-
长文讲解Linux内核性能优化的思路和步骤
一.性能调优简介
1.为什么要进行性能调优?
1) 编写的新应用上线前在性能上无法满足需求,这个时候需要对系统进行性能调优
2) 应用系统在线上运行后随着系统数据量的不断增长、访问量的不断上升,系统的响应速度通常越来越慢,不满足业务需要,这个时候也需要对系统进行性能调优
2. 性能调优包括那些方面?
1. 谈到系统或产品的性能调优,可以从广义和狭义两个范围来理解。
从广义的层面来看,就不仅限于程序内部了,因为造成系统性能问题的瓶颈很可能来源于方方面面,而这种情况往往是性能调优很普遍的情况,
下面就从广义的范围细分成几个角度来进行阐述,见图-1 广义性能调优鱼骨图

2.从狭义的范畴来看,性能调优主要是指通过修改软件程序逻辑、结构等技术手段提升软件产品的各项性能指标,如响应时间等。本文重要是从狭义的范畴来看。
从狭义的范畴看,性能调优可以从 硬件(计算机体系机构)、操作系统(OS\JVM)、文件系统、网络通信、数据库系统、中间件、应用程序本身等方面入手。
这里主要关注JVM、中间件、应用程序的性能调优。
3. 性能的参考指标
执行时间:一段代码从开始运行到运行结束所使用的时间。
CPU时间:(算法)函数或者线程占用CPU的时间。
内存分配:程序在运行时占用的内存空间。
磁盘吞吐量:描述I/O的使用情况。
网络吞吐量:描述网络的使用情况。
响应时间:系统对某用户行为或者动作做出响应的时间。响应时间越短,性能好。
【文章福利】小编推荐自己的Linux内核技术交流群: 【977878001】整理一些个人觉得比较好得学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!前100进群领取,额外赠送一份 价值699的内核资料包(含视频教程、电子书、实战项目及代码)

内核资料直通车:Linux内核源码技术学习路线+视频教程代码资料
学习直通车:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
二.性能调优步骤
1.性能调优步骤图

