-
RL 从敲门到入门
背景
闲暇时间看了看强化学习相关基础,记录一下读书笔记。主要参考:http://www.incompleteideas.net/book/the-book.html前八章
主要案例:
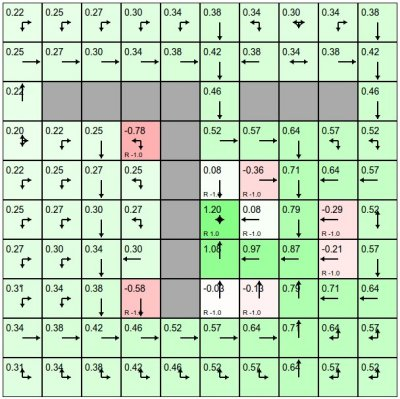
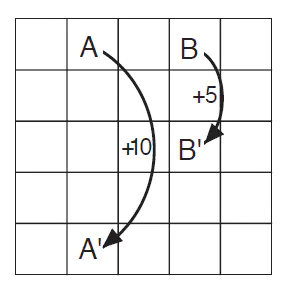
GridWord
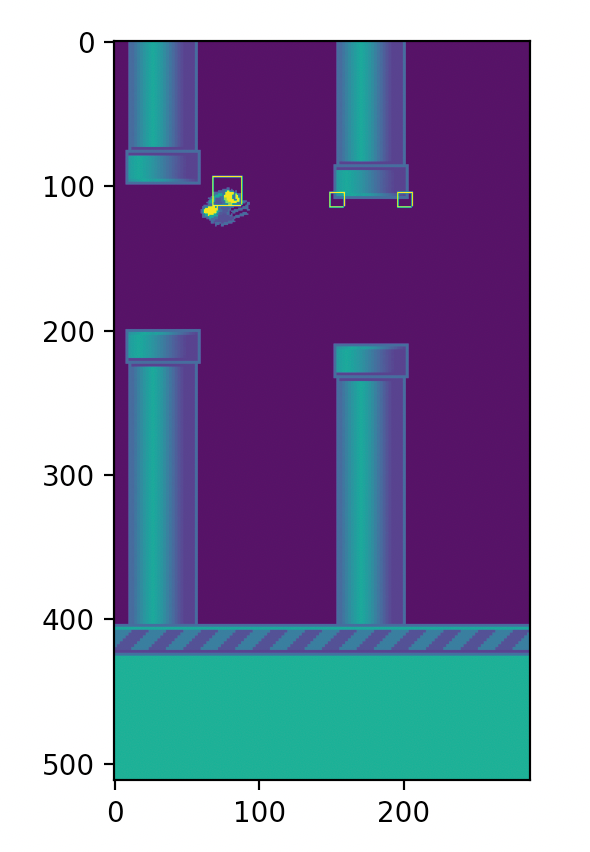
FlappyBird
整体框架
主要的内容安排遵循 特化 -> 泛化 的思路过程,大致是“介绍一个特殊的算法,然后填到已有的框架中,如果已有的框架不兼容,那就想办法泛化当前框架“。
符号与定义
回报(其中R的单步奖励、gamma是折扣系数,表示有多重视未来的收益):
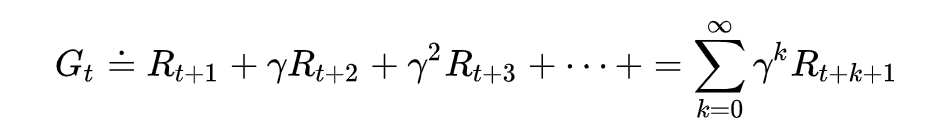
价值函数 v:表示一个状态下期望获得的总收益。
动作价值函数 q:表示一个状态下采取动作 a 期望获得的总收益。
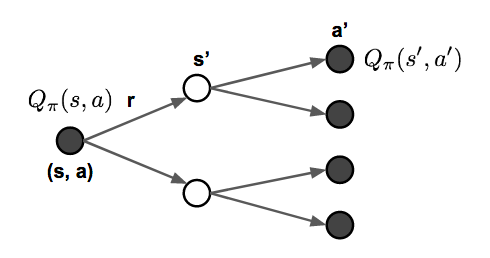
回溯图:

贝尔曼方程:




策略p(a|s) 和 环境动态特性 p(s’,r|s,a)
举例子:

