-
canal监听mysql实践
canal监听mysql实践
canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,canal主要支持了MySQL的binlog解析,解析完成后才利用canal client 用来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基于canal)。使用场景包括:
1.缓存更新
2.异步数据库或者同步到关系型数据库的中间媒介
canal介绍及工作原理
基于日志增量订阅&消费支持的业务:
- 数据库镜像
- 数据库实时备份
- 多级索引 (卖家和买家各自分库索引)
- search build
- 业务cache刷新
- 价格变化等重要业务消息
这里也介绍了业务cache刷新和价格变化等重要数据变更消息的监听。
Canal原理相对比较简单:

-
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
-
mysql master收到dump请求,开始推送binary log给slave(也就是canal)
-
canal解析binary log对象(原始为byte流)
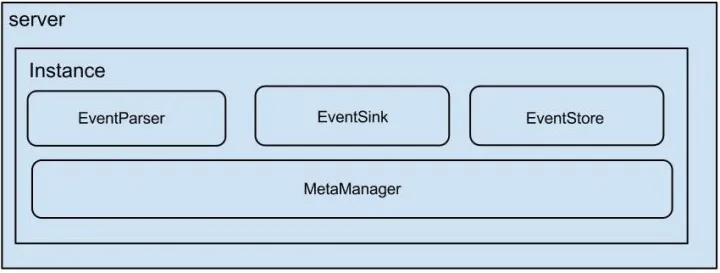
Canal架构及工作原理
- server 代表一个 canal 运行实例,对应于一个 jvm
- instance 对应于一个数据队列 (1个 canal server 对应 1…n 个 instance )
- instance 下的子模块
- eventParser: 数据源接入,模拟 slave 协议和 master 进行交互,协议解析
- eventSink: Parser 和 Store 链接器,进行数据过滤,加工,分发的工作
- eventStore: 数据存储
- metaManager: 增量订阅 & 消费信息管理器

- EventSink起到一个类似channel的功能,可以对数据进行过滤、分发/路由(1:n)、归并(n:1)和加工。EventSink是连接EventParser和EventStore的桥梁。
- EventStore实现模式是内存模式,内存结构为环形队列,由三个指针(Put、Get和Ack)标识数据存储和读取的位置。
- MetaManager是增量订阅&消费信息管理器,增量订阅和消费之间的协议包括get/ack/rollback,分别为:
- Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:batch id[唯一标识]和entries[具体的数据对象]
- void rollback(long batchId),顾名思义,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
- void ack(long batchId),顾名思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
docker canal搭建
先在Docker Hub中下载canal-server镜像
docker pull canal/canal-server:latest- 1
先启动Canal,用于复制properties配置文件
docker run -p 11111:11111 --name canal -d canal/canal-server:latest- 1
初次启动Canal镜像后,将instance.properties文件复制到宿主机,用于后续挂载使用
docker cp canal:/home/admin/canal-server/conf/example/instance.properties /mydata/canal/conf/- 1
修改instance.properties,该文件主要配置监听的mysql实例
################################################# ## mysql serverId , v1.0.26+ will autoGen # canal.instance.mysql.slaveId=0 # enable gtid use true/false 未开启gtid主从同步 canal.instance.gtidon=false # position info 在同一宿主机内 若有主从数据库,填写主数据库地址 canal.instance.master.address=172.17.0.1:3306 #需要读取的起始的binlog文件 不填写的话默认应该是从最新的Binlog开始监听 canal.instance.master.journal.name= #需要读取的起始的binlog文件的偏移量 canal.instance.master.position= #需要读取的起始的binlog的时间戳 canal.instance.master.timestamp= canal.instance.master.gtid= # rds oss binlog canal.instance.rds.accesskey= canal.instance.rds.secretkey= canal.instance.rds.instanceId= # table meta tsdb info canal.instance.tsdb.enable=true #canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb #canal.instance.tsdb.dbUsername=canal #canal.instance.tsdb.dbPassword=canal # 从数据库地址 主备切换时使用 #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = #canal.instance.standby.gtid= # username/password canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false #canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex canal.instance.filter.regex=.*\\..* # table black regex 不需要监听的名单 canal.instance.filter.black.regex=mysql\\..*,sys\\..*,performance_schema\\..*,information_schema\\..* # table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch # table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # mq config 默认的sql存储队列 canal.mq.topic=example # dynamic topic route by schema or table regex #canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\\..*,.*\\..* canal.mq.partition=0 # hash partition config #canal.mq.enableDynamicQueuePartition=false #canal.mq.partitionsNum=3 #canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6 #canal.mq.partitionHash=test.table:id^name,.*\\..* #################################################- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
Canal为我们提供了canal.instance.filter.regex与canal.instance.filter.black.regex选项参数来过滤数据库表数据解析,类似黑白名单。常见例子有:
●所有表:.* or .\…
●canal schema下所有表:canal\…*
●canal下的以canal打头的表:canal\.canal.*
●canal schema下的一张表:canal\.test1
●多个规则组合使用:canal\…*,mysql.test1,mysql.test2 (逗号分隔)修改canal.properties,该文件主要时配置canal server