调优前首先要做的是衡量系统现状,这包括目前系统的请求次数、响应时间、资源消耗等信息,例如B系统目前95%的请求响应时间为1秒。
在有了系统现状后可设定调优目标,通常调优目标是根据用户所能接受的响应速度或系统所拥有的机器以及所支撑的用户量估算出来的,例如 设定调优目标:95%的请求要在500ms内返回。
在设定了调优目标后,需要做的是寻找性能瓶颈,这一步最重要的是找出造成目前系统性能不足的最大瓶颈点。找出后,可结合一些工具来找出造成瓶颈点的代码,到此才完成了这个步骤。
在找到了造成瓶颈点的代码后,开始进行性能调优。通常需要分析其需求或业务场景,然后结合一些优化的技巧确定优化的策略,优化策略或简或繁,选择其中收益比(优化后的预期效果/优化需要付出的代价)最高的优化方案,进行优化。
优化部署后,继续衡量系统的状况,如已达到目标,则可结束此次调优,如仍未达到目标,则要看是否产生了新的性能瓶颈。或可以考虑继续尝试上一步中制定的其他优化方案,直到达成调优目标或论证在目前的体系结构上无法达到调优目标为止。
三. 性能调优思路
性能调优的步骤主要有:衡量系统现状、设定调优目标、寻找性能瓶颈、性能调优,验证是否达到调优目标。
本文档主要关注调优步骤中的 寻找性能瓶颈 和 性能调整(优) 两个关键的阶段阶段,主要思路见下图:图-3 寻找性能瓶颈和性能调优项结构分解图
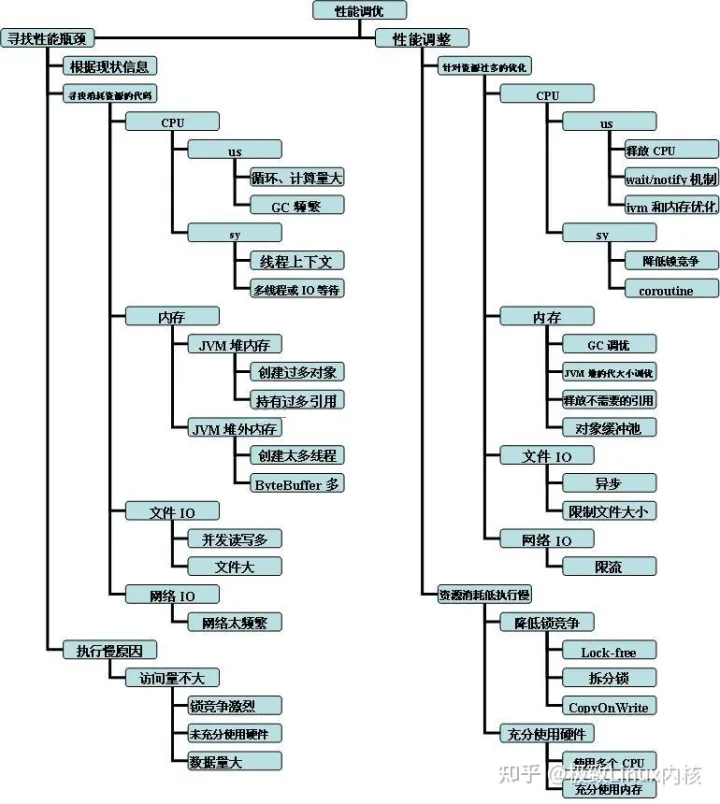
四.寻找性能瓶颈
寻找性能瓶颈分个两部分:寻找过度消耗资源的代码 和 寻找未充分使用资源但程序执行慢的原因和代码。
通常性能瓶颈的表象是资源消耗过多外部处理系统的性能不足;或者资源消耗不多但程序的响应速度却仍达不到要求。
这里资源主要是指:消耗在CPU、内存、文件IO、网络IO等方面资源。机器的资源是有限的,当某资源消耗过多时,通常会造成系统的响应速度慢。
外部处理系统的性能不足主要是指所调用的其他系统提供的功能(如数据库操作的响应速度不够);所调用的其他系统性能不足多数情况下也是资源消耗过多,但程序的性能不足造成的; 数据库操作性能不足通常可以根据数据库的sql执行速度、数据库机器的IOPS、数据库的Active Sessions等分析出来。
寻找未充分使用资源但程序执行慢的原因和代码:资源消耗不多、但程序的响应速度仍然达不到要求的主要原因是程序代码运行效率不够高、未充分使用资源或程序结构不合理。
对于Java应用而言,寻找性能瓶颈的方法通常为首先分析资源的消耗,然后结合OS和Java等一些分析工具来查找程序中造成资源消耗过多的代码。
1.CPU消耗分析
在Linux中,CPU主要用于 中断、内核进程以及用户进程的任务处理,优先级为:中断 > 内核进程 > 用户进程,在学习如何分析CPU消耗状况前,有三个重要概念交代一下。
1) 上下文切换、运行队列、利用率
上下文切换
每个CPU(或多核CPU中的每核CPU)在同一时间只能执行一个线程。 Linux采用的是抢占式调度:即为每个线程分配一定的执行时间,当到达执行时间、线程中有IO阻塞或高优先级线程要执行时,Linux将切换执行的线程,在切换时要存储目前程序的执行状态PCB(Program Control Block),并恢复要执行的线程的状态,这个过程就称为上下文切换。
对于Java应用,典型的是在进行文件IO操作、网络IO操作、锁等待或线程Sleep时,当前线程会进入阻塞或休眠状态,从而触发上下文切换,上下文切换过多会造成内核占据较多的CPU使用,使得应用的响应速度下降。
运行队列
每个CPU核都维护了一个可运行的线程队列,例如一个4核的CPU, Java应用中启动了8个线程,且这8个线程都处于可运行状态,那么在分配平均的情况下每个CPU中的运行队列里就会有两个线程。通常而言,系统的load主要由CPU的运行队列来决定,假设以上状况维持了1分钟,那么这1分钟内系统的load就会是2,但由于load是个复杂的值,因此也不是绝对的,运行队列值越大,就意味着线程要消耗越长的时间才能执行完。 Linux System and NewWork Performance Monitoring中建议控制在每个CPU核上的运行队列为1-3个。
利用率
CPU利用率为CPU在用户进程、内核进程、中断处理、IO等待以及空闲五个部分使用的百分比,这五个值是用来分析CPU消耗情况的关键指标。 Linux System and NewWork Performance Monitoring 中建议用户进程的CPU消耗/内核的CPU消耗的比例在 65%-70% / 30%-35%
2)Linux观测CPU消耗状态的工具:perf、top、vmstat、pidstat、sar、pcpu、ps Hh -eo tid
工具 perf 性能测试工具
sudo apt-get install linux-tools-common
sudo apt-get install linux-tools-3.13.0-27-generic
工具top
用工具SSH登陆到Linux 上后,在字符界面下输入top命令后即可查看CPU的消耗情况,CPU的信息在TOP视图的上面几行中
Top查看CPU使用情况图:第四行被矩形围起来的部分:其中 0.2% us 表示用户进程处理所占的百分比;0.7% sy 表示为内核线程处理所占的百分比; 0.0% ni 表示被nice命令改变优先级的任务所占的百分比;99.0% id 表示CPU的idle空闲时间所占的百分比; 0.0% wa 表示在执行的过程中等待IO所占的百分比; 0.2% hi 表示硬件中断所占的百分比; 0.0% si 表示软件中断所占的百分比。