其中 s到sa节点是依据策略决定的;sa到s是依据环境决定的。
我们要学习的是策略。
如果策略不变,全部都是静态的概率的话,那么我们只考虑同质节点,就可以从马尔科夫决策过程退化为马尔可夫过程,这个最被大家熟知的就是Pagerank了,现在就是加了一个决策过程,如果想生硬套在pagerank上,我们就要先有一个目标,比如从随机的节点以最短的步数跳到中国政府网。然后环境的随机性体现在每个网页上都有看不见的广告。四、基于动态规划
必要条件:马尔可夫决策过程描述完备。
这一点通常非常难以做到,真实的环境基本无法精确描述甚至粗略描述环境的动态转移特性。另外计算复杂度也比较高。
相似的问题:HMM4.1 策略评估
目标:给定一个一直策略,计算该策略的状态价值与状态动作价值。
贝尔曼状态价值方程
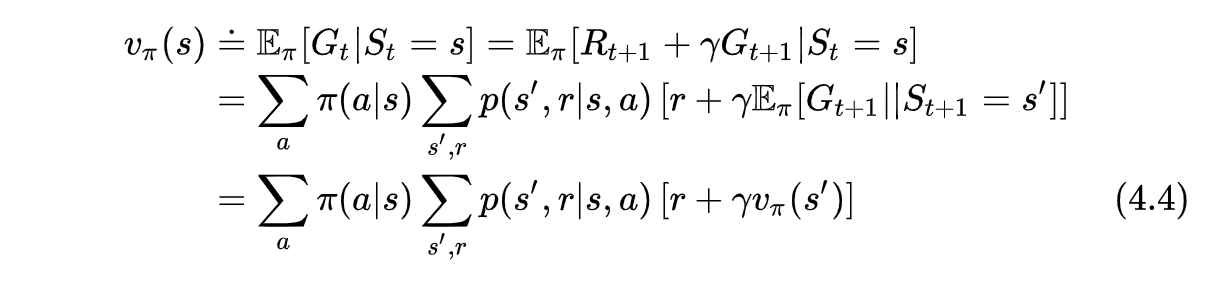
上式可以用直接求解线性方程组的方式解决,也可以用迭代的方式解,即 Iteration Policy Evaluation。
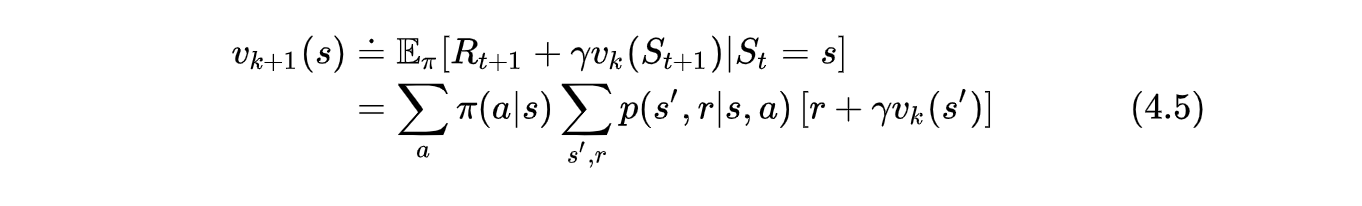
这个方法的局限性:
动态环境难以完全确定。
利用了期望更新,这些方法是基于所有后续状态的期望值的,而不仅仅是后续状态的一个样本。关于 DP 表更新方式
同步更新:每一轮迭代完成后,用新的table完全的替换老的table
就地更新:新的值直接在原table中更新,会有一些随机性,但是实际上比双数组的方法在实践中收敛的更快。4.2 策略提升
根据以上定理,怎么构造一个新的策略呢?也就是说怎么使新策略产生 的行为的动作值函数要大于等于状态值函数 。
值函数是不同动作下动作值函数的期望(对于确定性策略二者是相等的,因为只有一个动作).那么选择使得动作价值函数(即Q value)大的动作不就行了.所以新的策略改进为:
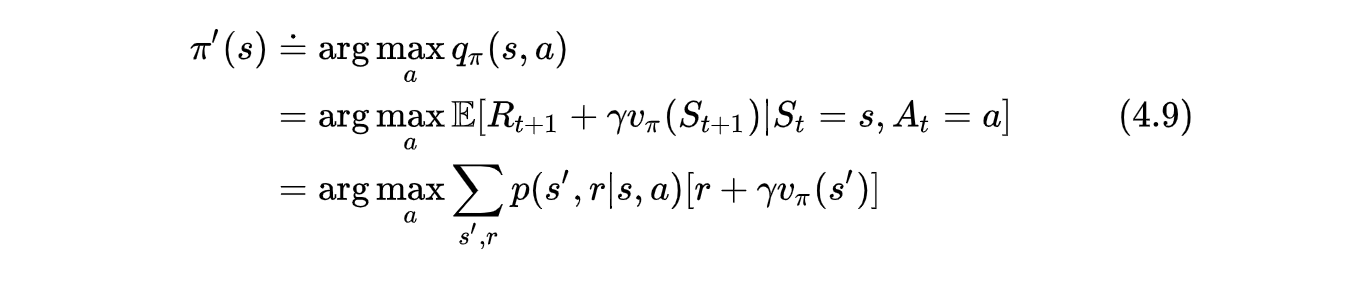
4.3 策略迭代
策略迭代包括两个同时进行的相互作用的流程,一个使价值函数与当前策略一致(策略评估),另一个根据当前价值函数贪心的更新策略。
在策略迭代中,两个流程交替进行,每个流程都必须在另一个开始前结束。
广义策略迭代:
参考:Majorization-Minimization优化框架_彬彬有礼的专栏-CSDN博客 以及 Majorization-Minimization算法 | pxxyyz

伪代码:

DEMO:REINFORCEjs: Gridworld with Dynamic Programming4.4 价值迭代
策略迭代的问题在于,有两层循坏:最外层的循环基本认为不能省略,因为Policy Improve需要不停的提升自己。那么内层的Policy Evaluate的循环呢?
可以从 Demo 中发现,迭代30轮后执行策略提升和迭代10000轮后得到的策略是几乎一样的(出现这种情况的原因可以简单的理解为:决策的时候只关注状态值的相对大小,而不是绝对值)。一方面,我们设置一个较大的阈值,来使得 Policy Evaluate 可以更加粗略、快速的认为自己收敛了。
而更加极端的情况,就是去掉 Evaluate 这一步的循环,每次只执行一遍就进入策略提升环节。