################################################# ######### destinations ############# ################################################# ##配置监听多数据实例的地方 单数据库监听的话这里配置example就可以 canal.destinations = example # conf root dir canal.conf.dir = ../conf # auto scan instance dir add/remove and start/stop instance canal.auto.scan = true canal.auto.scan.interval = 5 # set this value to 'true' means that when binlog pos not found, skip to latest. # WARN: pls keep 'false' in production env, or if you know what you want. canal.auto.reset.latest.pos.mode = false canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml #canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml canal.instance.global.mode = spring canal.instance.global.lazy = false canal.instance.global.manager.address = ${canal.admin.manager} #canal.instance.global.spring.xml = classpath:spring/memory-instance.xml canal.instance.global.spring.xml = classpath:spring/file-instance.xml #canal.instance.global.spring.xml = classpath:spring/default-instance.xml # tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ 选择的消费队列 canal.serverMode = tcp- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
消费队列模式与Server-client模式一致,主要区别如下:
- 不需要CanalServerWithNetty,改为CanalMQProducer投递消息给消息队列
- 不使用CanalClient,改为MqClient获取消息队列的消息进行消费
这种模式相比于Server-client模式
-
下游解耦,利用消息队列的特性,可以支持多个客户端广播消费、集群消费、重复消费等
-
会增加系统的复杂度,增加一些延迟
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uLGBhukW-1668440711353)(http://p3-tt.byteimg.com/large/pgc-image/7ba19ac6829f4d4688d0f4e93ab2919f?from=pc)]](https://1000bd.com/contentImg/2024/04/23/343cba8e2c57e3f8.png)
本地的instance.properties:容器的instance.properties 将容器的instance.properties配置文件挂载到宿主机,方便后续变更
docker stop canal;docker rm canal; 重新生成容器
docker run -p 11111:11111 --name canal -v /mydata/canal/conf/instance.properties:/home/admin/canal-server/conf/example/instance.properties -d canal/canal-server:latest
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jp1I8Fvr-1668440711354)(C:\Users\煎饼果子\AppData\Roaming\Typora\typora-user-images\image-20221113191556796.png)]](https://1000bd.com/contentImg/2024/04/23/f0a8b7b70091d8b4.png)
查看消费实例example的日志可以看出canal监听的binlog位置正好是连接时的binlog位置,前提是未指定了Binlog的位置。客户端开始连接后便可以从指定位置开始消费增量的binlog。binlog-format=ROW # 选择 ROW 模式.
java客户端实例消费
1.引入pom文件
<!--canal--> <dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.client</artifactId> <version>1.1.5</version> </dependency> <!-- Message、CanalEntry.Entry等来自此安装包 --> <dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.protocol</artifactId> <version>1.1.5</version> </dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.application.yml配置文件canal
canal: serverAddress: 42.192.183.193 serverPort: 11111 instance: #多个instance - example- 1
- 2
- 3
- 4
- 5
对应的properties文件
@Component @ConfigurationProperties(prefix = "canal") @Data public class CanalInstanceProperties { /** * canal server地址 */ private String serverAddress; /** * canal server端口 */ private Integer serverPort; /** * canal 监听实例 */ private Set<String> instance; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3.监听数据库变动代码
@Component @Slf4j public class MysqlDataListening { private static final ThreadFactory springThreadFactory = new CustomizableThreadFactory("canal-pool-"); private static final ExecutorService executors = Executors.newFixedThreadPool(1, springThreadFactory); @Autowired private CanalInstanceProperties canalInstanceProperties; @PostConstruct private void startListening() { canalInstanceProperties.getInstance().forEach( instanceName -> { executors.submit(() -> { connector(instanceName); }); } ); } /** * 消费canal的线程池 */ public void connector(String instance){ CanalConnector canalConnector = CanalConnectors.newSingleConnector( new InetSocketAddress(canalInstanceProperties.getServerAddress(), canalInstanceProperties.getServerPort()), instance, "", ""); canalConnector.connect(); //订阅所有消息 canalConnector.subscribe(".*\\..