linux下查看根据进程查看线程的方法
1、cat /proc/${pid}/status
2、pstree -p ${pid}
3、3.1 top -p ${pid} 再top 中键入[Shift]-[H]组合键。
3.2 或者直接输入 top -bH -d 3 -p ${pid}
top -H 手册中说:-H : Threads toggle
加上这个选项启动top,top一行显示一个线程。否则,它一行显示一个进程。
1 先用ps + grep找出该死的进程pid,比如 30420
2 top -H -p 30420,(top然后shift+H可以看出某个线程)所有该进程的线程都列出来了。看看哪个线程pid占用最多,然后将这个pid转换为16进制,如 44bf,注意要小写
3 jstack 30420 | less,然后查找 nid=0x44bf,,找到了
4、ps xH
手册中说:H Show threads as if they were processes
这样可以查看所有存在的线程。
5、ps -mp
手册中说:m Show threads after processes
这样可以查看一个进程起的线程数。
工具pidstat
pidstat 是SYSSTAT中的工具.,如需使用pidstat,请先安装SYSSTAT:http://www.icewalkers.com/Linux/Software/59040/sysstat.html
安装方法: root$ sudo apt-get install sysstat
SYSSTAT包含工具有:sysstat, sar, sadf, iostat, pidstat,mpstat, nfsiostat and cifsiostat commands for Linux.
使用例子:
sar -n DEV 1 100
sar -n DEV 1 100 | grep lo
输入pidstat 1 2,在console上将会每隔1秒输出目前活动进程的CPU消耗状况,共输出2次, pidstat使用示例图 所示:

其中CPU表示的为当前进程所使用到的CPU个数,
如须查看进程中线程的CPU消耗状况,可以输入 pidstat -p [PID] -t 1 5 这样的方式来查看,执行后的输出如下:

图中的TID即为线程ID,较之top命令方式而言, pidstat的好处为可查看每个线程的具体CPU利用率的状况( 例如%usr 、%system )
CPU消耗方面相关工具介绍
除了top、pidstat外、linux中还可以使用vmstat来采样(例如每秒 vmstat 1)查看CPU的上下文切换、运行队列、利用率的具体信息。
ps Hh -eo tid,pcpu 方式也可用来查看具体线程的CPU消耗状况;sar来查看一定时间范围内以及历史的cpu消耗状况信息。SYSSTAT包含工具有:Sysstat, sar, sadf, iostat, pidstat,mpstat, nfsiostat and cifsiostat commands for Linux.
The sysstat package contains the sar, sadf, iostat, nfsiostat, cifsiostat, pidstat and mpstat commands for Linux.
The sar command collects and reports system activity information. The information collected by sar can be saved in a file in a binary format for future inspection. The statistics reported by sar concern I/O transfer rates, paging activity, process-related activities, interrupts, network activity, memory and swap space utilization, CPU utilization, kernel activities and TTY statistics, among others.
The sadf command may be used to display data collected by sar in various formats (CSV, XML, database-friendly, etc.).
The iostat command reports CPU utilization and I/O statistics for disks and network filesystems.
The pidstat command reports statistics for Linux tasks (processes).
The mpstat command reports global and per-processor statistics. Both UP and SMP machines are fully supported.
Sysstat has also support for hotplug CPU's, and for National Language (NLS).
The nfsiostat command reports I/O statistics for network filesystems.
The cifsiostat command reports I/O statistics for CIFS filesystems.
当CPU消耗严重时,主要体现在us、sy、wa 或 hi的值变高, wa的值是IO等待造成的,hi的值变高主要为硬件终端造成的,例如网卡接受数据频繁的状况。
对于Java应用而言,CPU消耗严重主要体现在us、sy两个值上,分别看看Java应用在这两个值高的情况下应如何找到对应造成瓶颈的代码。
3)us (CPU的用户进程处理所占的百分比)
当us值过高时,表示运行的应用消耗了大部分的CPU. 在这种情况下,对于Java应用而言,最重要的是找到具体消耗CPU的线程及锁执行的代码。
pstack显示每个进程的栈跟踪
pstree以树结构显示进程
方法如下:
首先通过Linux提供的命令(如:top/jps找到java进程pid,然后pidstat通过进程pid找到对应的线程tid)找到消耗CPU严重的线程及其ID,将此线程ID转化为十六进制的值。
其次通过kill -3 [javapid]或jstack 的方式dump出应用的java线程信息,通过之前转化出的十六进制的值找到对应的nid值的线程。此线程即为消耗CPU的线程,在采样时须多执行几次上述的过程,以确保找到真实的消耗CPU的线程。
寻找过程:第一步:jps找到java进程号PID=2418, 然后pidstat -p 2418 -t 1 5 | less 找到消耗CPU多的线程号tid=2428,然后将tid=2428(十进制) 转换为十六进制数:97C.


第二步:jstack 2418 > jstack03.txt 将线程dump信息写入文件jstack03.txt, 然后将十六进制的线程数:97C 为79C为查询条件,到jstack03.txt文件中查找到nid= 97C的线程,该线程即为消耗CPU多的线程。

从上可以看出,主要是ConsumeCPUTask的执行消耗了CPU,但由于jstack需要时间,因此基于jstack并不一定能分析出真正的消耗CPU的代码是哪行。
例如在一个操作中循环调用了很多其他的操作,如其他的操作每次都比较快,但由于循环太多次,造成了CPU消耗,在这种情况下jstack是无法捕捉出来的。最佳方式是通过 intel vtune来进行分析,vtune是商业软件(Intel芯片的一款性能分析软件,用AMD芯片的同学就不能用了)。
在不使用vtune的情况下,则只能通过认真查看整个线程中执行的动作来分析原因,例如在从上图中,可以看出ConsumeCPUTask一直处于运行状态,可以分析ConsumeCPUTask这个线程具体在做的动作,从其代码可看出真个线程一直处于运行过程中,中途没有IO中断、锁等待现象,因此造成了CPU消耗严重。
该示例源代码UsHighOfCpuDemo.java下载地址为:见参考部分
4) sy (内核线程处理所占的百分比)
当sy值高时表示Linux花费了更多的时间在进行线程切换,Java应用造成这种现象的主要原因是启动的线程比较多,且这些线程多数都处于不断的阻塞(例如锁等待、IO等待状态)和执行状态的变化过程中,这就导致了操作系统要不断地切换执行的线程,产生大量的上下文切换。在这种状况下,对Java应用而言,最重要的是找出线程不断切换状态的原因,可采用的方法为通过 kill -3 [javapid] 或jstack -l [javapid] 的方式dump出java应用程序的线程信息,查看线程的状态信息以及锁信息,找出等待状态或锁竞争过多的线程。
第一步运行 [root@localhost example]# java -jar SyHighOfCpuDemo.jar , top图如下: CPU的 sy使用比较高

