-
pytorch深度学习实战lesson14
第十四课 丢弃法(Dropout)

目录
理论部分
这节课很重要,因为沐神说这个丢弃法比上节课的权重衰退效果更好!


为什么期望没变?
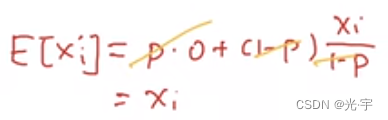
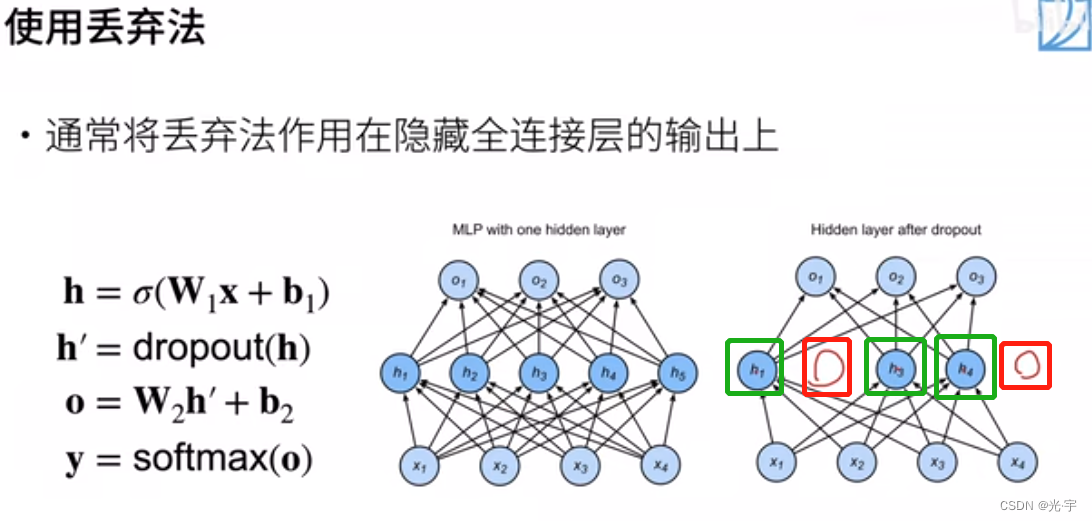
如上图所示,使用dropout后,是将隐藏层的的某几个神经元变成零,然后没有变成0的神经元会相应增大以保证总的期望不变。当然保留和置零的神经元不是一定的。这个是训练才会使用,测试的时候不用。