而这个公式其实就是公式其实就是,贝尔曼最优方程的迭代形式。根据前面的内容,这个迭代一定收敛到最优的值函数 ,对应的我们就得到了最优策略。在两者(完整的策略迭代和值迭代)之间的**,就是截断策略迭代算法**(truncated policy iteration)。从名字就可以看出它和策略迭代很像,只是缩减策略评估的迭代轮数。并且把两个过程融合成了一个更新表达式。
4.5 异步动态规划
看Demo可以发现策略迭代的另一个问题吗?
DP算法的一个重大问题是我们每一轮策略评估或者值迭代中需要遍历每一个状态。这样对于状态空间很大的问题,比如棋类游戏,是不可接受的。因为即使执行一轮更新也可能需要我们无法接受的时间。
所以我们需要一种更灵活的更新方式。这就是异步动态规划算法。在异步DP算法中,我们可以以任意次序来更新状态的值。也可以特定频率来更新某些状态。比如有些状态可能更新了若干次,而其他某些状态可能才更新一次。
**这种灵活的更新次序就避免了严格遍历每一个状态导致的问题。但是这并不意味着我们的计算量减小了(因为要收敛,理论上所有状态都要遍历无限次)。只是我们可以选择那些有可能尽快改善策略的状态,而不是卡在某些毫无意义的状态上。**对于某些和最优行为关联不大的状态,甚至可以忽略。另外我们也可以设计更新的次序,从而使“值”信息能更有效的传播(回想备份图的回溯过程)。
异步算法使计算和实时交互的结合更容易。就是让智能体在环境中探索,然后用DP更新探索到的状态的值。同时利用DP更新后的策略来指导智能体在环境中决策。以蒙特卡洛的方式得到状态序列,然后用DP的方法来更新值函数和策略,这里已经有了下一章的影子。4.6 广义策略迭代
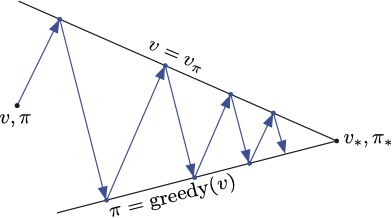
其实是将策略迭代和值迭代结合到一起的一个 general 的框架。
几乎所有的RL方法都可以用GPI很好的描述。也就是说他们都有策略和值函数。策略基于值函数得到改进。同时,值函数总是期望收敛到当前策略的值。如果两个过程都稳定了,那么一定是得到了最优的策略(贝尔曼最优方程决定的)。
也可以通过下图来理解GPI中策略评估和策略提升的关系。他们相互竞争又相互合作。
竞争表现在如果是当前策略相对于值函数贪婪了,那么这个值函数不是当前策略的值函数(因为策略变了)。合作表现在值函数又会不断去拟合新的策略,并且这两者共同使得策略向最优解的方向前进。
上面左图表示策略迭代;右图表示值迭代或者截断策略迭代。一点总结
异步更新的迭代轮数需要大一点,因为同步更新每次会迭代全部n个状态,但是异步的只会更新一个,所以外层的iter_num要设置为*n才能保证每个state统计意义上和同步更新有同样的更新次数
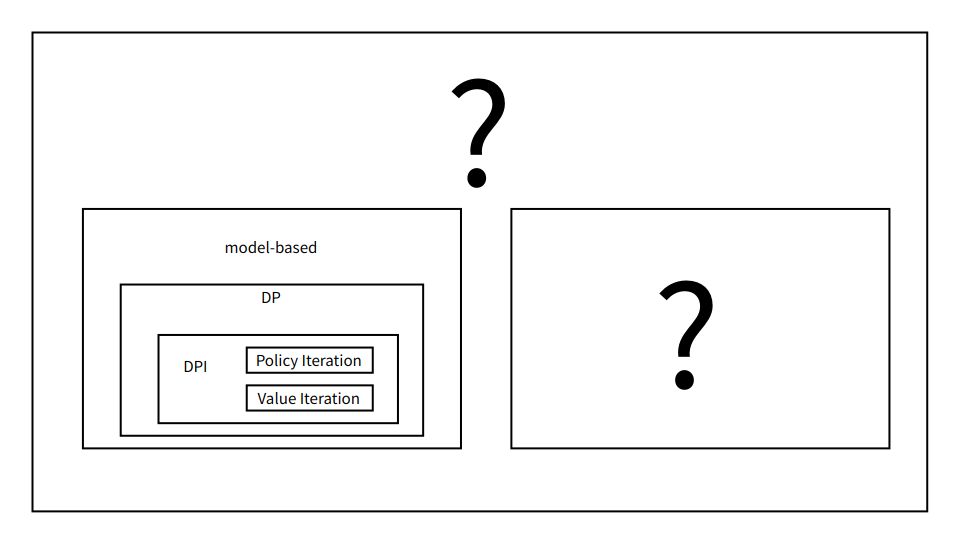
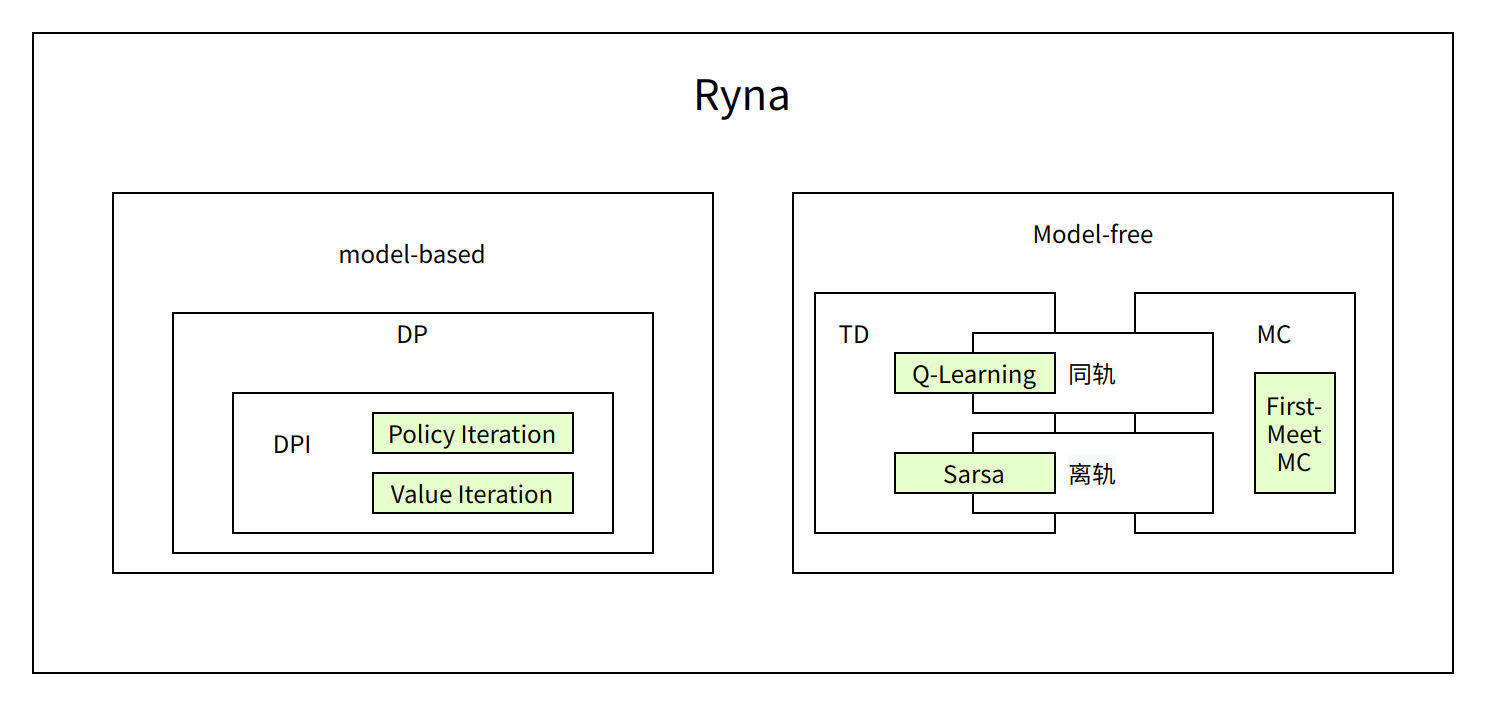
Model-based vs. Model-free
Policy iteration 和 value iteration 都需要得到环境的转移和奖励函数,所以在这个过程中,agent 没有跟环境进行交互。
在很多实际的问题中,MDP 的模型有可能是未知的,也有可能模型太大了,不能进行迭代的计算。比如 Atari 游戏、围棋、控制直升飞机、股票交易等问题,这些问题的状态转移太复杂了。
DP算法中一个重要的思想就是自举。所有的方法都根据后继状态价值的估计,来更新对当前状态价值的估计。
算法特征与回溯图:model-based,planning
RoadMap
五、蒙特卡罗方法
这是一类实用的估计价值函数并寻找最优策略的算法,因为仅需要经验。我们同样需要建立一个模型,不过这个模型只需要一些状态转移的样本,而不像DP一样需要所有的模型可能的转移概率。
暂时我们只考虑分幕任务。这样的话,我们可以让价值估计和策略改进在幕结束时才进行,因此蒙特卡洛算法是逐幕做出改进的,而非每一步都改进(这就变成了在线算法)。
本章中的蒙特卡洛估计,特指对完整的回报取平均的做法。
这里的蒙特卡洛估计与常见的求解期望的应用不一样的地方在于,每个状态都需要被估计,但是每个状态的真实值又依赖于自己和相关状态下所采取的策略,因此这是一个非平稳的蒙特卡洛估计问题,为了处理其非平稳性,我们使用了类似 GPI 的迭代思想。
划重点:我们此时无法知道一个状态采取一个动作后的后继状态的转移概率了5.1 蒙特卡洛预测
一个很自然的做法就是利用回报平均值来近似期望回报。当样本越来越大时,这个估计值将会收敛到期望值。这几乎是所有MC方法的思想。
根据采样的思想,我们就可以根据策略选择动作,然后收集多条经历了状态轨迹(episode),计算回报均值就行了。但是你可能会想到一个问题:如果一个episode中同一个状态出现了多次,到底该记一次还是出现一次记一次。这就是first-visit MC方法和every-visit MC方法。面对敌人,开枪 面对敌人,开枪 面对敌人,开枪 面对敌人,逃跑 我跪了 1+(0.9*-70)=-62 1+(0.9*-79)=-70 1+(0.9*-89)=-79 1+(0.9*-100)=-89 -100 图注:reward discount v(t+1)
first-visit MC方法对比DP的优势:在于如果只想估计某一个或者某几个状态的状态值,MC估计可以做到但是DP估计做不到。即每个状态的估计是独立的。MC对于一个状态的估计完全不依赖对其他状态的估计。
5.2 动作价值的MC估计
小思考:其实 FirstVisit MC State Evaluation 算法是没用的,为什么?
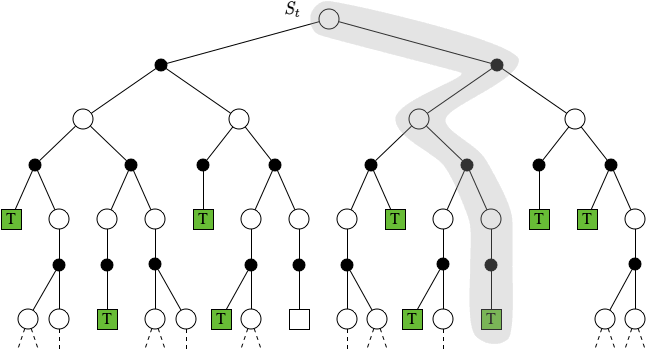
MC方法估计动作值函数
如果无法得到环境的模型,那么计算动作的价值(q(s,a))比起计算状态价值会更加有用。因为在有环境模型的时候,我们可以简单的在当前状态下尝试每一个动作,观察到了什么状态,然后选一个最大的R + discount * V(S’)就可以。
但是如果我们不知道环境模型,那么就必须有办法计算出动作价值函数才可以。(考虑一个真实游戏的env,除非我们有即时存档读档的功能,可以不断的恢复一个特定的状态,然后尝试所有的可能的下一步状态,否则就无法利用DP回溯计算。)其实用MC方法估计动作值函数和估计状态值函数基本都是一样的。也是采样轨迹,求均值。但是不同的是我们记录的是从某个**状态动作对(state action pair)**之后的累积回报,然后求均值。从对(状态)的迁移转换到最(状态-动作)的迁移困难的地方只是我们的思考角度,从算法本身实施上是完全一致可复用的。
如何保持试探
这里需要探索机制,因为我们的估计是依赖采样算法的,采样算法的要求是“采样次数足够多”。必须在对估计 q(s,a) 的时候,首先是要确保 s 下所有的 a 都可以采样到足够多次。
试探性出发:将特定的状态-动作设置为轨迹的起点。(棋类可以做到,或者模拟环境也许可以做到,但是一些实时环境不能满足这个要求。)
非最优试探动作。
小思考:考虑为什么DP不需要探索机制?策略动作估计就选择当前最好的动作就可以?5.3 蒙特卡洛控制
基于MC的广义策略迭代
知道我们的目标,现在的问题就是如何做?无外乎也是GPI的思想,和DP一样,不断地策略评估,策略提升,直到收敛。不同之处仅仅是我们估计值函数的手段不一样了。DP中使用贝尔曼方程,这里使用的是MC方法,也就是上一节讲的方法。另外,对于MC在策略评估中,我们往往评估的是动作值函数,而非状态值函数。所以整个过程如下:

蒙特卡洛控制和前面基于动态规划的控制是一样的方法,因为如上图所示,两个阶段被 pi 和 Q 完全的抽象分割了。而 improvement 这篇文章里我们自始至终用的其实都是 greedy 和 ε-greedy ,所以我们的重点关注点在这篇文章中应该放在 Evaluation 这一步。MC策略迭代方法的缺陷
我们在MC策略迭代方法中做了两个假设:
第一是每个episode是exploring starts
第二是策略评估可以进行无数次
为了得到一个实际可行的策略,我们必须去掉这两个假设。我们先来解决第二个假设。
类似我们在DP方法中的解决办法,我们给出两个方案:
第一种:还是要坚持执行完整的策略评估,只是我们不再追求精确收敛。相反,当值函数落在收敛值的一个误差范围内,就Ok了。精确收敛需要无限步,而对于收敛到一个范围则执行足够多步数就行了。
第二种:不需要做完整的策略评估,执行若干步甚至是一步评估就行了,类似于从策略迭代到值迭代到广义扩展。所以说无限次策略评估只是理论上的条件,现实中还是很好解决的。5.4 没有试探性假设的蒙特卡洛控制
在介绍具体的方法前,我们先介绍两个概念:
on-policy(同轨策略):它的含义是我们估计或者改善的策略和决策的策略是一样的。决策的策略通常也成为behavior policy。
off-policy(离轨策略):与上面相反,当然就是说我们用来采样的策略(behavior policy)和待估计或者改善的策略不是一个策略。同轨策略的方案:因为我们说了exploring starts产生的原因就是怕采样策略不能取到所有的状态空间(这里的采样策略就是目标策略,它往往是一个确定性策略,或者趋向于一个确定性策略,所以有些状态探索不到是很正常的)。可是现在不一样了,我们的 行动策略 完全可以是一个随机的策略来保证能够遍历所有状态和动作。这样exploring starts就没必要了,关键点就是让目标策略自己负责探索。
离轨策略的方案:使用soft policy,比较简单的方案就是使用 ε-greedy method,来确保每一个动作都有非零概率被采样。关键点是让负责采样的行动策略负责探索,目标策略自身用来学习,并且使用恰当的重采样。
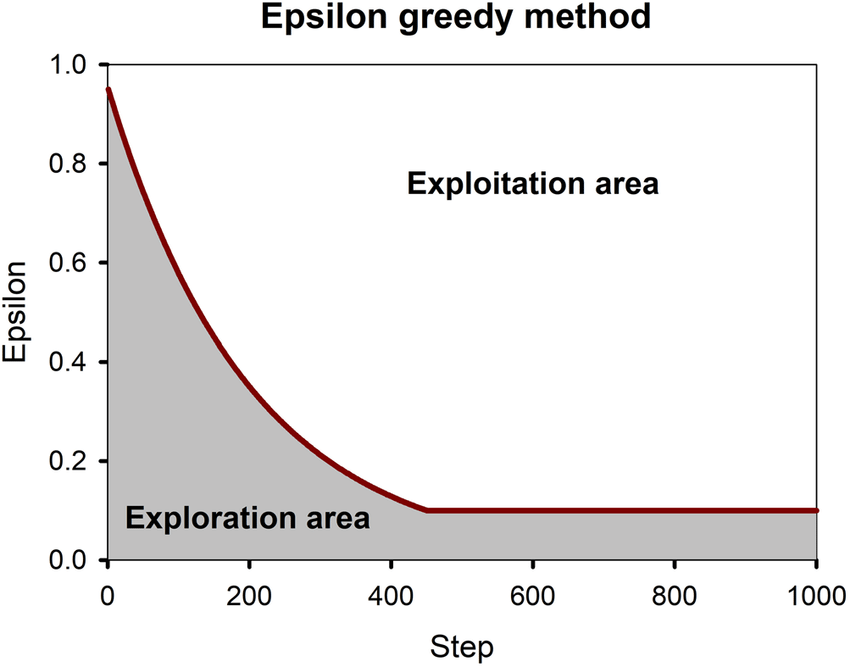