在用vmstat -n 3 执行一下看一下上下文切换情况

由上可知,CPU在cs(内核线程上下文切换) 以及sy上消耗很大。
第二步 运行时采用jstack -l 查看程序的线程状况,可以看到启动了很多线程,并且很多的线程都经常处于 TIMED_WAITING(on object monitor)状态、WAITING (on object monitor)和Runnable状态的切换中。
通过on object monitor对应的堆栈信息,可查找到系统中锁竞争激烈的代码,这是造成系统更多时间消耗在线程上下文切换的原因。
具体TIMED_WAITING(on object monitor)状态、WAITING (on object monitor)和Runnable状态如下图



该示例源代码SyHighOfCpuDemo.java下载地址为:见参考
2.内存消耗分析
Java应用对于内存的使用包括两方面 JVM堆内存 和 JVM堆外内存。 Java应用对内存的消耗上主要是在JVM堆内存上。在正式环境中,多数Java应用都会将 -Xms 和 -Xmx设为相同的值,避免运行期要不断申请内存。
目前Java应用只有在创建线程和使用Direct ByteBuffer 时才会操作JVM堆外的内存JVM,因此在内存消耗方面最值得关注的是JVM内存的消耗状况。对于JVM内存消耗状况分析的方法工具有:JVM(jmap、jstat、mat、visualvm等方法)。JVM内存消耗过多会导致GC执行频繁,CPU消耗增加,应用线程的执行速度严重下降,甚至造成OutOfMemoryError,最终导致Java进程退出。
sudo -u admin /opt/taobao/java/bin/jmap -F -dump:live,format=b,file=/home/admin/dumpcrash_20150909_2.log 6606sudo -u admin /opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234/opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234jmap -histo 13321> dump_platform.corejmap -dump:live,format=b,file=heap_platform.core 13321jmap –dump:file=<文件名>,format=b [pid] sudo -u admin /opt/taobao/java/bin/jmap -F -dump:live,format=b,file=/home/admin/dumpcrash_20150909_2.log 6606sudo -u admin /opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234/opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234jmap -histo 13321> dump_platform.corejmap -dump:live,format=b,file=heap_platform.core 13321jmap –dump:file=<文件名>,format=b [pid] sudo -u admin /opt/taobao/java/bin/jmap -F -dump:live,format=b,file=/home/admin/dumpcrash_20150909_2.log 6606sudo -u admin /opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234/opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234jmap -histo 13321> dump_platform.corejmap -dump:live,format=b,file=heap_platform.core 13321jmap –dump:file=<文件名>,format=b [pid] sudo -u admin /opt/taobao/java/bin/jmap -F -dump:live,format=b,file=/home/admin/dumpcrash_20150909_2.log 6606sudo -u admin /opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234/opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234jmap -histo 13321> dump_platform.corejmap -dump:live,format=b,file=heap_platform.core 13321jmap –dump:file=<文件名>,format=b [pid] sudo -u admin /opt/taobao/java/bin/jmap -F -dump:live,format=b,file=/home/admin/dumpcrash_20150909_2.log 6606sudo -u admin /opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234/opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234jmap -histo 13321> dump_platform.corejmap -dump:live,format=b,file=heap_platform.core 13321jmap –dump:file=<文件名>,format=b [pid] sudo -u admin /opt/taobao/java/bin/jmap -F -dump:live,format=b,file=/home/admin/dumpcrash_20150909_2.log 6606sudo -u admin /opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234/opt/company/java/bin/jmap -F -dump:file=/home/user/dumpcrash_xxx.log 1234jmap -histo 13321> dump_platform.corejmap -dump:live,format=b,file=heap_platform.core 13321jmap –dump:file=<文件名>,format=b [pid] 分析jmap的dump文件: Eclipse Memory Analyzer http://www.eclipse.org/mat/downloads.php
对于JVM堆以外的内存方面的消耗,最为值得关注的是swap的消耗 以及 物理内存的消耗,这两方面的消耗都可基于操作系统的命令来查看。