实践部分
从零开始实现:
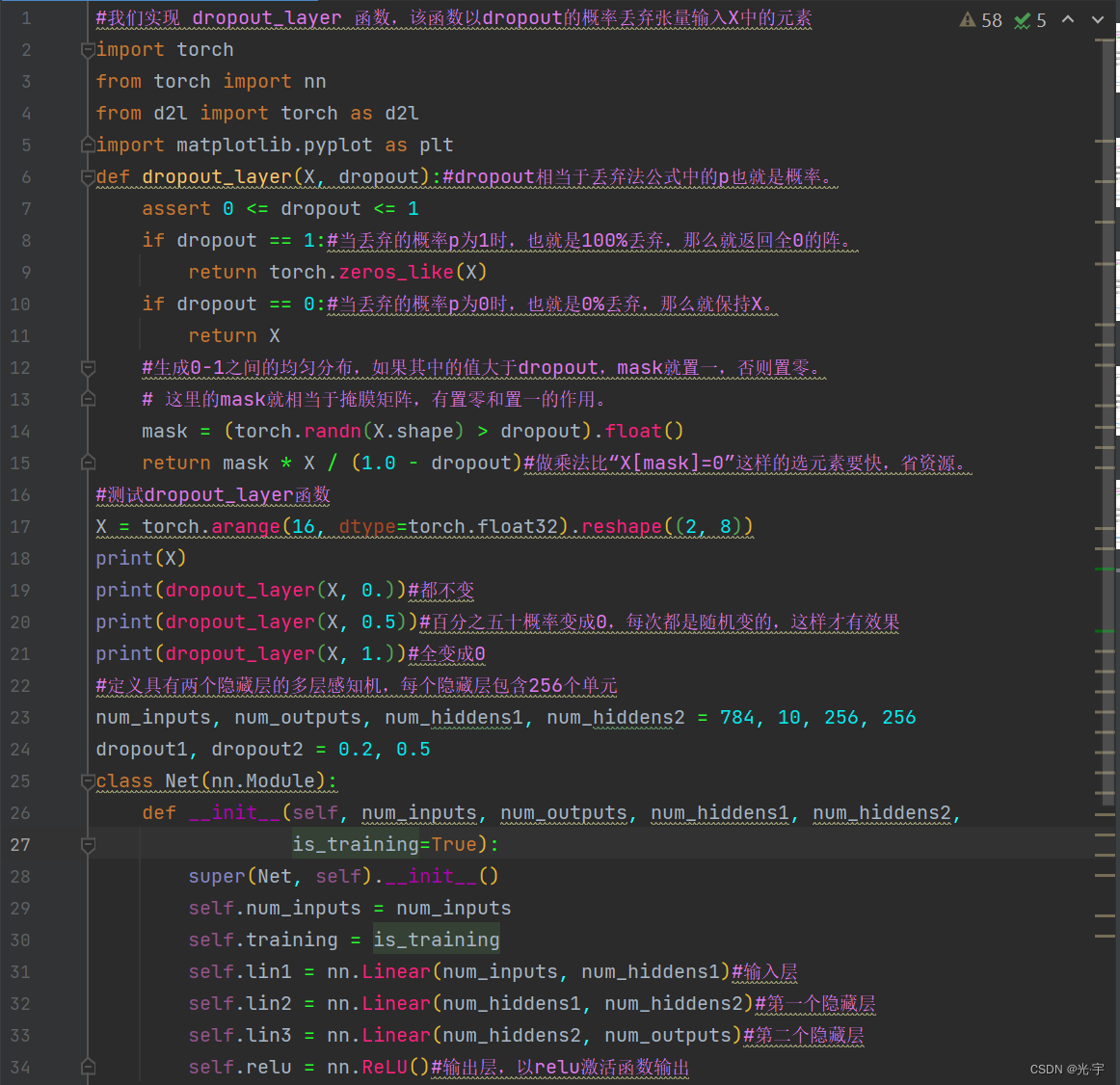


代码:
- #我们实现 dropout_layer 函数,该函数以dropout的概率丢弃张量输入X中的元素
- import torch
- from torch import nn
- from d2l import torch as d2l
- import matplotlib.pyplot as plt
- def dropout_layer(X, dropout):#dropout相当于丢弃法公式中的p也就是概率。
- assert 0 <= dropout <= 1
- if dropout == 1:#当丢弃的概率p为1时,也就是100%丢弃,那么就返回全0的阵。
- return torch.zeros_like(X)
- if dropout == 0:#当丢弃的概率p为0时,也就是0%丢弃,那么就保持X。
- return X
- #生成0-1之间的均匀分布,如果其中的值大于dropout,mask就置一,否则置零。
- # 这里的mask就相当于掩膜矩阵,有置零和置一的作用。
- mask = (torch.randn(X.shape) > dropout).float()
- return mask * X / (1.0 - dropout)#做乘法比“X[mask]=0”这样的选元素要快,省资源。
- #测试dropout_layer函数
- X = torch.arange(16, dtype=torch.float32).reshape((2, 8))
- print(X)
- print(dropout_layer(X, 0.))#都不变
- print(dropout_layer(X, 0.5))#百分之五十概率变成0,每次都是随机变的,这样才有效果
- print(dropout_layer(X, 1.))#全变成0
- #定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元
- num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
- dropout1, dropout2 = 0.2, 0.5
- class Net(nn.Module):
- def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
- is_training=True):
- super(Net, self).__init__()
- self.num_inputs = num_inputs
- self.training = is_training
- self.lin1 = nn.Linear(num_inputs, num_hiddens1)#输入层
- self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)#第一个隐藏层
- self.lin3 = nn.Linear(num_hiddens2, num_outputs)#第二个隐藏层
- self.relu = nn.ReLU()#输出层,以relu激活函数输出
- def forward(self, X):
- H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))#第一个隐藏层