本节小思考:考虑flappy bird中使用MC方法,由于初始时每一个状态的value都是一样的,那么每一帧状态下,策略对任何一个行为(飞 or 不飞)都没有偏好,就会等概率的选择飞或者不飞(有问题吗)?5.5 离轨控制算法
跳过
同离轨对比
on-policy更加直观,简单。用要学习的策略去产生数据,再用它产生的数据来更新策略。但是样本效率低,因为早期产生的数据会被抛弃,只有最新的策略及其它产生的数据参与更新。
off-policy由于产生动作的策略和学习的策略不一样。而且通常来说方差更大,收敛更慢。但是off-policy方法更通用和强大。如果换个视角来看,on—policy 可以看成是 off-policy 的特殊情况。再者,想象一下,我们可以使用任何策略来产生样本,而不用关心要求解的策略。这样就很容易获得大量的数据,样本效率高。一点总结
对比 MC 方法和 DP 方法
优点
- 直接通过交互经验学习,因此不需要完备环境模型(environment dynamics)
- 可以使用仿真或者采样模型(sample models)。这里的sample model是相对于explicit environment model的。对于很多问题我们很容易得到采样模型,但却不容易得到显式的转移概率模型
- 利用MC方法,我们可以只聚焦于一个子状态空间,比如某些我们感兴趣的状态。而DP理论上必须遍历整个状态空间。
- 它不严格依赖于马尔科夫性假设。在 DP 和后面将要讲到的时序差分方法中都需要通过后续状态(successor state)值来更新当前状态,这个显然以来马尔科夫假设的,但是 MC 完全是采样的,所以不依赖假设。
缺点:
- 计算效率可太低了
关键点
非自举、依赖探索与经验、model-free
小思考:MC的缺点是什么?样本需求大,或者说样本数据利用率低。
算法特征与回溯图:

RoadMap

六、时序差分学习(TD)
如果必须挑出一个强化学习独特的核心的思想来,毫无疑问是时间差分学习(temporal-difference learning)。
TD学习结合了MC方法和DP方法的思想。可以直接从原始经验中学习,不需要知道环境模型,这一点和MC方法一致。同时又不需要仿真出完整的轨迹来,直接可以利用其它状态的估计来更新当前状态的值,这一点又和DP方法类似。
对于控制问题,DP、TD和MC都使用了广义策略迭代(GPI)的某个变种,这些方法之间的主要差别在于他们解决预测问题的不同方式。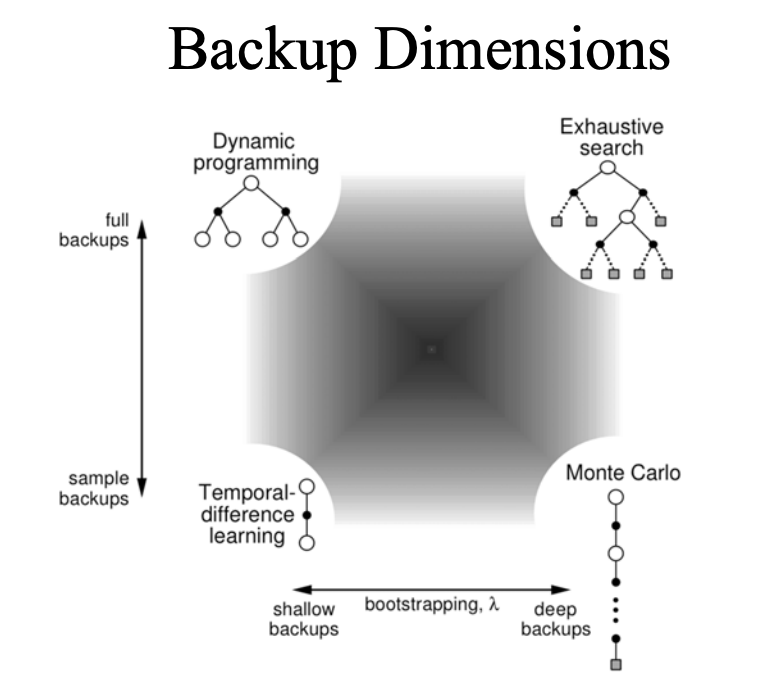
6.1 时序差分预测
面对敌人,开枪 面对敌人,开枪 面对敌人,开枪 面对敌人,逃跑 我跪了 MC 1+(0.9*-70)=-62 1+(0.9*-79)=-70 1+(0.9*-89)=-79 1+(0.9*-100)=-89 -100 TD | 0 | 0 | 0 | 0 | -100 |
| | 1+(0.9*-0)=1 | 1+(0.9*-0)=1 | 1+(0.9*-0)=1 | 1+(0.9*-100)=-89 | -100 |
| | 1 | 1 | -79 | | -100 |TD和MC都利用经验来解决预测问题。大致来说,MC需要一直等到一个状态的访问得到Gain之后,再用这个Gain作为V(s)的目标进行估计。
这就意味着MC方法必须要等到一幕结束才可以,但是TD方法,则不需要;比如最简单的TD方法,在状态转移到S_t+1并收到R_t+1的收益的时候可以立即作出更新。
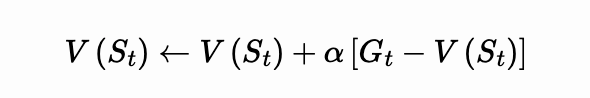