方法区Method Area内存大小对应的配置参数是:-XX:PermSize -XX:MaxPermSize 这个抛出OutOfMemoryError: PermGen space (常量池或类太多,如反射,CGLib等)
Java堆Heap内存大小对应的配置参数是:-Xms -Xmx 这个抛出OutOfMemoryError: Java heap space
虚拟机栈VM stack内存大小对应的配置参数是:-Xss 这个抛出StackOverflowError; OutOfMemoryError:unable to create new native thread
本地方法栈Native Method stack内存大小对应的配置参数是:-XX:DirectoryByteBuffer -XX:MaxDirectoryByteBuff 这个抛出OutOfMemoryError: sun.misc.Unsafe.allocateMemory(Native Method)
在Java语言中,对象访问是如何进行的呢?
对象访问在Java语言中无处不在的,即使最普通的程序行为,也会涉及Java栈、Java堆、方法区这三个最重要内存区域之间的关联关系,如下代码:
Object obj = new Object();
假设这句代码出现在方法体中,那“Object obj”这部分的语义将会反映到【Java栈】的本地变量表中,作为一个reference类型数据出现。
而“new Object()”这部分的语义将会反映到【Java堆】中,形成一块存储了Object类型所有实例数据值(Instance Data,对象中各个实例字段的数据)的结构化内存,根据具体类型以及虚拟机实现的对象内存布局(Object Memory Layout)的不同,这块内存的长度是不固定的。
另外在Java堆中还必须包含能查找到此对象类型数据(如对象类型、父类、实现的接口、方法等)的地址信息,这些类型数据则存储在【方法区Method Area】中。
类加载的步骤:

1)内存消耗分析工具介绍
在Linux中可通过vmstat、sar、top、pidstat, pmap等方式来查看 swap和物理内存的消耗状况。
vmstat
在命令行中输入vmstat,其中的信息和内存相关的主要是memory下的swpd、free、buff、cache以及swap下的si 和 so.

其中swpd是指虚拟内存已使用的部分,单位为kb;free表示空闲的物理内存;buffer表示用于缓冲的内存;cache表示用于作为缓存的内存
swap下的si是指每秒从disk读至内存的数据量;so是指每秒从内存中写入disk的数据量。swpd值过高通常是由于物理内存不够用,操作系统将物理内存中的一部分数据转为放入硬盘上进行存储,以腾出足够的空间给当前运行的程序使用。
在目前运行的程序变化后,即从硬盘上重新读取数据到内存中,以便恢复程序的运行,这个过程会产生swap IO, 因此看swap的消耗情况主要关注的是swapIO的状况,如swapIO发生得较频繁,那么严重影响系统的性能。
由于Java应用是单进程应用,因此只要JVM的内存设置不是过大,是不会操作到swap区域的。物理内存消耗过高可能是由于JVM内存设置过大、创建的Java线程过多或通过Direct ByteBuffer往物理内存中放置了过多的对象造成的。
sar
通过sar的-r参数可查看内存的消耗状况,例如sar -r 2 5

物理内存相关的信息主要是kbmemfree、kbmemused、%memused、kbbuffers、kbcached, 当物理内存有空闲时,Linux会使用一些物理内存用于buffer和cache, 以提升系统的运行效率,因此可以认为系统中可用的物理内存为: kbmemfree + kbmemused + kbcached.
sar相比vmstat的好处是可以查询历史状况,以更加准确地分析趋势状况,例如 sar -r -f /temp/log/sa/sa12
vmstat 和 sar的共同弱点是不能分析进程所占用的内存量。
top
通过top可查看进程所消耗的内存量,不过top中看到的Java进程消耗的内存。因为Java进程是包括了JVM已分配的内存加上Java应用所耗费的JVM以外的物理内存,这会导致top中看到Java进程所消耗的内存大小有可能超过 -Xmx 加上 -XX:MaxPermSize设置的内存大小,并且Java程序在启动后也只是占据了-Xms的地址空间,但并没有占据实际的内存,只有在相应的地址空间被使用过后才被计入消耗的内存中。因此纯粹的根据top很难判断出Java进程消耗的内存中有多少是属于JVM的,有多少是属于JVM外的内存。
一个小技巧是对由于内存满而发生过Full GC的应用而言(不是主动调用System.gc的应用),多数情况下(例如由于产生的对象过大导致执行Full GC并抛出OutOfMemoryError的现象就要出外)可以认为其Java进程中显示出来的内存消耗值即为 JVM -Xmx的值 + 消耗的JVM外的内存值。

4pidstat
通过 pid也可以查看进程所消耗的内存量,命令格式为: pidstat -r -p [pid] [interval] [times], 例如如下:

查看该进程所占用的物理内存RSS(Resident Set Size)和虚拟内存的大小VSZ(virtual memory size)。
从以上的几个工具来看,最佳的内存消耗分析方法是结合top或pidstat,以及JVM的内存分析工具来共同分析内存消耗状况。
下面通过例子分别展示Java应用对物理内存的消耗和对JVM堆内的消耗。
2) JVM堆外内存消耗分析
基于Direct ByteBuffer可以很容易地实现对物理内存的直接操作,而无须耗费JVM heap区。
例子中,为了更清晰地观察内存的变化情况,放入了多个Thread.sleep,加上 -Xms140 -Xmx140参数执行上面的代码,在执行过程中结合top命令和jstat命令查看java进程占用内存的大小以及JVM heap的变化情况。
[root@localhost ~]# jps4661 jar4670 Jps[root@localhost ~]# pidstat -r -p 4661 1 100 [root@localhost ~]# jps4661 jar4670 Jps[root@localhost ~]# pidstat -r -p 4661 1 100 [root@localhost ~]# jps4661 jar4670 Jps[root@localhost ~]# pidstat -r -p 4661 1 100 [root@localhost ~]# jps4661 jar4670 Jps[root@localhost ~]# pidstat -r -p 4661 1 100 jps找到java进程,jstat -gcutil [pid] 1000 10
代码示例:HighNonHeapOfMemoryDemo.java
结合上面top和jstat观察到的状态,可以查出 direct bytebuffer消耗的是JVM heap 外的物理内存。但它同样是基于GC方式来释放的,同时也可以看出JVM heap一旦使用后,即使进行了GC,进行中仍然会显示之前其所消耗的内存大小,因此JVM内存中具体的消耗状况必须通过JDK提供的命令才可以准确分析。
除了Direct Bytebuffer方式对JVM外物理内存的消耗外,创建线程也会消耗一定大小的内存。这一方面取决于-Xss对应值的大小,另一方面也取决于线程stack的深度,当线程退出时,其所占用的内存将自动释放。
3)JVM堆内存消耗分析(需要重点补充)
Java应用中除了Direct Bytebuffer、创建线程等操作JVM外物理内存的方法外,大多数都是对于JVM heap区的消耗。
在Java程序出现内存消耗过多、GC频繁或OutOfMemoryError的情况后,要首先分析其所耗费的是JVM外的物理内存还是JVM heap区。 如为JVM外的物理内存,则要分析程序中线程的数量以及Direct Bytebuffer的使用情况;如果为JVM heap区,则要结合JDK提供的工具或外部的工具分析程序中的具体对象的内存占用情况。
3.文件IO消耗分析
1)文件IO分析的常用命令
Linux在操作文件时,将数据放入文件缓存区,直到内存不够或系统要释放内存给用户进程使用时,才写入文件中。因此在查看Linux内存状况时经常会发现可用(free)的物理内存不多,但cached用了很多,这是Linux提升文件IO速度的一种做法,在这种做法下,如物理空闲内存够用,通常在Linux上只有写文件和第一次读取文件时会产生真正的文件IO. 在Linux中要跟踪线程的文件IO的消耗,主要方法是通过pidstat来查找。
pidstat
输入如:pidstat -d -t -p [pid] 1 100 类似的命令即可查看线程的IO消耗状况,必须在2.6.20以上版本的内核或安装SYSSTAT工具后才会有效,执行后的效果如下图
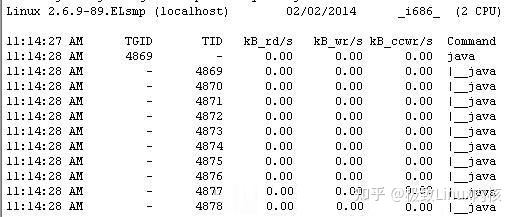
其中kB_rd/s表示每秒读取的kB数,kB_wr/s表示每秒写入的kB数。
没有安装pidstat或内核版本不在2.6.20以后的版本的情况,可通过iostat来查看,但iostat只能查看整个系统的文件IO消耗情况,无法跟踪到进程的文件IO消耗情况。
iostat
直接输入iostat命令,可查看各个设备的IO历史状况,如下图:
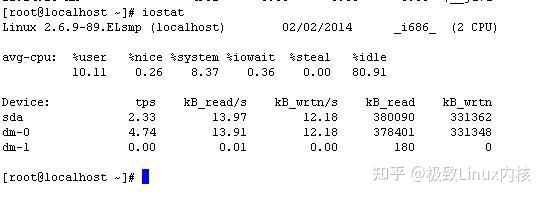
在上面的几项指标中,其中Device表示设备卷名称或分区名;tps是每秒的IO请求数,这也是IO消耗情况中值得关注的数字;kB_read/s表示每秒钟读的kB数; kB_wrtn/s 表示每秒钟写的kB数; kB_read总共读取的数量; kB_wrtn总共写入的数量;
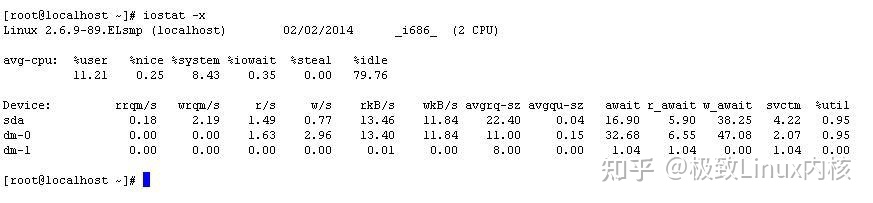
除了上面的方式外,还可通过输入iostat -x xvda 3 5 这样的方式来定时采样查看IO的消耗状况,执行如下:

其中值得关注的主要有: r/s表示每秒钟读的请求数;w/s表示每秒钟写的请求数;await表示平均每次IO操作的等待时间,单位为毫秒;avgqu-sz 表示等待请求的队列的平均长度;svctm表示平均每次设备执行IO操作的时间;%util表示有百分之多少用于IO操作。
在使用iostat查看IO的消耗时,首先要关注的是CPU中的iowait%所占的百分比,当iowait占据了主要的百分比时,就表示要关注IO方面的消耗状况了,
这时可以通过iostat -x 方式来详细地查看具体情况,参见下图:
2)文件IO消耗分析案例
当文件IO消耗过高时,对于Java应用最重要的是找到造成文件IO消耗高的代码,寻找的最佳方案为通过pidstat直接找到文件IO操作多的线程。之后结合jstack找到对应的Java代码,如没有pidstat,也可直接根据jstack得到的线程信息来分析其中文件IO操作较多的线程。
Java应用造成文件IO消耗严重主要是多个线程需要进行大量内容写入(例如频繁的日志写入)的动作;或磁盘设备本身的处理速度慢;或文件系统慢;或操作的文件本身已经很大造成的。
例子,通过往一个文件中不断地增加内容,文件越来越大,造成写速度慢,最终IOWait值高。

从关注从top中的%iowait值偏高可以判断占据了很多CPU, 结合iostat的信息来看,主要是wkB/s比较高主要是写的消耗,并且花费在await上的时间要远大于svctm的时间。至于是什么动作导致了iowait,仍然需要对应用的线程dump来分析,找出其中的IO操作相关的动作。使用pidstat找到IO读写量大的线程ID,然后结合jstack生成的线程dump文件,即可找到相应的消耗文件IO多的动作。
jstack操作进程线程的dump文件如下:

从上面的线程堆栈中,可看到线程停留在了(Native Method)这个Native方式上,这个方法所做的动作为将数据写入文件中,也就是所要寻找的IO操作相关的动作。继续跟踪堆栈往上查找,知道查找到系统中的代码,例如例子中的,
-
相关阅读:
第一百六十一回 Sliver综合示例
【Numpy总结】第一节:Numpy 对象与类型
Vue.use的实现原理
Unity之NetCode多人网络游戏联机对战教程(5)--ConnectionData与MemoryPack
Qt基础教程:QString
15、用户web层服务(三)
k8s之Job和CronJob
windows下使用nginx + waitress 部署django
spring 事务失效的 12 种场景
centos7安装ansible图形化管理界面AWX
- 原文地址:https://blog.csdn.net/m0_74282605/article/details/127865103