那么spark内部肯定有自己的访问者,位置在spark-catalyst包中,如下:
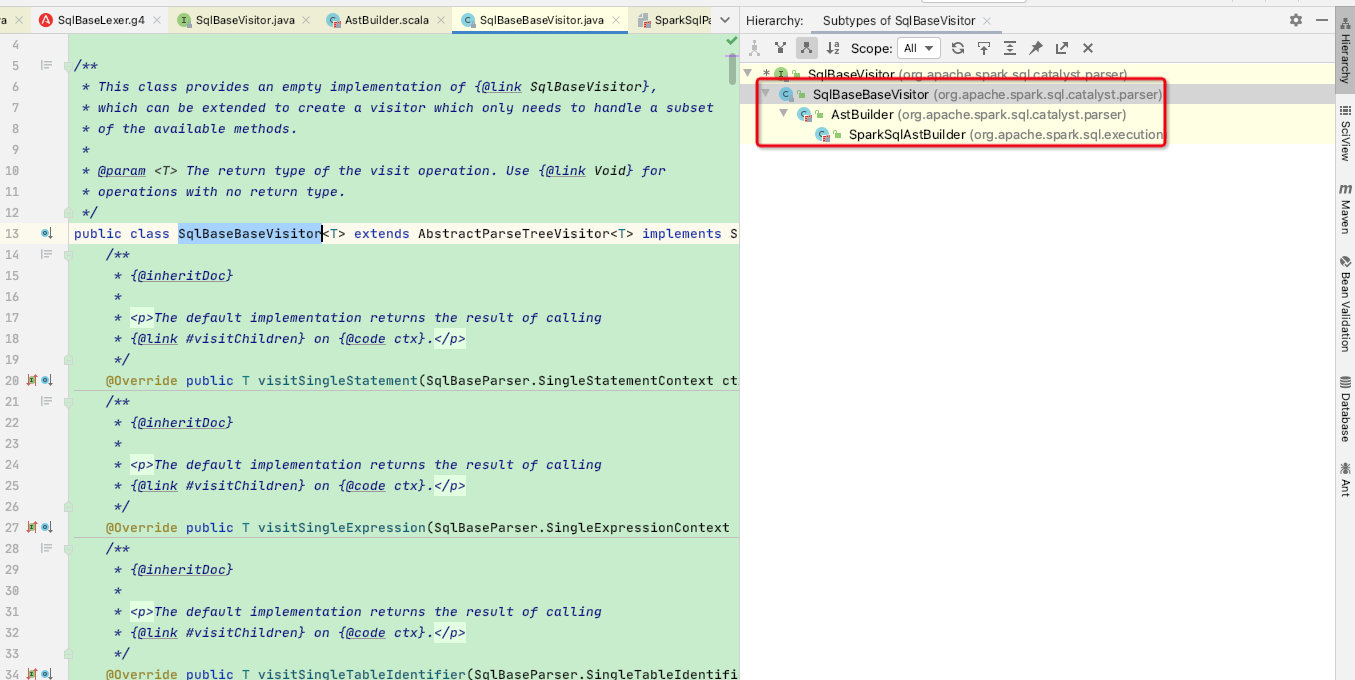
由于sparksql是通过访问器模式实现递归调用语法树,故这里看SqlBaseBaseVisitor
发现真正实现的是子类:AstBuilder、SparkSqlAstBuilder,其内部实现函数便是sparksql各个节点的执行逻辑
至此SparkSql中涉及antlr4的知识点就结束了,后面就是unresovle阶段,将在下一节讲解
-
相关阅读:
编程方式使用Spring切面
pexpect 自动交互输入
大脑神经网络具有什么性,大脑神经网络属性分析
【管理咨询宝藏资料25】某能源集团五年发展战略报告
iOS自动化测试方案(二):Xcode开发者工具构建WDA应用到iphone
SpringBoot+ElasticSearch 实现模糊查询,批量CRUD,排序,分页,高亮!
多智能体强化学习的主要流程是什么?训练方式跟单智能体有什么不同?
5月第3周榜单丨飞瓜数据B站UP主排行榜单(哔哩哔哩)发布!
客户端打开浏览器post提交数据
如何搭建安全的 CI/CD 管道?
- 原文地址:https://blog.csdn.net/qq_35128600/article/details/127890898