- if self.training == True: #如果是在训练的话
- H1 = dropout_layer(H1, dropout1)#就dropout
- H2 = self.relu(self.lin2(H1)) #第二个隐藏层
- if self.training == True: #如果在训练的话
- H2 = dropout_layer(H2, dropout2)#就dropout
- out = self.lin3(H2) #输出层不dropout
- return out
- net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
- #训练和测试
- num_epochs, lr, batch_size = 10, 0.5, 256
- loss = nn.CrossEntropyLoss()
- train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
- trainer = torch.optim.SGD(net.parameters(), lr=lr)
- d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
- plt.show()
简洁实现:
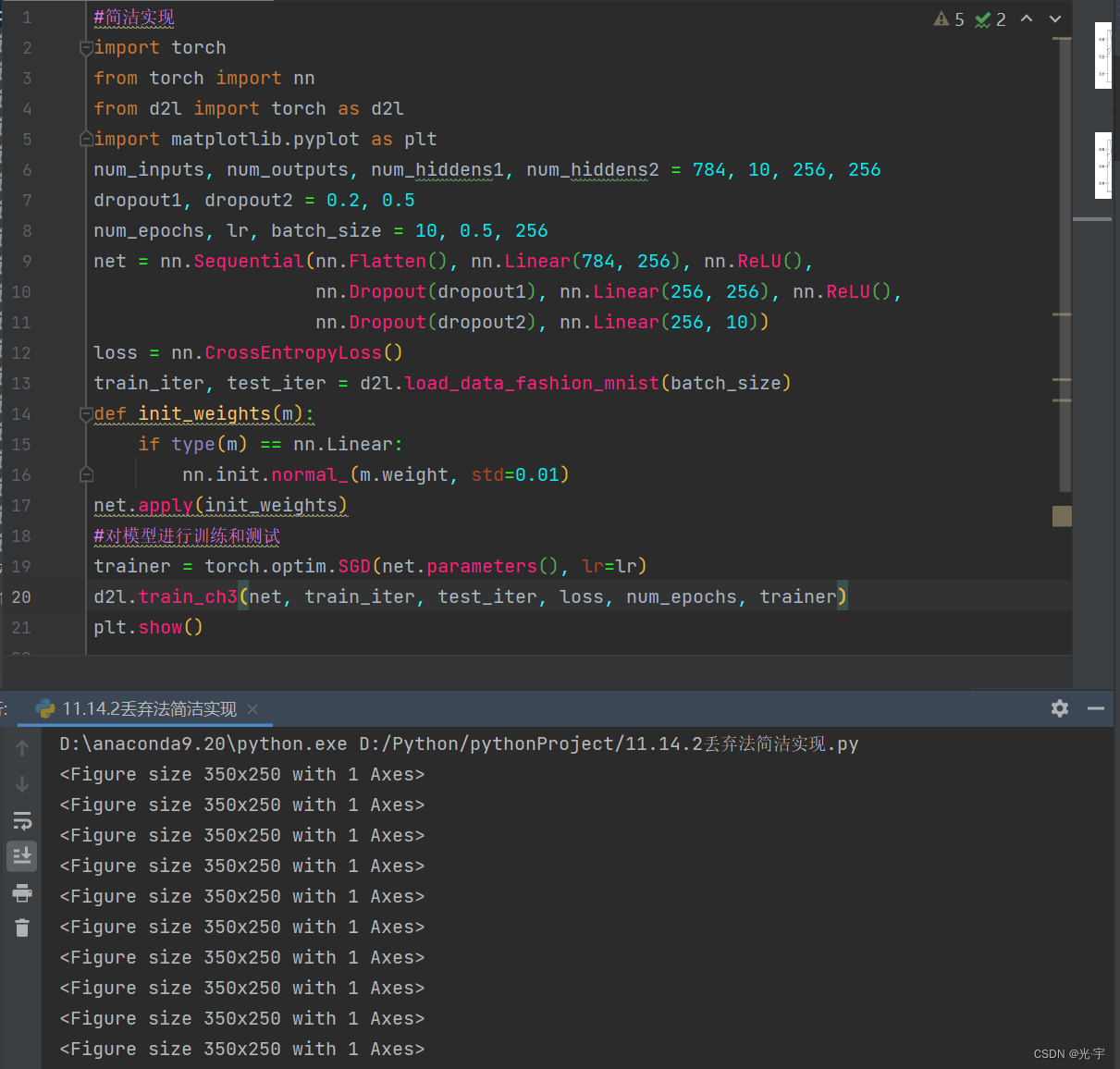
代码:
- #简洁实现
- import torch
- from torch import nn
- from d2l import torch as d2l
- import matplotlib.pyplot as plt
- num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
- dropout1, dropout2= 0.2, 0.5
- num_epochs, lr, batch_size = 10, 0.5, 256
- net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(),
- nn.Dropout(dropout1), nn.Linear(256, 256), nn.ReLU(),
- #nn.Dropout(dropout2), nn.Linear(256, 256), nn.ReLU(),
- nn.Dropout(dropout2), nn.Linear(256, 10))
- loss = nn.CrossEntropyLoss()
- train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
- def init_weights(m):
- if type(m) == nn.Linear:
- nn.init.normal_(m.weight, std=0.01)
- net.apply(init_weights)
- #对模型进行训练和测试
- trainer = torch.optim.SGD(net.parameters(), lr=lr)
- d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
- plt.show()
拓展:
在简洁实现的基础上,调整参数看有什么变化。
1、把两个dropout的概率都设为0(代码第7行)