*"); // canalConnector.subscribe("test1.*"); 只订阅test1数据库下的所有表 //恢复到之前同步的那个位置 canalConnector.rollback(); for(;;){ //获取指定数量的数据,但是不做确认标记,下一次取还会取到这些信息。 注:不会阻塞,若不够100,则有多少返回多少 Message message = canalConnector.getWithoutAck(100); //获取消息id long batchId = message.getId(); int size = message.getEntries().size(); if (size == 0 || batchId == -1) { try{ Thread.sleep(1000); } catch (InterruptedException ignored) { } } if(batchId != -1){ log.info("instance -> {}, msgId -> {}", instance, batchId); printEnity(message.getEntries()); //提交确认 canalConnector.ack(batchId); //处理失败,回滚数据 //canalConnector.rollback(batchId); } } } private void printEnity(List<CanalEntry.Entry> entries) { for (CanalEntry.Entry entry : entries) { if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) { continue; } CanalEntry.RowChange rowChange = null; try{ // 序列化数据 rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue()); } catch (InvalidProtocolBufferException e) { e.printStackTrace(); } assert rowChange != null; CanalEntry.EventType eventType = rowChange.getEventType(); log.info(String.format("================>; binlog[%s:%s] , name[%s,%s] , eventType : %s", entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType)); if (rowChange.getEventType() == CanalEntry.EventType.QUERY || rowChange.getIsDdl()) { log.info("sql ------------>{}" ,rowChange.getSql()); } for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) { switch (rowChange.getEventType()){ //如果希望监听多种事件,可以手动增加case case UPDATE: printColumn(rowData.getAfterColumnsList()); printColumn(rowData.getBeforeColumnsList()); break; case INSERT: printColumn(rowData.getAfterColumnsList()); break; case DELETE: printColumn(rowData.getBeforeColumnsList()); break; default: } } } } private void printColumn(List<CanalEntry.Column> columns) { StringBuilder sb = new StringBuilder(); for (CanalEntry.Column column : columns) { sb.append("["); sb.append(column.getName()).append(" : ").append(column.getValue()).append(" update=").append(column.getUpdated()); sb.append("]"); sb.append(" "); } log.info(sb.toString()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
数据库变动效果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kaZaI9oH-1668440711355)(C:\Users\煎饼果子\AppData\Roaming\Typora\typora-user-images\image-20221114223319230.png)]](https://1000bd.com/contentImg/2024/04/23/0c40dd946d188994.png)
注意的问题**canal client:**为了保证有序性,一份实例(instance)同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。canal server 上的一个 instance 只能有一个 client 消费。clientId是固定的,Binlog文件落入文件保存。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g1zNll5x-1668440711356)(C:\Users\煎饼果子\AppData\Roaming\Typora\typora-user-images\image-20221113224244554.png)]](https://1000bd.com/contentImg/2024/04/23/b4566b23ddacc4fa.png)
由于保证了有序性,生产过快而消费慢的问题,如何解决消费堆积问题
其次在使用Canal自带客户端进行同步时需要自己手动调用get()或者getWithoutAck()进行拉取
拉取日志后进行同步只能一条一条处理,效率比较低
为了解决上面的问题打算在日志同步过程中引入MQ来作为中间同步,Canal支持RocketMQ和Kafka两种,最终选用Kafka来进行总结
canal的原理是借助mysql主从复制的协议,模拟从数据库拉取增量Binlog日。canal通过Instance作为一个从数据库实例,客户端连接实例后有序消费增量的Binlog日志。有几点特别注意的是,一是canal的生产消费模型是一个带指针的数组,分别指向生产位置、消费位置和ack位置,来控制消费和生产的队列。二是Binlog的配置需要时row格式,canal的解析针对row格式做了适配。三是canal通过client竞争的方式保证消费时只有一个client消费,保证binlog的有序性。四是,生产端数据量大的时候canal会存在消费不及时的问题,存在一定延时性。性能分析时业务binlog入库到canal client拿到数据,基本可以达到10~20w的TPS。具体业务解析时肯定要低于这个,不过对于一般业务来说,已足够用。
参考
https://github.com/luozijing/springLearning 代码仓
https://blog.csdn.net/gudejundd/article/details/119358028 缓存删除解决方案
https://zhuanlan.zhihu.com/p/345736518-ShardingSphere canal详解
https://github.com/alibaba/canal/wiki/%E7%AE%80%E4%BB%8B canal详解
https://github.com/alibaba/canal/wiki/performance canal性能
-
相关阅读:
自己动手写数据库:并发管理的基本原理
resource android:attr/lStar not found.和unknown tag <:string>问题
[纯理论] FCOS
2020 滴滴java面试笔试总结 (含面试题解析)
鸿蒙特色物联网实训室
python的语法错误与异常
postman接口传参案例
【DesignMode】设计模式的7种原则
5、Kafka集成 SpringBoot
怎么解决MySQL 8.0.18 大小写敏感问题
- 原文地址:https://blog.csdn.net/qq_17236715/article/details/127858089