其中我们可以定义 TD 误差,衡量了当前估计和估计目标(更好)的差别。:
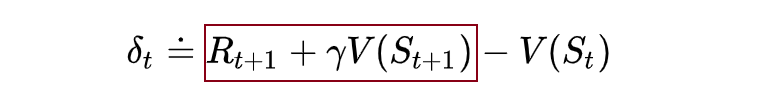
6.4 Sarsa: On-policy TD Control

这个变化就是最简单的 TD 算法,即TD(0),很自然的我们可以想到更高级的泛化,也就是TD(n)。
在这里不给出 TD Value Estimate 的伪代码,因为没用。。(原因类似MC对state的估计实际用途不大,为了可以策略提升,主要需要的是动作价值的估计)
思考:为什么 TD 算法会比 MC 收敛的更快一点?6.5 Q-Learning
Sarae 是在线策略,因为行动策略和目标策略是一个策略。


6.7 关键点
关键词与回溯图:自举、model-free
RoadMap

七、n步自举法(TODO)

八、基于表格型方法的规划与学习
规划(planning)与学习(learning)的区别仅在于,planning使用模型经验,learning使用真实经验。
这样的话,我们可以对前面提到的方法分分类:
基于动态规划的方法 -> 规划
基于蒙特卡洛估计的方法 -> 学习
基于时序差分的方法 -> 学习
有模型方法的核心部分是规划,无模型则更强调学习。比如都需要计算值函数,都是依赖于备份回溯操作来更新值函数。本章目标是找到一个框架统一这两大类方法。8.1 模型和规划
model:这里的模型指的不是我们用于学习的agent,而是说对环境的模型。是一个wrapper,他会像真实环境一样,对action做出响应,但是这个可能是模拟出来的。
model:
distribution model(分布式模型)
sample model(采样模型)
experience:
real experience(真实经验):从真实模型产生
simulated experience(模拟经验):从学习到的模型产生
Value Iteration
Planning:通过仿真经验学习
Learning: 通过真实经验学习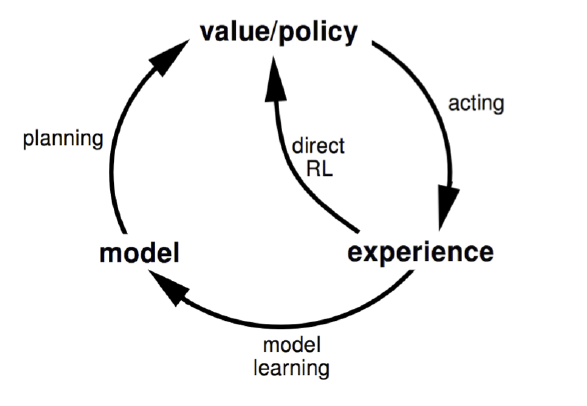
其中间接方法能够更充分的利用有限的经验,从而获得更好的策略,减少与环境的相互作用;直接方法则更加简单健壮,不受模型自身偏差影响。
一个简单的环境类:

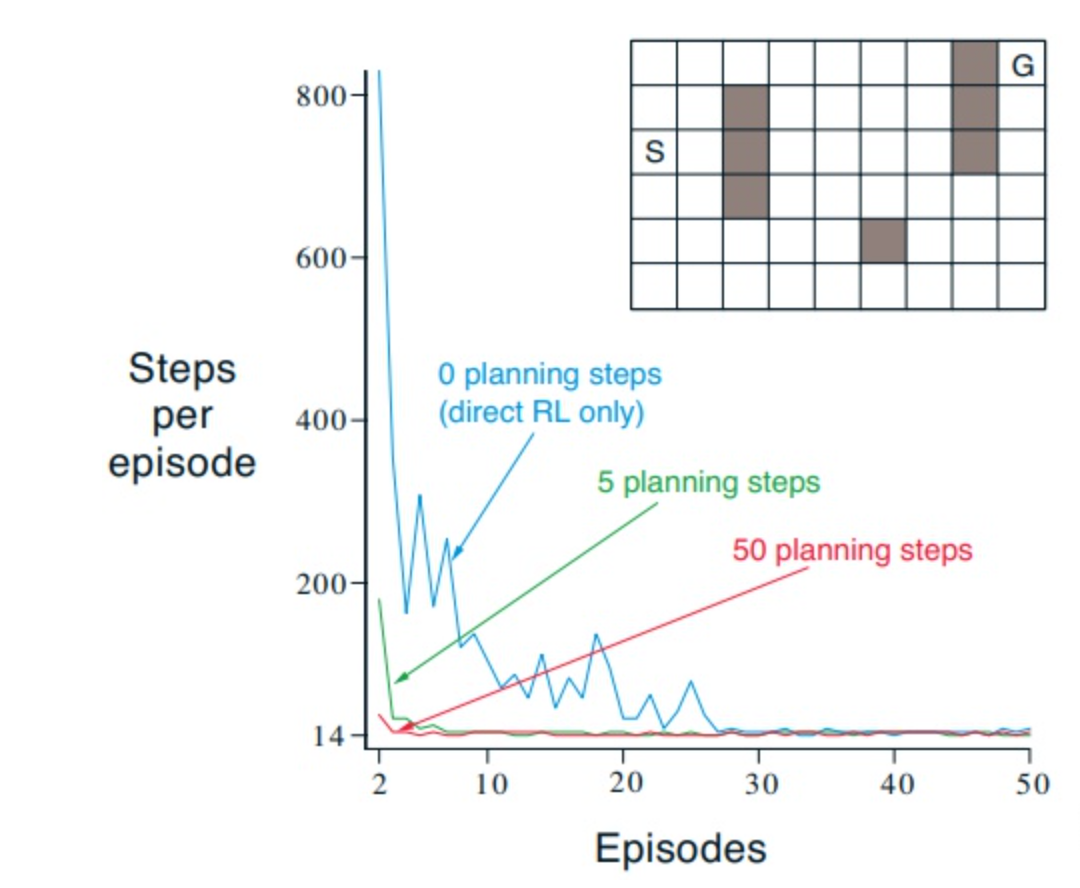
8.2 Dyna: Integrated Planning, Acting, and Learning


8.4 优先遍历
问:单纯的随机抽取有什么问题?
对快速更新的追求
见上图,在第二个episode时,状态值的更新如箭头所示。对于没有规划的TD(0)算法,只有目标状态的前一个状态被更新了。其他的都是0。试想如果在规划的时候,我们随机抽取的状态不包含G的前一个状态,那么执行一步更新后,所有状态的值还是0。
怎么更新才最有效呢?也许沿着目标状态(goal state)倒着更新是一个好的思路。可是目标状态这是个很强的约束,也许有的问题没有目标状态,也许有的问题目标状态很多,你到底应该从哪一个开始倒推。比如星际争霸,赢的方式有太多流派与可能性,就无法确定所谓的目标状态。
实际上,在HRL(分层强化学习)中,专门有一个研究的领域就叫做option discovery,就是为了找子目标,从而简化问题。最近也有一些方法试图通过自主学习的方式学习出这些子目标来,但往往实验表明学习到的现象很难解释,很难给它一个明确的物理意义。
从goal state倒推的方式是不具有普适意义的。那么更为普遍的做法是什么呢?更一般的做法是从任何值发生变化的状态开始倒推。首先呢,状态值是一个普遍的概念,所以具有一般性。其次,如果某个状态值变了,从它周围往外扩散,自然也是最合理的。这个一般性的思想叫做反向聚焦(backward focusing)。对环境的不信任与好奇机制
DynaQ -> DynaQ+
假设GridWorld游戏,在训练的某一个阶段(此时假设模型已经找到一条通向终点的路径),我们在当前路径下设置障碍或者在其他位置设置捷径,会怎么样?
如果是epsilon-greedy算法,对于有障碍的问题,会用大量的时间不死心的在原路径上徘徊;而对于捷径,则几乎无法发现。对于这种【渣男环境】,我们为DynaQ加入【好奇心】,即“对于长时间未使用的行动,逐渐增大其explore prob”的思想。


RoadMap
后续话题
期望更新与采样更新的对比
实时动态规划
轨迹采样
决策时规划、启发式搜索、蒙特卡洛树搜索
预演算法
DQN讲一练二考三
Sarsa 和 QLearning 的 区别到底是什么?你觉得这两个算法哪个收敛的更快?
疑问
P98 收敛性怎么保证?
如何证明时序差分法和MC方法的误差界?
对于离策略的算法,一般都需要利用重要性采样来纠正行为策略采样带来的偏差。那么为什么这里的Q学习算法没有用重要性采样呢?Why don’t we use importance sampling for one step Q-learning?Flappy
参考
Easy-RL
https://www.cs.upc.edu/~mmartin/url-RL.html
9.3 When the Model Is Wrong
A (Long) Peek into Reinforcement Learning
https://www.ctolib.com/LyWangPX-Reinforcement-Learning-2nd-Edition-by-Sutton-Exercise-Solutions.html
Chapter 6: Temporal-Difference Learning · Reinforcement Learning: An Introduction(2nd)
强化学习入门(第二版)读书笔记 -
相关阅读:
JAVA潮购购物网站计算机毕业设计Mybatis+系统+数据库+调试部署
交互与前端3 前端需求简单梳理
node.js中HTTP不同请求方法的处理(GET,POST),如何获取GET,POST请求中的参数
Node学习五(1) —— 查询和读写文件(path模块,路径处理)
机器人仿真-SolidWorks学习笔记(0)-前期准备
Python-sklearn-diabetes项目实战
[附源码]计算机毕业设计springboot实验室管理系统
InheritableThreadLocal 在线程池中进行父子线程间消息传递出现消息丢失的解析
Charles安装配置
【微软技术栈】C#.NET 正则表达式
- 原文地址:https://blog.csdn.net/cookieZZ/article/details/127882699