和简洁实现比,没什么大区别。
2、把两个dropout的概率分别设为0.7和0.9(代码第7行)
Traceback (most recent call last):
File "D:\Python\pythonProject\11.14.2丢弃法简洁实现.py", line 20, in
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
File "D:\anaconda9.20\lib\site-packages\d2l\torch.py", line 343, in train_ch3
assert train_loss < 0.5, train_loss
AssertionError: 2.3032064454396566
3、把两个dropout的概率都设为1(代码第7行)
相当于把隐藏层神经元都给换成0了。
报错了
Traceback (most recent call last):
File "D:\Python\pythonProject\11.14.2丢弃法简洁实现.py", line 20, in
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
File "D:\anaconda9.20\lib\site-packages\d2l\torch.py", line 343, in train_ch3
assert train_loss < 0.5, train_loss
AssertionError: 2.3032064454396566
4、把两个dropout的概率分别设为1和0(代码第7行)
Traceback (most recent call last):
File "D:\Python\pythonProject\11.14.2丢弃法简洁实现.py", line 20, in
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
File "D:\anaconda9.20\lib\site-packages\d2l\torch.py", line 343, in train_ch3
assert train_loss < 0.5, train_loss
AssertionError: 2.3032064454396566
5、把两个dropout的概率分别设为0和1(代码第7行)
Traceback (most recent call last):
File "D:\Python\pythonProject\11.14.2丢弃法简洁实现.py", line 20, in
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
File "D:\anaconda9.20\lib\site-packages\d2l\torch.py", line 343, in train_ch3
assert train_loss < 0.5, train_loss
AssertionError: 2.3032064454396566
上面这三种情况都是dropout1和dropout2里面有一个设的比较大的时候才会报错,报错的原因是说torch.py里面有一句assert语句出问题了。这块我还没想到怎么解决。我也不是很明白torch.py里面的三组assert语句有什么用。。如果有大佬明白咋回事的话可以指点一下。谢谢。
6、加个隐藏层。


感觉效果不是很好啊。
后来把隐藏层的输入输出维度改了一下就好点了:


-
相关阅读:
JavaWeb在线商城系统(java+jsp+servlet+MySQL+jdbc+css+js+jQuery)
基于Struts开发物流配送(快递)管理系统
openbmc开发38:webui开发—增加head栏语言切换
手写一个Bus总线
在Ubuntu20.04安装Kylin4 On Docker并在DataGrip配置JDBC协议连接容器内Hive1.2.1及Kylin4.0.0
基于Java+SpringBoot+Thymeleaf+Mysql在线考试系统设计与实现
Goby 漏洞发布|Revive Adserver 广告管理系统 adxmlrpc.php 文件远程代码执行漏洞(CVE-2019-5434)
Statistical Hypothesis Testing
亚马逊计划向开创性的人工智能初创公司Anthropic投资高达4亿美元
公钥密码学中的公钥和私钥
- 原文地址:https://blog.csdn.net/weixin_48304306/article/details/127850503
